

Российская особенность
В большинстве стран была создана одна кодовая страница для своего алфавита. Но Россия всегда шла своим путем.
Семейство кодировок 8859
Восьмибитное семейство кодировок 8859, созданное International Standorts Organization, ISO, для наведения порядка в восьмибитных кодировках, расширило таблицу ASCII для латинских букв с диакритикой и лигатур (кодировка ISO 8859-1), славянских языков с латинским алфавитом, например, чешский, польский, венгерский, (ISO 8859-2), турецкого, мальтийского, эсперанто, галисийского языков (ISO 8859-3), кириллицы (ISO 8859-5), арабского (ISO 8859-6), греческого (ISO 8859-7), иврита (ISO 8859-8) и других языков. Кириллическая кодировка этого семейства не получила широкого распространения, зато стандарт ISO 8859-1 (так называемая Latin-1) стала стандартом для "расширенной" латиницы и содержит практически все символы западноевропейских языков. Так, многие шрифты для Windows соответствуют кодировке ISO 8859-1 начиная с позиции 160 до конца таблицы, а в диапазоне 128-159 содержат дополнительные символы (длинное тире или "торговая марка", например). Именно в этом семействе появилось понятие "кодовая страница" (набор из 256 символов для каждого определённого языка или группы языков). Крупным недостатком такого подхода является невозможность смешивания языков в одном документе и отсутствие представления для китайского и японского языков.
Появление кириллицы (ISO 8859-5).
Изначальные английские версии поставляемых в Россию программ не могли работать с русским алфавитом (это и понятно - в них же не было русской кодовой страницы). Поэтому была создана русская кодовая страница, получившая название ISO-8859-5, в которой кодам символов, большим 127, соответствовали русские буквы. Так как их всего 33, а с заглавными - 66, то в кодовой странице осталось место для символов псевдографики.
Особенности использования данной таблицы кодировки.
Например, западная программа могла из символов псевдографики изобразить таблицу. Если в системе стояла ISO-8859-5, то рисовалась русская буква, и внешний вид рисунка был весьма своеобразным. Это происходило из-за того, что коды символов псевдографики не совпадали: в английской и в русской таблицах символов.
Дополнительно:
Материал из Википедии – свободной энциклопедии
ISO 8859-5 – 8-битная кодовая страница из серии ISO-8859 для представления кириллицы. В России почти не употребляется.
ISO 8859-5 была создана на базе «основной кодировки» (все русские буквы сохранили своё расположение, за исключением заглавной Ё).
Имеются буквы многих языков, использующих кириллицу, однако в целом ISO 8859-5 – не очень удобная кодировка, поскольку в ней отсутствуют многие нужные символы, такие как тире (—), кавычки-ёлочки («»), градус (°) и др. Нет также буквы Ґ, используемой иногда в украинской письменности.
Порядок символов этой кодовой страницы использовался при размещении букв кириллицы в наборе символов Unicode (со сдвигом вверх на 864 позиции).
Основная кодировка
Основная кодировка согласно ГОСТ 19768-87 была принята в 1987 г. взамен КОИ-8, однако использовалась мало. Основную кодировку поддерживало только оборудование и программное обеспечение, производившееся в СССР (ЕС ПЭВМ, Лексикон, …), а также некоторые принтеры Epson.
Гораздо более популярной оказалась описанная в том же ГОСТе альтернативная кодировка (с тем же набором символов, но в другом порядке). Примечание: «альтернативная» кодировка рассмотрена ниже, CP866.
На базе основной кодировки была создана ISO 8859-5, но и она не нашла широкого применения.
Нижняя часть таблицы кодировки (латиница) полностью соответствует кодировке ASCII. Числа под буквами обозначают шестнадцатеричный код буквы в Юникоде.
