

«Узкие» места, обусловленные иерархической структурой памяти
Предположим, что в вычислительной системе решается какая-нибудь очень большая задача, например, система линейных алгебраических уравнений с матрицей максимального размера. Если используется метод Гаусса, то исключать элементы можно в самых различных порядках. При этом общее число выполняемых арифметических операций остается одним и тем же или меняется не более чем в 2—3 раза. Однако, пропуская разные варианты метода для одной и той же вычислительной системы, замечаем, что общее время решения задачи меняется в десятки раз и более.
Другая реальная ситуация. Пусть зафиксирован какой-либо вариант метода Гаусса, но теперь решаются системы различных размеров. При этом ожидается, что общее время решения задачи будет меняться пропорционально общему числу арифметических операций. Но и в этом случае встречаются неожиданности. Иногда для некоторых порядков время решения задачи может оказаться существенно большим.
На общее время решения задачи влияет много факторов. Но главные из них — это время выполнения арифметических операций и время взаимодействия с оперативной памятью. В методах типа Гаусса вся совокупность арифметических операций известна заранее. Поэтому, если время решения задачи почему-то оправданно возрастает, то, скорее всего, есть определенная не аккуратность в использовании оперативной памяти. А это означает, что имеются причины для болee глубокого обсуждения структуры оперативной памяти и принципов ее использования. Тем более, если возникает необходимость решать большие задачи.
Главное требование к оперативной памяти — обеспечение малого времени доступа к отдельным словам. Вообще говоря, оно должно быть намного меньше, чем время выполнения операций над словами, в крайнем случае — соизмеримым с ним.
В современных вычислительных системах подсистема памяти имеет сложную иерархическую структуру из многих уровней. Чем выше уровень в иерархической структуре памяти, тем он более быстродействующий и менее емкий.
Самый быстрый уровень памяти — это регистровая память. Она имеет очень небольшой объем, измеряемый единицами или десятками слов. В ней хранятся те результаты выполнения операций, которые необходимы для реализации команд, непосредственно следующих за исполняемой. По существу регистровая память является неотъемлемой частью функциональных устройств.
Следующий уровень памяти – это кэш-память. Она тоже имеет свою иерархическую структуру, состоящую из 3 уровней. Кэш-память является своеобразным буфером между регистровой памятью и оперативной памятью. В современных вычислительных системах ее объем достигает многих миллионов слов. Управляет использованием кэш-памяти устройство управления.
На стадии перевода программ в машинный код компилятор может выстраивать команды таким образом, чтобы эффект от использования регистровой и кэш-памяти был максимальным. Но это делается не всегда.
Стремление сделать оперативную память "обыкновенной" вычислительной системы достаточно большой приводит к усложнению ее структуры. В свою очередь, это неизбежно увеличивает разброс времен доступа к отдельным словам. Наилучший режим работы с оперативной памятью обычно поддерживается как операционными системами, так и компиляторами. Но для программ произвольного вида он не всегда может быть реализован. Чтобы его использовать, составитель программ должен соблюдать вполне определенные правила, о существовании которых следует узнать заранее.
Если для реализации алгоритма нужно не просто составить какую-нибудь программу, а добиться, чтобы она работала максимально быстро, то соблюдение этих правил может дать ощутимый эффект. Как уже отмечалось, многие вычислительные системы особенно быстро осуществляют доступ к словам с последовательными физическими адресами. Пусть, например, программа составляется на языке Fortran. С точки зрения этого языка безразлично, проводить обработку элементов массивов по строкам или столбцам. Безразлично это и с точки зрения сложности получаемой программы. Все различие сводится лишь к тому, что в одном случае мы имеем дело с преобразованием элементов каких-то матриц, а в другом — транспонированных к ним. Принимая во внимание специфику доступа к оперативной памяти, компиляторы с языка Fortran всегда располагают массивы в физической оперативной памяти последовательно по адресам, столбец за столбцом, слева направо и сверху вниз. Предположим, что реализуется алгоритм решения систем линейных алгебраических уравнений методом Гаусса. В этом случае время работы программы будет определяться ее трехмерными циклами. В зависимости от того, расположена матрица системы в массиве по столбцам или строкам, внутренние циклы программы будут также осуществлять обработку элементов массивов по столбцам или строкам. Времена реализации обоих вариантов могут различаться весьма заметно, иногда в несколько раз. Факт существенный, если речь идет о разработке оптимальных программ.
