

Практика 1
«Эконометрия»
2 курс
При
исследовании поведения экономической
системы во времени независимой переменной
является временной параметр (час, день,
месяц, год), обозначаемый в дальнейшем
![]() .
Тогда зависимая переменная будет
сочетать два фактора: а) при фиксированном
времени
является
случайной величиной; б) является функцией
аргумента
.
Такую величину называют случайной
функцией или случайным процессом и ее
будем обозначать, как
.
Тогда зависимая переменная будет
сочетать два фактора: а) при фиксированном
времени
является
случайной величиной; б) является функцией
аргумента
.
Такую величину называют случайной
функцией или случайным процессом и ее
будем обозначать, как
![]() .
В общем виде модели случайных процессов
описывающих поведение экономических
систем можно записать в виде:
.
В общем виде модели случайных процессов
описывающих поведение экономических
систем можно записать в виде:
![]() ,
(1.2.1)
,
(1.2.1)
где
![]() - случайная составляющая, которая в
каждый момент времени имеет нулевое
среднее, т.е.
- случайная составляющая, которая в
каждый момент времени имеет нулевое
среднее, т.е.
![]() .
Детерминированная (регулярная)
составляющая
.
Детерминированная (регулярная)
составляющая
![]() допускает в общем случаи следующую
запись:
допускает в общем случаи следующую
запись:
![]() ,
(1.2.2)
,
(1.2.2)
где
![]() -
тренд, как правило, параметризованная
функция (например, параболическая
-
тренд, как правило, параметризованная
функция (например, параболическая
![]() );
);
![]() -
сезонная составляющая;
-
сезонная составляющая;
![]() - периодическая составляющая. Часто
тренд
называют полиномиальной
составляющей,
а
- периодическая составляющая. Часто
тренд
называют полиномиальной
составляющей,
а
![]() и
- тригонометрическими
составляющими
случайного процесса.
и
- тригонометрическими
составляющими
случайного процесса.
На практике детерминированная составляющая может включать одно (например, тренд ) или два слагаемых (например, тренд и сезонную составляющую ).
Кроме аддитивной модели (1.2.1) возможна мультипликативная модель случайного процесса:
![]() ,
(1.2.3)
,
(1.2.3)
Временной
выборкой случайного процесса (в зарубежной
литературе time-series
data)
называется совокупность наблюдений
![]() случайной величины
случайной величины
![]() в дискретные моменты времени
в дискретные моменты времени
![]() .
.
Например,
взяты
![]() выпусков некоторого рекламного издания,
и они упорядочены по дате выпуска. Из
каждого выпуска взята цена автомобиля
определенного класса. В этом случаи
получаем временную выборку, составленную
из наблюдений
выпусков некоторого рекламного издания,
и они упорядочены по дате выпуска. Из
каждого выпуска взята цена автомобиля
определенного класса. В этом случаи
получаем временную выборку, составленную
из наблюдений
![]() ,
где
,
где
![]() - время выхода i-го
рекламного издания.
- время выхода i-го
рекламного издания.
Временная
зависимость данных делает существенным
порядок следования наблюдаемых значений
![]() во временной выборке. Это означает, что
перестановка
во временной выборке может существенно
сказаться на характеристиках исследуемой
зависимости
.
во временной выборке. Это означает, что
перестановка
во временной выборке может существенно
сказаться на характеристиках исследуемой
зависимости
.
К основным задачам анализа случайного процесса относятся:
выделение детерминированной составляющей ;
выделение тренда ;
выделение сезонной составляющей ;
выделение периодической составляющей
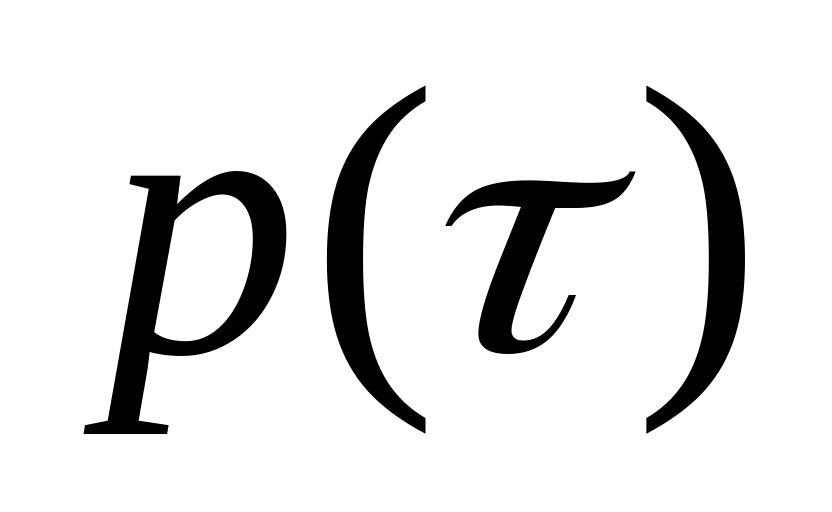 ;
;построение модели случайной составляющей ;
прогнозирование развития изучаемого процесса на основе построенной модели временного ряда.
Здесь
под выделением понимается не только
разделение детерминированной составляющей
на присутствующие в ней слагаемые, но
и построение соответствующего
математического описания для каждого
слагаемого
![]()
Временным
рядом (или
дискретным
случайным процессом)
называется совокупность случайных
величин
![]() , сформированную из случайной величины
в моменты
, сформированную из случайной величины
в моменты
![]() Учитывая что моменты
жестко фиксированы временной ряд можно
записать как совокупность
Учитывая что моменты
жестко фиксированы временной ряд можно
записать как совокупность
![]() ,
состоящую из n
случайных величин
,
состоящую из n
случайных величин
![]() .
