

3.4.2 Построение функции перв(µ)
Значение функции ПЕРВ() можно определить пользуясь следующими правилами: 1) Если цепочка µ начинается терминальным символом и имеет вид bµ', то функция ПЕРВ(µ) = {b}, 2) Если цепочка µ является пустой цепочкой, µ = $, то функция ПЕРВ(µ) = $,
3) Если цепочка µ начинается нетерминальным символом <B> и имеет вид <B>µ', а в схеме грамматики имеется n правил, в любой части которых находится символ <B>: <B> 1 | 2 | ... | n ,
и, если не существует вывода <B> ==>* $, то функция ПЕРВ(<B>µ') представляет собой объединение множеств: ПЕРВ(<B>µ') = ПЕРВ(1) ПЕРВ (2) ...ПЕРВ(n),
4) Если цепочка µ начинается нетерминальным символом и имеет вид <B>µ', в схему грамматики входят n правил вида <B> 1 | 2 | ... | n , и <B> является аннулирующим нетерминалом, т.е. существует <B> ==> *$, то функция ПЕРВ(<B>µ')=ПЕРВ(µ') ПЕРВ( 1) ПЕРВ( 2) ... ПЕРВ( n).
В качестве примера выполним вычисление функции ПЕРВ для правил следующей грамматики:
Г3. 2 : R = { (1) <A> <B><C>c, (2) <A> g<D><B>, (3) <B> $, (4) <B> b<C><D><E>, (5) <C> <D>a<B>, (6) <C> ca, (7) <D> $, (8) <D> d<D>, (9) <E> g<A>f, (10) <E> c }.
Вначале найдем значения функции для правых частей правил (2), (4), (6), (8), (9) , (10) , начинающихся терминальными символами: ПЕРВ(g,<D>,<B>) = {g} ПЕРВ(b<C><D><E>) = {b} ПЕРВ(ca) = {c} ПЕРВ(d<D>) = {d} ПЕРВ(g<A>f) {g} ПЕРВ(c) = {c} Затем вычислим функцию для правил (5) и (6) :
ПЕРВ (<C>) = ПЕРВ (<D>a<B>) ПЕРВ (ca).
Учитывая, что <D> является аннулирующим нетерминалом, получаем:
ПЕРВ(<C>) = ПЕРВ(a<B>) ПЕРВ(<D>) {c} = {a}{d}{c}={a,d,c}.
При вычислении функции для правил (1) и (2) также необходимо иметь в виду то, что <B> является аннулирующим терминалом, поэтому имеем:
ПЕРВ(<A>) = ПЕРВ(<B><C>c) ПЕРВ(g<D><B>) = ПЕРВ(<C>c) ПЕРВ(<B>) ПЕРВ(g<D><B>) =
{a,d,c} {b} {g} = {a,b,c,d,g}.
9.Определение и правила вычисления функции СЛЕД. Использование функции.
3.4.3 Построение функции СЛЕД(<B>)
Аргументом функции СЛЕД является нетерминальный символ, например <B>, а значение функции СЛЕД(<B>) представляет собой множество терминалов, которые могут следовать непосредственно за нетерминалом <B> в цепочках, выводимых из начального символа грамматики. Вычисление значения функции СЛЕД(<B>) должно выполняться по следующим правилам: 1) Если в схеме грамматики имеются правила вида
<X1> µ1<B>1, <X2> µ2<B>2, ... , <Xn> µn<B>n,
и все цепочки i/$ , то
СЛЕД(<B>) = ПЕРВ( 1) ПЕРВ( 2) ... ПЕРВ( n).
2) Если же среди приведенных выше правил имеется хотя бы одна цепочка i = $, например пусть 1 = $, то функция вычисляется так:
СЛЕД(<B>) = СЛЕД(<X1>) ПЕРВ( 2) ... ПЕРВ( n).
Выполним вычисление функции СЛЕД для нетерминалов грамматики Г3.2 . Вначале определим функцию для нетерминала <A>, который встречается в правой части правила (9). СЛЕД(<A>) = ПЕРВ(f) = {f}. Нетерминал <C> входит в правые части правил (1) и (4), учитывая также, что нетерминал <D> являетя анулирующим, получаем:
СЛЕД(<C>) = ПЕРВ(<D>) ПЕРВ(<E>) ПЕРВ(c) = {c,d,g}.
Нетерминал <B> входит в правые части правил (1), (2), (5), поэтому имеем:
СЛЕД(<B>) =ПЕРВ(<C>c) СЛЕД(<A>) СЛЕД(<C>),
подставляя в полученное выражение значения функций, входящих в правую часть, получаем:
СЛЕД(<B>) = { a, c, d, } { f } U { c, d, g, } = { a, c, d, g, f }.
