

2. Исследование тракта кодер-декодер источника
1. Источник сообщений на передающей стороне представляет собой дискретный источник без памяти с алфавитом из 16 символов. Вероятности выдачи каждого символа источником и скорость выдачи символов известны. Для заданного источника найдём энтропию, избыточность и производительность.
Энтропия
источника
– это средняя информативность источника
на один символ, определяющая «неожиданность»
или «непредсказуемость» выдаваемых им
сообщений. Она
равна нулю, если с вероятностью равной
единице источником выдается всегда
одно и то же сообщение (в этом случае
неопределенность в поведении ИС
отсутствует). Энтропия максимальна,
если сообщения выдаваемые источником
появляются независимо и с одинаковой
вероятностью. В этом случае она равна
![]() .
.
![]() [бит/симв]
[бит/симв]
Избыточность – информационная характеристика дискретного источника. Избыточность приводит к тому, что за заданный промежуток времени будет передано меньше сообщений, и, следовательно, менее эффективно будет использоваться канал передачи дискретных сообщений. Задачу устранения избыточности при передаче выполняет кодер источника.
![]()
где К = 16 – объем алфавита.
Производительность – средняя энтропия в единицу времени, то есть среднее количество информации, выдаваемое источником в единицу времени.
![]() [бит/с]
[бит/с]
2. Найдем минимально необходимое число разрядов кодового слова, при условии, что производится примитивное кодирование:
![]()
Найдем среднее количество двоичных символов, приходящееся на один символ источника, при условии примитивного кодирования:
Среднее
количество двоичных символов
![]() ,
приходящееся на один символ источника,
будет равно k,
т.е.:
,
приходящееся на один символ источника,
будет равно k,
т.е.:
![]() (т.к.
все символы представляются комбинациями
с одинаковым числом разрядов).
(т.к.
все символы представляются комбинациями
с одинаковым числом разрядов).
3. Построение кодового дерева неравномерного кода Шеннона - Фано:
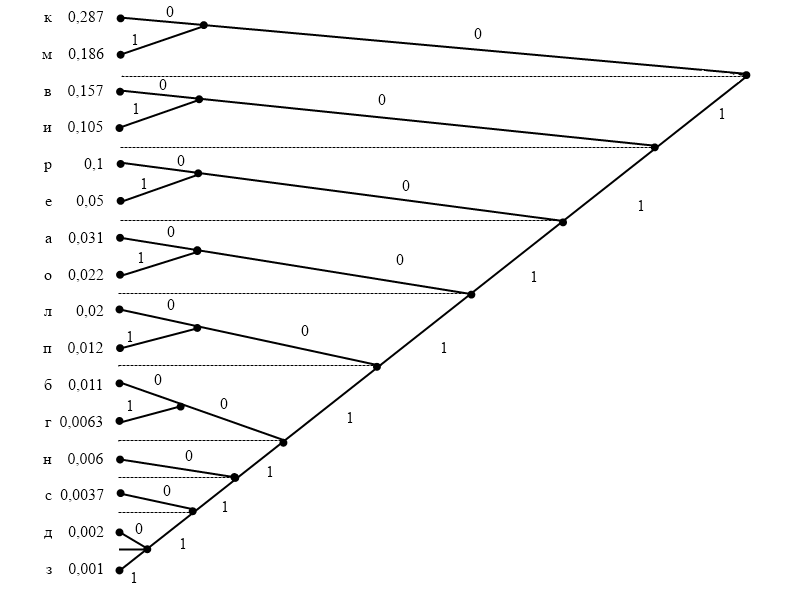
Рис. 2. Построение кодового дерева кода Шеннона – Фано.
