

1. Общая характеристика процесса проектирования АСОИУ
Для решения задачи построения АСОИУ проводят системный анализ объекта автоматизации, реинжениринг бизнес-процессов, выбирают наиболее эффективное архитектурное решение, формализуют его в комплекте проектной документации, организуют проект по разработке необходимого обеспечения и реализуют управление этим проектом в течение всего его жизненного цикла.
Процессу проектирования присущи такие факторы, как сложность, обусловленная большим количеством учитываемых параметров, необходимость поиска компромиссов и риск, связанный с отсутствием возможности точного описания среды функционирования системы и изменением требований во времени.
Окончательным результатом проектирования является проект - проектно-конструкторская и технологическая документация, в которой представлено описание проектных решений по созданию и эксплуатации системы в конкретной программно-технической среде.
Сам процесс проектирования состоит в последовательной формализации проектных решений на различных стадиях жизненного цикла системы: предпроектного анализа требований, технического и рабочего проектирования, внедрения и эксплуатации АСОИУ.
Системное проектирование охватывает период от формулирования идеи создания или модернизации системы до начала детального проектирования и разработки программных средств. Результат периода — согласованное формализованное разработчиком и заказчиком представление о целях, назначении, функциональных задачах и качестве программных средств для удовлетворения запросов пользователей. Результат работы по проектированию — системный проект, ТЗ и контракт на продолжение проектирования или решение о его прекращении. В системном проекте отражают:
-
обобщенный анализ обследования объекта автоматизации, функций существующей АСОИУ (если требуется модификация системы)
-
совокупность предварительных исходных требований
-
оценки имеющихся и доступных ресурсов
-
результаты предварительного анализа на основе сравнения с аналогами
-
цели, задачи, функции проектируемой системы
-
проекты планов жизненного цикла, гарантии качества, защиты и безопасности системы
-
результаты анализа существующей и возможной инструментальной среды разработки
-
предварительный план организации работ, требования к составу и квалификации специалистов.
Совокупность методологий проектирования системы, а также методов и средств организации проектирования называется технологией проектирования. В основе технологии проектирования лежит технологический процесс, определяющий последовательность действий, состав исполнителей, средства и ресурсы для их выполнения. Технология проектирования — совокупность трех составляющих:
-
пошаговой процедуры, определяющей последовательность технологических операций проектирования;
-
критериев и правил, используемых для оценки результатов выполнения технологических операций;
-
нотаций (графических и текстовых средств), используемых для описания проектируемой системы.
Управление проектом — особый вид деятельности, включающий постановку задач, подготовку решений, планирование, организацию и стимулирование специалистов, контроль хода работ и использования ресурсов при создании сложных систем. Цель управления проектом — рациональное использование и предупреждение потери ресурсов путем сбалансированного их распределения по частным работам на протяжении всего жизненного цикла объекта с заданным качеством.
Результаты проектирования представляются в виде спецификации. При этом необходимо добиться высокого уровня формализации. Для этого с использованием современных CASE-систем строят модели подсистем АСОИУ. Эти модели должны служить базой при разработке схем потоков управления и данных, описывающих процессы их обработки, и интегрироваться с обработанными моделями бизнес-процессов для комплексного исследования функционирования прототипов.
2. Назначение и функции ОС

3. Основные понятия исследования операций и системного анализа (= 68)
Система — множество элементов с определенными способами взаимодействия между ними, в совокупности выполняющих заданную цель.
Процесс — любое действие в системе (если система работает — в ней уже происходит некоторый процесс).
Операция — часть процесса, наделенная свойствами всей системы; управляемое мероприятие, выполняющее определенную цель, сопоставимую с целью всей системы. Например, операция составления расписания учебных занятий для учебного процесса в системе «университет».
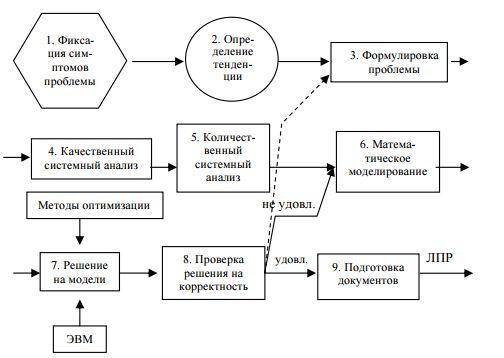
Весь комплекс работ по изучению и совершенствованию системы/операции проводит операционная группа системных аналитиков. Этот проект проводится в интересах лица, принимающего решения (ЛПР), которое может отвергнуть или принять проект. Схема этапов операционного проекта:
Характеристика этапов:
-
повод для изучения и совершенствования системы — фиксация симптомов, которые показывают проблемы в работе системы
-
установленные симптомы проблемы могут образовывать связанную цепочку фактов (тенденцию), которая помогает сформулировать проблему
-
важнейшим этапом исследования системы является четкая формулировка проблемы, которая присутствует на данному уровне жизнедеятельности системы;
-
качественный системный анализ — расщепление целостной системы (операции) на отдельные элементы (сущности)
-
количественный системный анализ позволяет описать все факторы, участвующие в операции на количественном уровне (на основе измеримых параметров). Для этого:
-
устанавливается критерий K — величина, количественно измеряющая степень достижения цели системы (операции)
-
вводятся количественные внутренние параметры системы, измеряющие факторы, участвующие в описании системы/операции
-
множество параметров разбивается на две части: неуправляемые (константы) (a1, a2, …, ak) = A и управляемые (переменные) (x1, x2, …, xn) = X
-
суть математического моделирования — установление количественных связей между K, A, X в виде операционной модели (ОМ). Первая часть ОМ — модель целевой функции, устанавливающей зависимость K = f(X, A), для которой требуется достигнуть минимального или максимального значения. Это выражение определяет смысл оптимизации системы. Вторая часть ОМ — математическое описание ограничений на выбор переменных X, в общем виде записываемых как phii(X, A) <= 0, I = 1, m. Каждая функция phii называется функцией ограничения. Полученная модель позволяет поставить задачу оптимизации следующим образом: найти такие управляемые переменные X, которые удовлетворяли бы вышеприведенной системе ограничений и обеспечивали наилучшее значение критерия K.
-
Решение поставленной математической задачи требует привлечения методов оптимизации.
-
Сопоставляя полученное решение с постановкой задачи, можно обнаружить противоречия, причиной которой может быть пренебрежение рядом ограничений или ошибками в построенной модели. Для установления приемлемости решения привлекается ЛПР.
-
Найденное оптимальное решение X* позволяет подготовить управляющее решение в форме документа для ЛПР.
Таким образом, операционное исследование — итерационный процесс, который сходится к определенному оптимальному решению. Исследование операций — наука о количественном обосновании оптимальных решений на основе построения и использования математической модели.
4. Декомпозиция отношений
Нормализация – это процесс разбиения или декомпозиции исходного отношения на несколько отношений с целью устранения нежелательных функциональных зависимостей, приводящих к возникновению избыточности хранения информации и аномалиям добавления, удаления, обновления.
Аппарат нормализации отношений разработан Коддом. В нем определены различные нормальные формы. Каждая нормальная форма ограничивает типы допустимых функциональных зависимостей отношений. Кодд выделил три нормальные формы: 1, 2, 3НФ, а сегодня определены НФБК, 4НФ, 5НФ.
Теорема Хеза: Пусть R(A,B,C) является отношением с атрибутами A,B,C. Если оно удовлетворяет зависимости A → B, то R равно соединению его проекций (A,B) и (A,C).
1НФ – Отношение находится в 1НФ, если значения всех атрибутов атомарные, то есть значение атрибута не должно быть множеством или повторяющейся группой.
2НФ – Отношение находится в 2НФ, если оно находится в 1НФ и нет частичной функциональной зависимости неключевых атрибутов от ключа (зависимость неключевых атрибутов от части ключа). Или если каждый не ключевой атрибут функционально полно зависит от ключа.
Рассмотрим на примере, почему наличие этих частичных функциональных зависимостей нежелательно при работе с отношением.
Пример 1:
Пусть имеется отношение Поставки, в котором имеется информация о поставщике, товаре и его цене. Каждый товар имеет одну цену и может поставляться несколькими поставщиками.
|
Поставщик |
Товар |
Цена |
|
Иванов |
Мыло |
2000 |
|
Иванов |
Сахар |
2500 |
|
Петров |
Мыло |
2000 |
|
Петров |
Сыр |
20000 |
Ключ: Поставщик, товар, тогда по определению ключа
Поставщик, товар цена
Кроме этого имеется зависимость атрибута «цена» от части ключа:
товар цена, значит отношение не в во 2НФ.
В отношении имеется избыточность хранения информации: сведения о цене товара повторяется несколько раз для разных поставщиков, хотя по условию цена товара фиксирована.
Разложив отношение на два, выполнив операцию проекции над атрибутами, входящими в частичную функциональную зависимость и, удалив из исходного отношения не ключевые атрибуты, зависящие от части ключа, устраним нежелательную функциональную зависимость, в результате чего получим два отношения:
R1 (Поставщик, товар); R2 (товар, цена). Отношение R1 имеет кортежи:(«Иванов,мыло», «Иванов , сахар», «Петров,мыло», «Петров, сыр»); отношение R2 имеет кортежи:(«мыло,2000», «сахар, 2500», «сыр, 20000»). Избыточность хранения устранена, аномалии устранены, кроме этого декомпозиция выполнена без потери информации.
В общем случае при наличии частичной ФЗ для приведения отношения R к 2 НФ выполняется дважды операция проекции, в результате чего получается два отношения: в первое отношение включается часть ключа и все не ключевые атрибуты, от неё зависящие, во второе отношение-ключ и оставшиеся не ключевые атрибуты.
Пример 2:
|
1 |
2 |
3 |
4 |
5 |
|
1 |
2 |
20 |
1 |
5 |
|
2 |
2 |
20 |
2 |
1 |
|
3 |
3 |
30 |
2 |
1 |
|
3 |
4 |
40 |
1 |
5 |
Ключи: <1,2>,<1,3>,<1,4>,<1,5>,<2,4>,<2,5>,<3,4>,<3,5>
1, 2 3; 2 3;
В результате нормализации получим два отношения:
R1 (2, 3)
|
|
|
|
2 |
3 |
|
2 |
20 |
|
3 |
30 |
|
4 |
40 |
R2 (1, 2, 4, 5)
|
1 |
2 |
4 |
5 |
|
1 |
2 |
1 |
5 |
|
2 |
2 |
2 |
1 |
|
3 |
3 |
2 |
1 |
|
3 |
4 |
1 |
5 |
Первое отношение находится во второй нормальной форме, так как оба атрибута – ключи, причём не составные, поэтому здесь не может быть частичной зависимости. Кроме этого можно сказать, что для анализа на частичную зависимость нужно иметь в отношении как минимум три атрибута, а здесь их – два.
Анализируем второе отношение:
Ключи: <1,2>,<1,4>,<1,5>,<2,4>,<2,5>.
<1,4> 5; 4 5 – то есть частичная функциональная зависимость. Разбиваем отношение R2 на R3 и R4:
R3(1,2,4)
|
3 |
||
|
1 |
2 |
4 |
|
1 |
2 |
1 |
|
2 |
2 |
2 |
|
3 |
3 |
2 |
|
3 |
4 |
1 |
Отношение R4 включает только два кортежа, так как два других удаляются.
R4(4,5)
|
4 |
|
|
4 |
5 |
|
1 |
5 |
|
2 |
1 |
Ответ: R1(2,3); R3(1,,2,4); R4(4,5).
3НФ – Отношение находится в 3НФ, если оно находится в 2НФ и отсутствуют транзитивные зависимости не ключевых атрибутов от ключа.
Иными словами, если выполняется совокупность условий:
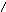
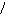
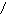
A → B; В → С;
С → А; В → А; С → B, то в отношении существует транзитивная зависимость неключевых атрибутов от ключа A и отношение не находится в 3 НФ. Если хотя бы одно из условий не выполняется, то такой зависимости между атрибутами A,B,C нет. Причем атрибуты A,B,C могут быть составными.
Пример 1:
Пусть имеется отношение «Хранение» с информацией о наименовании фирмы, о наименовании складов, принадлежащих фирмам и объеме продукции на складах, причем каждая фирма получает товары с одного склада, склад определяется объемом. Таблица «Хранение» выглядит следующим образом:
|
Фирма |
Склад |
Объем |
|
МЕНАТЕП |
МКЧ |
200 |
|
ИКС |
ДП |
600 |
|
АСКО |
ДП |
600 |
|
ПАРУС |
СК |
200 |
Ключ в отношении атомарный: <фирма>
фирма склад;склад объем ;
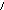
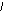
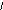
объем фирма;склад фирма; объем склад.
По определению, это отношение не в 3 НФ, в результате чего возникает избыточность хранения информации. Нормализация отношения путем выполнения дважды операций проекции устраняет избыточность и приводит отношение к 3НФ: R1(фирма, склад); R2(склад, объем).
Такое разбиение является разбиением без потери информации. Если бы мы выполнили декомпозицию таким образом: R1(фирма, склад); R2(фирма, объем), то при соединении этих отношений было бы непонятно, к какому складу относится фирма, если скла имеет одинаковый объем, то есть происходит потеря информации.
Таким образом, в общем случае при нормализации отношения R при переходе к 3НФ, получается два отношения- R1 и R2. В первое отношение включаются атрибуты B и C , во второе – A, B и все оставшиеся атрибуты исходного отношения R.
