

Лабораторна робота № 14
Тема
Основні статистичні функції OpenOffice .
Методи знаходження точкових оцінок.
Мета
Ознайомитись з основними статистичними функціями в Open Office та методами знаходження точкових оцінок основних розподілів.
Теоретичні відомості
Опрацювати матеріал Лекції №3.
Для створення формул в Open Office є можливість використати наперед підготовані формули, які називаються функціями.
Для створення формули на основі використання функції потрібно виконати такі дії:
в клітинку, в якій обчислюється формула, ввести знак дорівнює =;
ввести ім’я функції;
в дужках ввести аргументи (вхідні значення) функції, які використовуються для виконання обчислень;
натиснути клавішу <Enter>.
Аргументи функцій − це числа, адреси клітинок, адреси (назви) діапазонів та їх списки, а також інші функції.
В Open Office можна вставити функцію (Paste Function) використовуючи команду, за допомогою якої можна підібрати потрібну функцію та отримати інформацію про те, які потрібні аргументи і в якому порядку вони повинні бути розміщені.
Для виконання цієї команди потрібно виконати такі дії:
у меню Insert вибрати пункт Function… ;
у діалоговому вікні, яке з’явиться, із списку категорій (Function category) вибираємо ту категорію, до якої відноситься потрібна функція (у даній лабораторній роботі доцільно використовувати функції з категорії Statistical) ;
із списку функцій ( Function Name ) вибрати потрібну функцію;
задати аргументи функції, помістивши значення у відповідні поля;
натиснути на кнопку OK.
Можна також викликати список категорій за допомогою клавіші f.
Статистичні функції Open Office.
СРОТКЛ - Обчислює середнє абсолютних значень відхилень точок даних від середнього.
СРЗНАЧ - Обчислює середнє арифметичне аргументів.
СРЗНАЧА - Обчислює середнє арифметичне аргументів, включаючи числа, текст і логічні значення.
БІНОМРАСП - Обчислює окреме значення біноміального розподілу.
ХИ2РАСП - Обчислює односторонню вірогідність розподілу хі-квадрат.
ХИ2ОБР - Обчислює зворотне значення односторонньої вірогідності розподілу хі-квадрат.
ХИ2ТЕСТ
- Обчислює значення критерію
![]() .
.
ДОВЕРИТЬ - Обчислює довірчий (надійний) інтервал для середнього значення за генеральною сукупністю.
КОРРЕЛ - Обчислює коефіцієнт кореляції між двома множинами даних.
СЧЁТ - Підраховує кількість чисел в списку аргументів.
СЧЕТЗ - Підраховує кількість значень в списку аргументів.
СЧИТАТЬПУСТОТЫ - Підраховує кількість порожніх клітинок в заданому діапазоні.
СЧЁТЕСЛИ - Підраховує кількість непорожніх клітинок, що задовольняють заданій умові усередині діапазону.
КОВАР - Обчислює коваріацію, тобто середнє добутків відхилень для кожної пари точок.
КРИТБИНОМ - Обчислює найменше значення, для якого функція біномного розподілу менше або рівна заданому значенню.
КВАДРОТКЛ - Обчислює суму квадратів відхилень.
ЭКСПРАСП - Обчислює експоненціальний розподіл.
FРАСП - Обчислює F-розподіл вірогідності.
FРАСПОБР - Обчислює зворотне значення для F-розподілу вірогідності.
ФИШЕР - Обчислює перетворення Фішера.
ФИШЕРОБР - Обчислює зворотне перетворення Фішера.
ПРЕДСКАЗ - Обчислює значення лінійного тренда.
ЧАСТОТА - Обчислює розподіл частот у вигляді вертикального масиву.
ФТЕСТ - Обчислює результат F-тесту.
ГАММАРАСП - Обчислює гамма-розподіл.
ГАММАОБР - Обчислює зворотне гамма-розподіл.
ГАММАНЛОГ - Обчислює натуральний логарифм гамма функції.
СРГЕОМ - Обчислює середнє геометричне.
РОСТ - Обчислює значення відповідно до експоненціального тренда.
СРГАРМ - Обчислює середнє гармонійне.
ГИПЕРГЕОМЕТ - Обчислює гіпергеометричний розподіл.
ОТРЕЗОК - Обчислює відрізок, що відсікається на осі лінією лінійної регресії.
ЭКСЦЕСC - Обчислює ексцес множини даних.
