

В появившемся окне уже указаны коэффициенты альфа-Кронбаха и усредненной межпунктовой корреляции в указанном наборе переменных (у нас это шкала обм – обучаемость). Вот это окно:
В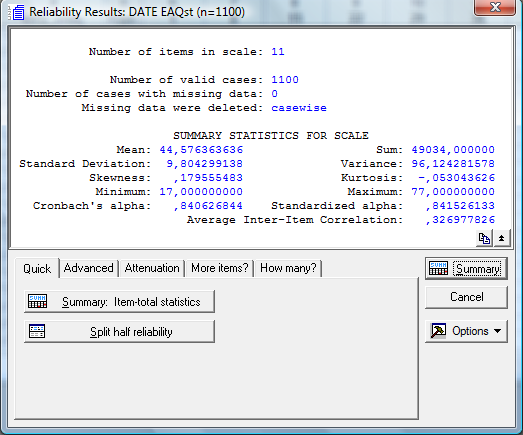 нем указано число пунктов (item
in scale) в
шкале, количество наблюдений (1100),
ошибочно забитых данных (0), среднее
значение по шкале (Mean),
Стандартное отклонение (Standart
Deviation), коэффициенты
асимметрии (Skewness) и эксцесса
(Kurtosis), минимум и максимум
по шкале. Но главное –коэффициент
надежности по альфа-Кронбаха. В нашем
случае их два – «сырой» и отъюстированный,
стандартизованный. Можете взять для
анализа любой. Очевидно, что он превышает
0,84. Это значительно выше минимальных
0,65 – 0,7. Значит, внутренняя согласованность
по шкале ОБМ вполне удовлетворительная,
близка к высокой (0,9).
нем указано число пунктов (item
in scale) в
шкале, количество наблюдений (1100),
ошибочно забитых данных (0), среднее
значение по шкале (Mean),
Стандартное отклонение (Standart
Deviation), коэффициенты
асимметрии (Skewness) и эксцесса
(Kurtosis), минимум и максимум
по шкале. Но главное –коэффициент
надежности по альфа-Кронбаха. В нашем
случае их два – «сырой» и отъюстированный,
стандартизованный. Можете взять для
анализа любой. Очевидно, что он превышает
0,84. Это значительно выше минимальных
0,65 – 0,7. Значит, внутренняя согласованность
по шкале ОБМ вполне удовлетворительная,
близка к высокой (0,9).
Там же указан усредненный коэффициент корреляции между пунктами (межпунктовая корреляция в данном наборе пунктов). Она равна 0,327. Если учесть, что удовлетворительным этот коэффициент считается в диапазоне от 0,2 до 0,5, то мы в этом наборе также имеем оптимальный показатель согласованности пунктов друг с другом. С одной стороны, они различаются (коэффициент корреляции не превышает 0,5), с другой – взаимосвязаны, т.е. измеряют одно и то же – обучаемость.
Осталось посмотреть коэффициент надежности по расщеплению на 2 половинки. Для этого щелкаем по клавише Split half realibility и немедленно получаем результат:
З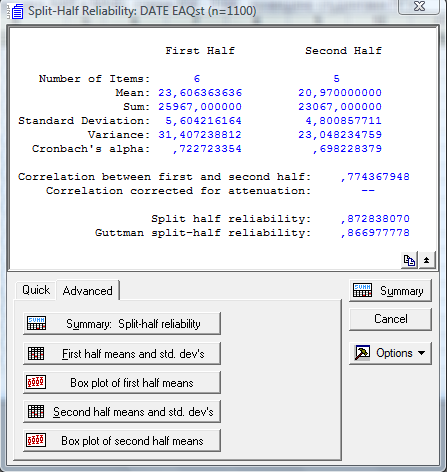 десь
все читается просто. По каждой из
половинок (6 пунктов и 5 пунктов) нашей
шкалы вычислены свои показатели
дескриптивной статистики (среднее,
сумма и т.п.), а также альфа-Кронбаха. Но
главное – величина коэффициентов
надежности по расщелению (Split
half). Их два – классический
и по Гутману. Впрочем, оба приблизительно
одинаковы: 0,87. Это – очень высокий
коэффициент надежности по расщеплению.
Да и альфа-Кронбаха по каждой отдельной
половинке около 0,7 или превышает его.
Это свидетельствует о достаточно высокой
надежности по внутренней согласованности.
