

Билет 19
Внутренняя модель данных. Индексы и их разновидности. Плюсы и минусы индексации.
Внутренняя модель данных БД - модель данных и доступа к данным, отражающая их структуру на физическом уровне БД. Она содержит описание форматов данных и дополнительных структур, необходимых для эффективного управления и доступа.
Индексы - объект базы данных, создаваемый с целью повышения производительности поиска данных. Проще всего индексы сравнить с указателями в книгах.
И ндекс
формируется из значений одного или
нескольких столбцов таблицы и указателей
на соответствующие строки таблицы. В
самом простом случае индекс – таблица
из двух полей: ключа индексации в сорт.
порядке и адреса записи файла с этим
ключом.
ндекс
формируется из значений одного или
нескольких столбцов таблицы и указателей
на соответствующие строки таблицы. В
самом простом случае индекс – таблица
из двух полей: ключа индексации в сорт.
порядке и адреса записи файла с этим
ключом.
Разновидности индексов
Плотный индекс – для каждой записи файла создается запись в индексе.
Неплотный (разреженный) индекс – одна запись в индексе для нескольких записей файла.
Реализация индексов
Индексы могут быть реализованы различными структурами. Наиболее часто используются B-деревья и хеши.
Достоинства и недостатки индексации
+ : ускорение выборки данных, возможность сортировки без физ. перестановки записей
- : использование дополнительной памяти, увеличение сложности выполнения технологически операций
Билет 20
В-дерево. Операции с B-деревом
B-дерево порядка n – сильно ветвящееся сбалансированное дерево поиска степени (2n+1). Структура B-дерева применяется для организации индексов во многих современных СУБД.
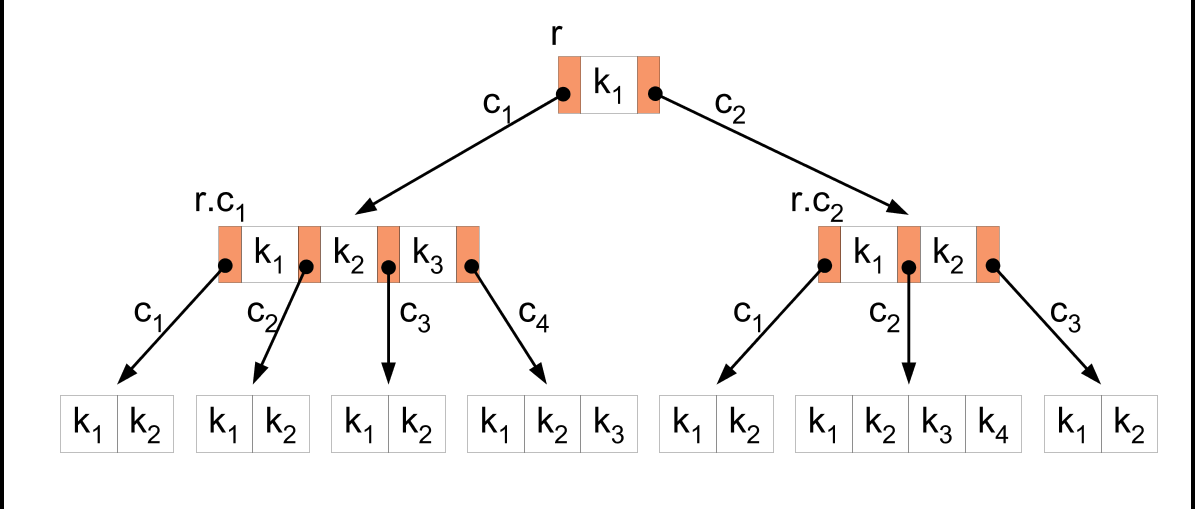
B-дерево степени 2
Свойства B-дерева
Сбалансированность — длина любых двух путей от корня до листов различается не более чем на единицу.
Ветвистость — каждый узел дерева ссылается на большое число узлов-потомков.
Каждый узел кроме корня содержит не менее n и не более 2n ключей.
Корень содержит не менее 1 и не более 2n ключей.
Все листья расположены на одном уровне.
Каждый нелистовой узел имеет кол-во исходящих ребер на 1 больше числа ключей.
С каждым ключом связан указатель на запись файла с тем же ключом индексации (на рисунке k1, k2…,kn – ключи индексации в сорт. порядке)
B-дерево растет от листьев к корню
С точки зрения физической организации B-дерево - мультисписочная структура страниц внешней памяти, то есть каждому узлу дерева соответствует блок внешней памяти (страница).
Операции с B-деревьями
Поиск
Пусть мы ищем значение X (ключ) в заданном В-дереве.
