

Понятие компилятора. Этапы анализа исходной программы.
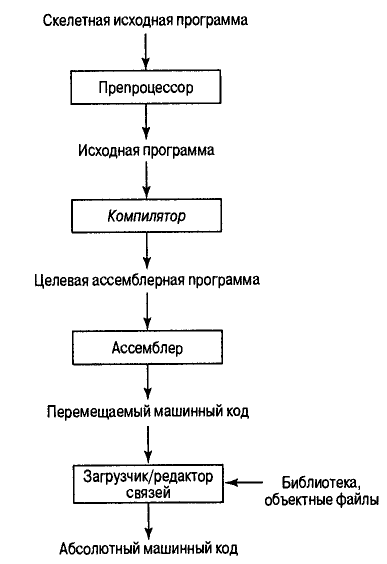
При компиляции анализ состоит из трех фаз:
Линейный анализ, при котором поток символов исходной программы считывается слева направо и группируется в токены (token), представляющие собой последовательности символов с определенным совокупным значением. В компиляторах линейный анализ называется лексическим, или сканированием.
Иерархический анализ, при котором символы или токены иерархически группируются во вложенные конструкции с совокупным значением. Иерархический анализ называется разбором (parsing), или синтаксическим анализом, который включает группирование токенов исходной программы в грамматические фразы, используемые компилятором для синтеза вывода. Обычно грамматические фразы исходной программы представляются в виде дерева.
Семантический анализ, позволяющий проверить, насколько корректно совместное размещение компонентов программы. В процессе семантического анализа проверяется наличие семантических ошибок в исходной программе и накапливается информация о типах для следующей стадии — генерации кода. При семантическом анализе используются иерархические структуры, полученные во время синтаксического анализа для идентификации операторов и операндов выражений и инструкций.
Важным аспектом семантического анализа является проверка типов, когда компилятор проверяет, что каждый оператор имеет операнды допустимого спецификациями языка типа.
Понятие компилятора. Лексический анализ.
Лексический анализатор представляет собой первую фазу компилятора. Его основная задача состоит в чтении новых символов и выдаче последовательности токенов, используемых синтаксическим анализатором в своей работе. На рисунке схематически показано взаимодействие лексического и синтаксического анализаторов, которое обычно реализуется путем создания лексического анализатора в качестве подпрограммы синтаксического анализатора (или подпрограммы, вызываемой им). При получении запроса на следующий токен лексический анализатор считывает входной поток символов до точной идентификации следующего токена.
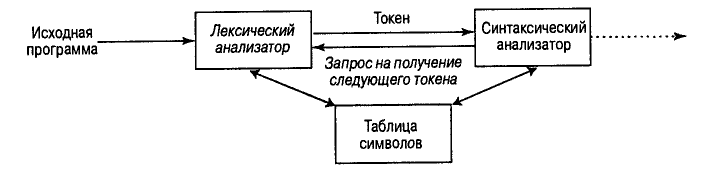
Поскольку лексический анализатор является частью компилятора, которая считывает исходный текст, он может также выполнять некоторые вторичные задачи интерфейса. К ним, например, относятся удаление из текста исходной программы комментариев и не несущих смысловой нагрузки пробелов (а также символов табуляции и новой строки). Еще одна задача состоит в согласовании сообщений об ошибках компиляции и текста исходной программы. В некоторых компиляторах лексический анализатор создает копию текста исходной программы с указанием ошибок. Если исходный язык поддерживает макросы и директивы препроцессора, то они также могут реализовываться лексическим анализатором.
Зачастую работа лексического анализатора состоит из двух фаз — сканирования и лексического анализа. Фаза сканирования отвечает за выполнение простейших задач, в то время как на фазу лексического анализа возлагаются задачи более сложные.
Задачи лексического анализа
Имеется ряд причин, по которым фаза анализа компиляции разделяется на лексический и синтаксический анализы.
Пожалуй, наиболее важной причиной является упрощение разработки. Отделение лексического анализатора от синтаксического часто позволяет упростить одну из фаз анализа.
Увеличивается эффективность компилятора. Отдельный лексический анализатор позволяет создать специализированный и потенциально более эффективный процессор для решения поставленной задачи. Поскольку на чтение исходной программы и разбор ее на токены тратится много времени, специализированные технологии буферизации и обработки токенов могут существенно повысить производительность компилятора.
Увеличивается переносимость компилятора. Особенности входного алфавита и другие специфичные характеристики используемых устройств могут ограничивать возможности лексического анализатора.
Токены, шаблоны, лексемы
Говоря о лексическом анализе, мы используем термины "токен", "шаблон" и "лексема" каждый в своем собственном смысле. Вообще говоря, во входном потоке существует набор строк, для которых в качестве выхода получается один и тот же токен. Этот набор строк описывается правилом, именуемым шаблоном (pattern), связанным с токеном. О шаблоне говорят, что он соответствует (match) каждой строке в наборе. Лексема же представляет собой последовательность символов исходной программы, которая соответствует шаблону токена.
Мы рассматриваем токены как терминальные символы грамматики исходного языка (используя выделение полужирным шрифтом). Лексемы, соответствующие шаблонам токенов, представляют в исходной программе строки символов, которые рассматриваются вместе как лексическая единица.
В большинстве языков программирования в качестве токенов выступают ключевые слова, операторы, идентификаторы, константы, строки литералов и символы пунктуации, например скобки, запятые и точки с запятыми.
Шаблон— правило, описывающее набор лексем, которые могут представлять определенный токен в исходной программе.