Т.е. пункты данной шкалы – ОБМ (обучаемость)
образуют высоконадежную шкалу.
десь
все читается просто. По каждой из
половинок (6 пунктов и 5 пунктов) нашей
шкалы вычислены свои показатели
дескриптивной статистики (среднее,
сумма и т.п.), а также альфа-Кронбаха. Но
главное – величина коэффициентов
надежности по расщелению (Split
half). Их два – классический
и по Гутману. Впрочем, оба приблизительно
одинаковы: 0,87. Это – очень высокий
коэффициент надежности по расщеплению.
Да и альфа-Кронбаха по каждой отдельной
половинке около 0,7 или превышает его.
Это свидетельствует о достаточно высокой
надежности по внутренней согласованности.
Т.е. пункты данной шкалы – ОБМ (обучаемость)
образуют высоконадежную шкалу.
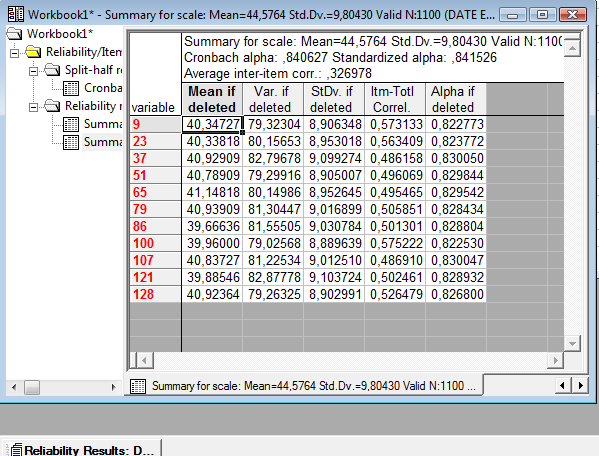
Щелкнув клавишу Cancel, Вы возвращаетесь к предыдущему меню анализа шкалы по внутренней согласованности. Если щелкните по клавише Summary, появится таблица, показывающая, что будет с коэффициентом альфа-Кронбаха, если удалить тот или иной пункт данной шкалы. Обратите внимание и на клавишу в левом углу (Reliability Results). Через нее Вы можете вернуться к меню для выбора другого набора переменных (пунктов), чтобы проверить надежность других шкал.
Все задания выполнены. Подготовьте подробный ответ с описанием всех операций и интерпретацией коэффициентов.
После ответа не забудьте закрыть открытые файлы. Сохранять ничего не надо.
Экзаменационное задание к вопросу № 48:
Вычисление и интерпретация наиболее популярных в психометрике коэффициентов дескриптивной (описательной или базовой) статистики.
Откройте в папке ЭКЗАМЕН файл «Станд_Кот и УАШ» в программе Statistica 6.0.
Вычислите все знакомые Вам параметры дескриптивной статистики тестовых показателей (среднее арифметическое, ст.отклонение, асимметрию, эксцесс и др.).
Проверьте нормальность распределения (визуально и другими средствами).
Выясните, какие из диагностических шкал и насколько близки к нормальному распределению?
________________________________________________________________________________
Руководство по выполнению задания к вопросу № 48:
Откройте в папке «Практические занятия на ПК» или «ЭКЗАМЕН» файл «Станд_Кот и УАШ» в программе Statistica.
Необходимые операции и коэффициенты находятся в модуле базовой статистики. Активизируем его следующим образом: Statistics – Basic Statistics/Tables – в выпавшем меню щелкаем по модулю Descriptive Statistics (или, подсветив данный модуль, нажимаем клавишу ОК). В итоге получаем окно выбора переменных:
 Активизируем
клавишу Variables и выбираем
для последующего анализа все переменные.
Нажимаем ОК. Затем активизируем клавишу
расширенного анализа Advanced,
и в выпавшем меню отмечаем то, что нам
необходимо. Вот как
это выглядит:
Активизируем
клавишу Variables и выбираем
для последующего анализа все переменные.
Нажимаем ОК. Затем активизируем клавишу
расширенного анализа Advanced,
и в выпавшем меню отмечаем то, что нам
необходимо. Вот как
это выглядит:
V alid
N
alid
N
Mean – среднее арифметическое;
Median – медиана;
Mode – мода;
Std.Deviation – станд.отклонение;
Skewness – асимметрия;
Std.err.Skewness – станд.ошибка асимметрии;
Kurtosis – эксцесс (островершинность распределения);
Std.err. Kurtosis – станд.ошибка эксцесса.