НАИБОЛЬШИЙ - Обчислює к-е найбільше значення з множини даних.
ЛИНЕЙН - Обчислює параметри лінійного тренда.
ЛГРФПРИБЛ - Обчислює параметри експоненціального тренда.
ЛОГНОРМОБР - Обчислює зворотний логарифмічний нормальний розподіл.
ЛОГНОРМРАСП - Обчислює інтегральний логарифмічний нормальний розподіл.
МАКС - Обчислює максимальне значення із списку аргументів.
МАКСА - Обчислює максимальне значення із списку аргументів, включаючи числа, текст і логічні значення.
МЕДИАНА - Обчислює медіану заданих чисел.
МИН - Обчислює мінімальне значення із списку аргументів.
МИНА - Обчислює мінімальне значення із списку аргументів, включаючи числа, текст і логічні значення.
МОДА - Обчислює значення моди множини даних.
ОТРБИНОМРАСП - Обчислює негативний біномний розподіл.
НОРМРАСП - Обчислює нормальну функцію розподілу.
НОРМОБР - Обчислює зворотний нормальний розподіл.
НОРМСТРАСП - Обчислює стандартний нормальний інтегральний розподіл.
НОРМСТОБР - Обчислює зворотне значення стандартного нормального розподілу.
ПИРСОН - Обчислює коефіцієнт кореляції Пірсона.
ПЕРСЕНТИЛЬ - Обчислює к-ий персентиль для значень з інтервалу.
ПРОЦЕНТРАНГ - Обчислює процентну норму значення в множини даних.
ПЕРЕСТ - Обчислює кількість перестановок для заданого числа об'єктів.
ПУАССОН - Обчислює розподіл Пуассона.
ВЕРОЯТНОСТЬ - Обчислює вірогідність того, що значення з діапазону знаходиться усередині заданих меж.
КВАРТИЛЬ - Обчислює квартиль множини даних.
РАНГ - Обчислює ранг числа в списку чисел.
КВПИРСОН - Обчислює квадрат коефіцієнта кореляції Пірсона.
СКОС - Обчислює асиметрію розподілу.
НАКЛОН - Обчислює нахил лінії лінійної регресії.
НАИМЕНШИЙ - Обчислює к-е найменше значення в множини даних.
НОРМАЛИЗАЦИЯ - Обчислює нормалізоване значення.
СТАНДОТКЛОН - Обчислює стандартне відхилення за вибіркою.
СТАНДОТКЛОНА - Обчислює стандартне відхилення за вибіркою, включаючи числа, текст і логічні значення.
СТАНДОТКЛОНП - Обчислює стандартне відхилення за генеральною сукупністю.
СТАНДОТКЛОНПА - Обчислює стандартне відхилення за генеральною сукупністю, включаючи числа, текст і логічні значення.
СТОШYX - Обчислює стандартну помилку передбачених значень у для кожного значення x в регресії.
СТЬЮДРАСП - Обчислює значення t-розподілу Стьюдента.
СТЬЮДРАСПОБР - Обчислює зворотний t-розподіл Стьюдента.
ТЕНДЕНЦИЯ - Обчислює значення відповідно до лінійного тренда.
УРЕЗСРЕДНЕЕ - Обчислює середнє внутрішності множини даних.
ТТЕСТ - Обчислює вірогідність, відповідну критерію Стьюдента.
ДИСП - Обчислює дисперсію за вибіркою.
ДИСПА - Обчислює дисперсію за вибіркою, включаючи числа, текст і логічні значення.
ДИСПР - Обчислює дисперсію для генеральної сукупності.
ДИСПРА - Обчислює дисперсію для генеральної сукупності, включаючи числа, текст і логічні значення.
ZТЕСТ - Обчислює двостороннє P-значення z-тесту.
В даній лабораторній роботі будемо використовувати наступні функцій:
СЧЁТ (COUNT) − підраховує кількість клітинок усередині діапазону.
Синтаксис: COUNT(діапазон)
діапазон – це діапазон, в якому потрібно підрахувати кількість клітинок.
МАКС (MAX) − повертає найбільше значення з набору значень.
Синтаксис: MAX(число1;число2;...)
Число1, число2, ... – це від 1 до 30 чисел, серед яких потрібно знайти найбільше.
МИН (MIN) – повертає найменше число у списку значень.
Синтаксис: MIN(число1;число2;...)
