

1,С1sс и risс процессоры. Особенности. Сравнительная характеристика.
Уровень архитектуры команд включает набор машинных команд, которые выполняются микропрограммой-интерпретатором или аппаратным обеспечением.
Двумя основными архитектурами набора команд, используемыми компьютерной промышленностью на современном этапе развития вычислительной техники, являются архитектуры CISC и RISC.
CISC
– Complete Instruction Set Computer (CISC-архитектура, компьютер на микропроцессоре с полным набором команд)
RISC
– Reduced Instruction Set Computer (RISC-архитектура, компьютер с сокращенным набором команд)
2,Wliv процессоры. Особенности. Отличие от сisс и risс процессоров.
VLIW (англ. very long instruction word — «очень длинная машинная команда») — архитектура процессоров с несколькими вычислительными устройствами. Характеризуется тем, что одна инструкция процессора содержит несколько операций, которые должны выполняться параллельно. Фактически это «видимое программисту» микропрограммное управление, когда машинный код представляет собой лишь немного свёрнутый микрокод для непосредственного управления аппаратурой.
Ключевым отличием от суперскалярных CISC-процессоров является то, что для них загрузкой исполнительных устройств занимается часть процессора (планировщик), на что отводится достаточно малое время, в то время как загрузкой вычислительных устройств для VLIW-процессора занимается компилятор, на что отводится существенно больше времени (качество загрузки и, соответственно, производительность теоретически должны быть выше). Примером VLIW-процессора является Intel Itanium.
VLIW можно считать логическим продолжением идеологии RISC, расширяющей её на архитектуры с несколькими вычислительными модулями. Так же, как в RISC, в инструкции явно указывается, что именно должен делать каждый модуль процессора. Из-за этого длина инструкции может достигать 128 или даже 256 бит.
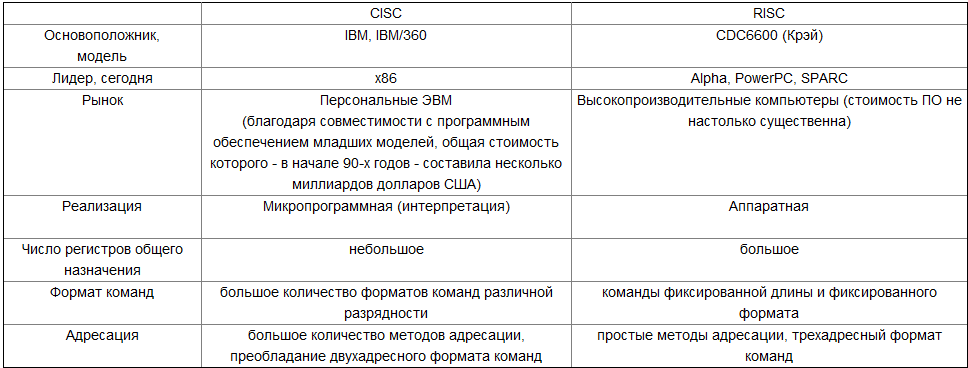
3,Развитие wliv технологии в процессорах с явным параллелизмом выполнения команд. Связка команд. Формат команды wliv. Потоковые процессоры.
Формат команды:
4,Этап повышения производительности процессора - конвейер. Идеальный конвейер и недостатки реального конвейера. Длина конвейера.
К онвейер
позволяет найти компромис между временем
ожидания ( время выполнения одной
команды) и пропускной способностью
процессора (сколько миллионов команд
в секунду выполняет процессор). Если
время цикла Тнс, а конвейер содержит н
стадий, товремя ожидания составит н*Т
нс, а пропускная способность 1000/Т млн
команд в секунду. На рис.3.1а цикл 2 нс
время выполнения команды 10 нс,
производительность 100 млн операций в
сек.
онвейер
позволяет найти компромис между временем
ожидания ( время выполнения одной
команды) и пропускной способностью
процессора (сколько миллионов команд
в секунду выполняет процессор). Если
время цикла Тнс, а конвейер содержит н
стадий, товремя ожидания составит н*Т
нс, а пропускная способность 1000/Т млн
команд в секунду. На рис.3.1а цикл 2 нс
время выполнения команды 10 нс,
производительность 100 млн операций в
сек.
Оценка производительности идеального конвейера:
Предположим Твк=20; Тдк=15; Твд=20; Тик=25; Тзр=20;
t = 5 – промежуточное время определяемое необходимостью записи промежуточных результатов.
Тогда время такта
Т = max{Твк=20; Тдк=15; Твд=20; Тик=25; Тзр=20} + t = 30
При последовательной обработке время выполнения N команд:
Т посл.= N*(Твк + Тдк + Твд + Тик + Тзр) = 100N
Т конв.= 5*Т+ (N-1) * Т
N=10 Тпосл.=1000 Тконв.=420
N=100 Тпосл.=10000 Тконв.=3120
5.
