

Шинно-мостовая архитектура
В шинно-мостовой архитектуре имеется центральная магистральная шина, к которой остальные компоненты подключаются через мосты. В роли центральной магистрали сначала выступала шина (E)ISA, затем ее сменила шина PCI. Шинно-мостовая архитектура чипсетов просуществовала долгое время и пережила много поколений процессоров (от 2-го до 7-го). Перемещение вторичного кэша с системной платы на процессор (Р6 и Pentium 4 у Intel и К7 у AMD) несколько упростило северную часть чипсета — в ней не надо управлять статической кэш-памятью, а остается лишь обеспечивать когерентность процессорного кэша с основной памятью, доступ к которой возможен и со стороны шины PCI.
Шина PCI в роли главной магистрали удержалась недолго: видеокартам с ЗD-акселератором ее пропускной способности, разделяемой между всеми устройствами, оказалось недостаточно. Тогда и появился порт AGP как выделенный мощный интерфейс между графическим акселератором и памятью (а также процессором). При этом задачи северного моста усложнились: контроллеру памяти приходится работать уже на три фронта — ему посылают запросы процессор, мастера шины PCI (и ISA, но тоже через PCI) и порт AGP. Пропускная способность AGP в режиме 2х/4х/8х составляет 533/1066/2133 Мбайт/с, так что шина PCI по производительности стала уже второстепенной. Однако в шинно-мостовой архитектуре она сохраняет свою роль магистрали подключения всех периферийных устройств (кроме графических). В качестве мощного представителя шинно-мостовой архитектуры можно рассматривать чипсет AMD-760. Здесь имеются первичная шина PCI на 64 бит и 66 МГц, являющаяся «экватором», и вторичная шина для подключения рядовой периферии.
Шина, к которой подключается множество устройств, является узким местом по ряду причин. Во-первых, из-за большого числа устройств, подключенных (электрически) к шине, не удается поднять тактовую частоту до уровня, достижимого в двухточечных соединениях. Во-вторых, шина, к которой подключается множество разнотипных устройств (особенно расположенных на картах расширения), обременена грузом обратной совместимости со старыми периферийными устройствами. Например, предусмотренные возможности повышения производительности PCI используются не всегда: расширение разрядности до 64 бит обходится слишком дорого (большое число проводников порождает свои проблемы), а повышение частоты до 66 МГц для шины возможно лишь если все ее абоненты поддерживают эту частоту. Достаточно установить одну «простую» карту PCI, и производительность центральной шины падает до начальных 133 Мбайт/с. То же можно сказать и о PCI-X: достаточно подключить к ней одно устаревшее устройство PCI, и все протокольные усовершенствования будут отменены.
Хабовая архитектура
С введением высокоскоростных режимов UltraDMA (ATA/66, ATA/100, а затем и AT А/133) связь двухканального контроллера IDE с памятью через шину PCI стала уже слишком сильно нагружать эту шину. Кроме того, появились высокоскоростные интерфейсы Gigabit Ethernet, FireWire (100/200/400/800 Мбит/с) и USB 2.0 (480 Мбит/с). Ответом на эти изменения в расстановке сил стал переход на хабовую архитектуру чипсета. В данном контексте хабы — это специализированные микросхемы, обеспечивающие передачу данных между своими внешними интерфейсами. Этими интерфейсами являются «прикладные» интерфейсы подключения процессоров, модулей памяти, шин расширения и периферийные интерфейсы (ATA, SATA, USB, FireWire, Ethernet). Поскольку к одной микросхеме все эти интерфейсы не подключить (слишком сложна структура и много требуется выводов), чипсет строится, как правило, из пары основных хабов (северного и южного), связанных между собой высокопроизводительным каналом.
Северный хаб чипсета выполняет те же функции, что и северный мост шинно-мостовой архитектуры: он связывает шины процессора, памяти и порта AGP. Однако на южной стороне этого хаба находится уже не шина PCI, а высокопроизводительный интерфейс связи с южным хабом. Пропускная способность этого интерфейса составляет 266 Мбайт/с и выше, в зависимости от чипсета. Если чипсет имеет интегрированную графику, то в северный хаб входит и графический контроллер со всеми своими интерфейсами (аналоговыми и цифровыми интерфейсами дисплея, шиной локальной памяти). Чипсеты с интегрированным графическим контроллером могут иметь внешний порт AGP, который становится доступным при отключении встроенного графического контроллера. Есть чипсеты, у которых порт AGP является чисто внутренним средством соединения встроенного контроллера, и внешний графический контроллер к ним может подключаться только по шине PCI.
