

Этапы проектирования баз данных
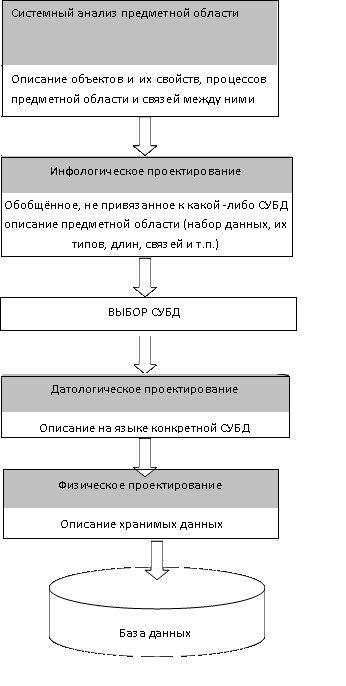
Законы проектирования баз данных: 1.Системный анализ предметной области 2.Инфологическое проектирование 3.Выбор СУБД 4.Датологическое проектирование 5.Физическое проектирование I Системный анализ предметной области На первом этапе проектирования баз данных рассматриваются цели и задачи с помощью которой они будут решатся. Анализируются информационные потребности будущих пользователей баз данных. Рассматриваются формы входных и выходных потоков, которые будут составлять основу баз данных. Затем уточняются алгоритмы и процедуры обработки данных хранимой в базе данных. Формируются требования, которым должна удовлетворять проектируемая база данных и определяется примерный список объектов предметной области, свойства которых будут использоваться при разработке базы данных. II Инфологическое проектирование На второй стадии проектирования выполняется моделирование данных. Моделирование данных – это процесс создания логической структуры данных. Существует два подхода к моделированию данных: Модель «Сущность-связь» Семантическая объектная модель Эти модели представляют собой языки для описания структуры данных и их связей в представлениях пользователей. Моделирование данных, подобно блок-схемам, отражают логику программы. Модель «Сущность-Связь» Сущность – это объект, идентифицируемый в рабочей среде пользователя за которым пользователь хотел бы наблюдать. Класс сущностей – это совокупность сущностей, которая описывается структурой, либо форматом сущностей, составляющих этот класс. Экземпляр сущности – представляет собой конкретную сущность. Атрибуты сущности – это свойства сущности, которые описывают характеристики сущности. Идентификаторы – это атрибуты, с помощью которых экземпляры именуются или идентифицируются. Если идентификатор указывает на один экземпляр сущности, то его значение называется уникальным. Если идентификатор не является уникальным, то его значение определяется некоторым множеством экземпляров сущности. Связи – это взаимоотношения сущностей выраженная связями. Модель «Сущность-Связь» включает в себя классы связей и экземпляры связей. Классы связей – это взаимоотношения между классами сущностей. Экземпляры связей – это взаимоотношения между экземплярами сущностей. Типы связей: Связь один к одному (1:1) – одиночный экземпляр сущности одного типа связан с одиночным экземпляром сущности другого типа. Связь один ко многим (1:М) – один экземпляр сущности связан со многими экземплярами другой сущности. Связь многие ко многим (М:N) – несколько экземпляров одной сущности связаны с несколькими экземплярами другой сущности. Модель «Сущность-Связь» или ER-диаграммы включают в себя изображения сущностей в виде прямоугольников (или прямоугольников с закругленными углами), а связей в виде ромбиков (или ромбиков с закругленными углами). На ER-диаграммах атрибуты обозначаются эллипсами. Если атрибутов у сущности много, то чтобы не загружать ER-диаграмму, атрибуты помещают в прямоугольник, в котором идет перечисление всех атрибутов сущности. Семантическая объектная модель Данная модель используется для моделирования данных на этапе инфологического моделирования. Семантический или смысловой объект – это объект, который в определенной степени моделирует смысл пользовательских данных. Они более точно моделируют представления пользователей. У семантических объектов есть имя, а также есть имя и у класса, отличающего его от других объектов и классов. Семантическая модель имеет набор атрибутов. Атрибуты описывают те характеристики объекта, которые необходимы для удовлетворения информационных потребностей в аспекте решаемых задач. Для моделирования данных в семантических объектах используется объектные диаграммы. Такие диаграммы используются разработчиками баз данных для описания и визуального представления структуры объектов. Объекты в них отражаются в вертикально ориентированных прямоугольниках. Имя объекта указывается внутри прямоугольника в верхней его части, а затем следует список атрибутов по порядку их значимости для этого объекта. Для описания типов семантических объектов используются следующие понятия: Однозначный атрибут - атрибуты с максимальным кардинальным числом равным 1. Многозначный атрибут – атрибут, имеющий максимальное кардинальное число большее 1. Необъектный атрибут – это простой или групповой атрибут. Типы объектов: простые, композитные, составные, гибридные, ассоциативные, родитель. III Выбор СУБД При выборе СУБД руководствуются следующими соображениями: аппаратное обеспечение, на котором в дальнейшем будет работать проектируемая база данных; системное программное обеспечение, с которым будет в последствии работать проектируемая база данных и соответствующее ей приложения; методология и подходы, к программированию реализованные в той или иной СУБД; модель данных, которая встроена в конкретную СУБД; Выбор СУБД полностью определяется на II этапе построения базы данных, т. к. оно зависит от той модели данных, которая встроена в выбранную СУБД. IV Датологическое проектирование После того, как выбор СУБД завершён, необходимо приступить к проектированию датологической модели базы данных. При формировании датологической схемы, каждая из определённых в концептуальной схеме сущностей отображается в таблицу, которая является одним отношением. При этом следует учитывать ограничения на размер таблиц, которые накладывает конкретная СУБД. V Физическое проектирование На этом этапе необходимо на конкретной СУБД, которую выбрали ранее, реализовать базу данных по той информации, которую собрали, обработали и подготовили (на предыдущих этапах проектирования базы данных). Описываются модули, их назначение, а также структура модулей. Этапы и содержание жизненного цикла БД: I. проектирование 1 II. создание 1). Генерация БД 2). Подготовка среды хранения данных 3). Ввод и контроль данных 4). Загрузка и корректировка БД III.эксплуатация 1). Реорганизация БД реструктуризация БД реформация БД 2). Организация доступа к БД поиск и обновление данных вывод отчетов разграничение доступа при необходимости инициирование и завершение работы с СУБД 3). Контроль состояния БД сбор и анализ статистики использования БД контроль целостности БД копирование и восстановление БД (по необходимости) Этапы проектирования базы данных: |
 ).