Связь реальной и пиковой производительности
Рассмотрим работу параллельной вычислительной системы, состоящей из n вычислительных модулей.
Под вычислительным модулем будем понимать любые устройства: например, ядра в мультипроцессорной системе, вычислительные узлы в кластерах, процессорные элементы в матричных системах типа SIMD; функциональные устройства (арифметико-логические устройства – АЛУ) в процессоре.
Пусть рассматриваемая параллельная вычислительная система выполняет программу. Практически в любой программе для параллельных систем можно выделить 2 части – последовательную и параллельную.
В последовательной части программы необходимо выполнить действия, которые невозможно распараллелить, например, инициация программы, ввод данных, вывод результатов, обмен данными между вычислительными модулями, часть действий, обусловленных сугубо последовательной природой алгоритма и т.п.
В параллельной части программы одновременно работают все задействованные по алгоритму вычислительные модули.
Примем, что производительность всех вычислительных модулей одинакова. Будем считать также, что последовательная часть программы выполняется на первом вычислительном модуле, а все остальные n-1 вычислительные модули при этом простаивают.
Будем считать, что вычислительные модули простые. Это означает, что новую операцию вычислительный модуль начинает только после завершения предыдущей операции.
Под операцией будем понимать любые действия, например, очередная команда программы типа «сложить два операнда и результат занести в регистр», процедура, некоторый алгоритм и т.л.
Пиковой производительностью будем называть максимальное количество операций, которое может быть выполнено вычислительной системой за единицу времени при полной загрузке всех вычислительных модулей.
Очевидно, что пиковая производительность характеризует потенциальную производительность параллельной вычислительной системы.
Аналогично определению пиковой производительности системы определим реальную производительность системы как сумму реальных производительностей задействованных при выполнении программы вычислительных модулей.
Интуитивно очевидно, что реальная производительность меньше его пиковой производительности, так как при выполнении реальных программ практически не удается полностью загрузить имеющиеся в параллельной системе вычислительные модули. Определим загруженность (коэффициент использования) вычислительного модуля как отношение объема реально выполненной работы за время Т к максимально возможному объему работы, которую вычислительный модуль может выполнить за тоже время Т.
Реальная производительность отдельно взятого вычислительного модуля будет равна произведению его пиковой производительности на его коэффициент использования (загруженность).
Реальная производительность параллельной вычислительной системы всегда будет меньше пиковой производительности. Отсюда видно, что для достижения наибольшей реальной производительности каждого вычислительного модуля нужно обеспечить наибольшую его загруженность. Для практических целей понятие производительности наиболее важно потому, что именно оно показывает, насколько эффективно вычислительный модуль выполняет полезную работу. По отношению к производительности понятие загруженности является вспомогательным. Тем не менее, оно полезно в силу того, что указывает путь повышения производительности, причем, через вполне определенные действия.
Хотелось бы и для системы вычислительных модулей ввести понятие загруженности, играющее аналогичную роль. Его можно определять по-разному. Например, как и для одного вычислительного модуля , можно было бы считать, что загруженность системы вычислительных модулей есть отношение объема реально выполненной работы за время Т к максимально возможному объему работы системы за тоже время Т. Такое определение вполне приемлемо и позволяет сделать ряд полезных выводов. Однако имеются и возражения. В этом определении медленные и быстрые вычислительные модули оказываются равноправными и если надо повысить загруженность системы, то не сразу видно за счет какого вычислительного модуля это лучше сделать.