Далее жмем ОК и получаем таблицу результатов:
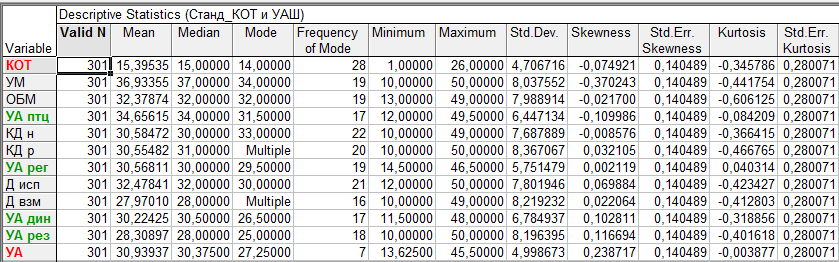
Уже по этой таблице можно судить о нормальности распределения переменных, полученных в выборке 301 респондента. Известно, что асимметрия и экесцесс в случае нормального распределения должны приближаться к нулю (грубая мера оценки нормальности – эти коэффициенты не должны превышать 1). Более тонкая мера оценки нормальности – величина эксцесса и асимметрии не должна превышать величины их стандартной оценки. А в нашем случае такие моменты имеются, например, по шкале УМ (учебная мотивация).
Впрочем, еще лучше нормальность распределения проверяется графически или с помощью специальных коэффициентов, например, Колмогорова-Смирнова. Вычислим эти коэффициенты и построим графики.
Для этого в нижнее левом углу щелкаем по клавише Descriptive Statistics, а в уже знакомом выпавшем меню выбираем Normality, а затем щелкаем по кнопке Histograms. Получим несколько графиков. Первым из них будет график распределения суммарного индекса учебной активности в данной выборке (n = 301). Вот этот график:
К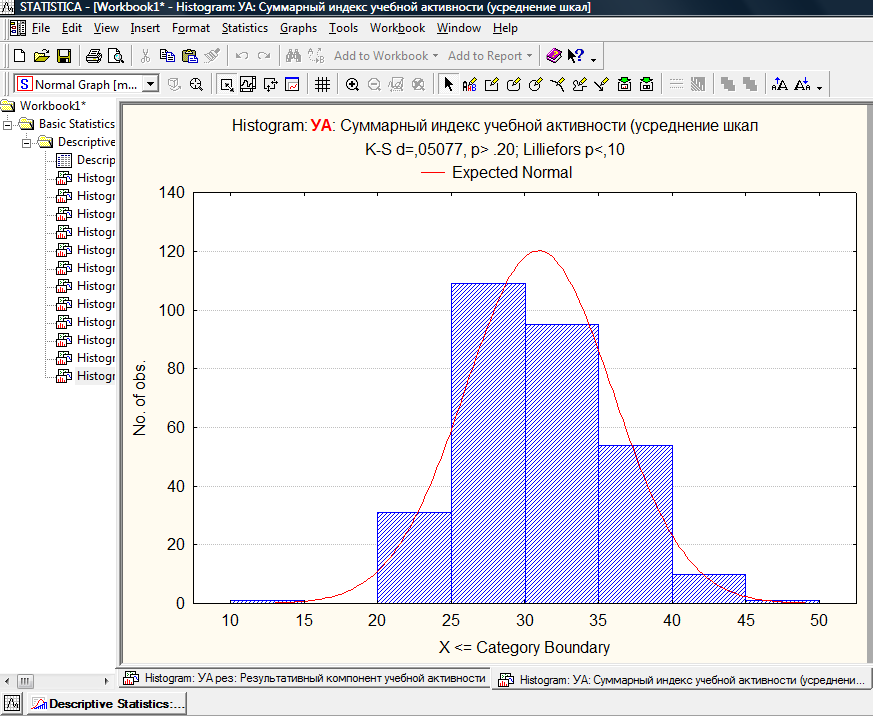 расная
линия – кривая идеального нормального
распределения. Столбики гистограммы
показывают реальное (эмпирическое)
распределение по шкале УА (учебной
активности). Очевидно, что эмпирическое
распределение близко к нормальному. На
это указывают и коэффициент d
по Колмогорову – Смирнову (K-S
d = 0,5; p.0,20). Это обозначает
следующее: вероятность ошибки вывода
о том, что наше эмпирическое распределение
значимо различается с нормальным
распределением, выше 0,20, т.е. эта
вероятность превышает 20%. Значит,
распределение не отличается от
нормального.