Анализ системной предметной области
и запросов будущих пользователей в
БД
2). Интеграция пользовательских
представлений с целью построения
инфологической модели предметных
областей.
3). Выбор средства реализации,
т.е. конкретных СУБД для разработки
БД
4). Датологическое проектирование
5).
Физическое проектирование
).
Анализ системной предметной области
и запросов будущих пользователей в
БД
2). Интеграция пользовательских
представлений с целью построения
инфологической модели предметных
областей.
3). Выбор средства реализации,
т.е. конкретных СУБД для разработки
БД
4). Датологическое проектирование
5).
Физическое проектированиеНа этапе проектирования базы данных разработчик должен определить, из каких таблиц должна состоять база данных, какие данные нужно поместить в каждую таблицу и как связать таблицы. Следовательно, в результате проектирования определяются логическая структура базы данных, т. е. состав реляционных таблиц, их структура и межтабличные связи. Для создания базы данных необходимо располагать описанием выбранной предметной области, охватывающим реальные объекты и процессы, а также определить все необходимые источники информации для удовлетворения предполагаемых запросов пользователей и потребности в обработке данных. На основе такого описания определяются состав и структура данных предметной области, которые должны находиться в базе и обеспечивать выполнение необходимых запросов и задач пользователей. Структура данных предметной области может отображаться информационно-логической моделью, на основе которой легко создается реляционная база данных. Этапы проектирования и создания базы данных:
построение информационно-логической модели данных предметной области;
определение логической структуры реляционной базы данных;
конструирование таблиц базы данных;
создание схемы данных;
ввод данных в таблицы (создание записей);
разработка необходимых форм, запросов, макросов, модулей, отчетов;
разработка пользовательского интерфейса.
В процессе разработки модели данных необходимо выделить информационные объекты, соответствующие требованиям нормализации данных, и определить связи между ними. Полученная модель позволит создать реляционную базу данных без дублирования, в которой обеспечиваются однократный ввод данных при первоначальной загрузке и корректировках, а также целостность данных при внесении изменений.
При разработке модели данных используются два подхода. Сначала определяются основные задачи, для решения которых строится база, выявляются потребности задач в данных и соответственно определяются состав и структура информационных объектов. Сразу устанавливаются типовые объекты предметной области. Наиболее рационально сочетание этих подходов, так как на начальном этапе, как правило, нет исчерпывающих сведений обо всех задачах. Использование такой технологии тем более оправдано, что гибкие средства создания реляционной базы данных допускают на любом этапе разработки внесение изменений и модифицирование ее структуры без ущерба для введенных ранее данных. Процесс выделения информационных объектов предметной области, отвечающих требованиям нормализации, может производиться на основе интуитивного или формального подхода. Теоретические основы формального подхода разработаны известным американским ученым Дж. Мартином и изложены в его монографиях по организации баз данных. При интуитивном подходе легко выявить информационные объекты, соответствующие реальным объектам, однако получаемая при этом информационно-логическая модель, как правило, требует дальнейших преобразований, в частности преобразования много-многозначных связей между объектами. При таком подходе в случае отсутствия достаточного опыта возможны существенные ошибки. Последующая проверка выполнения требований нормализации обычно показывает необходимость уточнения информационных объектов. Рассмотрим формальные правила выделения информационных объектов:
на основе описания предметной области выявить документы и их атрибуты, подлежащие хранению в базе данных;
определить функциональные зависимости между атрибутами;
выбрать все зависимые атрибуты и указать для каждого все его ключевые атрибуты, т. е. атрибуты, от которых он зависит;
сгруппировать атрибуты, одинаково зависимые от ключевых атрибутов. (Полученные группы зависимых атрибутов вместе с их ключевыми атрибутами образуют информационные объекты.)
При определении логической структуры реляционной базы данных на основе модели каждый информационный объект адекватно отображается реляционной таблицей, а связи между этими таблицами соответствуют связям между информационными объектами. В процессе создания БД сначала конструируются таблицы, соответствующие информационным объектам построенной модели данных. Далее может создаваться схема данных, в которой фиксируются существующие логические связи между таблицами, соответствующие связям информационных объектов. В схеме данных могут быть заданы параметры поддержания целостности базы данных, если модель была разработана в соответствии с требованиями нормализации. Целостность данных означает, что в БД установлены и корректно поддерживаются взаимосвязи между записями разных таблиц при загрузке, добавлении и удалении записей в связанных таблицах, а также при изменении значений ключевых полей. После формирования схемы данных осуществляется ввод непротиворечивых данных из документов предметной области. На основе созданной базы формируются необходимые запросы, формы, макросы, модули, отчеты, производящие требуемую обработку данных и их представление. С помощью встроенных средств и инструментов базы данных создается пользовательский интерфейс, позволяющий управлять процессами ввода, хранения, обработки, обновления и представления информации