Пример 2:
|
1 |
2 |
3 |
|
1 |
2 |
1 |
|
2 |
2 |
1 |
|
3 |
3 |
2 |
|
4 |
4 |
1 |
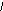

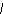
Ключи: <1>
1 2 ; 2 3; 3 1;3 2 ;2 1, поэтому необходима нормализация, в результате которой получаем: R1(1,2); R2(2,3).
5. Классификация информационно-вычислительных сетей (=76)
Информационно-вычислительная сеть, представляет собой систему компьютеров, объединенных каналами передачи данных.
Информационно-вычислительные сети, в зависимости от территории, ими охватываемой, подразделяются на:
• локальные (ЛВС или LAN — Local Area Network);
• региональные (РВС или MAN — Metropolitan Area Network);
• глобальные (ГВС или WAN — Wide Area Network).
Локальные – абоненты находятся на небольшом (до 10-15 км) расстоянии друг от друга. ЛВС объединяет абонентов, расположенных в пределах небольшой территории. Обычно такая сеть привязана к конкретному объекту.
Региональные – абоненты находятся в пределах одного города, района, области или даже небольшой страны. Обычно расстояния между абонентами региональной ИВС составляют десятки — сотни километров.
Глобальные – абоненты удалены друг от друга на значительное расстояние, часто расположены в различных странах или на разных континентах. Взаимодействие между абонентами такой сети может осуществляться на базе телефонных линий связи, систем радиосвязи и даже спутниковой связи.
Локальные вычислительные сети могут входить как компоненты в состав региональной сети, региональные сети — объединяться в составе глобальной сети, и, наконец, глобальные сети могут также образовывать сложные структуры. Именно такая структура принята в сети Интернет.
По принципу организации передачи данных сети можно разделить на две группы:
• последовательные;
• широковещательные.
В последовательных передача данных выполняется последовательно от одного узла к другому, и каждый узел ретранслирует принятые данные дальше. Практически все глобальные, региональные и многие локальные сети относятся к этому типу.
В широковещательных сетях в каждый момент времени передачу может вести только один узел, остальные узлы могут только принимать информацию. К такому типу сетей относится значительная часть ЛВС, использующая один общий канал связи (моноканал) или одно общее пассивное коммутирующее устройство.
По топологии ИВС могут быть:
• шинные (линейные, bus);
• кольцевые (петлевые, ring);
• радиальные (звездообразные, star);
• распределенные радиальные (сотовые, cellular);
• иерархические (древовидные, hierarchy);
• полносвязные (сетка, mesh);
• смешанные (гибридные).
6. Структура информационно-логической модели АСОИУ (свободен)
7. Операционные системы и мультипрограммирование (Оля)
8. Методологические основы теории принятия решений (=73)
Особенности задачи выбора решений:
-
в ряде задач варианты поведения операций представляют собой небольшое число отдельных альтернатив, не всегда однородных (строить большой завод, или строить малый, а потом расширять производство). Поэтому в теории принятия решений (ТПР) рассматривается как самостоятельный вопрос задание множества альтернатив, на котором ищется оптимальное решение;
-
часто множество альтернатив сначала неизвестно, поэтому говорят о генерации альтернатив в процессе решения задачи;
-
оценка ценности каждой альтернативы часто не сводится к сравнению количественных параметров, поэтому в ТПР применяют специальные методы измерения полезности альтернатив;
-
критерий является не скалярной величиной, а вектором. Встает вопрос о многокритериальной оптимизации;
-
во многих задачах присутствуют нечеткие переменные и нечеткие критерии, поэтому в ТПР есть специальный раздел принятия решений в «расплывчатых» ситуациях;
-
в ряде задач присутствуют несколько сторон, преследующих разные интересы (боевые действия, поведение государств, конкурирующие фирмы), принимающие решения в одной и той же системе (появляются конфликтные ситуации); для решения таких задач используется теория игр;
-
зачастую одни решения приводят к необходимости принимать другие решения, то есть требуется изучать многоэтапные решения;
-
во многих задачах принимаются групповые решения, где альтернативы оцениваются группой экспертов-специалистов; такой метод называется методом экспертных оценок.
9. Проектирование БД с использованием метода «сущность-связь»
БД - совокупность данных, хранящихся во внешней памяти ЭВМ, описывающих некоторую предметную область.
Три уровня абстракции:
– концептуальный (семантический уровень представления данных в виде абстрактных понятий, учитывающих особенности предметной области)
– логический (уровень представления в виде структуры данных – сущностей, атрибутов и связей)
– физический (уровень реализации базы данных).
Сущность – объект предметной области.
Атрибут – характеристика, свойство сущности.
Экземпляр сущности – конкретный объект с конкретными значениями атрибутов. Каждый экземпляр сущности уникален.
Связь – отображение/соответствие экземпляра одной сущности на экземпляр другой сущности.
Виды связей:
– 1:1 – каждому экземпляру одной сущности соответствует один экземпляр другой
– 1:n – каждому экземпляру одной сущности соответствует несколько экземпляров другой.
– n:m – многие ко многим. Допустимо на концептуальном и логическом уровне. На физическом уровне добавляется новая зависимая сущность, связанная идентифицирующими связями один ко многим с сущностями, находившимися в исходном отношении.
Модель Чена. Концептуальный уровень

Модель Бахмана. Концептуальный уровень
IDEF1X. Логический и физический уровень
Методология IDEF1Х предназначена для моделирования структур баз данных на основе диаграмм сущность-связь (ER-диаграмм).
Атрибут или группа атрибутов, которые однозначно идентифицируют экземпляры сущности, называются первичным ключом (Primary key).
Идентифицирующая связь устанавливается между независимой и зависимой сущностями (экземпляр зависимой сущности определяется только через отношение к сущности, которая его идентифицирует), при этом атрибуты первичного ключа родительской сущности переносятся в состав первичного ключа дочерней сущности (миграция ключа). В дочерней сущности эти атрибуты помечаются как внешний ключ (Foreign Key).
При установлении неидентифицирующей связи дочерняя сущность остается независимой. Атрибуты первичного ключа родительской сущности мигрируют в состав неключевых атрибутов дочерней сущности. Для неидентифицирующей связи можно указать обязательность. В случае обязательной связи при генерации схемы базы данных атрибут внешнего ключа получит признак NOT NULL, несмотря на то, что внешний ключ не войдет в состав первичного ключа дочерней сущности. В случае необязательной связи внешний ключ может принимать значение NULL. Необязательная неидентифицирующая связь помечается прозрачным ромбом со стороны родительской сущности.
Иерархия наследования (категорий) – особый тип объединения сущностей, обладающих общими характеристиками. В этом случае формируется обобщенная сущность (родовой предок), а специфическая для каждого типа информация может быть расположена в категориальных сущностях (потомках). Для каждой категории указывается дискриминатор – атрибут родового предка, который показывает, как отличить одну категориальную сущность от другой.
Имя роли – синоним атрибута внешнего ключа, который показывает, какую роль играет атрибут в дочерней сущности. Имя роли используется в случае, когда несколько атрибутов одной сущности имеют одинаковую область значений, но разный смысл или в случае рекурсивных связей (одна и та же сущность является и родительской и дочерней одновременно). При задании рекурсивной связи атрибут мигрирует в качестве внешнего ключа в состав неключевых атрибутов той же сущности. Так как атрибут не может появиться дважды в одной сущности под одним именем, он получает имя роли. Рекурсивная связь может быть только неидентифицирующей.
10. Способы коммутации в сетях (Лиза)
11. Функциональная модель АСОИУ
Элементами функциональной модели являются функции системы или решаемые задачи, а связями – информационные связи между функциями. Построение функциональной модели часто оказывается просто необходимым для грамотного проектирования.
В разработке функциональной модели принимают участие наиболее квалифицированные специалисты по системному анализу и созданию АСУ совместно с экспертами по создаваемой системе. Такая группа не должна быть многочисленной (3-5 квалифицированных человек). Ошибки в функциональной модели приводят к неправильному построению системы.
Разработка функциональной модели включает в себя:
-
Определение выполняемых системных функций и перечня решаемых задач. (Функции – то для чего служит система, что исполняет, задачи – что она решает для исполнения функций)
-
Оптимизация структуры создаваемой системы (Например, если самыми разными отделами решается одна и та же задача, то, возможно, ее стоит выделить в отдельное исполнение и назначить отдельных людей.)
-
Распределение функций по уровням иерархии системы. (Например, президент не должен инспектировать заборы в Челябинской области.)
-
Разделение функций и задач между персоналом и вычислительными средствами.
-
Оценка взаимосвязи решаемых задач и определение информационных связей между функциями. (Задачи решаются не по отдельности, а комплексе. Часто несоответствие, например, графиков (планов по времени) задач друг другу приводит к плачевным последствиям)
-
Описание в самом общем виде алгоритмов и процедур обработки информации в создаваемой системе.
Принципы построения функциональной модели:
-
разделяй и властвуй – решение сложных проблем путем их разделения на множество меньших задач, решение которых представляет меньшую трудность.
-
иерархического упорядочивания – организация составных частей в иерархические структуры с добавлением новых деталей на каждом уровне. Эти две принципа базовых.
-
абстрагирования – выделение существенных свойств и отвлечение от несущественных.
-
формализация – строгий методический подход к решению проблемы.
-
непротиворечивость – обоснованность и согласованность элементов.
-
структурирование данных – данные должны быть иерархически организованны.
Средства:
-
DFD – диаграмма потоков данных;
-
SADT – IDEF0, IDEF1, … – функциональные диаграммы;
-
ERD – диаграмма "сущность–связь" и т.д.
12. Режим разделения времени
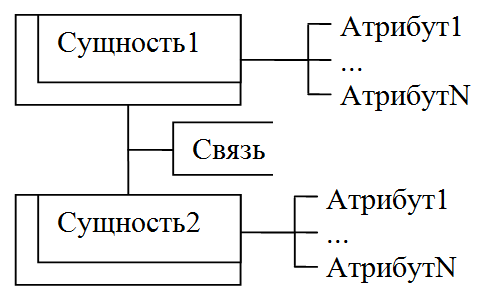
В составе компьютерных систем появились терминалы (вначале телетайпы, затем дисплеи), возникла необходимость реализации в ОС режима разделения времени (time sharing ) – возможности одновременной работы пользователей со своими заданиями с терминалов, ввода их в систему, запуска (при наличии свободного процессора), управления заданиями с терминала, их приостановки, отладки, визуализации на терминале их результатов. Особенности ОС с режимом разделения времени:
Хранение заданий в памяти или на диске. Ресурсы процессора распределены между несколькими заданиями, находящимися в памяти или на диске. Задание загружается в память , если оно является пакетным и выбрано операционной системой для выполнения, либо если оно активируется пользователем с терминала. Процессор выделяется только тем заданиям, которые находятся в памяти.
Откачка и подкачка (swapping) Возможна ситуация, когда какое-либо задание, управляемое с терминала, неактивно (например, выполняет ввод-вывод). В этом случае ОС может принять решение о временной выгрузке (swap out) образа памяти задания из памяти на диск, с целью освобождения памяти для других заданий. При повторной активизации задания оно вновь загружается в память ( swapped in ).
ОС выполняет поддержку диалогового взаимодействия между пользователем и системой.
Режим разделения времени
Назначение - обслуживание конечного числа пользователей с приемлемым для каждого пользователя временем ответа на их запросы (рис. 13.6).
Рис. 13.6. Организация работы ЭВМ в режиме разделения времени
Основные характеристики:
Многотерминальная многопользовательская система.
Любой пользователь со своего терминала может обратиться к любым ресурсам ЭВМ.
У пользователя создается впечатление, что он один работает на ЭВМ.
Реализация.
Время работы машины разделяется на кванты tk.
Каждый квант выделяется для соответствующего терминала. Терминалы могут быть активными и пассивными: активный реально включен в обслуживание (за ним работает пользователь), пассивный - нет (квант не выделяется). После обслуживания всех терминалов последовательность квантов повторяется.
Единого способа выбора времени кванта не существует. Иногда оно выбирается по количеству команд, которое должна выполнить ЭВМ за это время.
В основе реализации режима разделения времени лежит одноочередная дисциплина обслуживания пользователей.
13. Задачи выбора решений (1 вариант)
Представляют собой задачу поиска показателя эффективности W в виде функции:
![]()
где
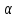 – заранее известные факторы;
– заранее известные факторы;
x – элементы решения;
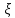 – неизвестные
факторы.
– неизвестные
факторы.
Т.к. W зависит от неизвестных факторов, задача поиска (оптимального) решения тоже теряет определенность. Математическим языком задачу поиска решения можно сформулировать следующим образом:
Наглядные примеры задач принятия решений (для лучшего понимания):

Методы
решения задач принятия решений зависят
от природы неизвестных факторов
 ,
т.е. от вида неопределенности:
,
т.е. от вида неопределенности:
Неизвестные
факторы
 представляют собой случайные величины,
статистические характеристики которых
известны (стохастические задачи).
Примеры таких задач:
представляют собой случайные величины,
статистические характеристики которых
известны (стохастические задачи).