|
.0 |
.1 |
.2 |
.3 |
.4 |
.5 |
.6 |
.7 |
.8 |
.9 |
.A |
.B |
.C |
.D |
.E |
.F |
8. |
╧ 2567 |
╨ 2568 |
╤ 2564 |
╡ 2561 |
╢ 2562 |
╖ 2556 |
╕ 2555 |
╥ 2565 |
╙ 2559 |
╘ 2558 |
╒ 2552 |
╜ 255C |
╛ 255B |
╞ 255E |
╟ 255F |
╓ 2553 |
9. |
╔ 2554 |
╗ 2557 |
╝ 255D |
╚ 255A |
═ 2550 |
║ 2551 |
╦ 2566 |
╣ 2563 |
╩ 2569 |
╠ 2560 |
╬ 256C |
░ 2591 |
▒ 2592 |
▓ 2593 |
╫ 256B |
╪ 256A |
A. |
┌ 250C |
┐ 2510 |
┘ 2518 |
└ 2514 |
─ 2500 |
│ 2502 |
┬ 252C |
┤ 2524 |
┴ 2534 |
├ 251C |
┼ 253C |
█ 2588 |
▄ 2584 |
▌ 258C |
▐ 2590 |
▀ 2580 |
B. |
А 410 |
Б 411 |
В 412 |
Г 413 |
Д 414 |
Е 415 |
Ж 416 |
З 417 |
И 418 |
Й 419 |
К 41A |
Л 41B |
М 41C |
Н 41D |
О 41E |
П 41F |
C. |
Р 420 |
С 421 |
Т 422 |
У 423 |
Ф 424 |
Х 425 |
Ц 426 |
Ч 427 |
Ш 428 |
Щ 429 |
Ъ 42A |
Ы 42B |
Ь 42C |
Э 42D |
Ю 42E |
Я 42F |
D. |
а 430 |
б 431 |
в 432 |
г 433 |
д 434 |
е 435 |
ж 436 |
з 437 |
и 438 |
й 439 |
к 43A |
л 43B |
м 43C |
н 43D |
о 43E |
п 43F |
E. |
р 440 |
с 441 |
т 442 |
у 443 |
ф 444 |
х 445 |
ц 446 |
ч 447 |
ш 448 |
щ 449 |
ъ 44A |
ы 44B |
ь 44C |
э 44D |
ю 44E |
я 44F |
F. |
Ё 401 |
ё 451 |
╭ 256D |
╮ 256E |
╯ 256F |
╰ 2570 |
→ 2192 |
← 2190 |
↓ 2193 |
↑ 2191 |
÷ F7 |
± B1 |
№ 2116 |
¤ A4 |
■ 25A0 |
A0 |
Примечания:
в позициях 0xF2 – 0xF5 должны быть прямые диагональные линии
позиция 0xFF, видимо, не использовалась вообще
Кодировка ISO 8859-5
Нижняя часть таблицы кодировки полностью соответствует кодировке ASCII. Числа под буквами – шестнадцатеричный код буквы в Юникоде.
|
.0 |
.1 |
.2 |
.3 |
.4 |
.5 |
.6 |
.7 |
.8 |
.9 |
.A |
.B |
.C |
.D |
.E |
.F |
8. |
PAD 80 |
HOP 81 |
BPH 82 |
NBH 83 |
IND 84 |
NEL 85 |
SSA 86 |
ESA 87 |
HTS 88 |
HTJ 89 |
VTS 8A |
PLD 8B |
PLU 8C |
RI 8D |
SS2 8E |
SS3 8F |
9. |
DCS 90 |
PU1 91 |
PU2 92 |
STS 93 |
CCH 94 |
MW 95 |
SPA 96 |
EPA 97 |
SOS 98 |
SGCI 99 |
SCI 9A |
CSI 9B |
ST 9C |
OSC 9D |
PM 9E |
APC 9F |
A. |
A0 |
Ё 401 |
Ђ 402 |
Ѓ 403 |
Є 404 |
Ѕ 405 |
І 406 |
Ї 407 |
Ј 408 |
Љ 409 |
Њ 40A |
Ћ 40B |
Ќ 40C |
SHY AD |
Ў 40E |
Џ 40F |
B. |
А 410 |
Б 411 |
В 412 |
Г 413 |
Д 414 |
Е 415 |
Ж 416 |
З 417 |
И 418 |
Й 419 |
К 41A |
Л 41B |
М 41C |
Н 41D |
О 41E |
П 41F |
C. |
Р 420 |
С 421 |
Т 422 |
У 423 |
Ф 424 |
Х 425 |
Ц 426 |
Ч 427 |
Ш 428 |
Щ 429 |
Ъ 42A |
Ы 42B |
Ь 42C |
Э 42D |
Ю 42E |
Я 42F |
D. |
а 430 |
б 431 |
в 432 |
г 433 |
д 434 |
е 435 |
ж 436 |
з 437 |
и 438 |
й 439 |
к 43A |
л 43B |
м 43C |
н 43D |
о 43E |
п 43F |
E. |
р 440 |
с 441 |
т 442 |
у 443 |
ф 444 |
х 445 |
ц 446 |
ч 447 |
ш 448 |
щ 449 |
ъ 44A |
ы 44B |
ь 44C |
э 44D |
ю 44E |
я 44F |
F. |
№ 2116 |
ё 451 |
ђ 452 |
ѓ 453 |
є 454 |
ѕ 455 |
і 456 |
ї 457 |
ј 458 |
љ 459 |
њ 45A |
ћ 45B |
ќ 45C |
§ A7 |
ў 45E |
џ 45F |
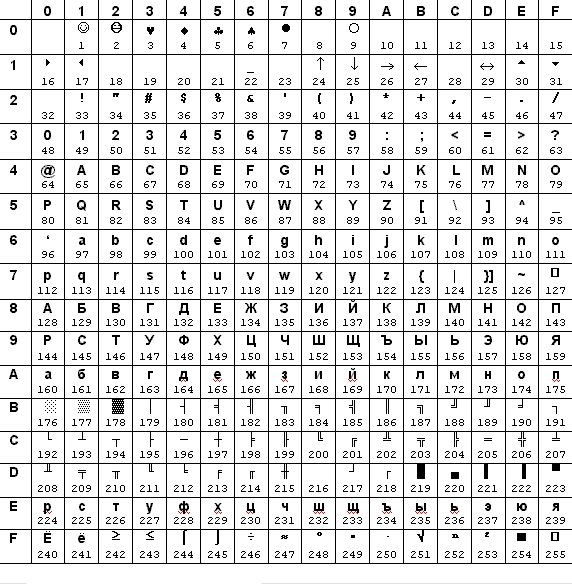
CP866
Кодировка CP866 (Code Page 866, кодовая страница) в настоящее время можно назвать реликтом, поскольку ее используют компьютеры, работающие под операционной системой MS DOS и OS/2. Её же использует сеть ФИДО.