Для нетерминала <D> , который входит в правила (2), (4) , (5) и (8), с учетом того, что нетерминал <B> является аннулирующим, получаем:
СЛЕД(<D>) =ПЕРВ(<B>) СЛЕД(<A>) ПЕРВ(<E>) ПЕРВ(a<B>),
учитывая, что , для нетерминала <E>, входящего в правило (4) СЛЕД(<E>) = СЛЕД(<B>) = {a,d,c,g,f}, окончательно имеем: СЛЕД(<D>) = ПЕРВ(<B>) СЛЕД(<A>) ПЕРВ(<E>) {a} =
= {b} {f} {c,g} {a} = {a,b,c,g,f}.
10.Определение и правила вычисления функции ВЫБОР. Использование функции.
3.4.4 Построение множества ВЫБОР.
Множество ВЫБОР, которое потребуется нам для построения переходов магазинных автоматов,можно определить с помощью функций ПЕРВ и СЛЕД следующим образом:
1) Если правило грамматики имеет вид <B> - > и не является аннулирующей цепочкой, другими словами не существует вывод ==>*$, то ВЫБОР(<B> ) = ПЕРВ( ). 2) Для аннулирующих правил грамматики вида <B> $, множество выбора определяется так ВЫБОР(<B> $) = СЛЕД(<B>). 3) Если правило грамматики имеет вид <B> µ и µ является аннулирующей цепочкой, то ВЫБОР(<B> µ) = ПЕРВ(µ) СЛЕД(<B>).
Для рассматриваемой грамматики Г3.2 множества ВЫБОР для каждого из правил, построенные описанным выше способом, имеют вид:
ВЫБОР(<A> <B><C>c) = ПЕРВ(<B><C>c) = {a,b,c,d}, ВЫБОР(<A> g<D><B>) = ПЕРВ(g<D><B>) = {g}, ВЫБОР(<B> $) = ПЕРВ($) СЛЕД(<B>) = {a,c,d,g,f}, ВЫБОР(<B> b<C><D><E>) = ПЕРВ(b<C><D><E>) = {b}, ВЫБОР(<C> <D>a<B>) = ПЕРВ(<D>a<B>) = {a,d}, ВЫБОР(<C> ca) = ПЕРВ(ca) = {a}, ВЫБОР(<D> $) = ПЕРВ($) СЛЕД(<D>) = {a,b,c,g,f}, ВЫБОР(<D> d<D>) = ПЕРВ(d<D>) = {d}, ВЫБОР(<E> g<A>f) = ПЕРВ(g<A>f) = {g}, ВЫБОР(<E> c) = ПЕРВ(c) = {c}.
11.КС-грамматики и LL1 грамматики.
3.5 Слаборазделенные грамматики
Используя введенные понятия, можно дать определение слаборазделенной грамматики.
-
Определение. КС-грамматика называется слаборазделенной, если выполняются следующие три условия:
правая часть каждого правила представляет собой либо пустую цепочку $, либо начинается с терминального символа,
если два правила имеют одинаковые левые части, то правые части правил должны начинаться разными символами,
для каждого нетерминала A, такого что A ==>* $ множество начальных символов не должно пересекаться с множеством символов, следующих за A.:
ПЕРВ(A) СЛЕД(A) = $
Используя приведенное определение, выясним, является ли следующая грамматика слаборазделенной:
Г3. 3 : R = {(1) <I> a<A> , (2) <I> b , (3) <A> c<I>a , (4) <A> $ }.
Эта грамматика не содержит правил с одинаковой левой частью, начинающихся одинаковыми терминалами, поэтому нужно проверить только условие (3) для правила (4). Вычисляя функции ПЕРВ(<A>) = {c} и СЛЕД(<A>) = СЛЕД(<I>) = {a}, находим, что множество значений функции ПЕРВ(<A>) и множество значений функции СЛЕД(<A>) не имеют общих элементов. Следовательно, грамматика Г3.3 является слаборазделенной. Проверка выполнения условия (3) для грамматики Г3. 4: R = { <I> a<I><A> | $ , <A> a | b }
дает следующие результаты: ПЕРВ(<I>) = {a} и СЛЕД(<I>) = ПЕРВ(<A>) = {a,b}, которые показывают, что пересечение множеств ПЕРВ(<I>) и СЛЕД(<I>) не пусто. Следовательно грамматика Г3.4 не является слаборазделенной.
3.6 LL(1) - грамматики.
Разделенные и слаборазделенные грамматики представляют собой подклассы грамматик более общего вида, которые называются LL(1) грамматиками, и которые определяются следующим образом.
-
Определение. КС-грамматика является LL(1) грамматикой тогда и только тогда, когда выполняются следующие два условия: 1 . Для каждого нетерминала, являющегося левой частью нескольких правил: <A> 1 | 2 | ... | n, необходимо, чтобы пересечение функций ПЕРВ(i) и ПЕРВ( j) было пусто для всех i =/= j. 2 . Для каждого аннулирующего нетерминала <A>,такого что <A> ==>* $, необходимо, чтобы пересечение множеств ПЕРВ(<A>) и СЛЕД(<A>) было пустым.