Примеры таких задач:
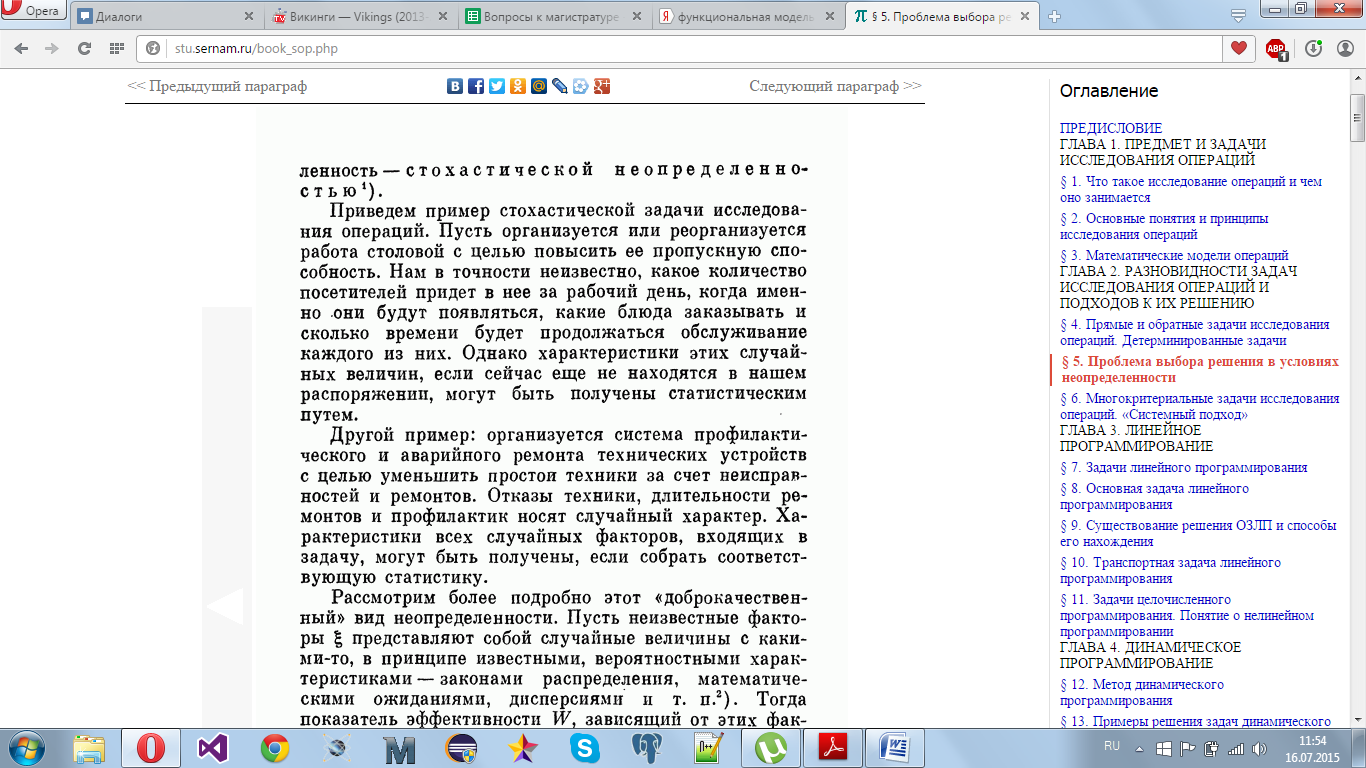
Для
решения можно заменить случайные факторы
 их мат ожиданиями в случае, если случайные
факторы мало отклоняются от своих мат
ожиданий.
их мат ожиданиями в случае, если случайные
факторы мало отклоняются от своих мат
ожиданий.
Если же
это условие не выполняется, т.е. факторы
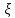 "существенно случайны", то заменять
их мат ожиданиями нельзя. В этом случае
можно использовать подход, который
называется "оптимизация в среднем",
при котором в качестве показателя
эффективности W выбирается
среднее значение:
"существенно случайны", то заменять
их мат ожиданиями нельзя. В этом случае
можно использовать подход, который
называется "оптимизация в среднем",
при котором в качестве показателя
эффективности W выбирается
среднее значение:

При этом эффективность каждой отдельной операции может значительно отличаться от мат ожидания как в большую, так и в меньшую сторону – таким образом "выигрыш" от использования этого метода происходит "в общем" при многократном повторении операций. Это наводит на мысль, что и этим методом можно пользоваться не всегда:

Также этот метод неэффективен для единичных задач, для которых низкое значение W может привести к неприемлемым результатам.
Неизвестные
факторы
 не могут быть изучены и описаны
статистическими методами. Такое
может быть в случае, если законы
распределения
не могут быть изучены и описаны
статистическими методами. Такое
может быть в случае, если законы
распределения
 существуют, но к моменту принятия решения
не могут быть получены, например:
существуют, но к моменту принятия решения
не могут быть получены, например:
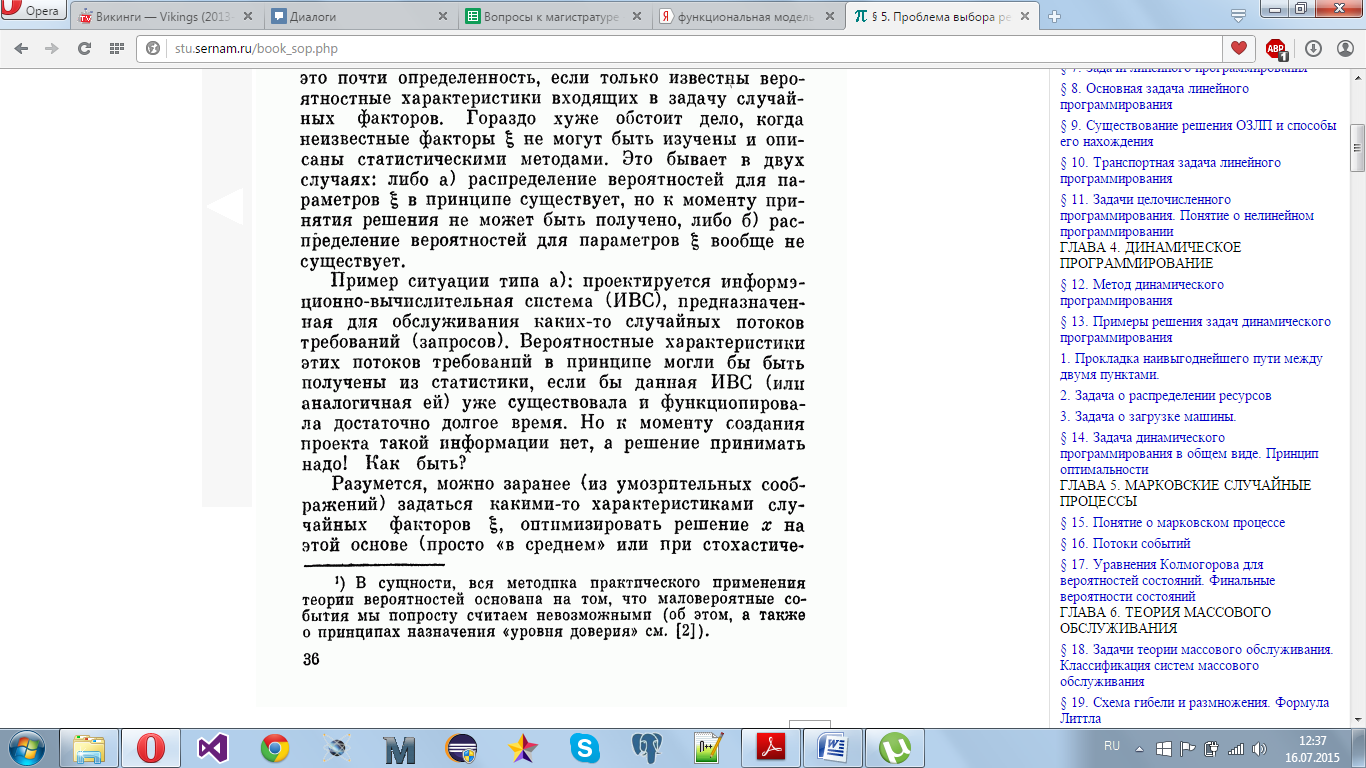
В этом случае применяют адаптивные алгоритмы управления: некоторые элементы решения х остаются свободными, изменяемыми. Сначала выбираются произвольные элементы решения, система пускается в ход, и по мере накопления опыта изменяются элементы решения таким образом, чтобы увеличивалась эффективность. Адаптивные алгоритмы избавляют от предварительного сбора статистики и могут перестраиваться при "изменении обстановки".
Также
неизвестные факторы
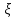 могут вообще не иметь вероятностных
характеристик (нестохастическая
неопределенность).
могут вообще не иметь вероятностных
характеристик (нестохастическая
неопределенность).
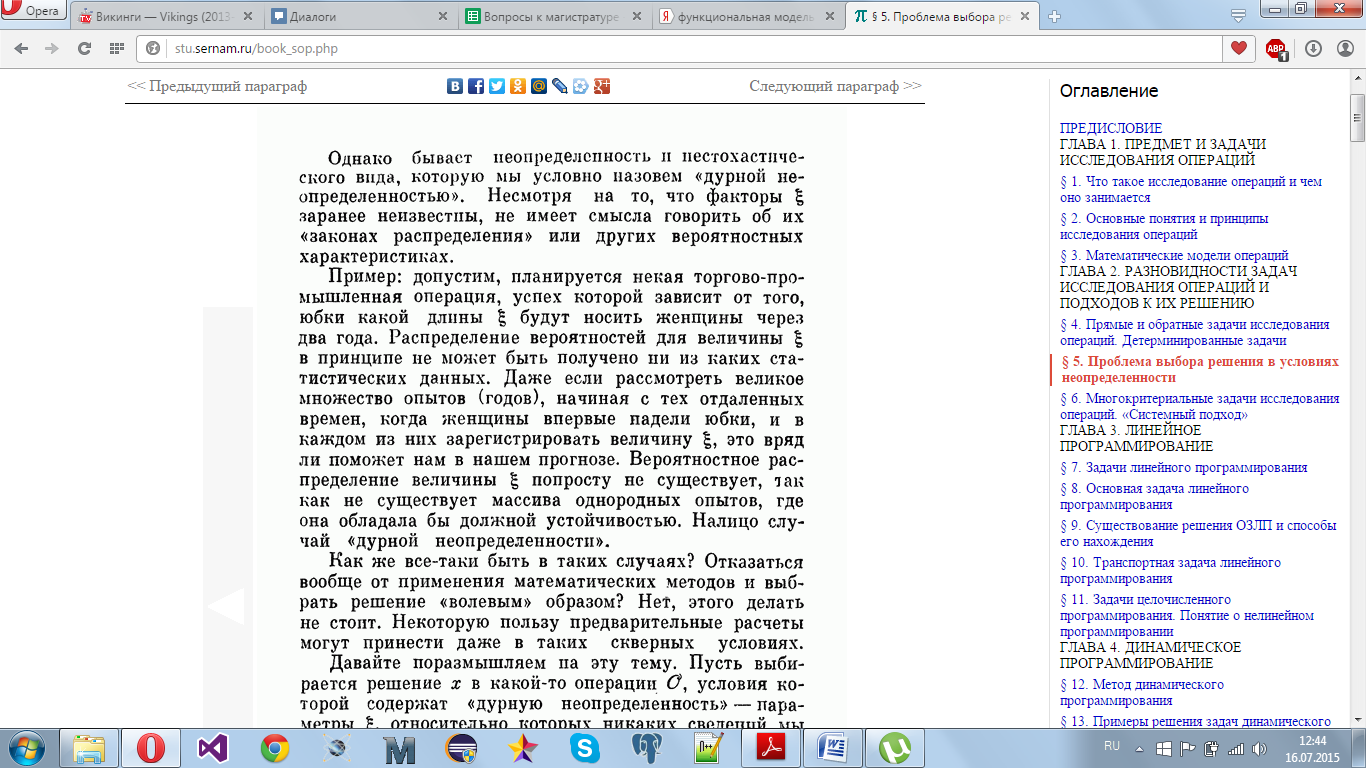
В данном
случае оптимальным будет не выбор
решения х, оптимального для каких-либо
значений факторов
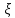 (выбранных произвольно), а выбор некого
компромиссного решения, которое может
не быть оптимальным ни для каких условий,
но все таки быть приемлемым в целом их
диапазоне.
(выбранных произвольно), а выбор некого
компромиссного решения, которое может
не быть оптимальным ни для каких условий,
но все таки быть приемлемым в целом их
диапазоне.
13. Задачи выбора решений (2 вариант)
Общая постановка. Задачей принятия решения назовем пару (Ω, P), где Ω — множество вариантов, P – принцип оптимальности. Решение задачи — множество Ω P ≤ Ω, полученное с помощью принципа оптимальности P. Математическим выражение принципа оптимальности P служит функция выбора CP. Она сопоставляет любому множеству X ≤ Ω его часть CP(X). Элементы множества Ω называются альтернативами (вариантами). Принцип оптимальности P задает понятие лучших альтернатив: лучшими считают альтернативы, принадлежащие CP(Ω).
Пусть некоторое свойство альтернатив из Ω выражается числом, то есть существует отображение φ: Ω →E1. Такое свойство называется критерием, а число φ(x) – оценка альтернативы x по критерию. Одновременный учет нескольких свойств может быть затруднительным. При этом можно выделить группы свойств, называемых аспектами.
Аспект – сложное свойство альтернатив, одновременно учитывающее все свойства, входящие в группу.
Пусть все свойства k1, …, km, учитываемые при решении задачи (Ω, P), являются критериями. Критериальным пространством называют пространство Em, координаты которого – оценки соответствующих критериев.
Пример. При определении маршрута перевозок альтернативы – маршруты. Диспетчер учитывает свойства: протяженность, загрузка, энергоемкость, безопасность, техническое обслуживание и др.
Техническое обслуживание – число станций, сроки выполнения ремонтных работ и т. д. ТО – аспект.