Эта кодировка (иначе называется "альтернативная" кодировка), отличалась от ISO-8859-5 порядком следования русских букв до строчной "р", а символы псевдографики кодировались в ней теми же кодами, что и в исходной английской таблице символов. Следовательно, при принятии операционной системой этого варианта кодовой страницы можно было использовать нелокализованные версии западных программ, работающих с псевдографикой. Например, западная программа могла из символов псевдографики изобразить таблицу. Если в системе была установлена "альтернативная" кодовая страница, то символ псевдографики оказывался на нужном месте, и рисунок получался. Напомним, что «если в системе стояла ISO-8859-5, то рисовалась русская буква, и внешний вид рисунка был весьма своеобразным». Поэтому, несмотря на то, что в "альтернативной" кодовой странице русские символы шли не подряд, а с разрывом между строчными буквами "п" и "р", именно она впоследствии получила наибольшее распространение. Кодовая страница ISO-8859-5 применялась при русификации компьютерных систем Sun, поставлявшихся в Россию.
Заслуга внедрения русских кодовых страниц принадлежит российской компании "Диалог" и ее ведущему программисту Петру Квитеку. В 1989 году в этой фирме-партнере Microsoft была локализована MS-DOS 4.1 – первой из всех операционных систем. При ее создании в качестве основной кодовой страницы была взята "альтернативная" кодировка, названная DOS (кодовая страница 866) - именно из-за того, что программы, использующие ее, корректно отображали символы псевдографики. Так как MS DOS стала основной операционной системой для персональных компьютеров, это привело к еще более широкому распространению данной кодовой страницы.
«Альтернативная» кодовая таблица, CP866:
Win1251 (CP1251)
При создании локализованной версии операционной системы Windows фирма Microsoft решила создать собственную кодовую страницу для кириллицы. В частности, с появлением графического интерфейса отпала необходимость в использовании символов псевдографики, что позволило сделать последовательным порядок символов русского алфавита в кодовой странице, а также разместить в ней различные специальные символы вроде изображения торговой марки и др. Появилась кодировка Windows (кодовая страница 1251), которую создал тот же Петр Квитек. В ней тем символам, что в кодировке DOS (866) соответствовали одни русские буквы, были поставлены в соответствие другие символы. В результате для чтения в Windows русского текста, набранного в DOS, стали требоваться программы-перекодировщики.
Примечание: Альтернативная кодировка не подошла для ОС Windows. Пришлось передвинуть русские буквы в таблице на место псевдографики, и получили кодировку Windows 1251 (Win-1251).
Данная кодировка Win1251 (CP1251, Code Page 1251, кодовая страница) сейчас является одной из наиболее распространенных в сети Интернет и персональных компьютерах (на которых установлена операционная система Windows). Все Windows приложения должны понимать эту кодировку без перевода.
Windows-1251 – набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Пользуется довольно большой популярностью. Была создана на базе кодировок, использовавшихся в ранних «самопальных» русификаторах Windows в 1990–1991 гг. совместно представителями «Параграфа», «Диалога» и российского отделения Microsoft. Первоначальный вариант кодировки сильно отличался от представленного ниже в таблице (в частности, там было значительное число «белых пятен»).
Windows-1251 выгодно отличается от других 8‑битных кириллических кодировок (таких как CP866, KOI8-R и ISO-8859-5) наличием практически всех символов, использующихся в русской типографике для обычного текста (отсутствует только значок ударения); она также содержит все символы для близких к русскому языку языков: украинского, белорусского, сербского и болгарского.
