

Компиляторы. Фазы компиляции.
1.1.1. Трансляторы , интерпретаторы и компиляторы
Транслятор может быть интерпретирующего или компилирующего типа. В первом случае его называют интерпретатором входного языка, а во втором - компилятором.
Интерпретатор последовательно читает предложения входного языка, анализирует их и сразу же выполняет, а компилятор не выполняет предложения языка, а строит программу, которая может в дальнейшем быть запущена для получения результата.
На вход компилятора подается текст, написанный на входном языке - языке, понятном человеку, а результатом работы компилятора является текст на языке, понятном устройству.
1.1.2. Стадии работы компилятора
Работа компилятора состоит из нескольких стадий, которые могут выполняться последовательно, либо совмещаться по времени. Эти стадии могут быть представлены в виде схемы.

Первая стадия работы компилятора называется лексическим анализом, а программа, её реализующая, - лексическим анализатором (ЛА). На вход лексического анализатора подаётся последовательность символов входного языка. ЛА выделяет в этой последовательности простейшие конструкции языка, которые называют лексическими единицами. Примерами лексических единиц являются идентификаторы, числа, символы операций, служебные слова и т.д. ЛА преобразует исходный текст, заменяя лексические единицы их внутренним представлением - лексемами. Лексема может включать информацию о классе лексической единицы и её значении. Кроме того, для некоторых классов лексических единиц ЛА строит таблицы, например, таблицу идентификаторов, констант, которые используются на последующих стадиях компиляции.
Вторую стадию работы компилятора называют синтаксическим анализом, а соответствующую программу - синтаксическим анализатором (СА). На вход СА подается последовательность лексем, которая преобразуется в промежуточный код, представляющий собой последовательность символов действия или атомов. Каждый атом включает описание операции, которую нужно выполнить, с указанием используемых операндов. При этом последовательность расположения атомов, в отличие от лексем, соответствует порядку выполнения операций, необходимому для получения результата.
На третьей стадии работы компилятора осуществляется построение выходного текста. Программа, реализующая эту стадию, называется генератором выходного текста (Г). Генератор каждому символу действия, поступающему на его вход, ставит в соответствие одну или несколько команд выходного языка. В качестве выходного языка могут быть использованы команды устройства, команды ассемблера, либо операторы какого-либо другого языка.
Рассмотренная схема компилятора является упрощенной, поскольку реальные компиляторы, как правило, включают стадии оптимизации.
1.1.3. Построение компилятора
Для построения компилятора необходимо однозначное и точное задание входного и выходного языков. Такое задание предполагает определение правил построения допустимых конструкций (выражений) языка. Множество таких правил называют синтаксисом языка. Кроме того, задание должно включать описание назначения и смысла каждой конструкции языка. Такое описание называют семантикой языка.
Для построения точных и недвусмысленных описаний применяют метод абстракций, который предполагает выделение наиболее существенных свойств рассматриваемого объекта и опускание свойств, менее значимых для рассматриваемого случая. Например, при построении модели входных языков можно рассматривать входной текст как последовательность символов, построенную по определенным правилам, отвлекаясь от характера начертания символов и их расположения на листе. Математические модели, использующие представление текстов в виде цепочек символов, называют формальными языками и грамматиками.
Определение языка и формальной грамматики. Вывод в грамматике. Типы формальных грамматик.
1.2. Определение формальной грамматики и языка.
Изучение предмета начнем с определения первичных понятий.
1.2.1. Первичные понятия
Определение. Конечное множество символов, неделимых в данном рассмотрении, называется словарем или алфавитом, а символы, входящие в множество, - буквами алфавита. |
Например, алфавит A = {a, b, c, +, !} содержит 5 букв, а алфавит B = {00, 01, 10, 11} содержит 4 буквы, каждая из которых состоит из двух символов.