С появлением PCI-E архитектура не слишком изменилась: северный хаб (мост) вместо порта AGP теперь предлагает высокопроизводительный (8х или 16х) порт, а то и пару портов PCI-E для подключения графического адаптера. Маломощные (1х) порты PCI-E могут предоставляться как северным, так и южным хабами (это решает разработчик чипсета). В последнем случае корневой комплекс PCI-E «расползается» по двум микросхемам чипсета, связанным между собой «фирменным» интерфейсом. Использования PCI-E как единой коммуникационной базы внутри чипсета пока не наблюдается
2. PCI EXPRESS
Итак, новая последовательная шина, которой предписывалось решить все проблемы компьютерной отрасли разом, получила название PCI Express - это случилось 22 июля 2002 года. Во-первых, новая шина теоретически должна выступить в качестве основного транспорта между всеми, без исключения, узлами компьютера
PCI Express - последовательный интерфейс, имеющий много общего с сетевой организацией обмена данными
Имея последовательно-сетевую природу, стек PCI Express разделен на три уровня: аппаратный (Physical - физический), аппаратно-логический (Data link - передача данных) и логический (Transaction - транзакции).
Уже не раз говорилось, что стандарт PCI Express «исповедует» последовательную передачу данных. На аппаратном уровне реализовано разностное усиление сигнала (сигнальный уровень PCI Express составляет 0,8 В): по одному проводнику передается положительное аналоговое представление сигнала, по второму - отрицательное. Разностный приемник сигнала на другом конце линии инвертирует принятый сигнал и складывает с сигналом, прибывшим по другому проводнику, поэтому, если где-либо сигнал был «разбавлен» помехой (которая подвергла воздействию оба проводника), то она сама себя нивелирует.
PCI Express построен на принципах симплексной технологии, а это означает, что сигналы идут одновременно, в противоположных направлениях и по отдельным парам проводов - итого две пары, называемые линией. Стандарт декларирует пропускную способность симплексной линии на отметке 2,5 Гбит/с в одну сторону или, соответственно, 5 Гбит/с в обе стороны. Однако эти значения масштабируемы.
Билет5.
1.арифметические операции над плавающей запятой
X1=q1*2^p1
X2=q2*2^p2
1)Сложение или вычитание
При (+)(-) чисел с разными порядками реализуется следующая последовательность операций:
Сравнение и выравнивание порядков
Сложение или вычитание мантисс
Нормализация результата
2)умножение
А)умножение мантисс
Б) сложение порядков
3)деление
X1/x2=q1/q2 *2^(p1-p2) + нормализация результата
2.Локальные шины
Через локалную шину центральный процессор компьютера получает непосредственный доступ к периферийным устройствам
ЛОКАЛЬНАЯ ШИНА PCI
КОМПАНИИ INTEL
По случайному совпадению компания Intel анонсировала свою спецификацию шины PCI тоже в июне 1992г. на выставке PC Expo.
Локальная шина компании Intel - типичная внутренняя шина, которая позволяет изготовителям комплексного оборудования устанавливать компоненты непосредственно на системную плату, минуя шину ЦП-память. Спецификация требует, чтобы сопряжение ЦП и подключаемого переферийного устройства проводилось с помощью так называемой мостовой (Bridge) интегральной схемы.
Такое решение, как указывает Майкл Бейли, менеджер по маркетингу средств PCI компании Intel, обеспечивает необходимую для ввода-вывода пропускную способность и в то же время не задерживает работу ЦП. Процессор при этом может работать с основной памятью на полной скорости.
Специалисты компании Intel говорят, что PCI - это мультиплексная 32-разрядная шина, предусматривающая расширение до 64-х разрядов. Шина способна работать в синхронном режиме на частотах до 33 Мгц. Для 32-разрядного варианта шины пропускная способность составляет 132 Мбайт/c.