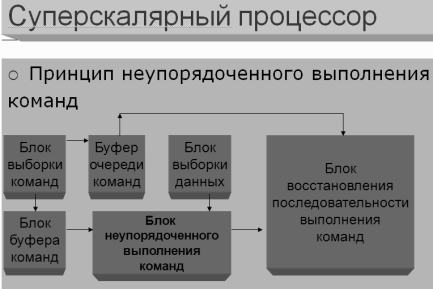 Динамическое
прогнозирование переходов:
Динамическое
прогнозирование переходов:
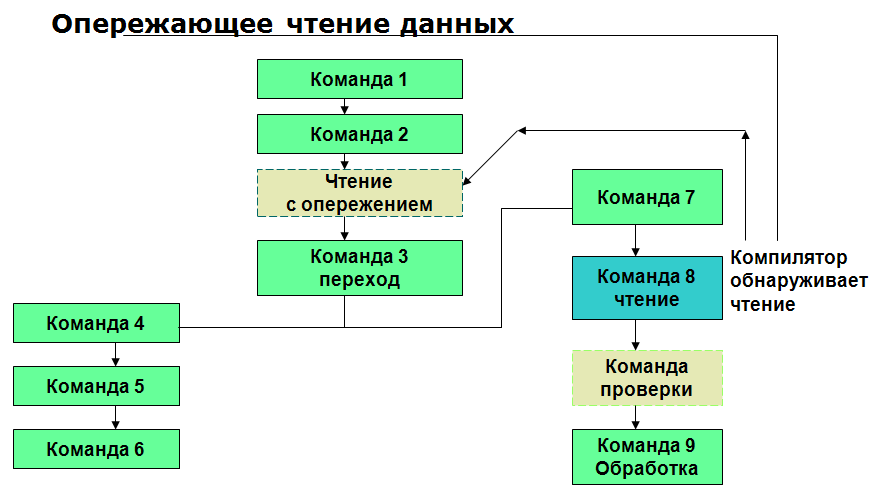
Спекулятивное выполнение:
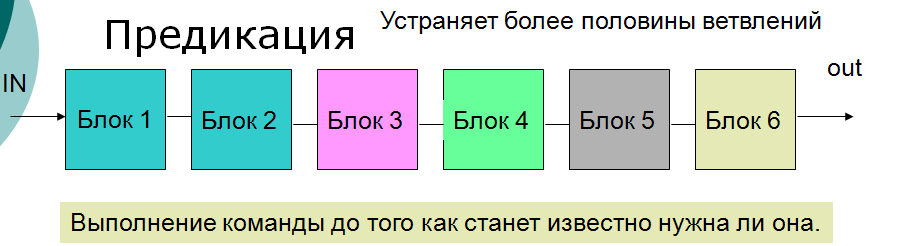
Проблема суперскальных МП: Простои конвейеров из-за нерегулярной загрузки функциональных устройств МП. Наличие одного счетчика команд. Ограничение на количество конвейеров и функциональных устройств МП – непропорциональное усложнение структуры. Одновременное исполнение нескольких программ только в режиме разделения времени.
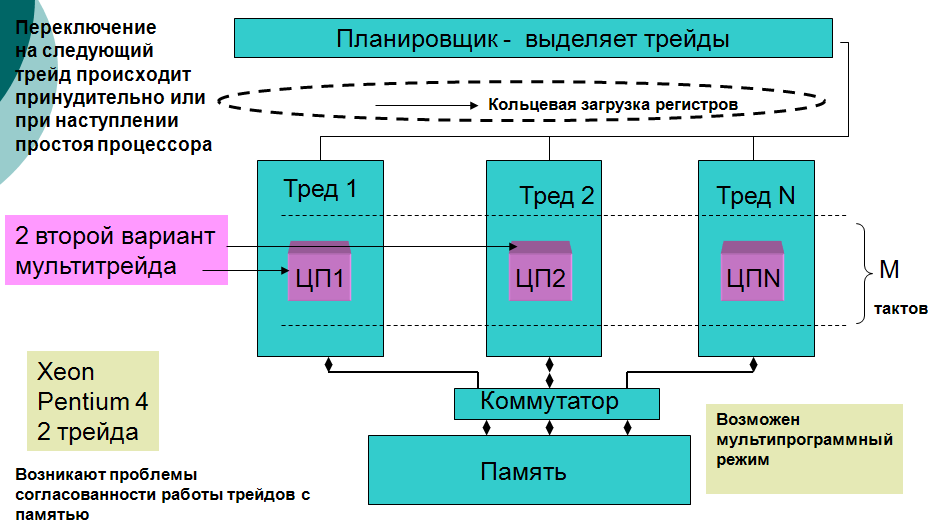
6. Проблема суперскальных МП: Простои конвейеров из-за нерегулярной загрузки функциональных устройств МП. Наличие одного счетчика команд. Ограничение на количество конвейеров и функциональных устройств МП – непропорциональное усложнение структуры. Одновременное исполнение нескольких программ только в режиме разделения времени. Принцип работы мультитрейдовой архитектуры:
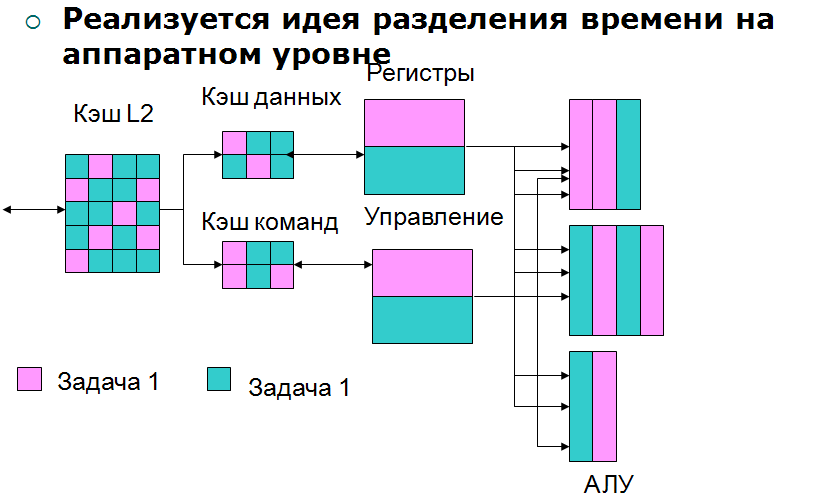
Технология Hyper-Threading:
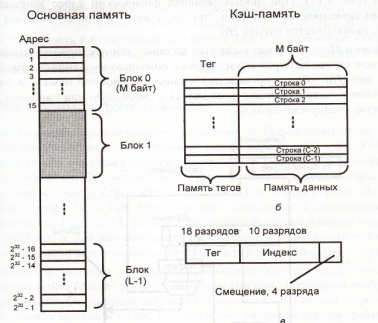
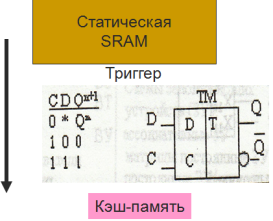