Определение. Последовательность букв алфавита называется словом или цепочкой в этом алфавите. Число букв, входящих в слово, называется его длиной. |
Например, слово в алфавите A a=ab++c имеет длину l(a) = 5, а слово в алфавите B b=00110010 имеет длину l (b) = 4. Если задан алфавит A, то обозначим A* множество всевозможных цепочек, которые могут быть построены из букв алфавита A. При этом предполагается, что пустая цепочка, которую обозначим знаком $, также входит в множество A*.
Определение. Формальной порождающей грамматикой Г называется следующая совокупность четырех объектов: Г = { Vт, VA, <I> VA, R }, где Vт - терминальный алфавит (словарь); буквы этого алфавита называются терминальными символами; из них строятся цепочки порождаемые грамматикой; VA - нетерминальный, вспомогательный алфавит (словарь); буквы этого алфавита используются при построении цепочек; они могут входить в промежуточные цепочки, но не должны входить в результат порождения; <I> - начальный символ грамматики <I> VA. R - множество правил вывода или порождающих правил вида , где и - цепочки , построенные из букв алфавита Vт VA, который называют полным алфавитом (словарем) грамматики Г. |
В множество правил грамматики могут также входить правила с пустой правой частью вида <Е> . Чтобы избежать неопределенности из-за отсутствия символа в правой части правила, условимся использовать имвол пустой цепочки, записывая такое правило в виде <Е> $. Чтобы установить правила построения цепочек, порождаемых грамматикой , введем следующие понятия.
Определение. Пусть r = - правило грамматики Г и = ' " - цепочка символов, причем', " (Vт VA) *. Тогда цепочка = ' " может быть получена из цепочки путем применения правила r (т.е. заменой в m цепочки на ). В этом случае говорят, что цепочка непосредственно выведена из цепочки и обозначают . Определение. Если задана совокупность цепочек = ( 0, 1,...,n), таких что существует последовательность непосредственных выводов: 0 1, 1 2, ... , n-1 n, то такую последовательность называют выводом n из 0 в грамматике Г и обозначают 0 * n. Определение. Множество конечных цепочек терминального алфавита Vт грамматики Г, выводимых из начального символа <I>, называется языком, порождаемым грамматикой Г и обозначается L( Г). L( Г ) = {Vт* | <I> * }. |
1.2.3. Пустой язык
Определение. Если язык, порождаемый грамматикой Г, не содержит ни одной конечной цепочки (конечного слова), то он называется пустым. Утверждение. Для того, чтобы язык L( Г ) не был пустым, в множестве R должно быть хотя бы одно правило вида r = , где Vт* и должен существовать вывод <I> * . |
1.3. Типы формальных языков и грамматик
В теории формальных языков выделяются 4 типа грамматик, которым соответствуют 4 типа языков. Эти грамматики выделяются путем наложения усиливающихся ограничений на правила грамматики.
1.3.1. Грамматики типа 0. Грамматики типа 0, которые называют грамматиками общего вида, не имеют никаких ограничений на правила порождения. Любое правило r = может быть построено с использованием произвольных цепочек (Vт Va)*. Например, <T><W> <W><T> или x<A>b<C><D> x<H><D>.
1.3.2. Грамматики типа 1
Грамматики типа 1, которые называют также контекстно-зависимыми грамматиками, не допускают использования любых правил. Правила вывода в таких грамматиках должны иметь вид: 1<A>2 12,
где 1,2 - цепочки, возможно пустые, из множества (Vт Va)*, символ <А> Va и цепочка w(Vт Va)*. Цепочки 1 и2 остаются неизменными при применении правила, поэтому их называют контекстом (соответственно левым и правым), а грамматику - контекстно зависимой. Грамматики типа 1 значительно удобнее на практике, чем грамматики типа 0, поскольку в левой части правила заменяется всегда один нетерминальный символ, который можно связать с некоторым синтаксическим понятием, в то время как в грамматике типа 0 можно заменять сразу несколько символов, в том числе и терминальных. Например, грамматика:
Г1. 4: Vт = {a, b, c, d}, Va = {<I>, <A>, <B>} R = { <I> aA<I>, A<I> AA<I>, AAA A<B>A, A b, b<B>A bcdA, b<I> ba } является контекстно-зависимой, поскольку второе и шестое правила имеют непустой левый контекст, а третье и пятое правила содержат оба контекста. Вывод в такой грамматике может иметь вид: <I> a<A><I> a<A><A><I> ab<A><I> abb<I> abba.