При обмене данными ЦП получает непосредственный доступ к подключенным к шине PCI устройствам, которые могут распологаться в адресном пространстве памяти или в пространстве устройства ввода-вывода. В режиме захвата шины главные абоненты шины PCI получают прямой доступ к основной памяти. Мостовая интегральная схема тоже может обеспечивать факультативные функции буферизации и централизованного арбитража шины.
Тип соеденителя для печатных плат спецификации PCI в явном виде не определен, однако компания Intel заявляет, что при разработке этой спецификации она ориентировалась на конкретный тип разьема. В будущем в спецификацию планируется включить требования к средствам управления мощьностью потребления для машин с батарейным питанием и схемам управления напряжением питания для низковольтных микросхем.
Билет 6.
Кодирование чисел с учётом знака
Три кода:
прямой
Обратный
Дополнительный
1.[+-X]пр –прямой код
Если число положительно, то впереди стоит 0,если отрицательное, то 1
Информация хранится в памяти жёсткого диска
2. .[+-X]обр
.[+X]пр=.[+X]обр=.[+X]доп
3. .[+-X]доп
Для получения обратного кода необходимо взять обратный и к младшему разряду прибавить +1
*Сложение производится либо в обратных либо в дополнительных кодах.*
Примеры.
Механизм прерывания
Прерывание - это прекращение выполнения текущей команды или текущей последовательности команд для обработки некоторого события специальной программой - обработчиком прерывания, с последующим возвратом к выполнению прерванной программы. Событие может быть вызвано особой ситуацией, сложившейся при выполнении программы, или сигналом от внешнего устройства. Прерывание используется для быстрой реакции процессора на особые ситуации, возникающие при выполнении программы и взаимодействии с внешними устройствами.
Механизм прерывания обеспечивается соответствующими аппаратно-программными средствами компьютера.
Любая особая ситуация, вызывающая прерывание, сопровождается сигналом, называемым запросом прерывания (ЗП). Запросы прерываний от внешних устройств поступают в процессор по специальным линиям, а запросы, возникающие в процессе выполнения программы, поступают непосредственно изнутри микропроцессора. Механизмы обработки прерываний обоих типов схожи. Рассмотрим функционирование компьютера при появлении сигнала запроса прерывания, опираясь в основном на обработку аппаратных прерываний (рис. 14.1).
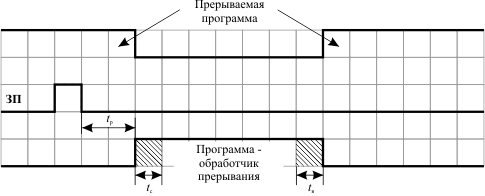
Рис. 14.1. Выполнение прерывания в компьютере: tр - время реакции процессора на запрос прерывания; tс - время сохранения состояния прерываемой программы и вызова обработчика прерывания; tв - время восстановления прерванной программы
После появления сигнала запроса прерывания ЭВМ переходит к выполнению программы - обработчика прерывания. Обработчик выполняет те действия, которые необходимы в связи с возникшей особой ситуацией. Например, такой ситуацией может быть нажатие клавиши на клавиатуре компьютера. Тогда обработчик должен передать код нажатой клавиши из контроллера клавиатуры в процессор и, возможно, проанализировать этот код. По окончании работы обработчика управление передается прерванной программе.
Время реакции - это время между появлением сигнала запроса прерывания и началом выполнения прерывающей программы (обработчика прерывания) в том случае, если данное прерывание разрешено к обслуживанию.
Время реакции зависит от момента, когда процессор определяет факт наличия запроса прерывания. Опрос запросов прерываний может проводиться либо по окончании выполнения очередного этапа команды (например, считывание команды, считывание первого операнда и т.д.), либо после завершения каждой команды программы.
Первый подход обеспечивает более быструю реакцию, но при этом необходимо при переходе к обработчику прерывания сохранять большой объем информации о прерываемой программе, включающей состояние буферных регистров процессора, номера завершившегося этапа и т.д. При возврате из обработчика также необходимо выполнить большой объем работы по восстановлению состояния процессора.
Во втором случае время реакции может быть достаточно большим. Однако при переходе к обработчику прерывания требуется запоминание минимального контекста прерываемой программы (обычно это счетчик команд и регистр флагов). В настоящее время в компьютерах чаще используется распознавание запроса прерывания после завершения очередной команды.
Время реакции определяется для запроса с наивысшим приоритетом.