расная
линия – кривая идеального нормального
распределения. Столбики гистограммы
показывают реальное (эмпирическое)
распределение по шкале УА (учебной
активности). Очевидно, что эмпирическое
распределение близко к нормальному. На
это указывают и коэффициент d
по Колмогорову – Смирнову (K-S
d = 0,5; p.0,20). Это обозначает
следующее: вероятность ошибки вывода
о том, что наше эмпирическое распределение
значимо различается с нормальным
распределением, выше 0,20, т.е. эта
вероятность превышает 20%. Значит,
распределение не отличается от
нормального.
Слева от построенного графика Вы видите несколько значков гистограмм. Щелкнув по любому из них, Вы увидите графики и коэффициенты по другим переменным данного файла. Проинтерпретируйте их на степень близости к нормальному распределению.
После выполнения задания закройте файлы, не сохраняя их.
Экзаменационное задание к вопросам № 49-50:
Построение профилей средних значений диагностических показателей для подготовки к индивидуальной или групповой консультации.
Откройте в папке ЭКЗАМЕН рабочую книгу «Материалы к экзамену» в Excel , откройте лист «Данные по Кеттеллу» и постройте Личностный профиль клиента (по указанию преподавателя) на фоне усредненных значений показателей вопросника Р.Кеттелла (16PF) в выборках "Норма" и "Нарко".
Как бы Вы построили свою работу в индивидуальной консультации с этим клиентом, используя диагностические данные?
________________________________________________________________________________
Руководство по выполнению задания к вопросам № 49-50:
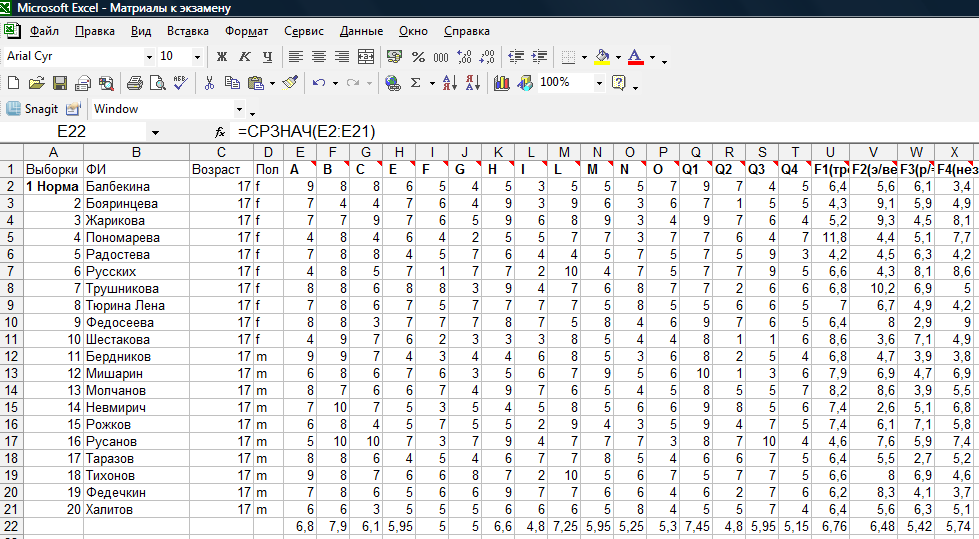
Откройте в папке «Практические занятия на ПК» рабочую книгу «Материалы к экзамену» в Excel. Откройте в этой рабочей книге лист «Профили по Кеттеллу». Как видите, уже готовый пример профилей у Вас на этом листе предложен. Осталось создать точно такой же самостоятельно.1 Для этого выполняем следующее:
Чтобы не портить образец, вставляем пустой лист (Вставка – Лист). Дважды щелкните по ярлычку этого листа и переименуйте его, например – Мой график).
Теперь чертим таблицу, по которой будем строить график. Делаем это прямо на пустом листе Мой график. Вот как будет выглядеть эта пока еще пустая таблица:

То есть, мы строим график в двух выборках, каждая из них по 20 респондентов. Это выборки Нарко (наркоманы) и Норма (не употребляющие наркотики). График будет построен по 20-ти шкалам личностного Вопросника Р.Кеттелла.