Большое число вычислительных модулей, так же как и конвейерные вычислительные модули, используются тогда, когда возникает потребность решить задачу быстрее. Чтобы понять, насколько быстрее это удается сделать, нужно ввести понятие "ускорение". Как и в случае загруженности, оно может вводиться различными способами, многообразие которых зависит от того, что с чем и как сравнивается. Нередко ускорение определяется, например, как отношение времени решения задачи на одном универсальном процессоре к времени решения той же задачи на системе из n таких же процессоров. Очевидно, что в наилучшей ситуации ускорение может достигать n . Отношение ускорения к n называется эффективностью. Заметим, что подобное определение ускорения применимо только к вычислительным системам, состоящим из одинаковых устройств, и не распространяется на смешанные вычислительные системы. Понятие же "эффективность" в рассматриваемом случае просто совпадает с понятием загруженности. При введении понятия "ускорение" мы поступим иначе.
Пусть алгоритм реализуется за время Т
на вычислительной системе из n
вычислительных модулей, в общем случае
простых или конвейерных и имеющих
пиковые производительности Pi
…. Pn.. Предположим, что
![]() .
При реализации алгоритма вычислительная
система достигает реальной производительности
Rc. Будем сравнивать
скорость работы вычислительной системы
со скоростью работы гипотетического
простого универсального вычислительного
модуля, имеющего такую же пиковую
производительность Pn,
как самый быстрый вычислительный
модуль системы, и обладающего
возможностью выполнять те же операции,
что все вычислительные модули системы.
.
При реализации алгоритма вычислительная
система достигает реальной производительности
Rc. Будем сравнивать
скорость работы вычислительной системы
со скоростью работы гипотетического
простого универсального вычислительного
модуля, имеющего такую же пиковую
производительность Pn,
как самый быстрый вычислительный
модуль системы, и обладающего
возможностью выполнять те же операции,
что все вычислительные модули системы.
Итак, будем называть отношение
![]() ускорением реализации алгоритма на
данной вычислительной системе или
просто ускорением. Выбор в качестве
гипотетического простого, а не
какого-нибудь другого, например,
конвейерного вычислительного модуля
объясняется тем, что один простой
универсальный вычислительный модуль
может быть полностью загружен на любом
алгоритме.
ускорением реализации алгоритма на
данной вычислительной системе или
просто ускорением. Выбор в качестве
гипотетического простого, а не
какого-нибудь другого, например,
конвейерного вычислительного модуля
объясняется тем, что один простой
универсальный вычислительный модуль
может быть полностью загружен на любом
алгоритме.
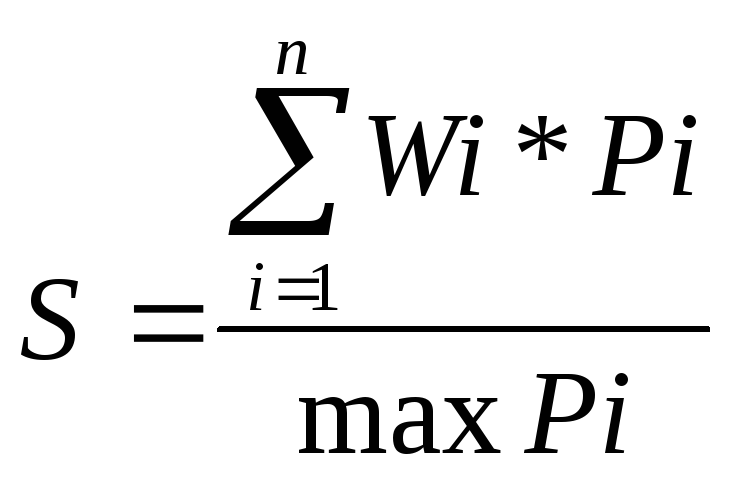 (1)
(1)
Анализ определяющего ускорение выражения (1) показывает, что ускорение системы, состоящей из n вычислительных модулей, никогда не превосходит n и может достигать n в том и только в том случае, когда все вычислительные модули системы имеют одинаковые пиковые производительности и полностью загружены.