Из определения следует, что грамматики LL(1), в отличие от разделенных грамматик и слаборазделенных, могут содержать правила, начинающиеся нетерминальными символами. Проверим относится ли рассмотренная ранее грамматика Г43 к классу LL(1). Для этого необходимо вначале проверить наличие одинаковых значений функций ПЕРВ для правил с одинаковой левой частью. Для правил (1) и (2) имеем
ПЕРВ(<B><C>a) = ПЕРВ(<B>) ПЕРВ(<C>) = {a,b,d,c}, ПЕРВ(g<D><B>) = {g}, а для правил (5) и (6) имеем ПЕРВ(<D>a<B>) = ПЕРВ(<D>) ПЕРВ(a<B>) = {a,d}, ПЕРВ(ca) = {c}.
Полученные результаты показывают, что первое условие LL(1) грамматики выполняется. Второе условие необходимо проверить для правил (3) и (7) рассматриваемой грамматики. Вычисляя функции ПЕРВ и СЛЕД для правила (8), имеем:
ПЕРВ(<B>) = {b} и СЛЕД(<B>) = {a,c,d,g,f}.
Эти функции не имеют одинаковых значений, следовательно грамматика Г43 является грамматикой LL(1). Рассматриваемый класс грамматик можно определить также с помощью множеств выбора следующим образом:
-
Определение. КС-грамматика называется LL(1) грамматикой тогда и только тогда, когда множества ВЫБОР, построенные для правил с одинаковой левой частью, не содержат одинаковых элементов.
12. Магазинные автоматы.
КС-грамматика определяет структуру цепочек и позволяет строить цепочки определенного языка. Магазинные автоматы, подобно рассмотренным ранее конечным автоматам, позволяют решать для контекстно-свободных языков задачу распознавания, которая заключается в том, что по заданной цепочке необходимо определить принадлежит ли она заданному языку. В работах, связанных с формальными языками и грамматиками,используется модель магазинного автомата, состоящая из входной ленты, устройства управления и вспомогательной ленты, называемой магазином или стеком. Входная лента разделяется на клетки (позиции) , в каждой из которых может быть записан символ входного алфавита. При этом предполагается, что в неиспользуемых клетках входной ленты расположены пустые символы . Вспомогательная лента также разделена на клетки, в которых могут располагаться символы магазинного алфавита. Начало вспомогательной ленты называется дном магазина. Связь устройства управления с лентами осуществляется двумя головками, которые могут перемещаться вдоль лент.
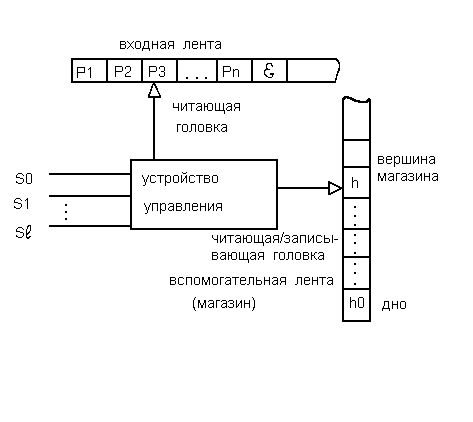
Головка входной ленты может перемещаться только в одну сторону - вправо или оставаться на месте. Она может выполнять только чтение. Головка вспомогательной ленты способна выполнять как чтение, так и запись, но эти операции связаны с перемещением головки определенным образом: - при записи головка предварительно сдвигается на одну позицию вверх, а затем символ заносится на ленту, - при чтении символ, находящийся под головкой считывается с ленты, а затем головка сдвигается на одну позицию вниз,т.о.головка всегда установлена против последнего записанного символа. Позицию, находящуюся в рассматриваемый момент времени под головкой, называют вершиной магазина.
Определение.Магазинный автомат М определяется следующей совокупностью семи объектов: M={P , S , sо , f , F , H , hо }, |
где P - входной алфавит, S - алфавит состояний, sо - начальное состояние, sо S , F - множество конечных состояний ,F является подмножеством S, H - алфавит магазинных символов, записываемых на вспомогательную ленту, hо- маркер дна, он всегда записывается на дно магазина , hо H, f - функция переходов f : {P { }} x S x H S x H* , если М-автомат - детерминированный, и f:{P { }} x S x H M(S x H*) , если М-автомат - недетерминированный. Функция f отображает тройки ( pi , sj , hk ) в пары ( sr , ) , где H* и hk - символ в вершине магазина, для детерминированного автомата или в множество пар для недетерминированного автомата. Эта функция описывает изменение состояния магазинного автомата, происходящее при чтении символа с входной ленты и премещении входной головки. В дальнейшем при построении магазинных автоматов потребуются две разновидности функций переходов, изменяющих состояние автомата без перемещения входной головки:
1) функция переходов с пустым символом в качестве входного символа: f0( s, h) = ( s', ), которая, независимо от того какой символ находится под читаюшей гловкой входной ленты, предписывает прочитать символ h из вершины магазина, изменить состояние автомата на s' и записать цепочку в магазин. 2)функция переходов с определенным входным символом: f*( s, ah) = ( s', ), которая предписывает изменение состояния и запись цепочки в магазин при условии, что символ a читается входной головкой, а в вершине магазина находится символ h .