7. Кэш-память – представляет собой организованную в виде ассоциативного запоминающего устройства, быстродействующую буферную память ограниченного объема, которая располагается между оперативной памятью и регистрами микропроцессора. В кэш памяти хранится информация чаще всего используемая в текущем цикле вычислений. Основа кэш памяти - принцип локальности ссылок. Назначение – повышение производительности системы за счет уменьшения количества циклов обращения к оперативной памяти. Кэш память скрыта от программиста и «невидима» для процессора. Стратегии замещения строк в кэш: - LRU (Least Recenly Used) - замещается строка, к которой дольше всего не обращались. Не востребованная информация. - FIFO – замещается строка самая давняя по пребыванию в кэш. Первый пришел – первый вышел.- Random – замещение случайным образом. Структура оперативной памяти и кэш-памяти: Основная память делится на блоки одинакового размера с кратными адресами ячеек. Обычно по размеру строки кэш. Так как все блоки в кэш памяти не умещаются вводится понятие тэга –указателя, какой блок ОП находится в кэш.
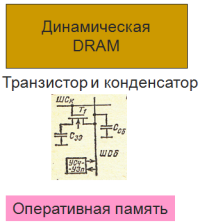
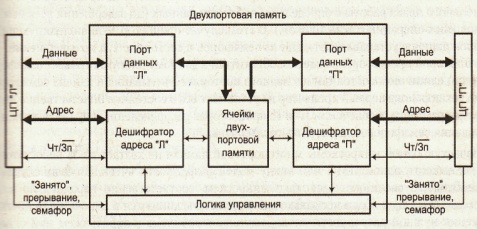
8. Оперативная память-RAM (Random Access Memory) – память с произвольным доступом.