Стоимость маршрута – стоимость топлива, обслуживания и т. д. Это тоже аспект. Но так как стоимость вычислима, то это критерий.
Сформулируем схему процесса принятия решения. Формируется множество Ω. Его подготавливают для последующего решения задачи выбора. Для формирования Ω используют условия возможности и допустимости альтернатив, которые определяют конкретными ограничениями задачи. При этом считают известным универсальное множество альтернатив Ωу. Таким образом, задача формирования Ω есть задача выбора (Ωу, P1), где P1 – принцип оптимальности, выражающий условия допустимости.
Множество Ω = CP1(Ωу), полученное в результате решения, называют исходным множеством альтернатив (ИМА).
Таким образом, задача принятия решения сводится к решению двух последовательных задач выбора.
В процессе решения участвуют лицо, принимающее решение (ЛПР), эксперты, консультанты. ЛПР имеет цель и служит мотивом постановки задачи, дает полномочия и несет ответственность. Его функция – выделять ΩP. ЛПР дает информацию о принципе оптимальности P.
Эксперт не несет ответственности, он дает оценки альтернатив для формирования ИМА и решения задачи выбора.
Консультант – специалист по теории выбора и принятия решений. Он разрабатывает модель принятия решений, организует работу ЛПР и экспертов.
14. Создание и модификация БД
Стандарт SQL не определяет, как должны создаваться базы данных, поэтому в каждом из диалектов языка SQL обычно используется свой подход.
Механизм создания в СУБД MS SQL Server, используется оператор CREATE DATABASE.
Процесс создания БД состоит из двух этапов: сначала организуется сама база данных (файл *.mdf), а затем принадлежащий ей журнал транзакций. (файл *.ldf). В файле базы данных записываются сведения об основных объектах (таблицах, индексах и т.д.), а в файле журнала транзакций – о процессе работы с транзакциями (контроль целостности данных, состояния базы данных до и после выполнения транзакций).
Создание базы данных в системе SQL-сервер осуществляется командой CREATE DATABASE. Следует отметить, что процедура создания базы данных в SQL-сервере требует наличия прав администратора сервера.
<определение_базы_данных> ::=
CREATE DATABASE имя_базы_данных
[ON [PRIMARY]
[ <определение_файла> [,...n] ]
[,<определение_группы> [,...n] ] ]
[ LOG ON {<определение_файла>[,...n] } ]
[ FOR LOAD | FOR ATTACH ]
Имя базы данных должно быть уникальным в пределах сервера и не может превышать 128 символов. Параметр ON определяет список файлов на диске для размещения информации, хранящейся в базе данных. Параметр PRIMARY определяет первичный файл. Если он опущен, то первичным является первый файл в списке. Параметр LOG ON определяет список файлов на диске для размещения журнала транзакций. Имя файла для журнала транзакций генерируется на основе имени базы данных, и в конце к нему добавляются символы _log.
<определение_файла>::=
([ NAME=логическое_имя_файла,]
FILENAME='физическое_имя_файла'
[,SIZE=размер_файла ]
[,MAXSIZE={max_размер_файла |UNLIMITED } ]
[, FILEGROWTH=величина_прироста ] )[,...n]
логическое имя файла – это имя файла, под которым он будет опознаваться при выполнении различных SQL-команд.
Физическое имя файла предназначено для указания полного пути и названия соответствующего физического файла, который будет создан на жестком диске. Это имя останется за файлом на уровне операционной системы.
<определение_группы>::=FILEGROUP имя_группы_файлов
<определение_файла>[,...n]
МОДИФИКАЦИЯ БД
Выполняется с помощью следующей конструкции:
<изменение_базы_данных> ::=
ALTER DATABASE имя_базы_данных
{ ADD FILE <определение_файла>[,...n]
[TO FILEGROUP имя_группы_файлов ]
| ADD LOG FILE <определение_файла>[,...n]
| REMOVE FILE логическое_имя_файла
| ADD FILEGROUP имя_группы_файлов
| REMOVE FILEGROUP имя_группы_файлов
| MODIFY FILE <определение_файла>
| MODIFY FILEGROUP имя_группы_файлов
<свойства_группы_файлов>}
Может быть изменено не более одного параметра конфигурации базы данных.
Можно добавить (ADD) новые файлы данных (в указанную группу файлов или в группу, принятую по умолчанию) или файлы журнала транзакций.
Параметры файлов и групп файлов можно изменять (MODIFY).
Для удаления из базы данных файлов или групп файлов используется параметр REMOVE. В качестве свойств группы файлов используются следующие:
READONLY – группа файлов используется только для чтения; READWRITE – в группе файлов разрешаются изменения; DEFAULT – указанная группа файлов принимается по умолчанию.
15. Разработка модели защиты данных в АСОИУ
На основе имеющегося опыта можно сформулировать следующие фундаментальные принципы организации защиты информации:
-
системность;
-
специализированность;
-
неформальность.
Основные требования принципа системности сводятся к тому, что для обеспечения надежной защиты информации в современных АСОИУ должна быть обеспечена надежная и согласованная защита во всех структурных элементах, на всех технологических участках автоматизированной обработки информации и во все время функционирования АСОИУ.
Специализированность как принцип организации защиты предполагает два аспекта:
1) ввиду специфических особенностей рассматриваемой проблемы надежный механизм защиты может быть спроектирован и организован лишь профессиональными специалистами по защите информации,
2) для обеспечения эффективного функционирования механизма защиты в составе АСОИУ должны функционировать специалисты по защите информации.
В соответствии с данным принципом значительное распространение за рубежом получает специализация по различным аспектам ЗИ.
Принцип неформальности означает, что методология проектирования механизма защиты и обеспечения его функционирования в основе своей является неформальной. Эта неформальность интерпретируется в том смысле, что в настоящее время не существует инженерной методики проектирования механизма защиты в традиционном понимании этого термина.
Общие требования к механизму защиты следующие:
адекватность, т.е. обеспечение требуемого уровня защиты (определяется степенью секретности подлежащей обработке информации) при минимальных издержках на создание механизма защиты и обеспечение его функционирования;
удобство для пользователей, основу чего составляет требование, чтобы механизм защиты не создавал для пользователей дополнительных трудностей, требующих значительных усилий для их преодоления; минимизация привилегий в доступе, предоставляемых пользователям, т.е. каждому пользователю должны предоставляться только действительно необходимые ему права по обращению к ресурсам системы и данным;
полнота контроля, т.е. обязательный контроль всех обращений к защищаемым данным; наказуемость нарушений, причем наиболее распространенной мерой наказания является отказ в доступе к системе;
экономичность механизма, т.е. обеспечение минимальности расходов на создание и эксплуатацию механизма;
несекретность проектирования, т.е. механизм защиты должен функционировать достаточно эффективно даже в том случае, если его структура и содержание известны злоумышленнику.
Основные положения по разработке систем ЗИ могут быть сформулированы так:
1) защита информации является не разовым мероприятием и даже не совокупностью мероприятий, а непрерывным процессом, который должен протекать (осуществляться) во все время и на всех этапах жизненного цикла АСОИУ;
2) осуществление непрерывного процесса защиты информации возможно лишь на базе промышленного производства средств защиты;
3) создание эффективных механизмов защиты может быть осуществлено высококвалифицированными специалистами-профессионалами в области защиты информации;
4) поддержание и обеспечение надежного функционирования механизмов защиты информации в АСОИУ сопряжено с решением специфических задач и поэтому может осуществляться лишь профессионально подготовленными специалистами.
16. Многопользовательский режим работы (свободен)
17. Функции полезности и критерии при принятии решений (82 – второй вариант)
Критерий принятия решений - это функция, выражающая предпочтения лица принимающего решения (ЛПР) и определяющая правило, по которому выбирается приемлемый или оптимальный вариант решения.
То есть в случае многокритериального анализа необходимо:
1. Чётко сформулировать цель, задачу и требуемый результат.
2. Классифицировать характеристики вариантов.
3. Беспристрастно выбрать критерии.
Критерий должен позволять ответить на один из следующих вопросов:
1. Является ли альтернатива допустимой: может ли она при условии, что остальные будут хуже, рассматриваться как решение?
2. Является ли альтернатива удовлетворительной, иначе говоря, можно ли её рассматривать в качестве решения задачи независимо от других альтернатив?
3. Какая из двух сравниваемых альтернатив лучше?
4. Является ли альтернатива оптимальной?
Критерии, отвечающие на вопросы первого или второго типов, называются критериями допустимости. Критерии, отвечающие на вопросы третьего и четвертого типов - критериями оптимальности (сравнения).
Различия между двумя этими типами очень интересны. Как правило, если человека просят сформулировать критерий, то предлагают критерий допустимости, так как такие критерии проще формулировать. Но использование только критериев допустимости не позволяет сравнивать хотя бы две альтернативы, если они обе допустимы. В этом случае потребуется критерий оптимальности. Чтобы оценить альтернативу по критерию допустимости, нужна только сама эта альтернатива. Для оценки по критерию оптимальности нужны, по крайней мере, две альтернативы, чтобы их можно было сравнить.
Введение в задачу дополнительного критерия допустимости сужает множество допустимых вариантов решения. Дополнительный критерий оптимальности расширяет множество вариантов решения, заслуживающих детального рассмотрения с учётом значения, придаваемого каждому критерию.
Критерии не должны быть сами по себе, они должны исходить из цели, преследуемой при решении задачи.
Отсюда следуют следующие требования к критериям:
a. Соответствие цели и задаче.
b. Критичность. «Чувствительность» к изменению варианта выбора.
c. Вычислимость критериев.
d. Полнота и минимальность.
e. Декомпозицируемость, то есть, чтобы можно было рассматривать каждый критерий независимо от других.
Функция полезности отражает предпочтения ЛПР по отношению к риску. Принятие или непринятие решения, связанного с риском, во многом зависит от характера функции полезности. Лицо, принимающее решения, оценивает не просто ожидаемые величины выигрыша и проигрыша, но и их полезность и вредность. Тогда принимается тот вариант решения, для которого полезность результата оказывается большей, чем у других вариантов.
Например, перед принятием важного решения руководитель должен решить вопрос о страховании своей ответственности. Обозначим ожидаемый выигрыш величиной В, потери величиной (-В), полезность выигрыша - П(В) и вредность потерь - П(-В). Тогда, если договор страхования заключен, «полезность» составит П(-В) в соответствии с величиной отдаваемого страхового взноса. «Полезность» потерь при отсутствии страховки должна быть скорректирована в соответствии с вероятностью неудачи Р и составит Р × П(-н). Следовательно, страховать риск следует в том случае, если П(-В) > Р × П(-н).
Построение функции полезности возможно после исследования действий ЛПР в обстановке, связанной с риском. Например, некто владеет ценными бумагами, которые с вероятностью 0,5 могут выиграть 1000 д.е. или не выиграть ничего. Решение расстаться с ними для уравновешенного лица, осторожного и смелого, приходит при различных значениях котировок курсовой стоимости ценных бумаг.
Таким образом, лицо, равнодушное к риску уступит свои ценные бумаги за величину в 500 д.е., соответствующую математическому ожиданию выигрыша. Человек, склонный к осторожности не станет рисковать и заберет гарантированный выигрыш в 300 д.е., а смелый владелец бумаг, склонный к риску дождется более высоких котировок бумаг, например в 700 д.е.
18. Поиск и сортировка данных, индексирование БД (Рома)
19. «Клиент/серверные» сети
Клиент-серверная сеть –распределенная система, компонентами которой являются клиенты, запрашивающие некоторые ресурсы или сервисы, и серверы, их представляющие.
Сетевые ресурсы в такой сети концентрируются на сервере, он же представляет услуги централизованного управления этими ресурсами.
Клиентами сети на основе сервера являются компьютеры пользователей, которые обращаются к серверу за услугами по решению прикладных задач, таких как работа с общими файлами, отправка и получение электронной почты, ресурсоемкие вычисления, доступ в Интернет и т.п.
Взаимодействие клиента и сервера стандартизировано. Инициатором обмена является клиент, который посылает запрос серверу, находящемуся в состоянии ожидания запроса.
Некоторые виды серверов, используемых в глобальной и локальных сетях:
Файловый сервер — предназначен для хранения и совместного использования файлов, доступ к которым осуществляется по сети.
Сервер печати (принт-сервер) — обеспечивает пользователей возможностью распечатки документов на сетевом принтере.
Почтовый сервер — обслуживает процессы передачи электронных сообщений между пользователями сети.
Коммуникационный сервер — управляет трафиком между узлами локальной сети и удаленными узлами.
В корпоративных сетях обычно одновременно используется несколько серверов разного назначения. Поэтому необходимо учитывать все возможные нюансы, которые могут проявиться при расширении сети, с тем чтобы изменение роли определенного сервера в дальнейшем не отразилось на работе всех пользователей.
Клиент-серверные сети разделяются на двухзвенные, трёхзвенные и многозвенные в зависимости от используемых архитектур. Двухзвенные – клиент <-> сервер, который для ответа клиенту использует только свои ресурсы. Трёхзвенная – клиент <-> сервер <-> сервер БД (это пример!) и многозвенная архитектуры разбивают нагрузочную составляющую сервера на множество серверов, закрепляя за каждым из них определенную задачу.