Теперь надо в эту таблицу занести данные. Если данные клиента (выберите его сами, например, Тюрина Аня) можно сразу скопировать и вставить в указанную строку таблицы из листа «Данные по Кеттеллу», то строки Норма и Нарко должны содержать средние арифметические по каждой выборке. Для этого надо эти средние вычислить, что мы и делаем.
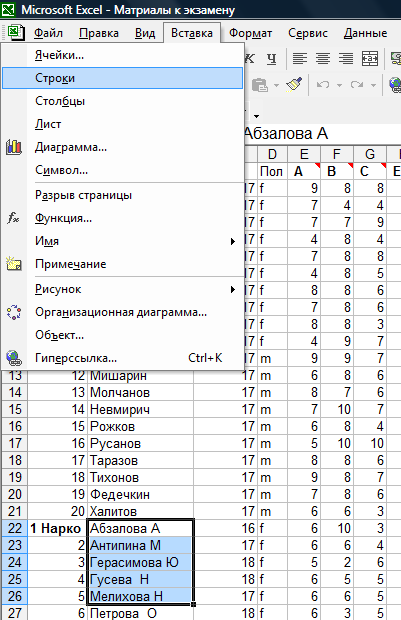
Заходим в лист Данные по Кеттеллу. Встаем в ячейку с адресом В:21. Она – на границе двух выборок (Нарко и Норма). Нам надо разделить эти две выборки. Разделение ведется вставкой нескольких строк между ними. Делается это так:
Встали по адресу В:21 – удерживая нажатой клавишу Shift, выделяем стрелкой вниз произвольное количество ячеек ниже (4 – 5), а затем щелкаем на линейке форматирования клавишу Вставка – строки. В итоге будет вставлено столько строк, сколько Вы выделилили ячеек. Вот как это выглядит перед вставкой:
 5. Теперь две выборки разлелены
пустыми строками. Встанем в первую
постую ячейку под показателем А (фактор
А по Кеттеллу) в выборке НОРМА. Эта ячейка
у нас по адресу Е:22. Шелкаем на линейке
форматирования (сверху) треугольничек
правее знака суммирования и выбираем
там опцию «среднее». Вот как проходит
выбор:
5. Теперь две выборки разлелены
пустыми строками. Встанем в первую
постую ячейку под показателем А (фактор
А по Кеттеллу) в выборке НОРМА. Эта ячейка
у нас по адресу Е:22. Шелкаем на линейке
форматирования (сверху) треугольничек
правее знака суммирования и выбираем
там опцию «среднее». Вот как проходит
выбор:
П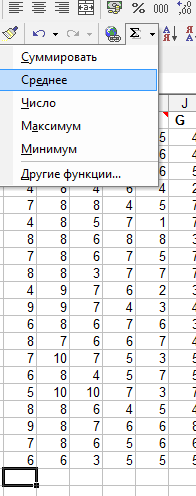 осле
щелчка по «среднее» образуется пунктир,
который показывает, по какому диапазону
данных будет вычислено среднее
арифметическое. Внимательно посмотрите
верхнюю и нижнюю ячейки диапазона. Если
все правильно – жмите ОК (Enter).
В итоге в ячейке Е:27 будет вычислено
среднее арифметическое.
осле
щелчка по «среднее» образуется пунктир,
который показывает, по какому диапазону
данных будет вычислено среднее
арифметическое. Внимательно посмотрите
верхнюю и нижнюю ячейки диапазона. Если
все правильно – жмите ОК (Enter).
В итоге в ячейке Е:27 будет вычислено
среднее арифметическое.
Что делать дальше? Либо повторять указанные операции для каждого столбца отдельно, либо искать более рациональный путь. 6. Обратите внимание – в правом нижнем углу ячейки Е:27, где уже содержится вычисленное среднее значение показателя А для выборки Норма, есть крестик. Совместите курсор мыши с этим крестиком, и Вы увидите, что курсор приобрел форму прямого чергого креста. Поймав этот момент, нажмите на левую клавишу мыши и, не отпуская ее, ведите по строке 27 вправо, до последнего столбца, по которому нужно получить средние. Не отпускайте левую клавишу мыши до тех пор, пока все не будет сделано точно. После этого клавишу можно отпустить – в итоге по всем столбцам будут вычислены средние. Вот как выглядит результат.