Если к кириллическому тексту в кодировке Windows-1251 20 раз подряд применить перекодирование KOI8-R→Windows-1251, в итоге будет получен исходный текст.
Имеет два недостатка:
строчная буква «я» имеет код 0xFF (255 в десятичной системе). Она является «виновницей» ряда неожиданных проблем в программах без поддержки чистого 8-го бита, а также (гораздо более частый случай) использующих этот код как служебный (в CP437 он обозначает «неразрывный пробел», в Windows-1252 – ÿ, оба варианта практически не используются; число же -1, в дополнительном коде длиной 8 бит представляющееся числом 255, часто используется в программировании как специальное значение, например, индикатор конца файла EOF часто представляется значением -1).
отсутствуют символы псевдографики, имеющиеся в CP866 и KOI8 (хотя для самих Windows, для которых она предназначена, в них не было нужды, это делало несовместимость двух использовавшихся в них кодировок заметнее).
Таблицы
Нижняя часть таблицы кодировки (латиница) полностью соответствует кодировке ASCII. Числа под буквами обозначают 16-ричный код подходящего символа в Юникоде.
Кодировка Windows-1251 (синоним CP1251)
(только нижняя часть, нумерация в виде шестнадцатеричных чисел)
|
.0 |
.1 |
.2 |
.3 |
.4 |
.5 |
.6 |
.7 |
.8 |
.9 |
.A |
.B |
.C |
.D |
.E |
.F |
8. |
Ђ 402 |
Ѓ 403 |
‚ 201A |
ѓ 453 |
„ 201E |
… 2026 |
† 2020 |
‡ 2021 |
€ 20AC |
‰ 2030 |
Љ 409 |
‹ 2039 |
Њ 40A |
Ќ 40C |
Ћ 40B |
Џ 40F |
9. |
ђ 452 |
‘ 2018 |
’ 2019 |
“ 201C |
” 201D |
• 2022 |
– 2013 |
— 2014 |
|
™ 2122 |
љ 459 |
› 203A |
њ 45A |
ќ 45C |
ћ 45B |
џ 45F |
A. |
A0 |
Ў 40E |
ў 45E |
Ј 408 |
¤ A4 |
Ґ 490 |
¦ A6 |
§ A7 |
Ё 401 |
© A9 |
Є 404 |
« AB |
¬ AC |
AD |
® AE |
Ї 407 |
B. |
° B0 |
± B1 |
І 406 |
і 456 |
ґ 491 |
µ B5 |
¶ B6 |
· B7 |
ё 451 |
№ 2116 |
є 454 |
» BB |
ј 458 |
Ѕ 405 |
ѕ 455 |
ї 457 |
C. |
А 410 |
Б 411 |
В 412 |
Г 413 |
Д 414 |
Е 415 |
Ж 416 |
З 417 |
И 418 |
Й 419 |
К 41A |
Л 41B |
М 41C |
Н 41D |
О 41E |
П 41F |
D. |
Р 420 |
С 421 |
Т 422 |
У 423 |
Ф 424 |
Х 425 |
Ц 426 |
Ч 427 |
Ш 428 |
Щ 429 |
Ъ 42A |
Ы 42B |
Ь 42C |
Э 42D |
Ю 42E |
Я 42F |
E. |
а 430 |
б 431 |
в 432 |
г 433 |
д 434 |
е 435 |
ж 436 |
з 437 |
и 438 |
й 439 |
к 43A |
л 43B |
м 43C |
н 43D |
о 43E |
п 43F |
F. |
р 440 |
с 441 |
т 442 |
у 443 |
ф 444 |
х 445 |
ц 446 |
ч 447 |
ш 448 |
щ 449 |
ъ 44A |
ы 44B |
ь 44C |
э 44D |
ю 44E |
я 44F |
Кодовая таблица Windows (CP-1251)
(полная таблица, нумерация в виде десятичных чисел)

KOI-8
В то время как на рынке операционных систем для персональных компьютеров безоговорочную победу одержала MS-DOS, среди операционных систем для сетей дело обстояло не так. Там начинала властвовать UNIX - операционная система, построенная на несколько других принципах. Эта система имела открытый исходный код - любой программист мог создать "свою" UNIX, настроенную именно на его предпочтения, что было очень удобно для программирования. И эта операционная система весьма бурно развивалась в сетевом отношении. Понятие кодовой страницы в UNIX имело несколько другое значение, но на этом мы сейчас останавливаться не будем.
Всемирная Сеть изначально зародилась и начала развиваться в Америке. Поэтому вся система почтовых серверов вначале была предназначена для работы с почтой англоязычных пользователей, пишущих таким же англоязычным. Так как использование в текстовых сообщениях, которые составляли тогда единственное содержимое электронной почты, символов псевдографики было отнюдь не обязательно (хватит и простого текста!), то программы, работающие с электронной почтой, делались в расчете на первую половину кодовой страницы - на семибитную кодировку.