Глубина прерывания - максимальное число программ, которые могут прерывать друг друга. Глубина прерывания обычно совпадает с числом уровней приоритетов, распознаваемых системой прерываний. Работа системы прерываний при различной глубине прерываний (n) представлена на рис. 14.2. Здесь предполагается, что с увеличением номера запроса прерывания увеличивается его приоритет.

Рис. 14.2. Работа системы прерываний при различной глубине прерываний
Без учета времени реакции, а также времени запоминания и времени восстановления:
t11+t12=t1,
t21+t22=t2.
Билет 7.
1.Представление информации в ЭВМ
Наличие двух различных сигналов
Наличие высокого\низкого уровня напряжения(потенциальный способ)
Отсутствие или наличие электрического импульса (импульсный способ)
Противоположные по знаку значения магнитного инд.(жёсткий диск, дискеты)
Графики
1) Потенц

Время такта = Tn+1-Tn
2)Импульсы

2.Стековая память
Стековая память является безадресной. Стековая
память может быть организована как аппаратно, так и на обычном массиве адресной памяти.
Запись в стековую память и чтение из нее производится по принципу магазина автомата Калашникова. Патроны в такой магазин вставляются через входное отверстие один за другим. Извлекаются патроны из магазина в обратном порядке по принципу «последний зашел — первый вышел». Стековую память очень часто используют при программировании. Особенно удобно использовать стек для сохранения данных при входе в подпрограмму и восстановления их перед выходом. В дальнейшем мы убедимся в этом на примерах. В настоящий же момент я хочу остановиться на методах организации стековой памяти.
Перед началом работы в указатель стека необходимо записать адрес вершины стека. Это некий адрес ячейки ОЗУ, которая является старшей ячейкой области памяти, выделенной под стек. Определять размер стековой памяти и адрес ее вершины должен сам программист.
Для работы со стеком в системе команд микроконтроллера есть две специальные команды:
- команда записи в стек (push);
- команда извлечения из стека (pop).
Выполняя команду push, микроконтроллер записывает содержимое одного из РОН в ОЗУ по адресу, на который указывает указатель стека, а затем уменьшает значение указателя на единицу. Новая команда push запишет значение другого РОН в следующую ячейку ОЗУ. А указатель передвинется еще дальше. Таким образом происходит заполнение стека.
Выполняя команду pop, микроконтроллер сначала увеличивает содержимое указателя стека на единицу, а затем извлекает содержимое ячейки ОЗУ, на которое указывает указатель. Считанное значение помещается в один из РОН(Регистры общего назначения ). В результате из стека считывается последнее записанное туда число. Следующая команда pop опять сначала увеличит указатель стека и прочитает предпоследнее записанное туда число. Благодаря регистру-указателю стека и описанному выше алгоритму реализуется полноценная стековая память.Сразу после сброса микроконтроллера содержимое указателя стека равно нулю. Если оставить это содержимое без изменений, то все команды, связанные со стеком, работать не будут
Билет 8.
1.логические элементы ЭВМ
Чтобы понять работу компьютера используют алгебру логики.
Мат. Логика-высказывания (истина \ ложь), связи, ист-1 ложь-0.
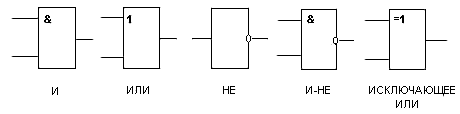
Логические элемент- схема или устройство, реализующее элементарные логические операции над логическими переменными.
1.Не –отрицание
Повторение y=x ,к у можно подключить более сильный источник
Сложение(дизъюнкция) «или»
Умножение (Конъюнкция) «И»
«ИЛИ-НЕ»
«И-НЕ»
Исключающее ИЛИ ; Сумма по модулю неравнозначности(?)
«НЕИСКЛЮЧАЮЩЕЕ ИЛИ» Разнозначность(сравнение)
2.порты ввода/вывода ПК
Порты устройств представляют собой некие электронные схемы, содержащие один или несколько регистров ввода-вывода и позволяющие подключать периферийные устройства компьютера к внешним шинам микропроцессора.