Начинаем от корня
Если X – это один из ключей текущего узла, то СТОП, ключ найден.
Иначе находим пару соседних ключей Y, Z, таких что X лежит в интервале от Y до Z
Переходим к потомку между Y и Z
Идём на шаг 2
Если мы дошли до листа и Х не содержится среди ключей, то СТОП, такого значения в дереве нет
Добавление элемента (ключа)
Убеждаемся, что добавляемый ключ отсутствует в дереве
Ищем лист, в который можно добавить ключ, совершая проход от корня к листьям.
Если найденный лист не заполнен, добавляем в него ключ.
Иначе разбиваем узел на два узла, в первый добавляем первые (n -1) ключей, во второй — последние (n – 1) ключей.
Добавляем ключ в один из этих узлов.
Оставшийся средний элемент добавляем в узел родителя, если он заполнен — повторяем пока не встретим не заполненный узел или не дойдем до корня.
В последнем случае корень разбивается на два узла и высота дерева увеличивается.
Удаление элемента (ключа)
Ищем узел, содержащий нужный ключ. Если он в листе, и лист содержит не менее (n+1) ключей, ключ просто удаляется.
В противном случае, если существует соседний лист, который содержит больше (n -1) ключа, удалим ключ из исходного узла, на его место поставим ключ-разделитель между исходным узлом и его соседом, а на его место поставим первый, если сосед правый, или последний, если сосед левый, ключ соседа.
Если все соседи содержат по (n-1)ключу, то объединяем узел с каким-либо из соседей, удаляем ключ и добавляем ключ-разделитель между узлами в объединенный узел.
Если в родительском узле осталось меньше (n-1) ключа, аналогичным образом добавляем в него ключи из соседей или объединяем узел в ними.
Если удаление происходит не из листа, удаляем самый левый ключ из поддерева следующего дочернего узла или самый правый из поддерева предыдущего дочернего узла и ставим удаленный ключ на место удаляемого ключа в исходном узле.
Билет 21
Хеширование. Разрешение коллизий. Виды хеш-функций.
Хеширование - это способ сведения одного большого множества к более меньшему.
Хеш-функция на основе некоторого ключа вычисляет адрес записи в файле: адрес = h(ключ).
Хорошая хеш-функция:
Равномерно распределяет ключи по адресному пространству
Простая в вычислении – быстрая
Дает минимальное кол-во коллизий
Коллизия – ситуация, когда разные ключи претендуют на один и тот же адрес.
Разрешение коллизий
1)Метод открытой адресации
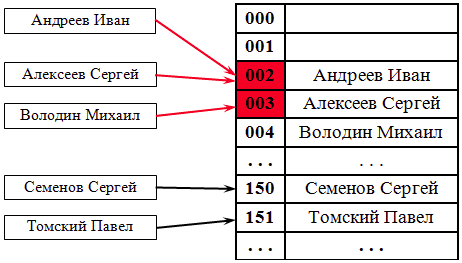
Если при добавлении новой записи(адреса) ячейка с вычисленным по хеш-функции h(ключ) индексом занята, просматриваем следующие записи таблицы по порядку до тех пор, пока не будет найдена первая пустая позиция в таблице.
Поиск свободных ключей в методе открытой адресации может проводиться методом повторного хеширования. Если ячейка (h(ключ)) уже занята некоторой записью с другим ключом, то функция rh применяется к значению h(ключ) для того, чтобы найти другую ячейку, куда может быть помещена эта запись.
Если ячейка rh(h(ключ)) также занята, то хеширование выполняется еще раз и проверяется ячейка rh(rh(h(ключ))). Этот процесс продолжается до тех пор, пока не будет найдена пустая ячейка. Rh – заданная некоторым образом функция повторного хеширования.
Недостатки метода: фиксированный размер таблицы, трудности с удалением записей.
2)Метод цепочек

Элементы множества, которым соответствует одно и то же хеш-значение (h(ключ)), связываются в цепочку-список. В позиции номер i хранится указатель на голову списка тех элементов, у которых хеш-значение ключа равно i.
Недостатки метода: использование дополнительной памяти для указателей.
Виды хеш-функций
1)Метод деления: h(key) = key mod m, где m – размер хеш-таблицы. Лучше выбрать в качестве m простое число, далеко отстоящее от степеней двойки.
2)Метод умножения: h(key) = [m*((key*A) mod 1)] , где m – размер хеш-таблицы, A – некоторая константа. Кнут говорит, что A = 0.61 – хороший выбор.
3)Метод середины квадрата: ключ умножается сам на себя и в качестве индекса используется несколько средних цифр этого квадрата.