20. Разработка пользовательского интерфейса (Евдошка)
21. ОС реального времени (Рома)
22. Классы задач исследования операций (свободен, = 87)
23. Создание форм и отчетов для баз данных (свободен)
24. Уровни и протоколы в сетях (Лиза, Дима Кипоров, =94)
25. Проектирование распределенной обработки данных (свободен)
26. Универсальные ОС и ОС особого назначения (Оля)
27. Детерминированные задачи исследования операций (свободен)
28. Физическая организация БД
Под физической организацией баз данных понимается совокупность методов и средств размещения данных во внешней памяти и созданная на их основе внутренняя (физическая) модель данных.
Физическая модель указывает, каким образом записи размещаются в базе данных, как они упорядочиваются, как организуются связи, каким путем можно найти записи и осуществить их выборку. Внутренняя модель разрабатывается средствами СУБД. Механизмы среды хранения БД служат для управления двумя группами ресурсов – ресурсами хранимых данных и ресурсами пространства памяти. В задачу этого механизма входит отображение структуры хранимых данных в пространство памяти, позволяющее эффективно использовать память и определить место размещения данных при запоминании и при поиске данных. В большинстве случаев в качестве единицы хранения принимается хранимая запись. Ресурсам пространства памяти соответствуют объекты внешней памяти ЭВМ, управляемые средствами операционной системы или СУБД. Для обеспечения естественной структуризации хранимых данных, более эффективного управления ресурсами и/или для технологического удобства всё пространство памяти БД разделяется на части (области, разделы и др.). Области памяти используются для размещения хранимых записей одного или нескольких типов и разбиваются на пронумерованные страницы фиксированного размера. В большинстве систем обработку данных на уровне страниц ведёт операционная система (ОС), а обработку записей внутри страницы обеспечивает только СУБД.
Страницы представляются в среде ОС блоками внешней памяти, кластерами или секторами, доступ к которым осуществляется за одно обращение. В системах, которые позволяют управлять размером страницы, приходится искать компромисс между производительностью системы и требуемым объёмом оперативной памяти. Страница имеет заголовок, содержащий служебную информацию, вслед за которым располагаются собственно данные. На странице размещается, как правило, несколько записей, и есть свободный участок для размещения новых записей. Если запись не помещается на одной странице, она разбивается на фрагменты, которые хранятся на разных страницах и имеют ссылки друг на друга.
Удаление записей может быть логическим или физическим. В первом случае запись помечается как удаленная, но фактически она остаётся на прежнем месте. Фактическое удаление этой записи будет произведено либо при реорганизации БД, либо специальной сервисной программой, инициируемой администратором БД. Единицей хранения данных в БД является хранимая запись. Она может представлять как полную запись концептуального уровня, так и некоторую её часть. Если запись разбивается на части, то её фрагменты представляются экземплярами хранимых записей каких-либо типов. Все части записи связываются указателями (ссылками) или размещаются по специальному закону так, чтобы механизмы междууровневого отображения могли опознать все компоненты и осуществить сборку полной записи концептуальной БД по запросу механизмов концептуального уровня.
Хранимые записи одного типа состоят из фиксированной совокупности полей и могут иметь формат фиксированной или переменной длины.
Записи переменной длины возникают, если допускается использование повторяющихся групп полей (агрегатов) с переменным числом повторов или полей переменной длины. Работа с хранимыми записями переменной длины существенно усложняет управление пространством памяти, но может быть продиктована желанием уменьшить объём требуемой памяти или характером модели данных концептуального уровня. В последнем случае для повышения производительности системы записи могут разбиваться на фрагменты фиксированной длины, возможно, различных типов.
Хранимая запись состоит из двух частей:
1. Служебная часть. Используется для идентификации записи, задания её типа, хранения признака логического удаления, для кодирования значений элементов записи, для установления структурных ассоциаций между записями. Никакие пользовательские программы не имеют доступа к служебной части хранимой записи.
2. Информационная часть. Содержит значения элементов данных.
Элементы хранимой записи могут иметь фиксированную или переменную длину. При этом обычно элементы фиксированной длины хранятся в начале записи и размещаются в памяти с заранее определённых позиций, а за ними размещаются элементы переменной длины. Хранение элементов переменной длины осуществляется одним из двух способов: размещение через разделитель или хранение размера элемента данных. Наличие полей переменной длины позволяет не хранить незначащие символы и тем существенно снижает затраты памяти на хранение данных; но при этом увеличивается время на извлечение элементов записи.Каждой записи БД система присваивает внутренний идентификатор, называемый (по стандарту CODASYL) ключом базы данных (КБД). Значение КБД формируется системой при размещении записи и содержит информацию, позволяющую однозначно определить место размещения записи (её адрес). В качестве КБД может выступать, например, последовательный номер записи в файле или совокупность адреса страницы и смещения от начала страницы. Виды адресации хранимых записей. Прямая адресация предусматривает указание непосредственного местоположения записи в пространстве памяти. Простейший вариант адресации используется в том случае, если в памяти хранится один вид записи фиксированной длины. Тогда в качестве адреса записи может использоваться её порядковый номер. Прямая адресация не позволяет перемещать записи в памяти без изменения ключа базы данных. Такие изменения привели бы к необходимости коррекции различных указателей на записи в среде хранения, что было бы чрезвычайно трудоемкой процедурой. В связи с отсутствием возможности перемещения при этом возникает явление фрагментации, т.е. появление разрозненных незаполненных участков памяти.
косвенную адресацию. Существует множество способов косвенной адресации. Один из них состоит в том, что часть адресного пространства страницы выделяется под индекс страницы. Число статей (слотов) в нем одинаково для всех страниц. Ключом БД по-прежнему служит номер этой записи в области. С помощью простых арифметических действий можно получить по номеру записи номер нужной страницы и номер требуемого слота в индексе этой страницы. Найденный слот укажет местоположение записи на этой странице, где N, n – это соответственно номер страницы памяти и номер слота на этой странице, в котором хранится адрес записи (смещение от начала страницы). При перемещении записи она остаётся на той же странице, и слот по-прежнему указывает на неё (меняется его содержимое, но не сам слот). Если запись не вмещается на страницу, она помещается на специально отведённые в данной области страницы переполнения, и соответствующий слот продолжает указывать место её размещения. Этот подход позволяет перемещать записи на странице, исключать фрагментацию, возвращать освободившееся пространство для повторного использования. При этом приложения БД остаются нечувствительными к таким операциям. Таким образом, косвенная адресация входит в группу методов, обеспечивающих физическую независимость данных. Также с адресацией связана другая функция среды хранения – поддержка связей между хранимыми записями. Для сетевой и иерархической моделей данных эти связи поддерживаются на физическом уровне. Способы представления связей определяются схемой хранения и чаще всего основаны на использовании указателей или на размещении данных в смежных областях памяти.
29. Эталонная модель взаимосвязи открытых систем (Нурсиня)
30. Логический анализ структур АСОИУ (свободен)
31. Классификация ОС
По признаку поддержки многозадачности различают однозадачные и многозадачные операционные системы.
По числу пользователей операционные системы делятся на однопользовательские и многопользовательские.
В зависимости от способа переключения с задачи на задачу различают системы с не вытесняющей многозадачностью и вытесняющей многозадачностью. Вытесняющая многозадачность предполагает использование прерываний от таймера как основной способ переключения задач.
Еще одним аспектом реализации многозадачности является использование концепции нитей (потоков) исполнения – многозадачности внутри одного процесса. Нити использовались в Windows.
Критерии эффективности системы пакетной обработки ориентированы на обеспечение максимальной пропускной способности, максимально полной загрузки вычислительной системы. Критерий характеризуется процентом загрузки центрального процессора; количеством заданий, выполняемых в единицу времени; оборотным временем (среднее время вычисления задачи). В таких системах выбор нового задания для выполнения определяется от текущей внутренней ситуации, складывающийся в системе. Время выполнения задачи зависит от того, какие задачи загружены одновременно с ней и как в них происходит ввод-вывод.
Система разделения времени устраняет данный недостаток пакетных систем. В таких системах распределение времени процессора организовано на основе квантования: периодического переключения управления между всеми одновременно запущенными задачами. С точки зрения задачи это создает иллюзию монопольного использования процессора (концепция терминала). Эффективность систем разделения времени определяется эргономическими показателями, связанными с субъективными ощущениями пользователя, как быстро система обрабатывает команды терминала. Системы разделения времени обладают меньшей пропускной способностью из-за того, что ресурсы процессора тратятся на постоянное переключение между задачами.
Реальное время в операционных системах — это способность операционной системы обеспечить требуемый уровень сервиса в определённый промежуток времени. Системы реального времени применяют для управления техническими объектами. В них существует предельно допустимое время, в течение которого должна быть выполнена программа управления объектом. Это время называется временем реакции, а свойство операционных систем оперативно реагировать на события – реактивностью. Различают системы
жёсткого реального времени — с режимом работы системы, при котором нарушение временных ограничений равнозначно отказу системы (RTLinux, AutomationRuntime, ART-Linux); системы мягкого реального времени — с режимом работы системы, при котором нарушения временных ограничений приводят к снижению качества работы (QNX, RT-11, WindowsCE).
По особенностям работы в сети операционные системы делятся на сетевые и распределенные. Сетевая операционная система – это обычная система, расширенная поддержкой сетевого взаимодействия. По методам реализации сетевых функций системы различаются по способам реализации справочной информации о сетевых ресурсах и адресации; механизмам обеспечения прозрачности доступа. (WindowsforWorkgroups 3.1) Распределённая операционная система, динамически и автоматически распределяя работы по различным машинам системы для обработки, заставляет набор сетевых машин обрабатывать информацию параллельно. Пользователь распределённой операционной системы не имеет сведений, на какой машине выполняется его работа. (Amoeba, Plan 9)
По аппаратным средствам, на которых функционируют операционные системы, их можно разделить на системы для мэйнфреймов (IBM System/360), миникомпьютеров (Unix), микрокомпьютеров (CP/M, MS DOS).
Архитектуры ОС: Монолитные система (Все части монолитного ядра работают в одном адресном пространстве), Клиент-серверная архитектура (предполагает наличие программного компонента потребителя сервиса, который называется клиентом, и программного компонента поставщика сервиса (сервера). Взаимодействие клиента и сервера стандартизировано. Инициатором обмена является клиент, который посылает запрос серверу, находящемуся в состоянии ожидания запроса), Объектно-ориентированные архитектуры операционных систем (Код ядра пишется на процедурном языке, а объекты моделируются средствами языка, например, Си).
32. Стохастические задачи исследования операций (свободен, =96)
33. Хеширование данных
Хеширование (или хэширование, англ. hashing ) – это преобразование входного массива данных определенного типа и произвольной длины в выходную битовую строку фиксированной длины. Такие преобразования также называются хеш-функциямиили функциями свертки, а их результаты называют хешем, хеш-кодом, хеш-таблицей или дайджестом сообщения (англ. message digest ).
Хеш-таблица – это структура данных, реализующая интерфейс ассоциативного массива, то есть она позволяет хранить пары вида "ключ- значение" и выполнять три операции: операцию добавления новой пары, операцию поиска и операцию удаления пары по ключу. Хеш-таблица является массивом, формируемым в определенном порядке хеш-функцией.
Принято считать, что хорошей, с точки зрения практического применения, является такая хеш-функция, которая удовлетворяет следующим условиям:
функция должна быть простой с вычислительной точки зрения;
функция должна распределять ключи в хеш-таблице наиболее равномерно;
функция не должна отображать какую-либо связь между значениями ключей в связь между значениями адресов;
функция должна минимизировать число коллизий – то есть ситуаций, когда разным ключам соответствует одно значение хеш-функции (ключи в этом случае называются синонимами ).
При этом первое свойство хорошей хеш-функции зависит от характеристик компьютера, а второе – от значений данных.
Если бы все данные были случайными, то хеш-функции были бы очень простые (например, несколько битов ключа). Однако на практике случайные данные встречаются достаточно редко, и приходится создавать функцию, которая зависела бы от всего ключа. Если хеш-функция распределяет совокупность возможных ключей равномерно по множеству индексов, то хеширование эффективно разбивает множество ключей. Наихудший случай – когда все ключи хешируются в один индекс.
При возникновении коллизий необходимо найти новое место для хранения ключей, претендующих на одну и ту же ячейку хеш-таблицы. Причем, если коллизии допускаются, то их количество необходимо минимизировать. В некоторых специальных случаях удается избежать коллизий вообще. Например, если все ключи элементов известны заранее (или очень редко меняются), то для них можно найти некоторую инъективную хеш-функцию, которая распределит их по ячейкам хеш-таблицы без коллизий. Хеш-таблицы, использующие подобные хеш-функции, не нуждаются в механизме разрешения коллизий, и называются хеш-таблицами с прямой адресацией.
Хеш-таблицы должны соответствовать следующим свойствам.
Выполнение операции в хеш-таблице начинается с вычисления хеш-функции от ключа. Получающееся хеш-значение является индексом в исходном массиве.
Количество хранимых элементов массива, деленное на число возможных значений хеш-функции, называется коэффициентом заполнения хеш-таблицы ( load factor ) и является важным параметром, от которого зависит среднее время выполнения операций.
Операции поиска, вставки и удаления должны выполняться в среднем за время O(1). Однако при такой оценке не учитываются возможные аппаратные затраты на перестройку индекса хеш-таблицы, связанную с увеличением значения размера массива и добавлением в хеш-таблицу новой пары.
Механизм разрешения коллизий является важной составляющей любой хеш-таблицы.