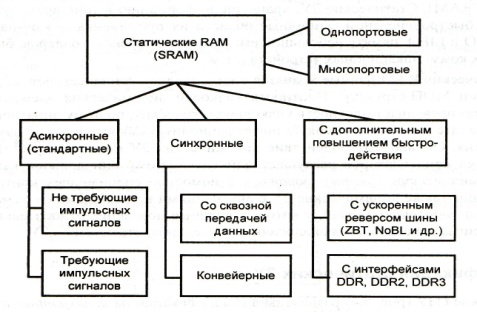
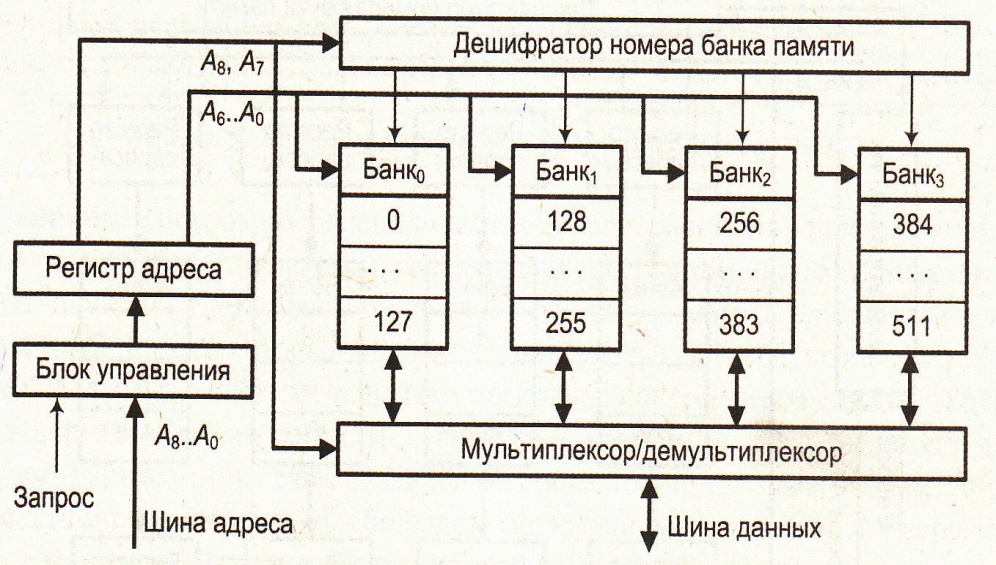
Много портовые ОЗУ: Обеспечивают возможность одновременного доступа к памяти двух устройств (Процессоров). Проблемы возникают, если устройства обращаются к ячейке с одним адресом, но такая вероятность не более 0.1%..
9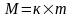 .
Структура 2D: ЗЭ образуют
прямоугольную матрицу
.
Структура 2D: ЗЭ образуют
прямоугольную матрицу
Применяется в ЗУ малой емкости. Недостатки: Сложный дешифратор; Матрица не квадратная и при большой емкости матрица приобретает вид полосы
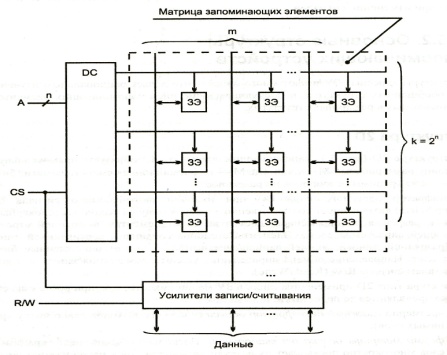 Структура
3D: Используется принцип
двухкоординатной выборки. Применяется
в ЗУ с многоразрядной – слойной
организацией. Недостаток – сложность
ЗЭ
Структура
3D: Используется принцип
двухкоординатной выборки. Применяется
в ЗУ с многоразрядной – слойной
организацией. Недостаток – сложность
ЗЭ
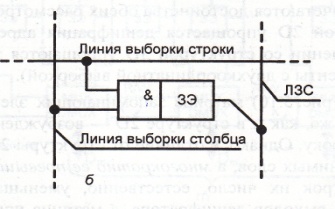
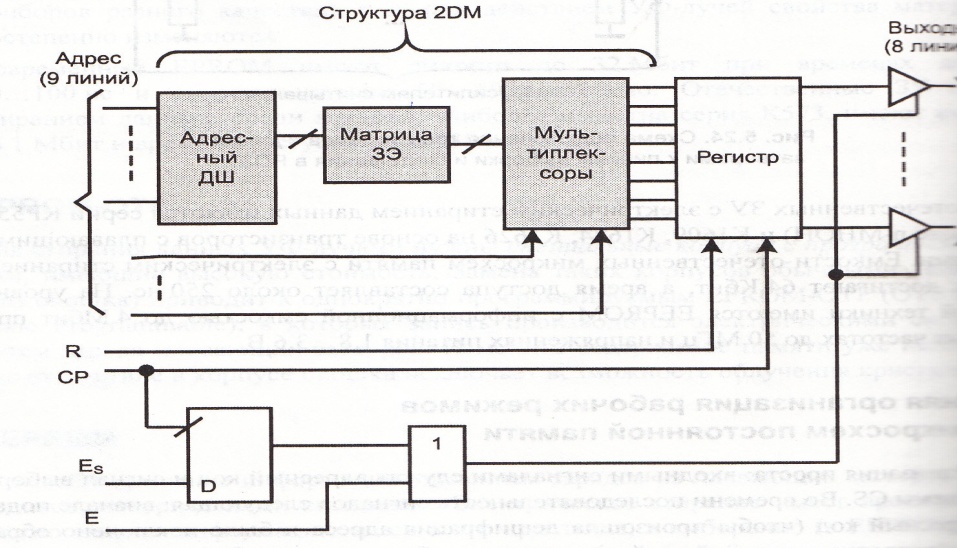
Структура 2DM: Сочетает достоинства двух предыдущих.