Билет 22
Модель TransRelation
Автор – Стив Тарен.
Основные сведения
Средство реализации реляционной модели
Обеспечивается независимость от физических данных
Обеспечивается разграничение между физическими и логическим уровнями системы
Три уровня абстракции
На верхнем уровне данные представлены в виде отношений, которые обычным образом составлены из кортежей и атрибутов
На нижнем уровне данные представлены с помощью различных внутренних структур модели TR, называемых таблицами, а сами эти таблицы состоят из строк и столбцов.
Средний уровень представляет собой уровень перенаправления между другими двумя уровнями — отношения верхнего уровня отображаются на файлы (абстрактные) среднего уровня, а затем эти файлы отображаются на таблицы низкого уровня. Кроме того, указанные файлы состоят из записей и полей; записи соответствуют кортежам, а поля — атрибутам верхнего уровня.

Основная идея
R — запись некоторого файла на файловом уровне

Хранимая форма записи R состоит из двух логически различимых частей – множества значений полей и множества “связующих данных”, позволяющих связать друг с другом эти значения полей, причем для физического хранения каждой из этих частей можно воспользоваться широким спектром возможностей.
Таблицы к билетам по SQL
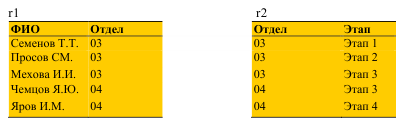
БД НИР
R1 = (ФИО, Отдел);
R2= (Отдел, Этап);
R3= (ФИО, Этап, Начисления).
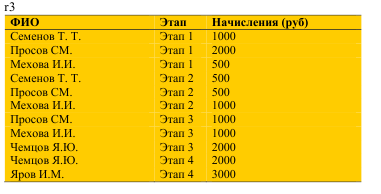
БД Сессия
S1 = (ФИО, Дисциплина, Оценка) — сведения о результатах сессии;
S2 = (ФИО, Группа) — сведения о составе групп;
S3 = (Группа, Дисциплина) — перечень экзаменов, подлежащих сдаче.
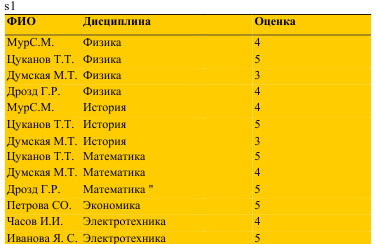
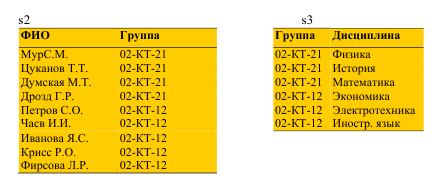
Билет 23
SQL. Описание данных.
SQL (Structured Query Language — «язык структурированных запросов») — универсальный компьютерный язык, применяемый для создания, модификации и управления данными в реляционных базах данных. SQL основывается на исчислении кортежей. Задумывался как близкий к естественному языку.
Обрабатываемые типы данных
Символьные типы данных - буквы, цифры и специальные символы.
Целые типы данных - только целые числа
Вещественные типы данных - числа с дробной частью
Денежные типы данных
Дата и время - дата, время и их комбинации
Двоичные типы данных - данные любого объема в двоичном коде
Последовательные типы данных - возрастающие числовые последовательности
null – пустое значение, причем 2 пустых значения не равны между собой.
С оставные части языка: DDL(язык определения данных), DML(язык манипулирования данных), DCL(язык управления данными).
Операторы определения данных (DDL)
DDL– Data Definition Language
Ядро: create – создание объекта БД, drop – удаление объекта БД, alter – изменение определения объекта
Основные команды
CREATE DATABASE(создать базу данных)
CREATE TABLE(создать таблицу)
CREATE VIEW(создать виртуальную таблицу)
CREATE INDEX(создать индекс)
CREATE TRIGGER(создать триггер)
CREATE PROCEDURE(создать сохраненную процедуру)
ALTER DATABASE(модифицировать базу данных)
ALTER TABLE(модифицировать таблицу)
ALTER VIEW(модифицировать виртуальную таблицу)
ALTER INDEX(модифицировать индекс)
ALTER TRIGGER(модифицировать триггер)
ALTER PROCEDURE(модифицировать сохраненную процедуру)
DROP DATABASE(удалить базу данных)
DROP TABLE(удалить таблицу)
DROP VIEW(удалить виртуальную таблицу)
DROP INDEX(удалить индекс)
DROP TRIGGER(удалить триггер)
DROP PROCEDURE(удалить сохраненную процедуру)