Подводя итог проведенным исследованиям, приведем для одного частного случая полезное, хотя и очевидное утверждение.
Если система состоит из n вычислительных модулей с одинаковой пиковой производительностью, то:
загруженность системы равна среднему арифметическому загруженностей всех вычислительных модулей;
реальная производительность системы равна сумме реальных производительностей всех вычислительных модулей;
пиковая производительность системы в n раз больше пиковой производительности одного вычислительного модуля;
ускорение системы равно сумме загруженностей всех вычислительных модулей.
Если система состоит только из простых вычислительных модулей, то ее ускорение равно отношению времени реализации алгоритма на одном универсальном простом вычислительном модуле с той же пиковой производительностью к времени реализации алгоритма на вычислительной системе.
Пусть система вычислительных модулей функционирует и показывает какую-то реальную производительность. Если производительность недостаточна, то в соответствии для ее повышения необходимо увеличить загруженность вычислительной системы. Для этого, в свою очередь, нужно повысить загруженность любого вычислительного модуля, у которого она еще не равна 1. Но остается открытым вопрос, всегда ли это можно сделать. Если вычислительный модуль загружен не полностью, то его загруженность заведомо можно повысить в том случае, когда данный вычислительный модуль не связан с другими из n вычислительных модулей. В случае же связанности вычислительных модулей ситуация не очевидна.
Не ограничивая общности, будем считать все вычислительные модули простыми, т. к. любой конвейерный вычислительный модуль всегда можно представить как линейную цепочку простых вычислительных модулей. Допустим, что между вычислительными модулями установлены направленные связи, и они не меняются в процессе функционирования вычислительной системы.
Тогда справедливо утверждение, что производительность вычислительной системы, состоящей из связанных между собой вычислительных модулей, в общем случае определяется самым непроизводительным вычислительным модулем.
Закон Амдала
Предположим, что по каким-либо причинам
k операций из N некоторой
программы необходимо выполнять
последовательно, а (N –
k) операций - параллельно.
Причины могут быть разными. Например,
операции могут быть последовательно
связаны информационно, и тогда без
изменения алгоритма их нельзя реализовать
иначе. Но вполне возможно, что просто
не распознан параллелизм, имеющийся в
той части алгоритма, которая описывается
этими операциями. Отношение
![]() назовем долей последовательных
вычислений, а
назовем долей последовательных
вычислений, а
![]() - долей параллельных операций.
- долей параллельных операций.
Утверждение.
Пусть система состоит из n одинаковых простых универсальных вычислительных модулей. Предположим, что при выполнении параллельной части алгоритма все n вычислительных модулей загружены полностью. Тогда максимально возможное ускорение равно
![]()
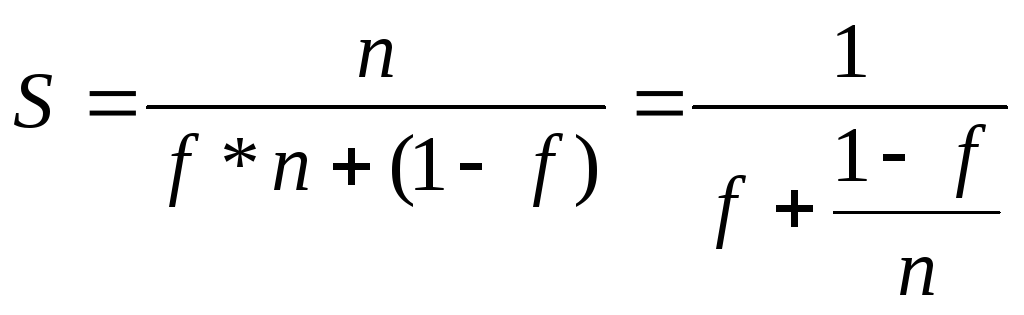 (2)
(2)
Докажем это утверждение.