Ясно, что текстовые сообщения, содержащие символы с кодами, большими 127 и не могущие быть закодированы восемью битами, нормально такими серверами обрабатываться не могли. Для того, чтобы такие письма все же как-нибудь проходили через семибитные почтовые серверы, символы сообщений принудительно приводились к семибитному виду - у них обнулялся первый бит, указывающий на половину их кодовой страницы. Например, символ "е" (русская буква е) переходил в "f", символ "ш" - в "y". Дальше шло уже обработанное таким образом письмо.
Если бы все почтовые сервера тогда были восьмибитные, то пересылка через них русскоязычной почты не составляла бы проблем – лишь бы компьютеры отправителя и получателя поддерживали бы русскую кодовую страницу. Но "обрезающие" сервера не позволяли так делать.
Выходы были. Первый, самый тогда распространенный – писать письмо транслитом, latinskimi bukvami. Некрасиво и плохо читаемо, зато надежно – дойдет в исходном виде в любом случае. Но, поскольку всё же не все почтовые сервера были семибитные, была создана специальная кодировка для электронной почты, которая отличалась тем, что на места, соответствующие кодам символов, большим 127, были поставлены русские символы, похожие по звучанию на английские буквы на местах, соответствующих кодам символов, меньших на 128. Иными словами, в этой новой кодировке коды 225, 226, 227, 228 соответствовали символам "а", "б", "ц", "д", которые при семибитном преобразовании перешли бы в коды 97, 98, 99, 100, соответствующие английским буквам "a", "b", "c", "d". Слово "привет", написанное в новой кодировке, пройдя через семибитный почтовый сервер, перешло бы в слово "PRIWET", что еще хоть как-то читаемо. Ну, а если бы письму повезло, и на его пути не встретились семибитные сервера, то оно дошло бы в исходном виде.
Новая кодировка была названа KOI-8. Так как системы на основе UNIX были в основном рассчитаны на работу с электронной почтой и международными сетями, то она стала стандартом для этой системы. Количество семибитных серверов стало понемногу сокращаться, сейчас их уже почти совсем в мире не осталось, а кодировка KOI-8 так и осталась.
KOI-8 использовалась не только UNIX-системами. Так, любой пользователь персонального компьютера под управлением MS-DOS или Windows, имеющий выход к электронной почте, должен был иметь у себя программу для получения и отправки сообщений, умеющую работать с KOI-8. Выход к системе электронной почты был возможен и с компьютеров фирмы Apple - с Макинтошей, однако в операционных системах для этих компьютеров использовалась своя, оригинальная русская кодировка символов, отличающаяся от всех остальных. Для того чтобы облегчить переписку между пользователями разных типов компьютеров и операционных систем, KOI-8 была рекомендована как универсальная кодировка, и любая почтовая программа была обязана уметь читать и отправлять сообщения в ней.
Итак: КОИ-8 является стандартной русской кодовой таблицей на компьютерах, работающих под управлением операционной системы UNIX. И код КОИ-8 фактически стал стандартом для представления русскоязычных текстов в глобальной компьютерной сети Internet.
Кодировка KOI-8R (KOИ-8, Код Обмена Информацией, 8-ми битный) позволяет кодировать 28 = 256 символов, в число которых входят 31 прописная и 32 строчных букв русского алфавита, 26 прописных и 26 строчных букв латинского алфавита, 10 цифр, 32 служебных знака и специальные символы, предназначенные для управления устройствами и передачи данных. Коды в диапазоне 21-5F соответствуют одинаковым символам как для KOI-7, так и для KOI-8R.
