

9.4. Методы эффективного кодирования при неизвестной статистике сообщений
Коды, экономичные одновременно для некоторого класса источников, называют универсальными кодами. Сформулируем постановку задачи универсального кодирования источников. Предположим, что алфавит состоит из двух букв a1 и a2, появляющихся независимо с вероятностями p, q=1-p. Однако величина p заранее неизвестна. Требуется построить код, для которого среднее число символов «0» и «1» на одну букву алфавита приближалось бы к H(A) при любом p, 0<=p<=1. Этот код строится так. Множество всех блоков длины n в алфавите A разбиваем на группы, которые имеют одинаковые вероятности при любом р. Таких групп будет ровно n+1. В нулевой группе отсутствует буква a2, она состоит из единственного блока а1а1...а1, вероятность появления которого рn.
Первая группа состоит из всех блоков длины n, содержащих одну букву а2. Эта группа состоит из Сп1=п блоков, вероятность каждого из которых равна рn-1q. Группа с номером k состоит из всех блоков длины п, содержащих k букв a2. Эта группа содержит п блоков, вероятность каждого из которых рn-k<qk.
Универсальный код для k-й группы состоит из двух частей: префикса и суффикса. Префикс содержит log2(n+1) двоичных знаков. Префикс указывает, к какой группе сообщений принадлежит кодируемый блок, суффикс содержит log Cnk двоичных символов и указывает номер блока в группе. Построенный таким образом код будет однозначно дешифруем. На приемном конце первоначально по log(n+1) элементам кода определяют, к какой группе принадлежит переданное сообщение, а затем по следующим log Cnk элементам определяют, какое именно сообщение передавалось.
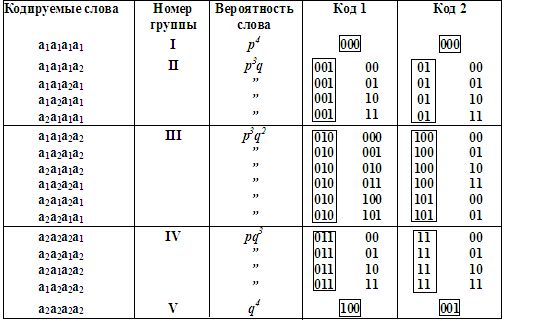
Код 1 в таблице 7 построен описанным выше способом. Здесь выделены штриховой линией префиксы. Этот метод кодирования называется комбинаторным.
Префикс каждой из групп при комбинаторном кодировании содержит ровно log(n+1) символов «0» и «1». Еще большего эффекта можно достичь, если префикс кодировать неравномерным кодом (Рисунок 1). Код 2 в таблице 7 построен именно этим методом. Универсальные методы кодирования хороши не только тем, что они экономичны для любого распределения вероятностей, но и достаточно просто реализуются. Для универсального кодирования на передающем и приемном концах не обязательно знать таблицу, которая определяет кодирование.
Код каждого блока вычисляется по мере поступления на кодирующее устройство букв а1 и а2. На приемном конце также можно декодировать, не прибегая к таблицам. При этом число операций на кодирование и декодирование блока длины п не превосходит п3.
Таблица 7 - Кодирование при неизвестной статистике сообщений
Из приведенного выше описания метода кодирования видно, наиболее трудоемкой частью кодирования является нахождение суффикса. Опишем алгоритм нахождения суффикса. Пусть в блоке А длины п буква а1 встречается на местах i1, i2, …, ir, тогда суффиксом для А назовем число N(A), вычисляемое по правилу:
![]() (9)
(9)
Очевидно, что блоки с разными наборами (i1, …, ir) получают разные номера. При этом максимальное значение номера равно
![]() (10)
(10)
Таким образом, двоичная запись номера (суффикса) должна иметь длину | log Cnr |.
Для нахождения N(A) воспользуемся таблицей биноминальных коэффициентов (треугольником Паскаля):
|
8 |
7 |
81 |
35 |
35 |
21 |
7 |
1 |
0 |
|
7 |
6 |
15 |
20 |
15 |
6 |
1 |
0 |
|
|
6 |
5 |
10 |
10 |
5 |
1 |
0 |
|
|
|
5 |
4 |
6 |
4 |
1 |
0 |
|
|
|
|
4 |
3 |
3 |
1 |
0 |
|
|
|
|
|
3 |
2 |
1 |
0 |
|
|
|
|
|
|
2 |
1 |
0 |
|
|
|
|
|
|
|
1 |
0 |
|
|
|
|
|
|
|
Элементы этой таблицы вычисляются по мере надобности либо размещаются в памяти кодирующего устройства.
Приведем
фрагмент этой таблицы, в которой на
пересечении i-й
строки и j-го
столбца стоит
![]() .
.
Пример 3. Пусть n=8, A=a2a1a1a2a1a1a2a1 тогда r=5; i1=2, i2=3, i3=5, i4=6, i5=8. Тогда номер блока N(A)=С11+С22+С43+С54+С75. Слагаемые в N(А) находим, используя таблицу дополнительных коэффициентов. Они выделены жирным шрифтом. Таким образом, N (А)=1+1+4+5+21=32 или в двоичной записи N(А)=100000.
Декодирование производится с помощью этой же таблицы.
Пример 4. Пусть нам известно, что длина передаваемого блока равна 8, и что в блоке пять букв а1 (количество букв в блоке находим по префиксу). Находим максимальное число в 5-м столбце, не превосходящее 32, это 21=С58-1, следовательно, i5=8, находим разность 32—21=11. Находим далее максимальное число 4-го столбца, не превосходящее 11. Это 5=C46-1 т. е. i4=6. Аналогично находим i3=5, i2=3, i1=2. Следовательно, декодированное сообщение имеет вид
A=a2a1a1a2a1a1a2a1, т.е. совпадает с переданным.
Рассмотренные кодирование и декодирование достаточно просто осуществляются с помощью специализированных вычислительных средств.