10. Организация микросхем памяти
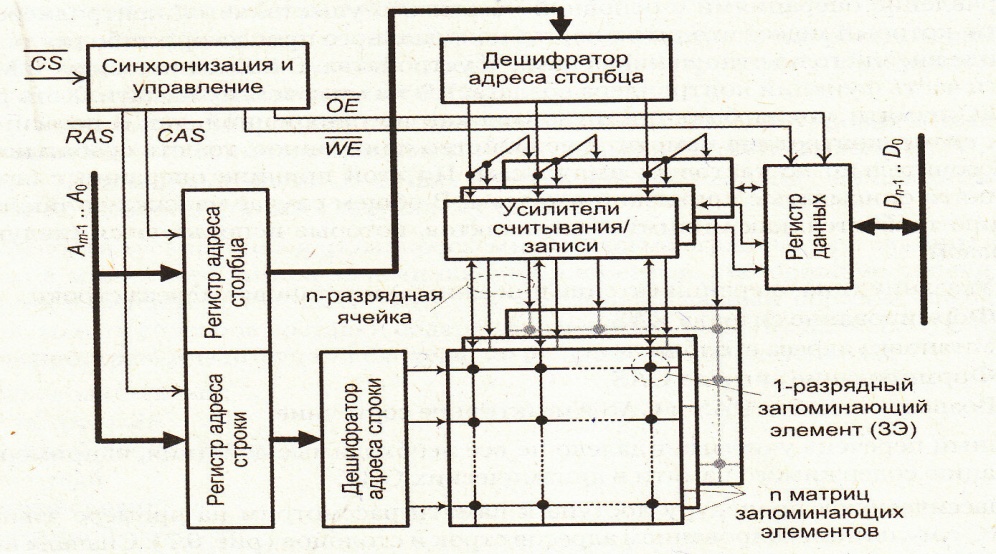
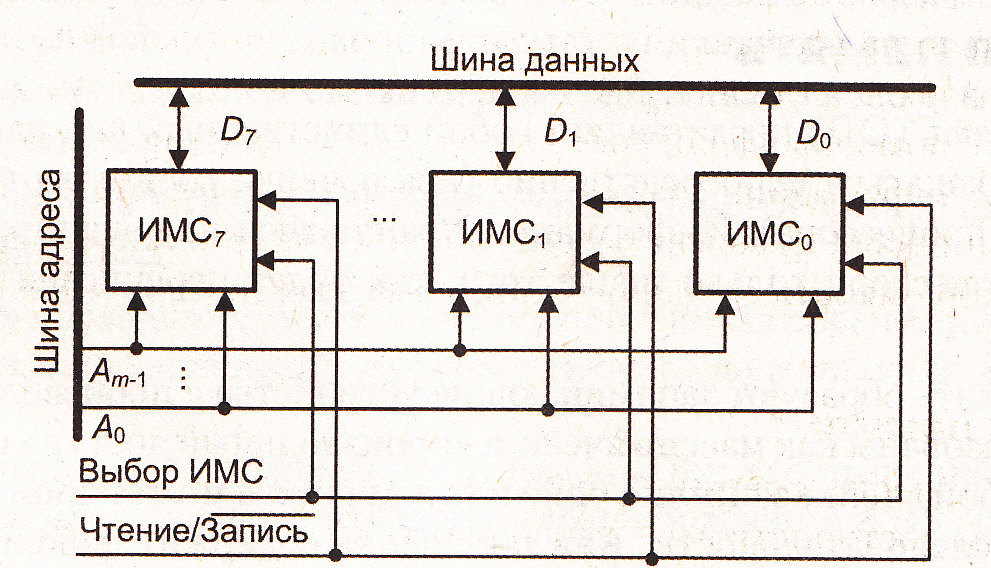
Увеличение разрядности памяти на ИСБлочная организация оперативной памяти
 Эволюция:
Эволюция:
FPM – Fast Page Mode – динамическая память с быстрым страничным доступом. EDO – Extended Data Out. Расширенное время удержания данных на выходе. BEDO – Burst EDO – вариант памяти с пакетным доступом. Синхронная динамическая память SDRAM Синхронная динамическая память DDR (Double Data Rate) Память DDR2 SDRAM. Память DDR3 SDRAM.
11,Синхронная динамическая память. Способ повышение производительности синхронной динамической памяти DDR- DDR2-DDRЗ.
DDR означает удвоенную скорость передачи данных. По переднему и заднему фронту синхросигнала.