Код |
Символ |
Код |
Символ |
Код |
Символ |
Код |
Символ |
Код |
Символ |
Код |
Символ |
Код |
Символ |
Код |
Символ |
Код |
Символ |
Код |
Символ |
20 |
пробел |
30 |
0 |
40 |
@ |
50 |
P |
60 |
\ |
70 |
p |
С0 |
ю |
D0 |
п |
E0 |
Ю |
F0 |
П |
21 |
! |
31 |
1 |
41 |
A |
51 |
Q |
61 |
а |
71 |
q |
С1 |
а |
D1 |
я |
E1 |
А |
F1 |
Я |
22 |
" |
32 |
2 |
42 |
B |
52 |
R |
62 |
b |
72 |
r |
С2 |
б |
D2 |
р |
E2 |
Б |
F2 |
Р |
23 |
# |
33 |
3 |
43 |
C |
53 |
S |
63 |
c |
73 |
s |
С3 |
ц |
D3 |
с |
E3 |
Ц |
F3 |
С |
24 |
$ |
34 |
4 |
44 |
D |
54 |
T |
64 |
d |
74 |
t |
С4 |
д |
D4 |
т |
E4 |
Д |
F4 |
Т |
25 |
% |
35 |
5 |
45 |
E |
55 |
U |
65 |
e |
75 |
u |
С5 |
е |
D5 |
у |
E5 |
Е |
F5 |
У |
26 |
& |
36 |
6 |
46 |
F |
56 |
V |
66 |
f |
76 |
v |
С6 |
ф |
D6 |
ж |
E6 |
Ф |
F6 |
Ж |
27 |
' |
37 |
7 |
47 |
G |
57 |
W |
67 |
g |
77 |
w |
С7 |
г |
D7 |
в |
E7 |
Г |
F7 |
В |
28 |
( |
38 |
8 |
48 |
H |
58 |
X |
68 |
h |
78 |
x |
С8 |
х |
D8 |
ь |
E8 |
Х |
F8 |
Ь |
29 |
) |
39 |
9 |
49 |
I |
59 |
Y |
69 |
i |
79 |
y |
С9 |
и |
D9 |
ы |
E9 |
И |
F9 |
Ы |
2A |
* |
3A |
: |
4A |
J |
5A |
Z |
6A |
j |
7A |
z |
СA |
й |
DA |
з |
EA |
Й |
FA |
З |
2B |
+ |
3B |
; |
4B |
K |
5B |
[ |
6B |
k |
7B |
( |
СB |
к |
DB |
ш |
EB |
Х |
FB |
Ш |
2C |
, |
3C |
< |
4C |
L |
5C |
\ |
6C |
l |
7C |
| |
СС |
л |
DC |
э |
EC |
Л |
FC |
Э |
2D |
- |
3D |
= |
4D |
M |
5D |
] |
6D |
m |
7D |
) |
СD |
м |
DD |
щ |
ED |
М |
FD |
Щ |
2E |
. |
3E |
> |
4E |
N |
5E |
^ |
6E |
n |
7E |
- |
СE |
н |
DE |
ч |
EE |
Н |
FE |
Ч |
2F |
/ |
3F |
? |
4F |
O |
5F |
Ъ |
6F |
o |
7F |
"забой" |
CF |
о |
DF |
ъ |
EF |
О |
FF |
"забой" |
Дополнительно. Примечание.
KOI-7
Появление:
Первые попытки русифицировать компьютеры начались еще до появления DOS. Семибитным кодам присвоили кириллические символы вместо латинских по примерному фонетическому соответствию. Система получила название KOI-7 (сокращение от Код Обработки Информации). С появлением полнобайтного кода кириллицей заменили альтернативные латинские символы с кодами-номерами от 192 до 256 (в двоичной системе это были номера, начинающиеся не с нуля, а с единицы, т.е. на разряд выше (например, десятеричные числа 126, 127, 128, 129 заполняют восемь ячеек памяти по двоичной системе как 01111110, 01111111, 10000000, 10000001)).
Так родилась кодировка KOI-8, объединяющая в одном коде латиницу с кириллицей. Ниже дана таблица кодов кириллицы в кодировке KOI-8.
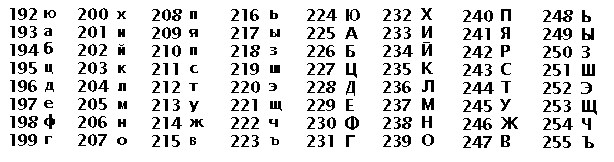
Описание:
Кодировка KOI-7 (KOИ-7, Код Обмена Информацией, 7-ми битный) позволяет кодировать 27 = 128 символов, из которых 32 буквы русского алфавита, 26 букв латинского алфавита, 10 цифр и 26 печатаемых символа, пробел, специальные символы и непечатаемые символы. Коды непечатаемых символов находятся в диапазоне 00-20 (с ними можно ознакомиться в таблице ASCII).
Замечательным правилом, действующим в этой кодировке, является весовой принцип кодирования латинских символов, для которого верно правило: Веса кодов букв латинского алфавита увеличиваются на единицу в алфавитном порядке, то есть:
Код последующего символа = Код предыдущего символа + 1, или
Код D = Код C + 1, и так далее...
Пользуясь этим правилом, можно легко располагать слова в алфавитном порядке, поскольку эта операция сводится к простому сравнению двоичных чисел, соответствующих кодам символов. Для русских символов этот принцип несправедлив.
Каждый символ в кодировке KOI-7 представлен восьмиразрядным двоичным числом (фактически, это один байт). Младшие 7 знакомест предназначены для кода самого символа, а самый старший бит называется разрядом контроля четности и очень часто используется для контроля ошибок, особенно при передаче данных. В этот разряд вписывают такое число (0 или 1), чтобы сумма единиц, содержащихся в коде данного символа, было четным.