Хеширование полезно, когда широкий диапазон возможных значений должен быть сохранен в малом объеме памяти, и нужен способ быстрого, практически произвольного доступа. Хэш-таблицы часто применяются в базах данных, и, особенно, в языковых процессорах типа компиляторов и ассемблеров, где они повышают скорость обработки таблицы идентификаторов. В качестве использования хеширования в повседневной жизни можно привести примеры распределение книг в библиотеке по тематическим каталогам, упорядочивание в словарях по первым буквам слов, шифрование специальностей в вузах и т.д.
34. Аналоговые каналы передачи данных, способы модуляции, модемы
На вход аналогового канала поступает непрерывный сигнал, и с его выхода также снимается непрерывный сигнал. Наиболее распространенный тип аналоговых каналов – телефонные сети общего пользования. Полоса пропускания в них от 0,3 до 3,4 кГц, что соответствует спектру человеческой речи. Для передачи дискретной информации необходимо устройство преобразования сигналов, согласующее характеристики дискретных сигналов и аналоговой линии. Согласование параметров сигналов и среды при использовании АКПД осуществляется с помощью воплощения сигнала, определяющего передаваемое сообщение, в некотором процессе, называемом переносчиком и приспособленном к реализации в данной среде. Переносчик в системах связи – электромагнитные колебания некоторой частоты несущей:

Изменение параметров несущей по закону передаваемого сообщения называется модуляция. Если это изменение относится к амплитуде, то модуляция амплитудная, если к частоте, то частотная, если к фазе – фазовая.
При приеме сообщения предусматривается обратная процедура извлечения полезного сигнала из переносчика, называемая демодуляция. Модуляция и демодуляция реализуются в модеме. Модем – устройство преобразования кодов и представляющих их электрических сигналов при взаимодействии аппаратуры окончания канала данных и линий связи.
1) При амплитудной модуляции на входы модулятора поступают сигнал V и несущая U. Например, если сигнал есть гармоническое колебание V = Vm*sin(W *t+j) с амплитудой Vm, частотой W и фазой j , то на выходе нелинейного элемента в модуляторе будут модулированные колебания UАМ = Um*(1+m*sin(W *t+j))*sin(v *t+y), где m = Vm/Um - коэффициент модуляции. На выходе модулятора в спектре сигнала присутствуют несущая частота v и две боковые частоты v +W и v -W. Если сигнал занимает некоторую полосу частот, то в спектре модулированного колебания появятся две боковые полосы.
При амплитудной модуляции во избежание искажений, называемых качанием фронта, нужно выполнение условия v >> W, где v и W - соответственно несущая и модулирующая частоты.
2) В сравнительно простых модемах применяют частотную модуляцию со скоростями передачи до 1200 бит/с. Так, если необходима дуплексная связь по двухпроводной линии, то возможно представление 1 и 0 в вызывном модеме частотами 980 и 1180 Гц соответственно, а в ответном модеме - 1650 и 1850 Гц.
3) Фазовая модуляция двумя уровнями сигнала (1 и 0) осуществляется переключением между двумя несущими, сдвинутыми на полпериода друг относительно друга. Другой вариант изменение фазы на p/2 в каждом такте при передаче нуля и на 3/4*p , если передается единица.
4) Квадратурно-амплитудная модуляция основана на передаче одним элементом модулированного сигнала n бит информации, где n = 4...8 (т.е. используются 16... 256 дискретных значений амплитуды).
35. Анализ и оценка производительности АСОИУ (свободен)
36. Диспетчеризация и синхронизация процессов
При исполнении процесс может изменять свое состояние
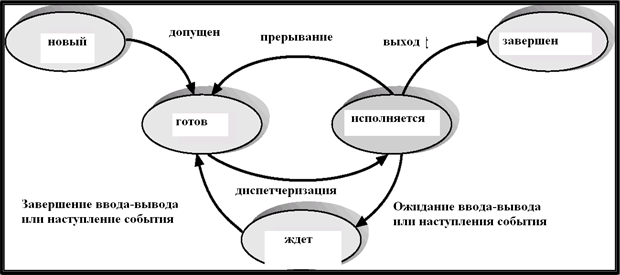
Новый процесс, созданный в системе, проходит стадию допущен (admitted) – включается операционной системой в очередь всех процессов в системе, после чего ОС переводит его в состояние готовности к выполнению. Из состояния готовности в состояние выполнения процесс переводится планировщиком ОС в результате диспетчеризации – выделения кванта процессорного времени. При выполнении процесс может быть прерван (по таймеру, в результате ошибки и т.п.), а после обработки прерывания операционной системой переходит снова в состояние готовности к выполнению.
Очереди, связанные с диспетчеризацией процессов
Очередь заданий (job queue) – cодержит множество всех процессов в системе. В нее попадает каждый новый процесс и остается в ней в течение всего пребывания в системе.
Очередь готовых процессов (ready queue) –содержащая множество всех процессов, находящихся в основной памяти и готовых к выполнению. В нее попадает каждый новый процесс, который система допускает к выполнению, а также каждый процесс после выполнения ввода-вывода или наступление ожидаемого события.
Очереди процессов, ожидающих ввода-вывода (device queues) – множества процессов, ожидающих результата работы устройств ввода-вывода (для каждого устройства организуется своя очередь).
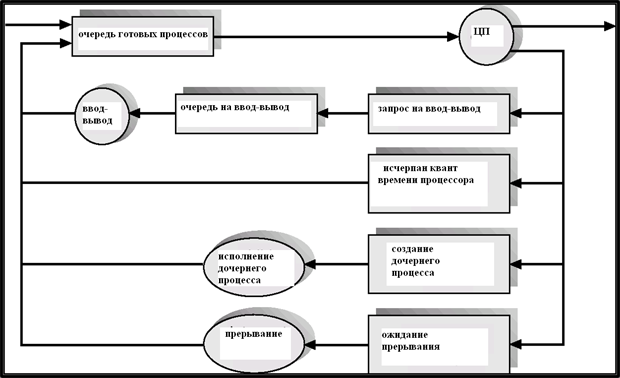
Управление процессами операционной системой и поведение процессов в системе можно рассматривать как миграцию между различными очередями.
Схема диспетчеризации процессов и работа с очередями представлена на рис.
Синхронизация процессов:
– это механизмы упорядочения работы взаимодействующих процессов (или потоков).
Примером задачи синхронизации является проблема потребителя – производителя с общим буфером, к которому каждый из процессов может параллельно обращаться во время работы. Такая ситуация называется конкуренцией за общие данные (race condition).Для предотвращения подобных ситуаций процессы следует синхронизировать.
Синхронизация процессов по критическим секциям заключается в том, чтобы обеспечить следующий режим выполнения: если один процесс вошел в свою критическую секцию, то до ее завершения никакой другой процесс не смог бы одновременно войти в свою критическую секцию.
Синхронизация на основе аппаратной поддержки атомарных операций
Такие операции позволяют выполнять блокировку входа в критическую секцию. Каждый процесс ждет, пока он не разблокируется, затем, в свою очередь, выполняет блокировку и входит в критическую секцию.
Кроме рассмотренных способов существует метод Синхронизации на основе общих семафоров ( Общий семафор (counting semaphore) - это целая переменная S, над которой определены две атомарных семафорных операции wait (S) и signal (S) )
37. Задачи в условиях неопределенности (свободен, =101)
38. Индексированные файлы
В БД. Индекс – структура данных, которая помогает СУБД быстрее обнаружить отдельные записи в файле и сократить время выполнения запросов пользователей. Структура индекса связана с определенным ключом поиска и содержит записи, состоящие из ключевого значения и адреса логической записи в файле, содержащей это ключевое значение. Файл, содержащий логические записи, называется файлом данных, а файл, содержащий индексные записи, - индексным файлом. Значения в индексном файле упорядочены по полю индексирования, которое обычно строится на базе одного атрибута.
Чтобы создать индексированный файл, записи сортируются по значениям их ключей, а затем распределяются по блокам в возрастающем порядке ключей. В каждый блок можно упаковать столько записей, сколько туда помещается. Однако в каждом блоке можно оставить место для дополнительных записей, которые могут вставляться туда впоследствии. Преимущество такого подхода заключается в том, что вероятность переполнения блока, куда вставляются новые записи, в этом случае оказывается ниже (иначе надо будет обращаться к смежным блокам). После распределения записей по блокам создается индексный файл: просматривается по очереди каждый блок и находится первый ключ в каждом блоке. Виды индексов:
Первичный индекс - это такой специальный массив-указатель порядка записей, когда файл данных последовательно упорядочивается по полю ключа упорядочения, а на основе поля ключа упорядочения создается поле индексации, которое гарантированно имеет уникальное значение в каждой записи.
Индекс кластеризации - это такой специальный массив-указатель порядка записей, когда файл данных последовательно упорядочивается по неключевому полю, и на основе этого неключевого поля формируется поле индексации, поэтому в файле может быть несколько записей, соответствующих значению этого поля индексации. Неключевое поле называется атрибутом кластеризации.
Вторичный индекс - это индекс, который определен на поле файла данных, отличном от поля, по которому выполняется упорядочение. Вторичный индекс также является упорядоченным файлом, аналогичным первичному индексу. Однако связанный с первичным индексом файл данных всегда отсортирован по ключу этого индекса, тогда как файл данных, связанный со вторичным индексом, не обязательно должен быть отсортирован по ключу индексации. Кроме того, ключ вторичного индекса может содержать повторяющиеся значения, что не допускается для значений ключа первичного индекса.
Отсортированный файл данных с первичным индексом называется индексированным последовательным файлом, или индексно-последовательным файлом. Эта структура является компромиссом между файлами с полностью последовательной и полностью произвольной организацией. В таком файле записи могут обрабатываться как последовательно, так и выборочно, с произвольным доступом, осуществляемым на основу поиска по заданному значению ключа с использованием индекса. Индексированный последовательный файл имеет более универсальную структуру, которая обычно включает следующие компоненты:
первичная область хранения;
отдельный индекс или несколько индексов;
область переполнения
При возрастании размера индексного файла и расширении его содержимого на большое количество страниц время поиска нужного индекса также значительно возрастает. Обратившись к многоуровневому индексу, можно попробовать решить эту проблему путем сокращения диапазона поиска. Данная операция выполняется над индексом аналогично тому, как это делается в случае файлов другого типа, т.е. посредством расщепления индекса на несколько субиндексов меньшего размера и создания индекса для этих субиндексов. На каждой странице файла данных могут храниться две записи. Кроме того, в качестве иллюстрации здесь показано, что на каждой странице индекса также хранятся две индексные записи, но на практике на каждой такой странице может храниться намного больше индексных записей. Каждая индексная запись содержит значение ключа доступа и адрес страницы. Хранимое значение ключа доступа является наибольшим на адресуемой странице.
Файл может иметь не больше одного первичного индекса или одного индекса кластеризации, но дополнительно к ним может иметь несколько вторичных индексов. Индекс может быть разреженным (sparse) или плотным (dense). Разреженный индекс содержит индексные записи только для некоторых значений ключа поиска в данном файле, а плотный индекс имеет индексные записи для всех значений ключа поиска в данном файле. Ключ поиска для индекса может состоять из нескольких полей.
В ОС.
Запись - это наименьший элемент данных, который может быть обработан как единое целое прикладной программой при обмене с внешним устройством.
Причем в большинстве ОС размер записи равен одному байту. В то время как приложения оперируют записями, физический обмен с устройством осуществляется большими единицами (обычно блоками). Поэтому записи объединяются в блоки для вывода и разблокируются - для ввода. Вопросы распределения блоков внешней памяти между файлами рассматриваются в следующей лекции.ОС поддерживают несколько вариантов структуризации файлов. Простейший вариант - так называемый последовательный файл. То есть файл является последовательностью записей. Поскольку записи, как правило, однобайтовые, файл представляет собой неструктурированную последовательность байтов.Обработка подобных файлов предполагает последовательное чтение записей от начала файла, причем конкретная запись определяется ее положением в файле. Такой способ доступа называется последовательным (модель ленты). В реальной практике файлы хранятся на устройствах прямого (random) доступа, например на дисках, поэтому содержимое файла может быть разбросано по разным блокам диска, которые можно считывать в произвольном порядке. Причем номер блока однозначно определяется позицией внутри файла. Файл, байты которого могут быть считаны в произвольном порядке, называется файлом прямого доступа.
Таким образом, файл, состоящий из однобайтовых записей на устройстве прямого доступа, - наиболее распространенный способ организации файла. Базовыми операциями для такого рода файловявляются считывание или запись символа в текущую позицию. В большинстве языков высокого уровня предусмотрены операторы посимвольной пересылки данных в файл или из него.
Подобную логическую структуру имеют файлы во многих файловых системах, например в файловых системах ОС Unix и MS-DOS. ОС не осуществляет никакой интерпретации содержимого файла. Эта схема обеспечивает максимальную гибкость и универсальность. С помощью базовых системных вызовов (или функций библиотеки ввода/вывода) пользователи могут как угодно структурировать файлы. В частности, многие СУБД хранят свои базы данных в обычных файлах.
Известны как другие формы организации файла, так и другие способы доступа к ним, которые использовались в ранних ОС, а также применяются сегодня в больших мэйнфреймах (mainframe), ориентированных на коммерческую обработку данных. Первый шаг в структурировании - хранение файла в виде последовательности записей фиксированной длины, каждая из которых имеет внутреннюю структуру. Операция чтения производится над записью, а операция записи переписывает или добавляет запись целиком. Другой способ представления файлов - последовательность записей переменной длины, каждая из которых содержит ключевое поле в фиксированной позиции внутри записи. Базисная операция в данном случае - считать запись с каким-либо значением ключа. Записи могут располагаться в файле последовательно (например, отсортированные по значению ключевого поля) или в более сложном порядке. Метод доступа по значению ключевого поля к записям последовательного файла называется индексно-последовательным. В некоторых системах ускорение доступа к файлу обеспечивается конструированием индекса файла. Индекс обычно хранится на том же устройстве, что и сам файл, и состоит из списка элементов, каждый из которых содержит идентификатор записи, за которым следует указание о местоположении данной записи. Для поиска записи вначале происходит обращение к индексу, где находится указатель на нужную запись.