П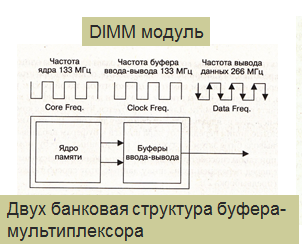 амять
DDR2
SDRAM:
За каждый
такт работы ядра на шину данных выдается
4 бита
амять
DDR2
SDRAM:
За каждый
такт работы ядра на шину данных выдается
4 бита
П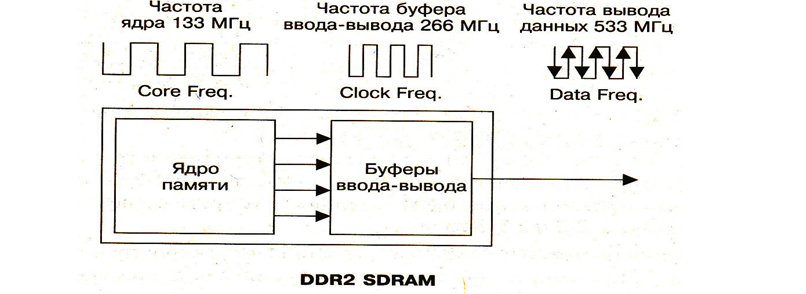 амять
DDR3
SDRAM:
Логическое
развитие DDR2.
Стандарт принят в 2007 году и к 2010 занял
основную долю рынка. Возможная частота
работы до 1800 МГц и выше. Питание 1.5 В.
амять
DDR3
SDRAM:
Логическое
развитие DDR2.
Стандарт принят в 2007 году и к 2010 занял
основную долю рынка. Возможная частота
работы до 1800 МГц и выше. Питание 1.5 В.
12.Технология
Thermal Monitor 1
и 2 . Идея - при достижении критической
температуры перевести процессор
на
пониженную тактовую частоту до снижения
температуры ядра. Технология Thermal
Monitor 2: К технологии Thermal
Monitor 1 добавляется функция
понижения напряжения питания. Технологии
работают в процессорах с тактовой
частотой свыше 2.8 ГГц.Технологии
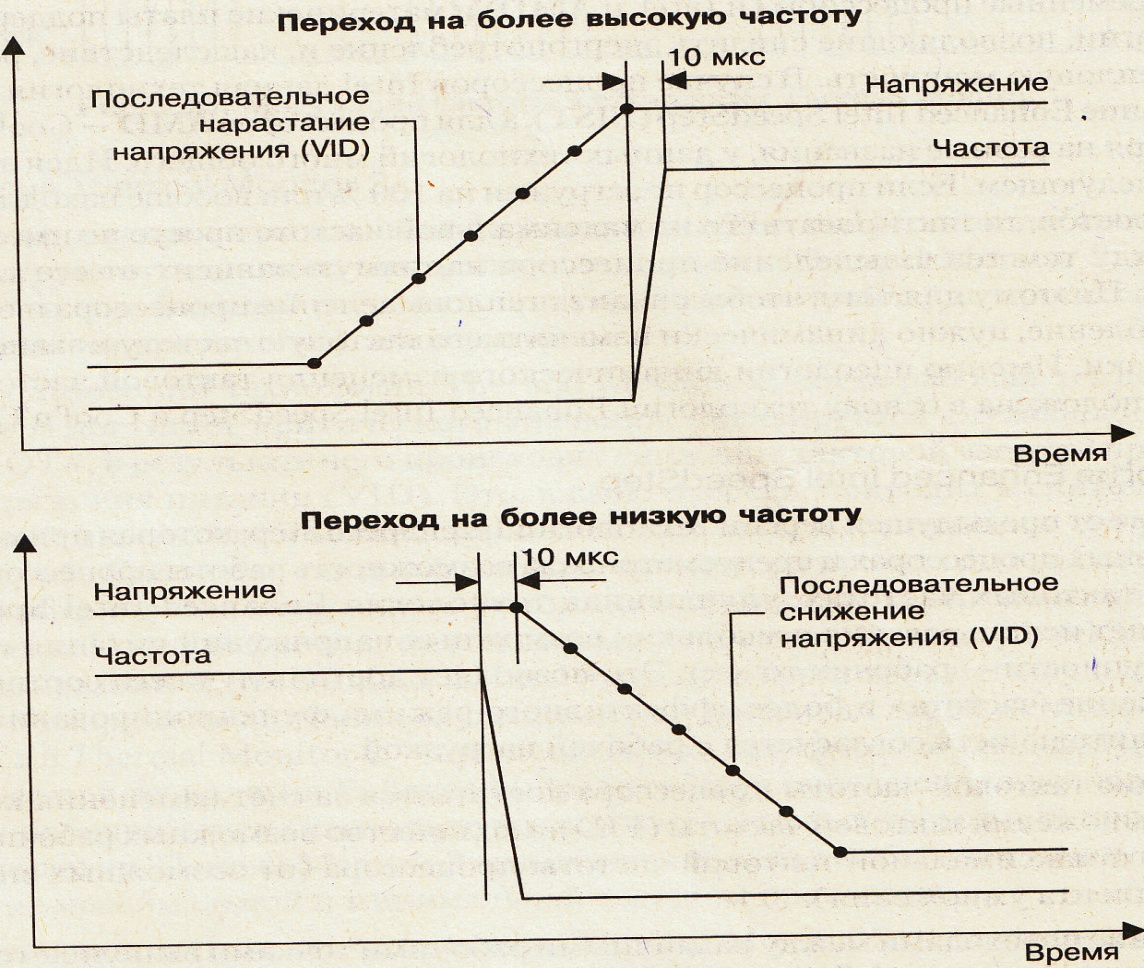
энергосбережения: Enhanced
Intel Speed Step.