Теперь осталось выделить средние по всем факторам Кеттелла в этой выборке, скопировать их и вставить в нашу таблицу для построения графика. Внимание!
Вставка осуществляется следующим образом: Вставка – Специальная вставка – Значения. Иначе у Вас вставятся сплошные «диезы».
Вот первый итог:

Осталось сделать то же самое по выборке Нарко, а также перенести данные Тюриной Ани в строку Клиент.
Таблица готова к построению графика.

Теперь строим график. Для этого активизируем на линейке форматирования клавишу Мастер диаграмм. Вот эта клавиша:
 Если Мастер Вами не обнаружен, обратитесь
к преподавателю. После нажатия на
клавишу выпадает меню выбора типа
диаграмм, где Вы выбираете «график»,
Если Мастер Вами не обнаружен, обратитесь
к преподавателю. После нажатия на
клавишу выпадает меню выбора типа
диаграмм, где Вы выбираете «график»,
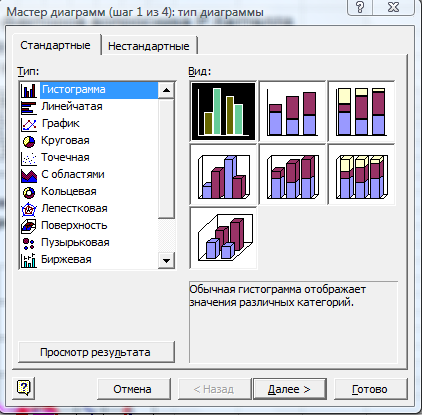
Затем среди меню выбора графиков выбираете именно тот, который открывается по умолчанию – График с маркерами, помечающими точки данных. Жмем кнопку Далее.
Открывается меню диапазона данных, по которому мы и строим график.
Теперь с помощью клавиш Shift и стрелок выделяем всю нашу таблицу, включая названия выборок и всех показателей. Этот диапазон будет обозначен пунктиром. Внимательно его осматриваем и принимаем. Если все нормально, нам уже будет показан черновой график. Вот такой:
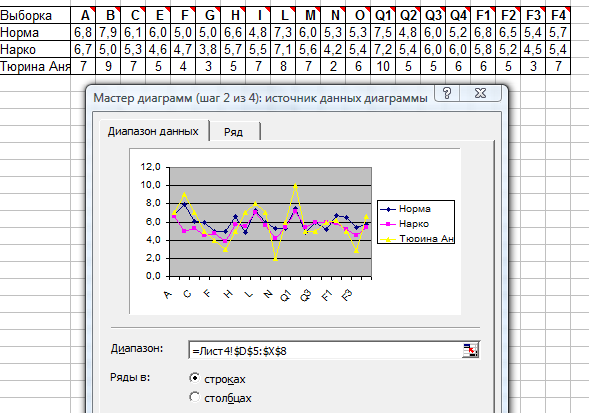
Жмем клавишу Далее и в выпавшем окне заполняем строки Название диаграммы, добавляем во вкладке Линии сетки Основные линии по оси Х, в окне Легенда располагаем легенду графика вверху (так удобнее и красивее). Наконец, жмем клавишу Далее, а затем на – Готово.
Вот наш промежуточный итог:
Г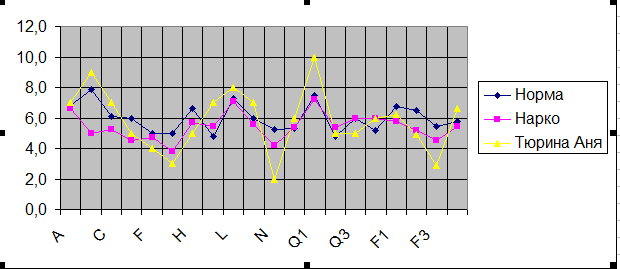 рафик
сильно отличается от образца, т.е. наш
результат еще форматировать и
форматировать. Переходим к следующему
этапу – этапу доводки графика до
совершенства.
рафик
сильно отличается от образца, т.е. наш
результат еще форматировать и
форматировать. Переходим к следующему
этапу – этапу доводки графика до
совершенства.