Число |
Символ |
Число |
Символ |
Число |
Символ |
Число |
Символ |
Число |
Символ |
Число |
Символ |
20 |
пробел |
30 |
0 |
40 |
@ |
50 |
P |
60 |
Ю |
70 |
П |
21 |
! |
31 |
1 |
41 |
A |
51 |
Q |
61 |
А |
71 |
Я |
22 |
" |
32 |
2 |
42 |
B |
52 |
R |
62 |
Б |
72 |
Р |
23 |
# |
33 |
3 |
43 |
C |
53 |
S |
63 |
С |
73 |
С |
24 |
$ |
34 |
4 |
44 |
D |
54 |
T |
64 |
Д |
74 |
Т |
25 |
% |
35 |
5 |
45 |
E |
55 |
U |
65 |
Е |
75 |
У |
26 |
& |
36 |
6 |
46 |
F |
56 |
V |
66 |
Ф |
76 |
Ж |
27 |
' |
37 |
7 |
47 |
G |
57 |
W |
67 |
Г |
77 |
В |
28 |
( |
38 |
8 |
48 |
H |
58 |
X |
68 |
Х |
78 |
Ь |
29 |
) |
39 |
9 |
49 |
I |
59 |
Y |
69 |
И |
79 |
Ы |
2A |
* |
3A |
: |
4A |
J |
5A |
Z |
6A |
Й |
7A |
З |
2B |
+ |
3B |
; |
4B |
K |
5B |
[ |
6B |
К |
7B |
Ш |
2C |
, |
3C |
< |
4C |
L |
5C |
\ |
6C |
Л |
7C |
Э |
2D |
- |
3D |
= |
4D |
M |
5D |
] |
6D |
М |
7D |
Щ |
2E |
. |
3E |
> |
4E |
N |
5E |
^ |
6E |
Н |
7E |
Ч |
2F |
/ |
3F |
? |
4F |
O |
5F |
Ъ |
6F |
О |
7F |
"забой" |
Unicode
В ранних версиях Windows для каждой кодовой страницы должен был иметься свой шрифт, так как в один шрифтовой файл – в одну кодовую страницу – нельзя было поместить больше 255 символов. Это имело определенные неудобства, и был придуман и утвержден новый стандарт таблицы символов – Unicode. Согласно этому стандарту, каждый символ кодировался не восемью, а шестнадцатью битами информации, что позволяло закодировать до 65536 символов. Эта кодировка также получила название двухбайтовой кодировки. Для совместимости со старыми стандартами первые 256 символов стандарта Unicode соответствовали стандартной кодовой таблице, а на остальных местах можно было разместить все необходимые символы всех языков. Соответственно, были созданы новые шрифты в стандарте Unicode.
В Unicode-шрифте имеются как бы несколько кодовых страниц сразу. Программа, работающая с таким шрифтом, использует символы нужной ей кодовой страницы. Для того, чтобы программы, не поддерживающие стандарт Unicode (например, Microsoft Word 6.0), могли работать с такими шрифтами, операционная система осуществляет так называемую "подстановку шрифтов", то есть "раскладывает" шрифт Unicode на отдельные кодовые страницы и выбирает из них ту страницу, которая соответствует установленной в системе. Параметры подстановки прописываются в системном реестре и в файле win.ini. Смысл находящихся в этом файле выражений – указание программам на то, где в шрифтовом файле искать символы, соответствующие нужной кодовой странице. Так, для шрифта Times New Roman эти символы (кириллица) начинаются с 204-го места, что и указано в win.ini. Теперь Microsoft Word 6.0 спокойно будет работать с Unicode-шрифтом Times New Roman, воспринимая его как обычный кириллический шрифт. При этом в восприятии Word 6.0 шрифт Times New Roman окажется как бы "разложенным" на набор шрифтов (Times New Roman Cyr, Times New Roman CE и др.), каждый из которых будет соответствовать определенной кодовой странице, несмотря на то, что все эти шрифты хранятся в одном файле.
Иногда встречается ситуация, когда Microsoft Word вполне нормально отображает текст на экране, но на принтер выводится набор квадратиков. Это вот как раз проявляется некорректное взаимодействие программного обеспечения, когда одни компоненты (Word) поддерживают новый стандарт, а другие – нет. (Пути преодоления этой проблемы таковы: либо установить новые драйвера к принтеру, либо в системном реестре, в разделе "HKEY_CURRENT_USER\Software\Microsoft\Office\8.0\Word\<имя принтера>" создать новую строковую переменную "Flags" со значением "8192", либо в системном реестре, в разделе "Font Substitution" для всех русских шрифтов, при печати которых выводятся квадратики, надо написать: Font,0=Font,204 и Font,204=Font,204. То же самое надо поместить и в win.ini.)