Идея – понижения тактовой частоты
работы процессора.
Переходом управляет сам
процессор.
 Компания
Atmel использует технологию
отключения питания специальными
командами. При этом могут быть выключены
различные блоки процессора до сторожевого
таймера.
Компания
Atmel использует технологию
отключения питания специальными
командами. При этом могут быть выключены
различные блоки процессора до сторожевого
таймера.
13.
Постоянные запоминающие устройства.
Классификация. Принцип работы.
Примеры.
Постоянные запоминающие
устройства ROM (Read-Only
Memory):
Используются для
хранения неизменяемой информации:
загрузочных программ ОС, программ BIOS,
тестовых программ.
-
Программируемые при
изготовлении – классические ROM
- Однократно программируемые после
изготовления PROM
-
Многократно программируемые EPROM
Классические ПЗУ – масочные диодные
и транзисторные, лазерные.
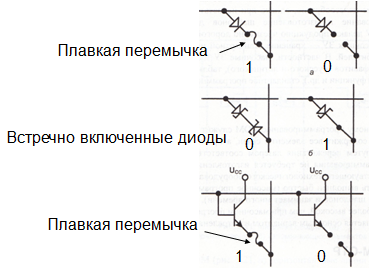
Однократно
программируемые ПЗУ PROM
и EPROM-OTP:
Информация
однократно записывается потребителем.
 Многократно
программируемые ПЗУ:
- EPROM
(Erasable Programmable
ROM) – стираемые программируемые
ПЗУ.
- EEPROM (Electrically
Erasable Programmable
ROM) – электрически стираемые
программируемые ПЗУ.
- Флэш-память.
Пример
структуры EPROM :
Многократно
программируемые ПЗУ:
- EPROM
(Erasable Programmable
ROM) – стираемые программируемые
ПЗУ.
- EEPROM (Electrically
Erasable Programmable
ROM) – электрически стираемые
программируемые ПЗУ.
- Флэш-память.
Пример
структуры EPROM :
14.
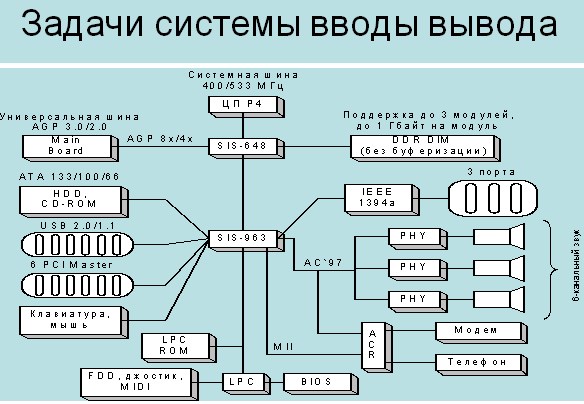
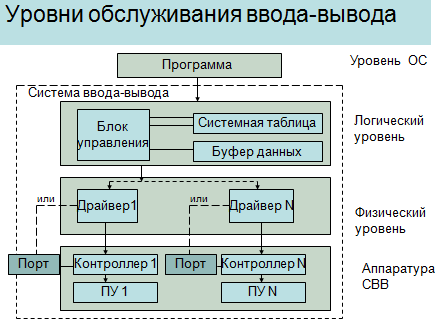
Система ввода и вывода. Элементы. Задачи.
Уровни обслуживания.
Элементы:
-Каналы -порты -BIOS
-Конторллеры
-драйверы
-интерфейсы:
1.
Физическая организация 2. Конструктивы
3.
Логическая организация
-способы
обмена:
1. Программный 2. Прямой
доступ к памяти
3. Через систему
прерываний
Глобальные задачи
СВВ:
-Обеспечение максимальной
производительности вычислительной
системы.
-Возможность изменения
конфигурации периферийных устройств
(ПУ).
-Возможность модифицировать ПУ
, не изменяя ядро системы.