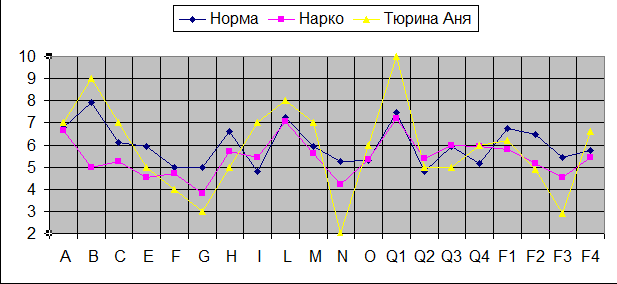
Что в этом черновом варианте плохо? Шкала баллов – от 0 до 12, а у Кеттелла она от 1 до 10-ти, да еще и десятичный знак после запятой. Фон графика – серый. Это приводит к плохой читаемости и затрате тонера при распечатках, т.е. неэкономично. Сами показатели приведены через один, а желательно, чтобы они все были. Слишком много места съедает легенда, лучше бы ее расположить сверху. Да и линии желательно изменить по цветам и их толщине. Например, самая ответственная линия клиента (Тюрина Аня) – желтым цветом. Желательно ее отметить особо – например, красным цветом. Итак, надо форматировать полученный черновой график.
Начинаем со шрифтов. Щелкаем правой клавишей мыши на любой точке белого поля графика, выделяя его (появляются черные квадратики по углам и центрам рамки). В выпавшем меню выбираем «Формат области диаграммы». Затем в выпавшем меню выбираем вкладку Шрифт и снимаем галочку в окошке Автомасштабирование. Если этого не сделать, при растягивании (увеличении графика) шрифты будут автоматически увеличиваться, а это лучше делать вручную. Вот как выглядит меню с убранной галочкой Автомастабирования.
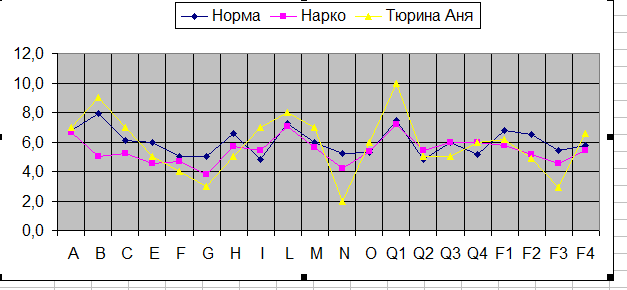
Получаем такой график
Теперь настроим ось ординат (баллов). Дважды щелкаем по любой точке оси ординат, например, по баллу 6,0. В выпавшем меню выбираем вкладку Число и ставим нулевое количество знаков после запятой (у нас пока один знак). Затем идем на вкладку Шкала и станавливаем минимальное значение 2, а максимальное – 10. Вот это меню с измененными данными:
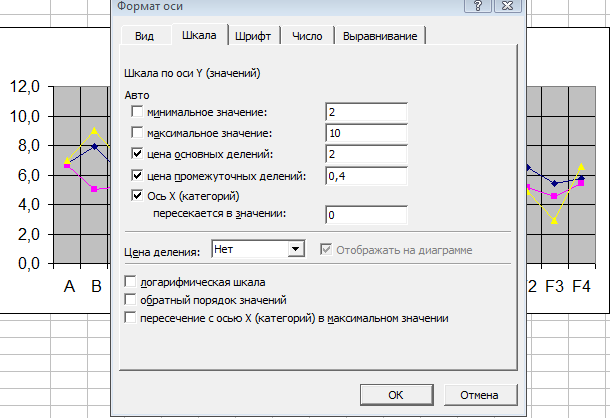
Жмем ОК – теперь на оси ординат нет нулей после запятой, а масштаб шкалы изменен на 2 – 10. Вот как это выглядит:
Теперь возьмемся за серый фон графика. Принцип тот же, что и раньше: что хотим изменить, по тому и щелкаем дважды левой клавишей мыши (т.е. по любой точке этой «серости»). В появившемся меню меняем цвет заливки на белый. Вот как это меню выглядит:
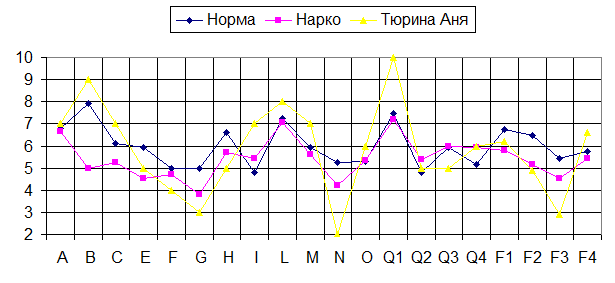
А вот и график после нажатия на ОК