В январе 1991 года возник консорциум UNICODE (Unicode Consortium), целью которого является продвижение, развитие и реализация стандарта Unicode как международной системы кодирования для обмена информацией, а также поддержание качества этого стандарта в будущих версиях.
Стандарт UNICODE 4.0 представляет собой новую систему кодирования символов, выводимых на экран монитора или на принтер, позволяющую закодировать 1 114 112 символов (в стандарте из принято называть code points). Большинство символов, используемых в основных языках мира занимают 65 536 code points, образуя Basic Multilingual Plane (BMP) (Основной Многоязычный Уровень). Оставшиеся (более миллиона) code points вполне достаточно для кодирования всех известных символов, включая малораспространенные языки и исторические знаки. Стандарт UNICODE поддерживается тремя формами, 32-битной (UTF-32), 16-битной (UTF-16) и 8-битной (UTF-8). Восьмибитная форма UTF-8 была разработана для удобной совместимости с ASCII-ориентироваными системами кодирования. Стандарт UNICODE совместим с Международным стандартом International Standard ISO/IEC 10646.
Наиболее просто устроена форма UTF-32. В ней каждый символ закодирован при помощи 32-битного блока. Благодаря этому каждый символ UTF-32 обладает однозначным соответствием между декодированным символом и блоком кода. Это форма имеет фиксированную длину знакоместа. Она покрывает все кодовое пространство UNICODE - 0...10FFFF16. Это гарантирует полную совместимость с UTF-16 и UTF-8. Форма UTF-32 является наиболее предпочитаемой для большинства UNIX платформ.
Стандарт UNICODE содержит 96 382 символа, взятых их мировых шрифтов. Этих символов более чем достатонно для общения на всех известных языках мира, а также для написания классических (исторических) шрифтов многих языков. UNICODE всключает в себя шрифты европейских алфавитов, средне-азиатское письмо, направленное справа на лево, шрифты Азии, и многие другие. Подмножество символов (code points) HUN включает 70 207 идеографических символов определяемых по национальным и промышленным стандартам Китая, Японии, Кореи, Тайвани, Вьетнама и Сингапура. Более того, UNICODE содержит знаки пунктуации, математические символы, технические символы, герметрические фотмы и графические метки (dingbats), фонетические знаки.
Ниже приведена сравнительная таблица кодов ASCII и UNICODE, взятая из Фрагмента спецификации UNICODE 4.0 (Unicode Standard, Version 4.0), размещенного на сайте Unicode Consortium.
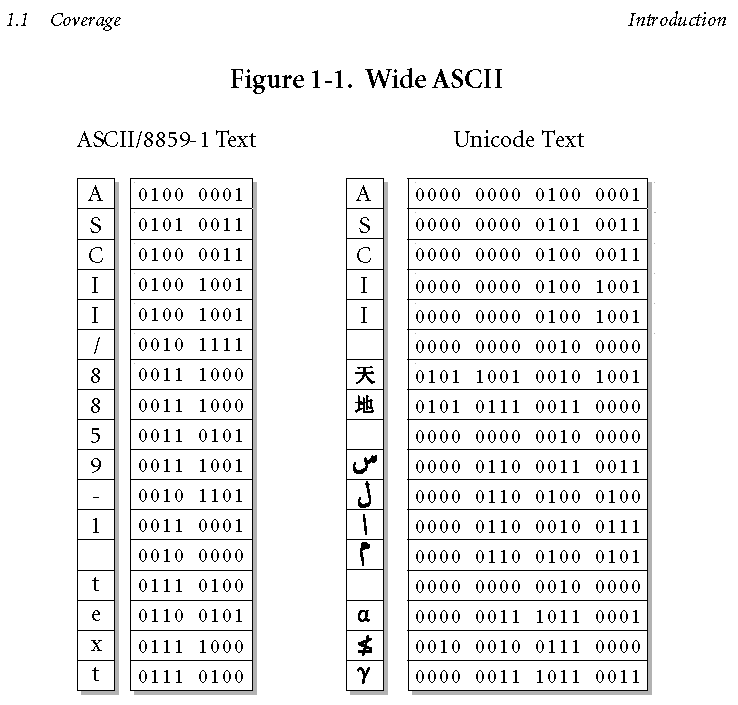
Кодовая таблица для кириллицы приведена на следующем рисунке (взято из Фрагмента спецификации UNICODE 4.0 (Unicode Standard, Version 4.0), размещенного на сайте Unicode Consortium.

Полная спецификация стандарта Unicode включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и прочих символов.