Число1, число2, ... – це від 1 до 30 чисел, серед яких потрібно знайти найменше.
СРЗНАЧ (AVERAGE) — повертає середнє арифметичне аргументів.
Синтаксис: AVERAGE(число1;число2;...)
Число1, число2, ... – це від 1 до 30 аргументів, для яких обчислюється середнє.
Зауваження
Аргументи мають бути або числами, або іменами, масивами або посиланнями, що містять числа.
Якщо аргумент, що є масивом або посиланнями, містить тексти, логічні значення або порожні клітинки, то такі значення ігноруються; але клітинки, які містять нульові значення, враховуються.
ДИСП(VAR) – обчислює дисперсію на основі вибірки.
Синтаксис: VAR(число1;число2;...)
Число1, число2, ... – це від 1 до 30 числових аргументів, які відповідають вибірці з генеральної сукупності.
СТАНДОТКЛОН (STDEV) - обчислює стандартне відхилення на основі вибірки.
Синтаксис: STDEV(число1;число2; ...)
Число1, число2, ... – це від 1 до 30 числових аргументів, які відповідають вибірці з генеральної сукупності.
МЕДИАНА (MEDIAN) – повертає медіану вказаних чисел. Медіана – це число, яке є серединою множини чисел; тобто половина чисел мають значення більші, ніж медіана, а інша половина – менші, ніж медіана.
Синтаксис: MEDIAN(число1;число2;...)
Число1, число2, ... – це від 1 до 30 чисел, для яких визначається медіана.
МОДА (MODE) – повертає значення в масиві або інтервалі даних, яке найчастіше трапляється або повторюється.
Синтаксис: MODE(число1;число2;...)
Число1, число2, ... – це від 1 до 30 аргументів, для яких обчислюється мода. Можна також використовувати один масив або посилання на масив замість аргументів, які розділяються крапкою з комою.
ЭКСЦЕСС (KURT) – повертає ексцес вказаних чисел.
Синтаксис: KURT (число1;число2;...)
Число1, число2, ... – це від 1 до 30 чисел, для яких визначається ексцес.
Можна також використовувати один масив або посилання на масив замість аргументів, які розділяються крапкою з комою.
СКОС (SKEW) - повертає асиметрію вказаних чисел.
Синтаксис: SKEW (число1;число2;...)
Число1, число2, ... – це від 1 до 30 чисел, для яких визначається асиметрія. Можна також використовувати один масив або посилання на масив замість аргументів, які розділяються крапкою з комою.
Точкові оцінки параметрів основних розподілів:
Експоненційний (показниковий) розподіл E(a) |
|
|
Розподіл Бернуллі B(n,p)
|
|
|
Розподіл Пуассона
P(n,
|
|
|
Рівномірний розподіл R(a;b) |
|
|
Нормальний розподіл N( |
|
|
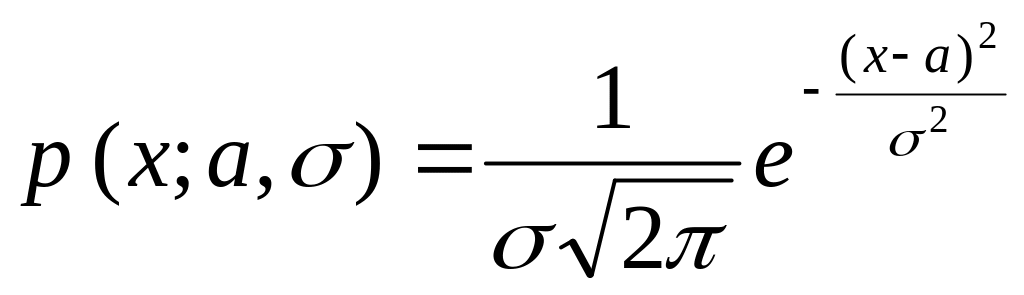
В лабораторній роботі використовуються функції:
СРЗНАЧ (AVERAGE) — повертає середнє арифметичне аргументів.
Синтаксис: AVERAGE(число1;число2;...)
Число1, число2, ... – це від 1 до 30 аргументів, для яких обчислюється середнє.
Зауваження
Аргументи мають бути або числами, або іменами, масивами або посиланнями, що містять числа.
Якщо аргумент, що є масивом або посиланнями, містить тексти, логічні значення або порожні клітинки, то такі значення ігноруються; але клітинки, які містять нульові значення, враховуються.