Примеры портов:
COM (последовательный порт)
LTP (параллельный порт)
USB (последовательный с высокой производительностью)
PS/2 (универсальный для подключения мыши и клавиатуры)
Через последовательные порты данные передаются последовательно байт за байтом. Предельное значение производительности последовательного порта - 112 Кбит/с. Этого недостаточно для передачи больших объемов данных, поэтому к последовательным портам подключают устройства, не требующие высокой производительности: модемы, мыши, устаревшие модели принтеров.
Через параллельный порт передаются одновременно все восемь битов, составляющих один байт. Предельное значение производительности параллельного порта - 5 Мбайт/с. К этому порту, как правило, подключается принтер.
Преимущество параллельного порта от последовательного заключается еще в возможности использования более длинных кабелей для соединения (до 10 м против 1.5 м).
Все современные компьютеры комплектуются портами нового поколения - USB. Это порты последовательного типа, но с высокой производительностью (до 12 Мбайт/с). Кроме высокой производительности к достоинствам USB портов относится удобство работы с ними: не требуется выключать оборудование перед стыковкой, возможно подключение нескольких устройств в одному порту. Многие модели современной периферийного оборудования могут подключаться к портам этого типа.
Кроме универсальных коммуникационных портов, предназначенных для любого оборудования, компьютер имеет два специализированных порта для подключения мыши и клавиатуры - это порты PS/2. Другие устройства к этим портам не подключаются
Билет 9.
1.Комбинационная схема для нахождения булевой ф-ции
Этапы построения логической функции
Правила нахождения аналитической функции, образование СДНФ(совершенной дизъюнктивной нормальной формы)
СДНФ - Это логическое выражение, в которое входят наборы элементарных конъюнкций одинакового ранга, связанных дизъюнкцией
Ранг-число аргументов
Составляем таблицу истинности
По каждому набору двоичных переменных, при которых фунеция принимает значение 1, составляем элементарные конъюнкции(минтермы)
Элементы строки конъюнкции записываются неинвертированными переменными, заданными 1 в таблице истинности. Переменные, заданные 0 в таблице истинности записывают инвертируемыми
Элементарные конъюнкции соединяют знаком дизъюнкции
2.Организация ОЗУ с произвольным доступом
ОЗУ или оперативное запоминающее устройство - это важный компонент любой компьютерной системы. ОЗУ - это память, предназначенная для хранения часто используемой информации для того, чтобы у компьютера был к ней быстрый доступ. По сравнению с жёстким диском компьютеру быстрее и легче иметь доступ к ОЗУ.
Оперативная память (RAM - Random Access Memory) - это массив кристаллических ячеек, способных хранить данные. Существует много различных типов оперативной памяти, но с точки зрения физического принципа действия различают динамическую память (DRAM) и статическую память (SRAM).
Ячейки динамической памяти (DRAM) можно представить в виде микроконденсаторов, способных накапливать заряд на своих обкладках. Это наиболее распространенный и экономически доступный тип памяти. Недостатки этого типа связаны, во-первых, с тем, что как при заряде, так и при разряде конденсаторов неизбежны переходные процессы, то есть запись данных происходит сравнительно медленно. Второй важный недостаток связан с тем, что заряды ячеек имеют свойство рассеиваться в пространстве, причем весьма быстро. Если оперативную память постоянно не <подзаряжать>, утрата данных происходит через несколько сотых долей секунды. Для борьбы с этим явлением в компьютере происходит постоянная регенерация (освежение, подзарядка) ячеек оперативной памяти.
Ячейки статической памяти (SRAM) можно представить как электронные микроэлементы - триггеры, состоящие из нескольких транзисторов. В триггере хранится не заряд, а состояние (включен/выключен), поэтому этот тип памяти обеспечивает более высокое быстродействие, хотя технологически он сложнее и, соответственно, дороже.
Оперативная память (ОЗУ, англ. RAM, Random Access Memory — память с произвольным доступом) — это быстрое запоминающее устройство не очень большого объёма, непосредственно связанное с процессором и предназначенное для записи, считывания и хранения выполняемых программ и данных, обрабатываемых этими программами.