Обозначим пиковую производительность
отдельного i-го вычислительного
модуля ВМi через Pi.
Пиковая производительность системы
![]()
![]()
Если всего выполняется N
операций, то среди них
![]() операций выполняется последовательно
и
операций выполняется последовательно
и
![]() параллельно на n
вычислительных модулях по
параллельно на n
вычислительных модулях по
![]() операций
на каждом. Не ограничивая общности,
можно считать, что все последовательные
операции выполняются на первом
вычислительном модуле. Весь алгоритм
реализуется за время
операций
на каждом. Не ограничивая общности,
можно считать, что все последовательные
операции выполняются на первом
вычислительном модуле. Весь алгоритм
реализуется за время
![]()
На параллельной части алгоритма работают как первый вычислительный модуль, так и все остальные вычислительные модули, тратя на это время
![]()
для
![]() .
Поэтому
.
Поэтому
![]() и
и
![]()
Следовательно
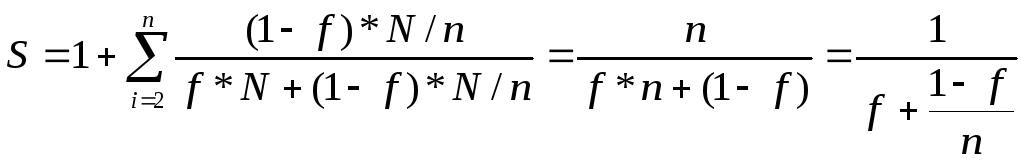
Следствие
Пусть система состоит из простых
одинаковых вычислительных модулей. При
любом режиме работы ее загруженность
не может превзойти
![]() (доли последовательных вычислений), а
ускорение – величины, равной обратной
величине доли последовательных
вычислений, т.е.
(доли последовательных вычислений), а
ускорение – величины, равной обратной
величине доли последовательных
вычислений, т.е.
![]() .
.
В проведенных исследованиях нигде не конкретизировалось содержание операций. В общем случае они могут быть как элементарными типа сложения или умножения, так и очень крупными, представляющими алгоритмы решения достаточно сложных задач. Современные вычислительные системы состоят из тысяч, десятков и даже сотен тысяч ядер. Они вполне укладываются в рассмотренные модели. Вычислительные системы с большим числом ядер должны быть загружены достаточно полно. В противном случае нет стимула их создавать. Исследования говорят о том, что в реализуемых на таких вычислительных системах алгоритмах доля последовательных операций должна быть порядка десятых и сотых долей процента.
В заключение отметим следующее. В обширной литературе, посвященной параллельным процессам и параллельным вычислительным системам, можно встретить много различных определений и законов, касающихся производительности, ускорения, эффективности и т. п. Как правило, новые определения и законы возникают тогда, когда старые в чем-то не устраивают исследователей. Однако ко всем таким "новациям" следует относиться очень осторожно. Довольно часто в попытке что-то "улучшить" скрываются какие-то «узкие» места, одни понятия подменяются другими, иногда просто проводятся ошибочные рассуждения.
Алгоритмы с параллелизмом по данным характерны тем, что в параллельной части они распадаются на одинаковые по выполняемым операциям ветви. Это обстоятельство обеспечивает возможность загрузить одинаковым образом и полностью все вычислительные модули системы при выполнении параллельной части.
Формулу Амдала следует применять для
прогноза возможного ускорения.
Величину
![]() ,
а затем и максимально возможное
ускорение, равное
,
а затем и максимально возможное
ускорение, равное
![]() можно подсчитать, не пропуская программу
на параллельной вычислительной системе.
можно подсчитать, не пропуская программу
на параллельной вычислительной системе.