СТАНДОТКЛОН (STDEV) - обчислює стандартне відхилення на основі вибірки.
Синтаксис: STDEV(число1;число2; ...)
Число1, число2, ... – це від 1 до 30 числових аргументів, які відповідають вибірці з генеральної сукупності.
Хід роботи
Типове навчальна завдання.
Запустіть програму OpenOffice.
Відкриється порожня книжка(в іншому випадку створіть нову книжку).
В діапазоні а1:а100 введіть дані спостережень – вибірку (табл.1).
Таблиця 1
-
12
27
47
21
11
25
61
45
22
22
30
52
55
24
23
29
33
38
53
33
35
35
70
52
35
34
48
61
53
41
25
16
47
70
18
18
27
44
62
11
27
26
34
61
13
45
48
36
21
14
36
51
35
18
36
22
50
61
11
70
28
60
65
21
66
38
62
70
18
67
46
54
53
27
61
47
58
54
24
70
24
25
54
25
62
12
27
47
21
11
25
61
45
22
22
30
52
55
24
23
Для знаходження числових характеристик виконайте послідовно команди:
Для побудови варіаційного ряду доцільно відсортувати попередньо введені дані (елементи вибірки).Для цього слід виділити фрагмент електронної таблиці – стовпчик А, який підлягає сортуванню і у вікні Sort by задати критерій сортування Ascending (зростаючий порядок).
Для знаходження числових характеристик виконайте послідовно команди.
COUNT (А1:А100)
MAX(А1:А100)
МИН (А1:А100)
AVERAGE(А1:А100)
VAR(А1:А100)
STDEV(А1:А100)
MEDIAN(А1:А100)
MODE(А1:А100)
KURT(А1:А100)
SKEW(А1:А100)
Результати обчислень:
-
Обсяг вибірки
100
Максимум
70
Мінімум
11
Середнє
37,38
Дисперсія вибірки
316,9451
Стандартне відхилення
17,80295
Медіана
35
Мода
11
Ексцес
-1,14579
Асиметрія
0,247749
Результати обчислень необхідних числових характеристик:
-
Середнє значення
37,38
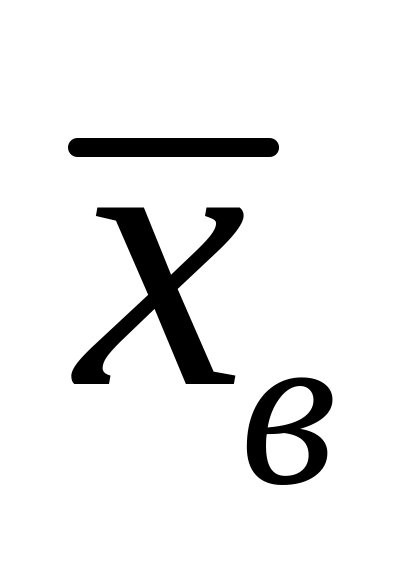
Стандартне відхилення
17,80295
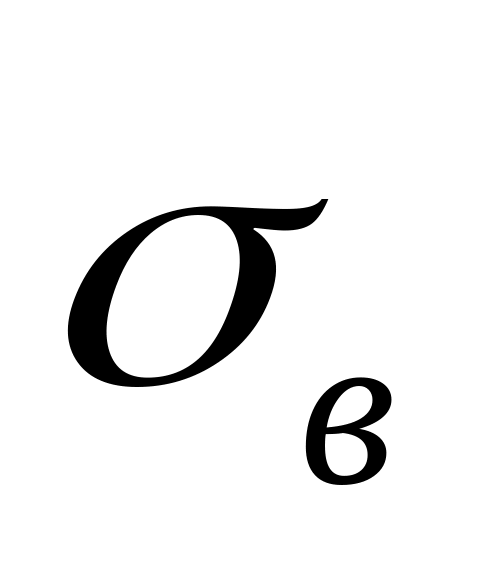
Результати обчислень точкових оцінок параметрів основних розподілів:
Експоненційний (показниковий) розподіл E(a) |
|
=0,026752
|
Розподіл Бернуллі B(n,p)
|
|
= 0,3738 |
Розподіл Пуассона P(n, )
|
|
=37,38 |
Рівномірний розподіл R(a;b) |
|
=6,544386 = 68,21561
|
Нормальний розподіл N( ) |
|
=37,38 =17,80295 |