1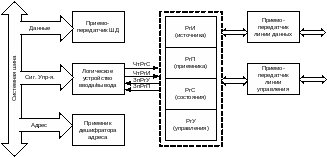 5.
Контроллеры. Драйверы. Задачи ими
решаемые. Система прерываний. Назначение.
Обработка прерываний. Приоритет
прерывания.
Обобщенная схема
контроллера:
5.
Контроллеры. Драйверы. Задачи ими
решаемые. Система прерываний. Назначение.
Обработка прерываний. Приоритет
прерывания.
Обобщенная схема
контроллера:
Драйвер
специальная программа, необходимая для
корректной работы компьютера. Драйвер
позволяет операционной системе компьютера
распознать и правильно использовать
любое вновь установленное в компьютере
устройство.
Функции драйверов:
-
Проверка готовности контроллера и ПУ
к обмену;
- Формирование управляющих
сигналов и данных для ПУ;
- Определение
действий при обнаружении ошибок;
-
Формирование сообщения о завершении
операции с указанием успешности или
неуспешности;
- Передача управления
на логический уровень.
Прерывание:
Процесс
переключения ЦП с одной программы на
другую по внешнему сигналу с сохранением
информации необходимой для продолжения
прерванной программы.
Вектор прерываний
– адрес хранения программы обработки
прерывания.
Приоритеты:
Относительное
обслуживание прерываний означает, что
если во время обработки прерывания
поступает более приоритетное прерывание,
то это прерывание будет обработано
только после завершения текущей процедуры
обработки прерывания.
Абсолютное
обслуживание прерываний означает, что
если во время обработки прерывания
поступает более приоритетное прерывание,
то текущая процедура обработки прерывания
вытесняется, и процессор начинает
выполнять обработку вновь поступившего
более приоритетного прерывания. После
завершения этой процедуры процессор
возвращается к выполнению вытесненной
процедуры обработки прерывания.
Диаграмма
прерывания:
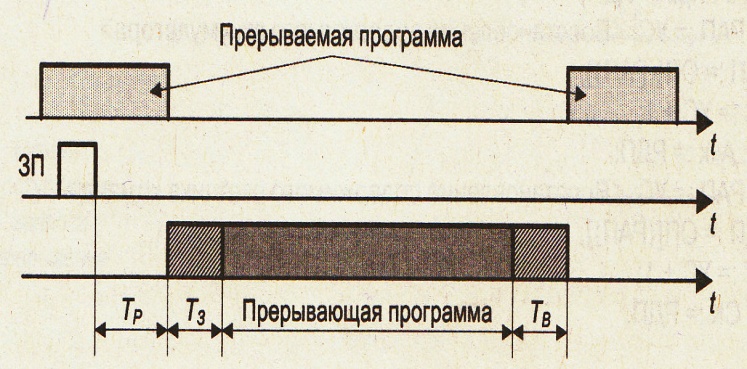
16. Контроллер прямого доступа к памяти. Назначение. Принцип работы. Контроллер прямого доступа к памяти: Режимы работы ПДП: - с захватом цикла – используются циклы, в которых МП не работает с памятью. Обмен байтом, словом; Медленный, но не требует применения специальных устройств. - с захватом цикла и отключение МП от системной шины. Приостановка выполнения очередной команды процессора сигналом ТПДП и обмен блоком данных между ВУ и памятью. Требуется выполнение программы загрузки регистров контроллера ПДП процессором адресом и размером загружаемого блока. - с блокировкой процессора. Назначение блоков контроллера ПДП: MR – регистр режима определяет параметры передачи: - порядок изменения адреса (+ или -); - возможность автоинициализации; - режим обслуживания (словом, блоком); CAR – регистр текущего адреса; BAR - регистр базового адреса (устанавливается инициализацией); CWR – текущий счетчик данных; WCR – базовый счетчик данных (устанавливается инициализацией); CR – регистр команд: - режим память- память через регистр TR или обычный; - запрет или разрешение ПДП; - порядок изменения приоритетов каналов; SR – регистр условий; Сигнал AEN – флаг управления шиной (ПДП;МП). Последовательность ПДП: 1. Принять запрос на ПДП от ВУ ( сигнал DRQ). 2. Сформировать запрос к МП на захват шины (сигнал HRQ). 3. Принять от МП сигнал подтверждения перевода схем приема передатчиков в третье состояние (HLDA). 4. Сформировать для ВУ сигнал о начале цикла ПДП (DACK). 5. Сформировать на шине адрес ячейки памяти для обмена. 6. Выработать сигналы управления, обеспечивающие обмен (MR,MW,IOR,IOW). 7. Уменьшить значение в счетчике данных. 8. Проверить условие окончания ПДП. Если счетчик данных не обнулен, то повторить пункты 5-8. 9. Если счетчик данных пуст выработать сигнал окончания ПДП – IEOP.