1.3.3. Грамматики типа 2
Грамматики типа 2 называют контектно-свободными и бесконтекстными грамматиками (КС-грамматики или Б-грамматики). Правила вывода таких грамматик имеют вид: <A>, где <A> Va и (Vт Va)*. Очевидно, что эти правила получаются из правил грамматики типа 1 при условии 1 = 2 = $. Поскольку контекстные условия отсутствуют, то правила КС-грамматик получаются проще, чем правила грамматик типа 1. Именно такие грамматики используются для описания языков программирования. Примером КС-грамматики может служить следующая: Г1. 5: Vт = {a, b}, Va = {<I>}, R = { <I> a<I>a, <I>b<I>b, <I>aa, <I>bb}.Эта грамматика порождает язык, который состоит из цепочек, каждая из которых в свою очередь состоит из двух частей, цепочки Vт* и зеркального отображения этой цепочки '.
L( Г5 ) = { ' | Vт+}, где Vт+ - это множество Vт* без пустой цепочки. С помощью правил этой грамматики может быть построена, например, следующая цепочка: <I>a<I>aab<I>baaba<I>abaababbaba.
1.3.4. Грамматики типа 3
Грамматики типа 3 называют автоматными грамматиками (А - грамматиками). Правила вывода в таких грамматиках имеют вид: <A>a или <A>a<B> или <A><B> a, где a Vт, <A>, <B>Va, причем грамматика может иметь только правила вида <A> a<B> - правосторонние правила, либо только вида <A><B>a - левосторонние правила. Примерами автоматных грамматик могут служить правосторонняя грамматика Г1. 6 и левосторонняя грамматика Г1. 7. Г1. 6: Vт = {a, b}, Va = {<I>, <A>}, R = { <I> a<I>, <I>a<A>, <A>b<A>, <A>b<Z>, <Z> $ }. Г1. 7: Vт = {a, b}, Va = {<I>, <A>}, R = { <I><A>b,
<A><A>b, <A><Z>a, <Z><Z>a, <Z> $ }.
Эти грамматики являются эквивалентными и порождают язык
L(Г7) = {a...ab...b | n,m > 0}.
Между множествами языков различных типов существует отношение включения: { L типа 3 } { L типа 2 }{ L типа 1 }{ L типа 0}. Доказано, что существуют языки типа 0, не являющиеся языками типа 1, языки типа 2, не являющиеся языками типа 1, и языки типа 3, не являющиеcя языками типа 2.
Учитывая, что наибольшее практическое применение находят грамматики типа 2 и типа 3, дальнейшее изложение посвящается рассмотрению именно этих типов грамматик.
3.Неоднозначные и эквивалентные грамматики. КС-грамматики. Виды вывода.
КС-грамматики.
Правила вывода таких грамматик имеют вид:
<A>,
где <A> Va и (Vт Va)*.
Именно такие грамматики используются для описания языков программирования. Примером КС-грамматики может служить следующая:
Г1. 5:
Vт = {a, b}, Va = {<I>},
R = { <I> a<I>a,
<I>b<I>b, <I>aa, <I>bb}.
Эта грамматика порождает язык, который состоит из цепочек, каждая из которых в свою очередь состоит из двух частей, цепочки Vт* и зеркального отображения этой цепочки '.
L( Г5 ) = { ' | Vт+},
где Vт+ - это множество Vт* без пустой цепочки. С помощью правил этой грамматики может быть построена, например, следующая цепочка:
<I>a<I>aab<I>baaba<I>abaababbaba.
1.3.7. Левый и правый выводы
Среди всевозможных выводов наибольший интерес представляют следующие два типа выводов.