Символ источника |
Вероятность р(аi) |
Код |
ki |
ki0 |
ki1 |
ki* р(аi) |
к |
0,287 |
00 |
2 |
2 |
0 |
0,372 |
м |
0,186 |
01 |
2 |
1 |
1 |
0,489 |
в |
0,157 |
100 |
3 |
2 |
1 |
0,471 |
и |
0,105 |
101 |
3 |
1 |
2 |
0,465 |
р |
0,1 |
1100 |
4 |
2 |
2 |
0,315 |
е |
0,05 |
1101 |
4 |
1 |
3 |
0,3 |
а |
0,031 |
11100 |
5 |
2 |
3 |
0,25 |
о |
0,022 |
11101 |
5 |
1 |
4 |
0,1 |
л |
0,02 |
111100 |
6 |
2 |
4 |
0,084 |
п |
0,012 |
111101 |
6 |
1 |
5 |
0,084 |
б |
0,011 |
1111100 |
7 |
2 |
5 |
0,077 |
г |
0,0063 |
1111101 |
7 |
1 |
6 |
0,07 |
н |
0,006 |
1111110 |
7 |
1 |
6 |
0,0441 |
с |
0,0037 |
11111110 |
8 |
1 |
7 |
0,042 |
д |
0,002 |
111111110 |
9 |
1 |
8 |
0,0296 |
з |
0,001 |
111111111 |
9 |
0 |
9 |
0,008 |
Среднее количество двоичных символов, приходящееся на один символ источника:
![]() [симв]
[симв]
Энтропия на выходе кодера:
![]() [бит/симв]
[бит/симв]
Избыточность на выходе кодера:
![]()
Код
Шеннона-Фано приблизил значение среднего
количества двоичных символов,
приходящееся на один символ источника
к энтропии источника
![]() [бит/симв].
Избыточность на выходе кодера
[бит/симв].
Избыточность на выходе кодера
![]() меньше
избыточности источника
меньше
избыточности источника
![]() .
.
Вывод: Примитивное кодирование применяется для согласования алфавита источника и алфавита канала. Отличительное свойство этого кодирования состоит в том, что избыточность дискретного источника, образованного выходом примитивного кодера, равна избыточности источника на входе кодера.
Экономное кодирование или сжатие данных применяется для уменьшения времени передачи информации или требуемого объёма памяти при её хранении. Отличительное свойство экономного кодирования состоит в том, что избыточность источника, образованного выходом кодера, меньше избыточности источника на входе кодера.
4. Вероятность двоичных символов:
![]()
![]()
![]()
Средняя скорость выдачи символов на выходе кодера источника:
![]() [симв/с]
[симв/с]
5. Описание процедуры кодирования и декодирования символов экономным кодом:
Процедура кодирования кодом Шеннона-Фано сводится к тому, что поэтапно, начиная от символа с максимальной вероятностью, массив символов источника делится на две группы с примерно равными суммарными вероятностями. Символам первой группы приписывается кодовый символ 1 (или 0), символам второй группы приписывается кодовый символ 0 (или 1). Формирование кодовой комбинации идёт справа налево. Этот код незначительно проигрывает по эффективности коду Хаффмана.
При кодировании происходит процесс преобразования элементов сообщения в соответствующие им числа (кодовые символы). Каждому элементу сообщения присваивается определенная совокупность кодовых символов, которая называется кодовой комбинацией. Совокупность кодовых комбинаций, отображающих дискретные сообщения, образует код. Правило кодирования может быть выражено кодовой таблицей, в которой приводятся алфавит кодируемых сообщений и соответствующие им кодовые комбинации. Множество возможных кодовых символов называется кодовым алфавитом, а их количество m - основанием кода. Число разрядов n, образующих кодовую комбинацию, называется разрядностью кода или длиной кодовой комбинации.

M – размер алфавита информационного символа;
m - размер алфавита кодового символа;
k – длина информационной комбинации;
n - длина кодовой комбинации.
На вход кодера поступает последовательность информационных символов bi в виде информационной комбинации b, длиной k. При помощи кодера каждой информационной комбинации присваивается совокупность кодовых символов, таким образом на выходе кодера образуется кодовая последовательность c длиной n.
В системах передачи дискретных сообщений обычно в результате демодуляции последовательность элементов сигнала превращается в последовательность кодовых символов. Затем по ним восстанавливаются сообщения, выдаваемые получателю. Последнее преобразование называется декодированием. В результате различных искажений и воздействия помех пришедший сигнал может существенно отличаться от переданного.