Задачи анализа временного ряда аналогичны
перечисленным выше задачам анализа
случайного процесса. Временная выборка
временного ряда также состоит из n
наблюдений (т.е. уже не случайных величин)
.
Задачи анализа временного ряда аналогичны
перечисленным выше задачам анализа
случайного процесса. Временная выборка
временного ряда также состоит из n
наблюдений (т.е. уже не случайных величин)
![]() ,
,
![]()
1.3. Системы одновременных уравнений
Такие системы могут состоять из тождеств и регрессионных уравнений, каждое из которых, кроме «собственных» объясняющих переменных, может включать в себя объясняемые переменные из других уравнений системы.
Примером может служить модель спроса и предложения. Пусть QD(t) – спрос на товар в момент времени t; QS(t) – предложение товара в момент времени t; P(t) – цена на товар в момент времени t, Y(t) -– доход в момент t. Система имеет вид:
QS(t) = 1 + 2 P(t) + 3 P(t – 1) + (t) (предложение) . (1.3.1)
QD(t) = 1 + 2 P(t) + 3 Y(t) + u(t) (спрос). (1.3.2)
QS(t) = QD(t) (равновесие). (1.3.3)
Цена на товар P(t) и спрос на товар Q(t) = QS(t) = QD(t) определяются из уравнения модели. Объясняющими переменными являются доход Y(t) и значение цены P(t – 1)) в предыдущий момент времени t – 1.
К основным задачам, возникающим при построении таких моделей можно отнести:
определение вида входящих функций регрессии;
оценивание коэффициентов регрессионных зависимостей;
определение решений, удовлетворяющих системе тождеств и регрессионных уравнений.
1.4. Типы переменных эконометрических моделей.
Применимо к рассмотренным моделям можно ввести следующую классификацию переменных:
экзогенные переменные – переменные, задаваемые из вне рассматриваемой системы и в определенном смысле управляемы;
эндогенные переменные – переменные, значения которых формируются в процессе и внутри функционирования анализируемой системы;
лаговые эндогенные переменные – переменные, входящие в уравнения анализируемой системы, но измерены в прошлые моменты, а, следовательно, являются уже известными заданными.
предопределенные переменные – все экзогенные переменные модели и лаговые эндогенные переменные.
Обобщая изложенное, можно сказать, что эконометрическая модель позволяет объяснить поведение эндогенных переменных в зависимости от значений экзогенных и лаговых эндогенных переменных.
1.5. Рассматриваемые задачи и вычислительная среда решения этих задач
Табличный процессор Excel предоставляет две возможности для реализации вычислений при построении эконометрических моделей:
программирование необходимых вычислений в ячейках Excel;
обращение к соответствующим функциям и модулям Excel.
Первый подход более универсальный (так как позволяет реализовать любой вычислительный алгоритм), но требует определенных затрат времени и знаний основ алгоритмизации вычислений. Второй путь более простой, но ограничен имеющимся набором «стандартных» функций и модулей Excel.
В работе будем использовать обе рассмотренные возможности реализации требуемого вычислительного алгоритма.
программирования арифметических выражений в ячейках электронной таблицы;
функций Excel (в основном математических и статистических).
Замечание 1.5.1. В тексте при описании той или иной функции в качестве формальных параметров используются имена переменных, определенные в тексте. При обращении к функции в качестве фактических параметров могут использоваться константы, адреса ячеек, диапазоны адресов и арифметические выражения. Например, описание функции для вычисления среднего арифметического значения (выборочного среднего) имеет вид:
СРЗНАЧ(![]() ,
,
где
![]() -
формальные параметры, число которых не
превышает 30 (
-
формальные параметры, число которых не
превышает 30 (![]() ).
Для вычисления среднего значения
величин, находящихся в ячейках B3,
B4,B5,B6,C3,C4,C5,C6,
обращение к функции в соответствующей
ячейке имеет вид
).
Для вычисления среднего значения
величин, находящихся в ячейках B3,
B4,B5,B6,C3,C4,C5,C6,
обращение к функции в соответствующей
ячейке имеет вид
=СРЗНАЧ(B3:B6;С3:C6) ,
т.е. в качестве фактических параметров используются два диапазона ячеек.
В качестве примера такого комментария на рис. 1.1 показан фрагмент документа Excel, вычисляющего среднее значение чисел, размещенных в ячейках B3:B6, C3:C6. Результат вычислений находится в ячейки B8, а ниже показано выражение, запрограммированное в этой ячейке.
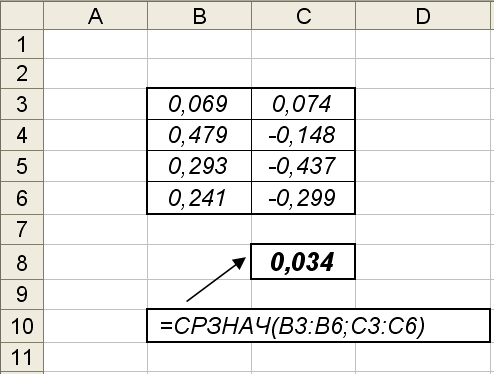
Рис. 1.1. Фрагмент вычисления среднего значения