

6.4. Критерии оптимизации для бд с одним сервером.
При проектировании систем с единым сервером БД эффективность системы зависит от показателей LRA и связанных с ним временных показателей эффективности. Как уже упоминалось, простая минимизация LRA может привести к слишком большим по размеру записям и в общем случае снизить эффективность системы. Поэтому в качестве целевой функции естественно использовать временной показатель, основой для расчета которого является TIO для последовательного (индекс s) и прямого (индекс r) доступа к файлу. С учетом возможности буферизации время обработки будет определяться следующим образом:
![]() , (6.13)
, (6.13)
где Tcash определяет время последовательного считывания таблиц или их частей в кэш памяти, Tf определяет время выбора LRA записей для ответа на запрос, Tt - время передачи ответа на запрос на рабочую станцию пользователя.
6.5.Построение эффективной логической структуры на основе алгоритма кластеризации атрибутов данных.
В качестве основы для поиска оптимальной логической структуры ИС был выбран алгоритм кластеризации атрибутов данных, то есть такая модификация таблиц БД, при которой время выполнения клиентских заданий уменьшается в соответствии с критериями. Основой анализа таблиц – кандидатов на слияние является исследование функциональных требований пользователя F={fp} и, в частности, бинарного вектора ωk={ωpk}, где ωpk=1, если p-я функция обращается к k-й таблице, и 0 в противоположном случае. Простой анализ значений этого вектора позволяет определить круг таблиц – кандидатов на слияние. Фиксируя p , и выбирая ненулевые элементы ωpk=1, можно получить список таблиц, с которыми манипулирует клиентское приложение.
Для того, чтобы определить наиболее часто совместно используемые таблицы, построим матрицу
![]() , (6.14)
, (6.14)
в которой отличные от нуля недиагональные элементы указывают на совместно используемые таблицы при выполнении определенной (p-ой) функции над данными. Определим теперь матрицу
![]() , (6.15)
, (6.15)
где P – число функций над данными в данной ИС. В отличие от матрицы crp, элементы последней матрицы могут принимать любые целые положительные значения или значение ноль. Ненулевой элемент дает общее число совместного использования таблиц при выполнении всех функций над данными.
Легко заметить, что процесс определения элементов матрицы cr довольно просто алгоритмизируется.
Следующий шаг в процессе кластеризации атрибутов данных заключается в сортировке элементов матрицы cr по возрастанию, после чего программный комплекс предлагает проектировщику принять объединение наиболее часто совместно используемых таблиц и дальнейшая работа происходит в интерактивном режиме.
Интерактивный режим выбран по следующим соображениям. Во-первых, проектировщик имеет в виду реальный объем таблиц, от которого зависит скорость обработки данных. Нет смысла сливать несколько таблиц в одну, если объем такой таблицы превышает некоторый пороговый уровень. Во-вторых, объединение не должно противоречить требованиям структурного системного анализа, поскольку тогда ИС становится слишком специфичной и теряет наглядность представления данных. Наконец, опытный проектировщик должен учитывать перспективу развития ИС, когда происходит расширение функций системы как за счет роста объема и структуры информации, содержащейся в БД, так и за счет увеличения числа функций над данными. Наконец, если проектировщик не отвергнет ни одного варианта кластеризации, это приведет лишь к увеличению времени расчета.
Алгоритм кластеризации предусматривает многоступенчатость. Это означает, что после принятия решения о кластеризации и анализе новой структуры в рамках CASE-системы, программа предусматривает возможность кластеризации данных новых таблиц, и процесс циклически повторяется. Окончание процесса кластеризации возможно либо по решению разработчика, либо когда элементы матрицы crp примут нулевые значения.
А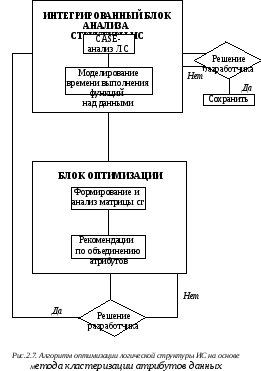 лгоритм
оптимизации структуры БД на основе
метода кластеризации атрибутов данных
представлен на рисунке 3.7.
лгоритм
оптимизации структуры БД на основе
метода кластеризации атрибутов данных
представлен на рисунке 3.7.
Принятие решения
Каждый из вариантов структуры, прошедший контроль разработчика, используется для моделирования времен Tq (среднего времени выполнения функций над данными) и σq – средне-квадратичных отклонений от Tq. Вариант принимается, если время Tq и σq лучше, чем в предыдущем варианте структуры. Точный критерий принятия варианта вытекает из сравнения средних и записывается в виде:
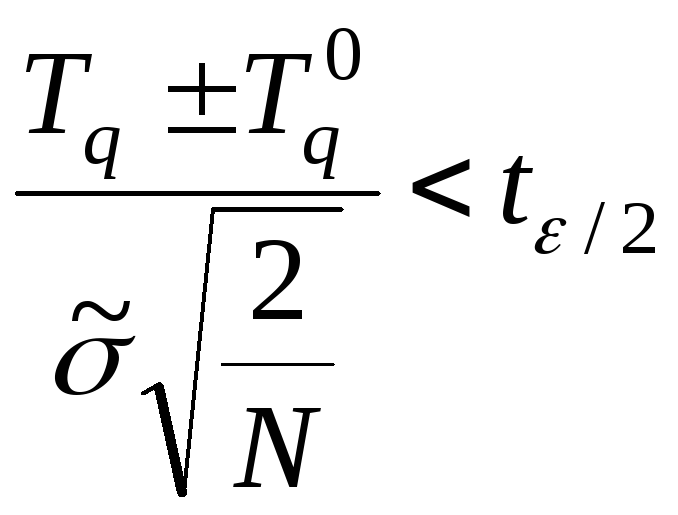 или
или
 , (6.16)
, (6.16)
где
![]() – среднее время выполнения функций над
данными в предыдущем варианте структуры
таблиц, N
– общее число выполненных функций
(запросов), а
– среднее время выполнения функций над
данными в предыдущем варианте структуры
таблиц, N
– общее число выполненных функций
(запросов), а
![]() -объединенная
оценка дисперсии:
-объединенная
оценка дисперсии:
![]() . (6.17)
. (6.17)