Термин “память с произвольным доступом” (random access memory – RAM) применяют к ЗУ, в которых выбор места хранения информации производится непосредственным подключением входов и выходов элементов памяти (через буферы, усилители и логические элементы) к входным и выходным шинам ЗУ. Это наиболее быстрый вид адресного доступа, применяемый в оперативных ЗУ и кэш-памяти
Регистровая КЭШ-память
КЭШ-память (регистровая) – высокоскоростная память сравнительно
большой емкости, являющаяся буфером между основной памятью и
микропроцессорной памятью и позволяющая увеличить скорость выполнения
операций. Регистры КЭШ-памяти недоступны для пользователя, отсюда и
название – КЭШ (Cache – ォтайникサ).**
Билет 10.
1.Ассинхронный RS триггер
Однотактный асинхронный RS-триггер.
Простейшим триггером является асинхронный RS -триггер, вариант схемы которого изображен на рис.1.2.
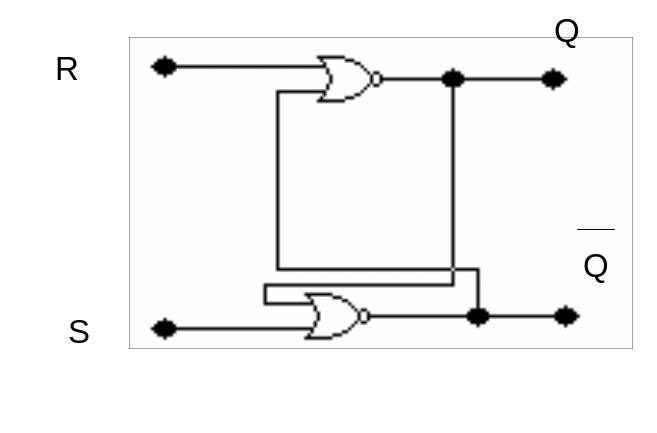
Рис 1.2
На рис.2.2 представлено условное изображение RS- триггера.
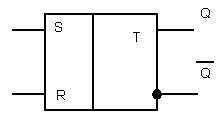
Рис.2.2
Этот триггер устанавливается в состоянии 1 (Q=1) информационными сигналами S=1; R=0 и в состоянии О (Q=0) сигналами S=0, R=1. Комбинация сигналов R=S=1 является запрещенной, т.к. состояние триггера не определено. Триггер является асинхронным, т.к. переход из одного состояния в другое происходит в темпе поступления входных информационных сигналов R, S. Таблица 1 отражает процесс перехода триггера из одного устойчивого состояния в другое. В ней содержатся значения текущих информационных сигналов Rt, St, Qt, а так же значение последующего выходного сигнала Qt+1 после момента прихода информационных сигналов R и S.
Таблица 1
St |
Rt |
Qt. |
Qt+1. |
0 |
1 |
о |
о |
0 |
1 |
1 |
о |
1 |
0 |
о |
1 |
1 |
0 |
1 |
1 |
0 |
0 |
о |
о |
0 |
0 |
1 |
1 |
1 |
1 |
|
не определено |
2.Организация ОЗУ с линейной выборкой
Пословная организация с линейной выборкой. В простейшем случае матрица памяти имеет пословную организацию с линейной выборкой. Другими словами, длина столбцов матрицы памяти совпадает с числом слов, а длина строки-с числом битов в слове. Для выборки слов используется дешифратор с взаимоисключающими выходными сигналами для каждого слова памяти. Для каждого входного адреса такой дешифратор выбирает одно и только одно слово в матрице памяти. Метод линейной выборки, отличаясь в принципе простотой, требует для большого числа слов большого дешифратора
Билет 11.
Синхронный RS триггер
Однотактный синхронный RS- триггер.
В отличие от асинхронного этот триггер на каждом информационном входе имеет дополнительные схемы совпадения, первые входы которых объединены и на них подаются синхронизирующие сигналы (рис. 3.2). Вторые входы схем совпадения являются информационными.
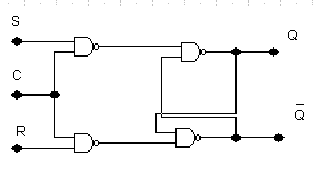
Рис 3.2
Наличие схем совпадения приводит к тому, что триггер будет срабатывать от сигналов R и S только при наличие синхросигнала. Условное изображение данного триггера показано на Рис. 4.2
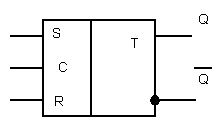 Рис
4.2
Рис
4.2
Организация ОЗУ с пространственной выборкой
???
Билет 12.
1.Т-триггер