Такие файлы называются индексированными, а метод доступа к ним - доступ с использованием индекса. В этом случае ОС использует древовидную организацию блоков, при которой блоки, составляющие файл, являются листьями дерева, а каждый внутренний узел содержит указатели на множество блоковфайла. Для больших файлов индекс может быть слишком велик. В этом случае создают индекс для индексного файла (блоки промежуточного уровня или блоки косвенной адресации).
39. Цифровые каналы передачи данных (Рома)
40. Управление проектом АСОИУ (свободен)
41. Понятия приоритета и очереди процессов (Мирош)
42. Задачи линейной оптимизации (Дима Кипоров, Ваня Семенов, =106)
43. Защита БД
Защита БД должна охватывать следующие моменты:
- используемое оборудование
- ПО
- персонал
- сами данные.
В многопользовательских вычислительных системах компьютерные средства контроля включают следующие моменты:
1. Авторизация пользователей.
2. Использование представлений.
3. Средства копирования и восстановления.
4. Шифрование.
5. Вспомогательные процедуры.
Авторизация пользователей заключается в предоставлении определенных прав, которые обеспечивают доступ к системе в целом, либо к ее отдельным объектам.
Аутентификация – механизм определений того, является ли пользователь тем, за кого се6я выдает.
Представление – это динамический результат выполнения одной или нескольких реляционных операций над базами отношения.
Резервное копирование – процесс периодического создания копий БД из файла журнала БД.
Средство поддержания целостности средства данных предназначены для исключения перехода данных в несогласованное состояние.
Шифрование данных – кодирование данных с помощью специальных алгоритмов, которые делают данные непригодными для чтения, если не известен ключ шифрования.
К основным средствам защиты относятся:
Защита паролем
Шифрование данных и программ
Разграничение прав доступа к обьектам баз данных
Защита полей и записей таблиц БД
Защита паролем это довольно простой и удобный метод защиты бд. Пароли и логины доступа хранятся в зашифрованном виде в системных файлах бд и так же являются бд.
Шифрование является более продвинутым способом защиты. Шифрование это преобразование информации, посредством алгоритма шифрования.
С целью контроля использования основных ресурсов БД во многих системах имеются средства установления прав доступа к объектам БД. Права доступа определяют возможные действия над объектом. Владелец объекта и администратор БД,имеют все права. Остальные пользователи могут иметь разные уровни доступа
Вот некоторые из них по отношению к таблицам:
Просмотр данных
Изменение данных
Добавление новых записей
Добавление или удаление данных
Изменение структуры таблицы
По отношению к полям относятся:
Полный запрет доступа
Только чтение
Полное разрешение всех операций
Защита отдельных полей таблицы(могут быть совсем скрыты от пользователя)
Дополнительные средства защиты БД:
Встроенные средства контроля значений данных в соответствии с типами
Повышение достоверности вводимых данных
Обеспечение целостности связей таблиц
Организации совместного использования объектов БД в сети
44. Разделение каналов по времени и частоте (Мирош)
45. Проектная документация АСОИУ (свободен)
46. Средства коммуникации процессов (свободен)
47. Задачи дискретной оптимизации (Юра, =111)
48. Целостность БД
Це́лостность ба́зы да́нных – соответствие имеющейся в базе данных информации её внутренней логике, структуре и всем явно заданным правилам.Каждое правило, налагающее некоторое ограничение на возможное состояние базы данных, называется ограничением целостности.
Целостность базы данных может быть нарушена вследствие сбоя оборудования, ошибки пользователя или программной ошибки. В системах со многими пользователями целостность может быть нарушена при одновременном обращении к одним и тем же фрагментам данных.
Целостность обеспечивается путем задания ограничений. В зависимости от источника можно выделить инструментальные ограничения, структурные ограничения и бизнес-правила .
К инструментальным ограничениям относят проверку правильности данных при вводе. Например, поле числа не может содержать текстовые символы, а поле даты должно содержать допустимое значение даты. Средства реализации инструментальных ограничений встроены в СУБД.
Структурные ограничения базируются на смысловых зависимостях между атрибутами отношений. Ссылочная целостность – это ограничение базы данных, гарантирующее, что ссылки между данными являются действительно правомерными и неповрежденными.
К структурным ограничениям относят также уникальность первичного ключа и уникальность возможных ключей. Бизнес-правила представляют собой условия того, что данные соответствуют предметной области. Бизнес-правила можно разделить на элементарные и расширенные. Элементарные правила ограничивают значения конкретного атрибута или агрегата атрибутов через ограничения домена. Расширенные правила выражаются в виде некоторой зависимости между атрибутами.
Ограничения могут быть статическими или динамическими. Статические ограничения должны выполняться для каждого состояния базы данных.Динамические ограничения проявляются при переходе базы данных из одного состояния в другое. Например, при повышении заработной платы служащего новое значение должно быть больше старого.
Ограничения могут найти свое выражение:
– при описании атрибутов отношений в концептуальной схеме;
– в запросе к базе данных;
– в процедуре базы данных ;
– в правиле (в триггере).
Процедуры базы данных создаются проектировщиком базы данных и дополняют СУБД. В различных СУБД они носят название хранимых,присоединенных, разделяемых и т. д. В системах с архитектурой "клиент-сервер" использование процедур баз данных позволяет значительно снизить трафик сети. Прикладная программа, вызывающая процедуру, передает серверу лишь ее имя и параметры.
Структурные ограничения реализуются процедурой нормализации, использующей функциональные зависимости, действующие между сущностями и атрибутами.
Правило (триггер) – программа для наблюдения за ситуацией, возникающей при изменениях в базе данных. Правило придается таблице базы данных и применяется при выполнении над ней операций включения, удаления или обновления строк, а также при изменении значений в столбцах таблицы. Применение правила заключается в проверке условия, при наступлении истинности которого вызывается указанная внутри правила процедура базы данных. Правила (так же, как и процедуры баз данных) хранятся независимо от прикладных программ.
ПРототипом правил послужили триггеры (triggers), которые впервые появились в СУБД Sybase и впоследствии были реализованы в том или ином виде и под тем или иным названием в большинстве многопользовательских СУБД.
Транзакция – неделимая с точки зрения воздействия на БД последовательность операторов манипулирования данными (чтения, удаления, вставки, модификации), такая, что: 1) либо результаты всех операторов, входящих в транзакцию, отображаются в БД; 2) либо воздействие всех операторов полностью отсутствует. При этом для поддержания ограничений целостности на уровне БД допускается их нарушение внутри транзакции так, чтобы к моменту завершения транзакции условия целостности были соблюдены. Для обеспечения контроля целостности каждая транзакция должна начинаться при целостном состоянии БД и должна сохранить это состояние целостным после своего завершения. Если операторы, объединенные в транзакцию, выполняются, то происходит нормальное завершение транзакции, и БД переходит в обновленное (целостное) состояние. Если же происходит сбой при выполнении транзакции, то происходит так называемый откат к исходному состоянию БД. Модели транзакций.: модель автоматического выполнения транзакций и модель управляемого выполнения транзакций, обе основаны на инструкциях языка SQL – COMMIT и ROLLBACK.
Автоматическое выполнение транзакций. В стандарте ANSI/ISO зафиксировано, что транзакция автоматически начинается с выполнения пользователем или программой первой инструкции SQL. Далее происходит последовательное выполнение инструкций до тех пор, пока транзакция не завершается одним из двух способов: • инструкцией COMMIT, которая выполняет завершение транзакции: изменения, внесенные в БД, становятся постоянными, а новая транзакция начинается сразу после инструкции COMMIT; • инструкцией ROLLBACK, которая отменяет выполнение текущей транзакции и возвращает БД к состоянию начала транзакции, новая транзакция начинается сразу после инструкции ROLLBACK. Такая модель создана на основе модели, принятой в СУБД DB2. Управляемое выполнение транзакций. Отличная от модели ANSI/ISO модель транзакций используется в СУБД Sybase, где применяется диалект Transact-SQL, в котором для обработки транзакций служат четыре инструкции: • инструкция BEGIN TRANSACTION сообщает о начале транзакции, т.е. начало транзакции задается явно; • инструкция COMMIT TRANSACTION сообщает об успешном выполнении транзакции, но при этом новая транзакция не начинается автоматически; • инструкция SAVE TRANSACTION позволяет создать внутри транзакции точку сохранения и присвоить сохраненному состоянию имя точки сохранения, указанное в инструкции; • инструкция ROLLBACK отменяет выполнение текущей транзакции и возвращает БД к состоянию, где была выполнена инструкция SAVE TRANSACTION (если в инструкции указана точка сохранения – ROLLBACK TO имя_точки_сохранения), или к состоянию начала транзакции.
49. Характеристики проводных линий связи (Ира)
50. Инструментальные средства проектирования АСОИУ
Инструментальные средства проектирования АСОИУ включают в себя различные программные системы автоматизации проектирования, поддерживающие создание и сопровождение АСОИУ на разных этапах проектирования и при разработке разного вида обеспечения (информационного, программного и других).
При разработке АСОИУ организационными объектами преимущественно используются так называемые CASE-средства (Computer Aided Software Engineering). Это программные средства, поддерживающие анализ и формулировку требований к системе, проектирование программного обеспечения и баз данных, тестирование, документирование и управление проектами. Большинство существующих CASE-средств применяют методологию структурного или объектно-ориентированного анализа и проектирования и представляют собой интегрированные системы из отдельных CASE- компонентов.
В качестве CASE-компонентов выступают:
– репозитарий (специальным образом организованное хранилище различных версий проектов);
– графические средства анализа и проектирования, обеспечивающие создание и редактирование иерархически взаимосвязанных диаграмм;
– средства разработки программ
– средства тестирования;
– средства документирования;
– средства управления проектом;
– средства интеграции с наиболее известными базами данных.
Примерами развитых CASE-систем могут служить система ERWIN, предназначенная для автоматизации проектирования баз данных и семейство объектно-ориентированных CASE-средств Rational Rose (RR), которые основаны на использовании языка моделирования UML. Система RR может генерировать коды разрабатываемых программ на языках С++, Small Talk, Java и ряде других. Кроме того, RR имеет средства для разработки проектной документации в виде диаграмм и спецификаций, а также имеет средства для реверсного инжиниринга программ. В состав RR входят следующие компоненты:
– репозитарий;
– графический интерфейс пользователя;
– средства просмотра проекта;
– средства контроля проекта;
– средства сбора статистики;
– средства генерации документации;
– средства генерации кода программ;
– анализатор, обеспечивающий реверсный инжиниринг (возможность повторного использования разработанных проектов и их компонентов).
Разработка баз данных в ERWIN состоит из двух этапов: этапа составления логической модели базы данных и этапа разработки на ее основе физической модели базы данных. Логическая модель означает прямое описание фактов проблемной области задач АСОИУ, то есть реальных объектов этой области и их связей. Объекты именуются на естественном языке, при этом не указываются типы данных (например, целое, вещественное и так далее) и не рассматривается использование конкретной СУБД. Конкретная СУБД, ее таблицы и типы данных составляют физическую модель. ERWIN поддерживает ряд СУБД, таких как Microsoft SQL, Oracle, Sybase, Microsoft Access, FoxPro, INFORMIX и многие другие.
При разработке АСОИУ технологическими процессами большую популярность приобрели системы сбора данных и диспетчерского управления (SCADA-системы), обеспечивающие сбор информации с удаленных объектов в реальном времени, анализ и обработку собранной информации и управление этими объектами. В SCADA-системах реализуются следующие принципы:
– работа в режиме реального времени;
– избыточность информации;
– сетевая архитектура открытых систем;
– модульность исполнения.
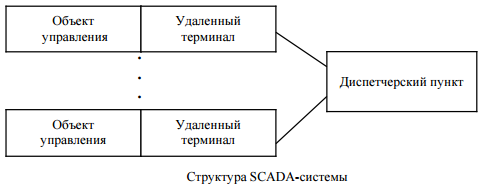
Современные SCADA-системы, и выполняют следующие функции:
прием информации о контролируемых параметрах управляемых объектов;
сохранение информации;
обработка принятой информации;
графическое представление хода технологического процесса;
прием и передача команд оператора;
регистрация событий;
оповещение персонала об аварийных ситуациях;
формирование сводок и других отчетов;
обмен информацией с автоматизированной системой управления предприятием.
51. Язык SQL (Нурсиня)
52. Многокритериальные задачи
- математическая модель принятия оптимального решения одновременно по нескольким критериям. Эти критерии могут отражать оценки различных качеств объекта(или процесса), по поводу к-рых принимается решение, или оценки одной и той же его характеристики, но с различных точек зрения. Теория М. з. относится к числу математич. методов исследования операций.
Формально
М. з. задается множеством X «допустимых
решений» и набором целевых функций
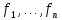 на
{X}, принимающих действительные значения.
Сущность М. з. состоит в нахождении
оптимального ее решения, т.е. такого
на
{X}, принимающих действительные значения.