Пришла очередь форматирования цвета и толщины линий. Среднее выборки НОРМА нас вполне устраивает, а профиль НАРКО пусть остается лиловым, но сделаем его потолще. Для этого, тщательно прицелившись курсором, дважды щелкаем по любой точке лиловой линии (но не по квадратному маркеру на этой линии). В выпавшем меню выбираем толщиту линии. Вот это меню
Жмем ОК, а затем так же настраиваем линию клиента. В нашем случае это жирная красная линия взамен желтой. Там же настраиваем и маркер (тоже красный с таким же фоном). Вот уже близкий к итоговому результат наших усилий:
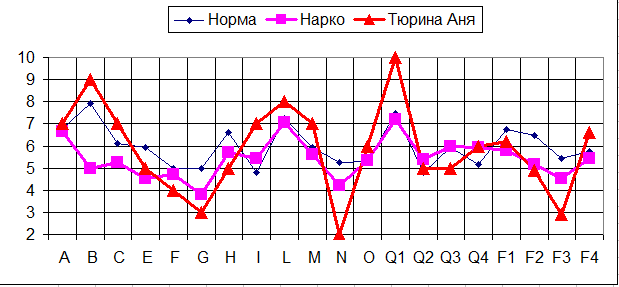
Но пропорции графика нарушены. Он слишком вытянут в длину. Обычно соотношение сторон должно быть близким к соотношению 5:4. Но и это легко настроить. Щелкаем левой клавишей мыши по белому полю левее легенды (или правее – это неважно). График выделится (появляютя черные квадратики по углам и центрам рамки).
Затем мы тянем левой клавишей мыши за один из этих черных квадратиков наш график. Он меняет свой размер. Только не увлекайтесь. В целом график должен сохранять исходные пропорции. Вот итог.
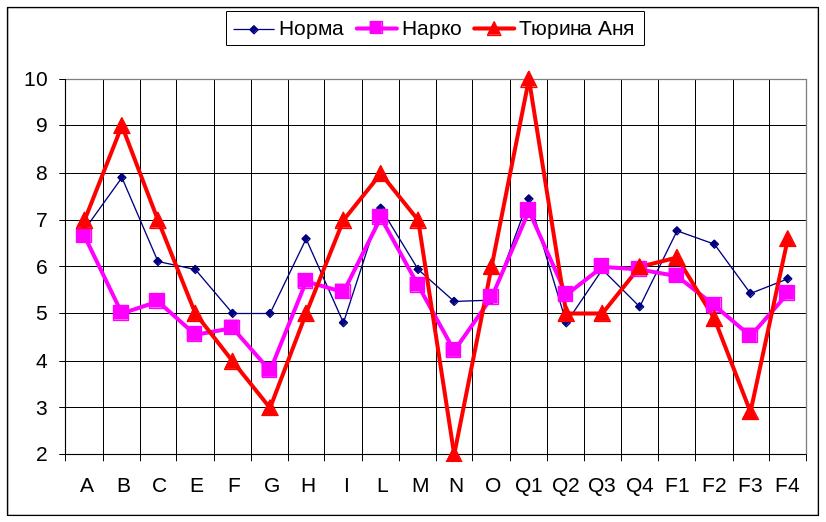
Теперь можно подобрать название графику и продумывать стратегию и тактику консультации данного клиента.
При этом особое внимание уделяется на повышенные и пониженные показатели тех или иных диагностических шкал. У Ани Тюриной это – фактор В (интеллект) – 9 баллов, фактор L (подозрительность, недоверчивость), фактор N ( сдержанность, проницательность), Q1(радикализм, мятежность, склонность к нестандартному поведению), G (добросовестность, ответственность) и F3 (уравновешенность). Т.е. наша клиентка - высокоинтеллектуальна, критична и недоверчива, неуравновешенна, мятежна. Кроме того, ее отличает недобросовестность и безответственность. Конечно, такой профиль имеет как сильные, так и слабые стороны по отношению к ситуации (лечение в наркодиспансере).
Продумайте тактику своего поведения в работе с этим клиентом.
Поупражняйтесь с построением графиков других клиентов. Для этого в таблицу, на основе которой график строился, достаточно скопировать фамилию нового клиента и его данные. График автоматически изменится.