Определение. Если при построении вывода цепочки при каждом применении правила заменяется самый левый нетерминальный символ, то такой вывод называется левым или левосторонним выводом . Если при построении вывода , всегда заменяется самый правый нетерминальный символ промежуточной цепочки, то вывод называется правым или правосторонним выводом . |
Например, приведенный выше вывод цепочки i * i + i в грамматике Г1. 9 является левосторонним выводом. Следует отметить, что различным выводам цепочки i+i в грамматике Г1. 9 соответствует одно и то же синтаксическое дерево. Аналогичная ситуация имеет место и при выводе цепочки i * i + i.
1.3.8. Неоднозначные и эквивалентные грамматики
Существуют грамматики, в которых одна и та же цепочка может быть получена с помощью различных выводов. Например, в грамматике Г1. 10 цепочка abc может быть получена с помощью двух различных выводов, и ей соответствуют два различных синтаксических дерева. Г1. 10: Vт = {a, b, c, d}, Va = {<I>, <A>, <B>},
R = { <I><A><B>, <A>a, <A>ac, <B>b, <B>cb}.
Первый вывод этой цепочки имеет вид :
1) <I><A><B><A>bacb,
а второй можно получить так :
2) <I><A><B><A>cbacb.
Этим выводам соответствуют разные синтаксические деревья и разборы :
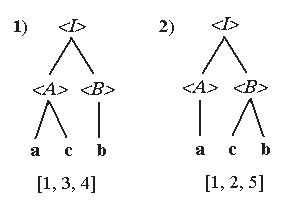
Следующая грамматика также допускает построение одной и той же цепочки с помощью двух выводов, имеющих разные синтаксические деревья. Г1. 11: Vт = {0, +}, Va = {<I>}, R = { <I>0, <I><I> + 0, <I>0 +<I> }.Два вывода этой грамматики, порождающие одинаковые цепочки, имеют вид:
1) <I><I> + 0<I> + 0 + 00 + 0 + 0,
2) <I>0 + <I>0 + 0 +<I>0 + 0 + 0, а синтаксические деревья, соответствующие этим выводам,
можно изобразить так:
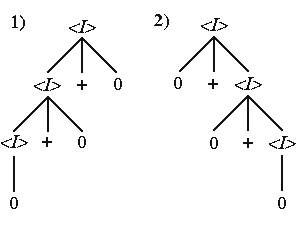
Рассмотренное свойство грамматик называется неоднозначностью. Оно может быть определено следующим образом.
Определение. Цепочка языка L(Г) называется неоднозначной, если для её вывода существует более чем одно синтаксическое дерево. Если грамматика Г порождает неоднозначную цепочку, то она называется неоднозначной. |
Неоднозначность может существовать не только в искусственных языках. Хорошо известно, что в естественных языках могут быть предложения, допускающие неоднозначное написание. Например, "Пальто испачкало окно". В этой фразе не ясно, что является подлежащим, а что дополнением. Другим примером служит английская фраза: "They are flying planes", которая может быть понята двояко: "Они пилотируют самолет" или : Это летящие самолеты". Свойство неоднозначности является крайне нежелательным для искусственных языков, поскольку оно не позволяет однозначным образом восстановить дерево вывода по заданной цепочке языка. В общем случае можно сделать следующий вывод: 1) каждой цепочке, выводимой в грамматике, может соответствовать одно или несколько синтаксических деревьев, 2) каждому синтаксическому дереву могут соответствовать несколько выводов, 3) каждому синтаксическому дереву соответствует единственный правый и единственный левый выводы. Кроме того, следует подчеркнуть, что один и тот же язык может быть получен с помощью различных грамматик.
Определение. Две грамматики Г1 и Г2 называются эквивалентными, ecли они порождают один и тот же язык, т.е. L(Г1) = L(Г2). |
4.Преобразования КС-грамматик. Соответствие формальных грамматик и конечных автоматов.
2.1 Приведенные грамматики. Из четырех типов грамматик контекстно-свободные грамматики являются наиболее важными с точки зрения приложений к языкам программирования и компиляции. С помощью КС-грамматики можно определить большую часть структуры языка программирования. При построении грамматик, задающих конструкции языков программирования, часто приходится прибегать к их преобразованию, чтобы порождаемый язык приобрел нужную структуру, поэтому вначале рассмотрим несколько достаточно простых, но важных преобразований КС-грамматик. Первый вид преобразования связан с удалением из грамматики бесполезных символов. Бесполезные символы в грамматике могут оказаться в следующих случаях: а) если символ не может быть получен при выводе, б) если из символа не может быть получена конечная терминальная цепочка (получается бесконечная цепочка или нет правил, приводящих к терминальной цепочке).
Вначале рассмотрим алгоритм выявления символов, из которых нельзя вывести конечные цепочки.
2.2 Определение непроизводящих символов.
Определение. Символ <X> VA называется непроизводящим, если из него не может быть выведена конечная терминальная цепочка. |
Рассматривая правила грамматики, можно сделать вывод, что если все символы правой части являются производящими, то производящим является и символ, стоящий в левой части. Последнее утверждение позволяет написать процедуру обнаружения непроизводящих символов в следующем виде: 1. Составить список нетерминалов, для которых найдется хотя бы одно правило, правая часть которого не содержит нетерминалов. 2. Если найдено такое правило, что все нетерминалы, стоящие в его правой части уже занесены в список, то добавить в список нетерминал, стоящий в его левой части. 3. Если на шаге 2 список больше не пополняется, то получен список всех производящих нетерминалов грамматики, а все нетерминалы не попавшие в него являются непроизводящими. Анализируя в соответствии с приведенными правилами следующую грамматику : Г2. 0: R = {<I>a<I>a, <I>b<A>d, <I>c, <A>c<B>d, <A>a<A>d, <B>d<A>f },находим, что здесь непроизводящими являются символы <А> и <В>. После удаления правил, содержащих непроизводящии символы, получаем: R' = {<I> a<I>a, <I> c}.
2.3 Определения недостижимых символов.
-
Определение. Символ X Vт VA называется недостижимым в КС-грамматике Г, если X не появляется ни в одной выводимой цепочке.
Рассматривая правила грамматики, можно заметить , что если нетерминал в левой части правила является достижимым , то и все символы правой части являются достижимыми. Это свойство правил является основой процедуры выявления недостижимых символов, которую можно записать так: Образовать одноэлементный список, состоящий из начального символа. Если найдено правило, левая часть которого уже имеется в списке, то включить в список все символы, содержащиеся в его правой части. Если на шаге 2 новые нетерминалы в список больше не добавляются, то получен список всех достижимых нетерминалов, а нетерминалы, не попавшие в список, являются недостижимыми. Например, применяя приведенные правила к следующей грамматике: Г2. 1 : R = { <I> a<I>b, <I> c, <A> b<I>, <A> a },
находим, что A является недостижимым символом.
2.4 Определения бесполезных символов.
Бесполезный символ грамматики можно определить следующим образом:
Определение. Символ X, который принадлежит VтU Va называется бесполезным в КС-грамматике Г, если он является недостижимым или непроизводящим. |
Исключить бесполезные символы из грамматики можно удаляя правила, содержащие вначале непроизводящие, а затем недостижимые символы. В качестве иллюстрации применения приведенных правил выполним преобразование следующей грамматики:
Г2. 2 : R = {<I>ac <I> b<A>, <A> c<B><C>, <B> a<I><A>, <C> bc, <C> d }.
Вначале находим, что <А> и <В> являются непроизводящими символами и, исключая правила с непроизводящими символами , получаем: R' = {<I>ac <C> bc, <C> d }.
В полученной схеме символ <C> является недостижимым символом. Исключая правила, содержащие этот символ, получаем: R" = {<I>ac }.
Определение. КС-грамматика называется приведенной, если она не содержит бесполезных символов. |
В дальнейшем изложении рассматриваются только приведенные КС-грамматики. Другие виды преобразований грамматик, описываемые ниже, предназначены для исключения правил определенного вида из схемы грамматики.