Сущность М. з. состоит в нахождении
оптимального ее решения, т.е. такого
 , к-рое в том или ином смысле максимизирует
значения всех функций
, к-рое в том или ином смысле максимизирует
значения всех функций
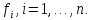 Существование решения, буквально
максимизирующего все целевые функции,
является редким исключением. Поэтому
в теории М. з. понятие оптимальности
получает различные и притом нетривиальные
истолкования. Содержание теории М. з.
состоит в выработке таких концепций
оптимальности, доказательстве их
реализуемости (т. е. существования
оптимальных в соответствующем смысле
решений) и нахождении этих реализаций
(т. е. в фактич. решении задачи).
Существование решения, буквально
максимизирующего все целевые функции,
является редким исключением. Поэтому
в теории М. з. понятие оптимальности
получает различные и притом нетривиальные
истолкования. Содержание теории М. з.
состоит в выработке таких концепций
оптимальности, доказательстве их
реализуемости (т. е. существования
оптимальных в соответствующем смысле
решений) и нахождении этих реализаций
(т. е. в фактич. решении задачи).
Наиболее
прямолинейным подходом к решению М. з.
является сведение ее к
обычной("однокритериальной") задаче
математнч. программирования путем
замены системы целевых функций
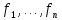 на одну "сводную" функцию
на одну "сводную" функцию
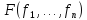 .
В ее роли могут выступать "взвешенные
суммы"
.
В ее роли могут выступать "взвешенные
суммы"
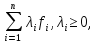 "взвешенные максимумы"
"взвешенные максимумы"
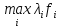 и др. "свертки" исходных целевых
функций. Такой подход концептуально и
технически представляется самым удобным.
Основным его недостатком является
трудно выполнимое требование содержательной
сопоставимости значений различных
целевых функций, а также неопределенность
(и нередко произвольность) в выборе
функции F и, в частности, "весов"
и др. "свертки" исходных целевых
функций. Такой подход концептуально и
технически представляется самым удобным.
Основным его недостатком является
трудно выполнимое требование содержательной
сопоставимости значений различных
целевых функций, а также неопределенность
(и нередко произвольность) в выборе
функции F и, в частности, "весов" .
Для их установления нередко рекомендуется
прибегать к экспертным оценкам.
.
Для их установления нередко рекомендуется
прибегать к экспертным оценкам.
Частный
случай описанного подхода состоит в
выделении "решающего критерия",
т. е. в том, чтобы все веса
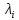 ,
за исключением нек-рого
,
за исключением нек-рого
 ,
полагать равными нулю. Тогда М. з. перейдет
в обычную задачу математич. программирования,
а множество ее оптимальных решений
можно рассматривать как множество
допустимых решений новой М. з. с целевыми
функциями
,
полагать равными нулю. Тогда М. з. перейдет
в обычную задачу математич. программирования,
а множество ее оптимальных решений
можно рассматривать как множество
допустимых решений новой М. з. с целевыми
функциями
 .
В качестве решений М. з. можно рассматривать
решения, оптимальные по Парето, т.е.
решения, не поддающиеся улучшению по
какому-либо критерию, иначе как за счет
ухудшения по другим критериям (иначе
говоря, такие
.
В качестве решений М. з. можно рассматривать
решения, оптимальные по Парето, т.е.
решения, не поддающиеся улучшению по
какому-либо критерию, иначе как за счет
ухудшения по другим критериям (иначе
говоря, такие
![]() ,
что для любого
,
что для любого
![]() из
из
![]() следует
следует
![]() при
нек-ром у). Недостатком этого подхода
является множественность оптимальных
по Парето решений. Этот недостаток
преодолевается предложенным Дж. Нашем
(J. Nash) методом "арбитражных решений",
существенно ограничивающим число
выбираемых решений среди оптимальных
по Парето содержательных соображений
нек-рых минимальных допустимых значений
при
нек-ром у). Недостатком этого подхода
является множественность оптимальных
по Парето решений. Этот недостаток
преодолевается предложенным Дж. Нашем
(J. Nash) методом "арбитражных решений",
существенно ограничивающим число
выбираемых решений среди оптимальных
по Парето содержательных соображений
нек-рых минимальных допустимых значений
![]() и
в последующем нахождении допустимого
х, максимизирующего
и
в последующем нахождении допустимого
х, максимизирующего
![]() М. з. можно
рассматривать как игру и подходить к
ее решению на основе различных
теоретико-игровых методов. Напр., если
допустимое решение х выбирается с целью
максимизировать одну из целевых функций
М. з. можно
рассматривать как игру и подходить к
ее решению на основе различных
теоретико-игровых методов. Напр., если
допустимое решение х выбирается с целью
максимизировать одну из целевых функций
![]() но
какую именно - для принимающего решение
субъекта неизвестно, то можно
воспользоваться взвешенной суммой этих
функций, взяв в качестве весов компоненты
смешанной стратегии "природы".
Возможны трактовки М. з. как бескоалиционной
игры, в том числе с позиций кооперативной
теории (см. Кооперативная игра),
и применения связанных с этим принципов
оптимальности.
но
какую именно - для принимающего решение
субъекта неизвестно, то можно
воспользоваться взвешенной суммой этих
функций, взяв в качестве весов компоненты
смешанной стратегии "природы".
Возможны трактовки М. з. как бескоалиционной
игры, в том числе с позиций кооперативной
теории (см. Кооперативная игра),
и применения связанных с этим принципов
оптимальности.
53. Иерархическая модель данных (Дамир)
54. Спутниковые каналы связи (свободен)
55. Типизация проектных решений АСОИУ (свободен)
56. Назначение и основные компоненты системы БД (Миша)
57. Принятие решений в условиях неопределенности (Катя, =121)
58. Сетевая модель данных (Нурсиня)
59. Сотовые системы связи
Сотовая связь – один из видов мобильной радиосвязи, в основе которого лежит сотовая сеть. Ключевая особенность заключается в том, что общая зона покрытия делится на ячейки (соты), определяющиеся зонами покрытия отдельных базовых станций. Соты частично перекрываются и вместе образуют сеть. Сеть составляют разнесённые в пространстве приёмопередатчики, работающие в одном и том же частотном диапазоне, и коммутирующее оборудование, позволяющее определять текущее местоположение подвижных абонентов и обеспечивать непрерывность связи при перемещении абонента из зоны действия одного приёмопередатчика в зону действия другого.
Основные составляющие сотовой сети – это сотовые телефоны и базовые станции, которые обычно располагают на крышах зданий и вышках. Будучи включённым, сотовый телефон прослушивает эфир, находит сигнал базовой станции. После этого телефон посылает станции свой уникальный идентификационный код. Телефон и станция поддерживают постоянный радиоконтакт, периодически обмениваясь пакетами. Связь телефона со станцией может идти по аналоговому протоколу (AMPS, NAMPS, NMT-450) или по цифровому (DAMPS, CDMA, GSM, UMTS). Если телефон выходит из поля действия базовой станции (или качество радиосигнала сервисной соты ухудшается), он налаживает связь с другой.
Основной элемент сотовой сети любого стандарта – это базовая станция, которая занимается приемом звонков абонентов и передачей данных по радиоканалу. В зависимости от стандарта связи, базовые станции работают в диапазоне частот от 450 до 2100 МГц. Поскольку радиус работы таких станций составляет порядка 10–12 км за городом и около 3–5 км в городе, их строят много и располагают относительно недалеко друг от друга. Тенденция использования широкополосных абонентских услуг (4G, потоковое видео) приводит к тому, что сотовым операторам необходимо увеличивать пропускную способность сети. Это достигается за счет модернизации оборудования (использование рабочей частоты 900/1800/2100 МГц) и увеличения числа базовых станций на ограниченной территории (при увеличении рабочей частоты снижается мощность передатчика, что ведет к уменьшению радиуса одной соты). Полностью автономные базовые станции представляют собой небольшие контейнеры. В обязательном порядке имеется беспроводной или кабельный канал связи с центром управления сетью, куда передается огромный поток данных – входящие и исходящие вызовы от абонентов. В городе базовые станции предпочитают устанавливать на уже существующие конструкции – в основном, на высотные здания. А на открытом пространстве используются антенно-мачтовые сооружения.
Приемопередающее оборудование располагается в шкафах или стойках. Здесь располагаются системные модули GSM (глобальный стандарт цифровой мобильной сотовой связи, с разделением каналов по времени и частоте.), CDMA (технология связи, при которой каналы передачи имеют общую полосу частот, но разную кодовую модуляцию) и LTE (стандарт беспроводной высокоскоростной передачи данных для мобильных телефонов и других терминалов, работающих с данными). Эти модули являются сердцем базовой станции, они принимают сигнал с антенн и осуществляют его преобразование и сжатие с дальнейшей пересылкой. Передача информации между системными модулями и приёмопередатчиками осуществляется через оптоволоконные кабели.
60. Графические средства представления проектных решений АСОИУ (свободен)
61. Обзор современных СУБД (Оля)
62. Основные понятия теории моделирования (свободен)
63. Реляционная модель данных (Оля)
64. Количество информации и энтропия, кодирование информации
Количественная мера информации необходима для сравнения различных источников сообщений и каналов связей.
При введении меры информации абстрагируемся от конкретного смысла информации.
При ожидании сообщения существует неизвестность или неопределенность относительно того, что содержится в ожидаемом сообщении. Это сообщение уничтожает эту неопределенность. Значит, чем больше ликвидируется неопределенности, тем большее количество информации несет сигнал.
![]() Неопределенность,
которая ликвидируется приходом такого
сигнала является единицей информации
и называется – 1 бит.
Неопределенность,
которая ликвидируется приходом такого
сигнала является единицей информации
и называется – 1 бит.
С помощью такой единицы находим количество информации в более сложных случаях. Сложную операцию выбора одного состояния из нескольких сводят к последовательности элементарных операций выбора между двумя равновероятностными возможностями.
Рассмотрим случай, если все состояния сигнала имеют равные вероятности появления. Укажем в таблице количество состояний и соответствующее количество элементарных операций выбора
|
Кол.сост. |
Кол.операций |
|
2 |
1 |
|
4 |
2 |
|
8 |
3 |
|
16 |
4 |
|
32 |
5 |
Легко заметить связь между значениями первого и второго столбцов. Обозначим через m – количество состояний сигнала, через I – количество элементарных операций выбора или количество информации. Тогда можно записать формулу :m = 2I. Выразим I через m, получим
![]() формулу
для вычисления количества информации,
если все состояния сигнала равновероятностны:
формулу
для вычисления количества информации,
если все состояния сигнала равновероятностны:
![]()
Вычислим по этой формуле количество информации для примеров 1 и 2, рассмотренных выше:
В первом примере:
![]()
Во втором примере :
![]()
На практике неопределенность зависит не только от числа состояний сигнала, но и от вероятности реализации сигнала. Рассмотрим простой пример: в шахматы играют чемпион мира с перворазрядником. Сообщение о том, что выиграл чемпион, несет мало информации, т.к. это ожидаемое сообщение, вероятность выигрыша чемпиона велика. А вот сообщение о победе перворазрядника уничтожило больше неопределенности, вероятность такого исхода мала. Этот пример иллюстрирует необходимость учета вероятности появления каждого из состояний сигнала.
Выведем формулу вычисления количества информации для такого случая.
Пусть А и В –события или состояния сигнала. Количество информации I(A/B) заключается в сообщении события В относительно наступления А и равно значению выражения
![]()
Числитель и знаменатель дроби – вероятности соответствующих событий.
Если появляется событие В=А, т.е. наступило А (значит А – достоверное событие), то I(A/B)= I(A/A)= I(A) – заключающееся в сообщении А. Учитывая, что А – достоверное событие, получим формулу для вычисления количества информации для сообщения А:
![]()
В дальнейшем основание логарифма указывать не будем.
![]() Полученная
формула
Полученная
формула
![]()
позволяет вычислить количество информации при получении сообщения (состояния), вероятность появления которого равна р.
Заметим, что для случая равновероятностных состояний можно пользоваться любой из этих двух формул.
3. Энтропия.
Энтропию (обозначение Нр), как меру неопределенности источника сообщений, осуществляющего выбор из m состояний , каждое из которых реализуется с вероятностью рi , предложил Клод Шеннон.
![]() Энтропия
вычисляется по формуле:
Энтропия
вычисляется по формуле:
![]()
-logpi – количество информации, которое несет i- тое состояние сигнала есть величина случайная. Тогда , энтропия – это математическое ожидание информации, которое несет сигнал с m состояниями, каждое из которых имеет вероятность появления рi .
Энтропия позволяет сравнивать количества информации, приносимые различными сигналами.
4. Кодирование информации.
Для передачи и хранения информации используется код. Код имеет алфавит- набор символов и правила, по которым с помощью данного кода передается информация.
Известная со школьной скамьи десятичная позиционная система счисления – это способ кодирования натуральных чисел, декартовы координаты – способ кодирования геометрических объектов числами.
Алфавит может содержать любое количество символов. Простейший код состоит из двух символов (двоичный). Именно его используют в ЭВМ: алфавит состоит из 0 и 1. Примерами таких кодов являются азбука Морзе (точка и тире), светофор на железной дороге.
В общем случае, как уже отмечалось, символов может быть любое количество. В русском алфавите 32 буквы, т.е. 32 символа. Если учесть знаки препинания и пробелы, то символов становится больше.
Но разные символы применяются не одинаково часто. Например, в алфавите русского языка наиболее часто в текстах используются буквы а, о, и; самые редкие щ, э, ф. Следовательно, вероятности появления различных символов - различные. Возникает задача : создать наиболее экономичный код, т.е. такой код, у которого энтропия была бы наибольшей, т.е. наименьшим количеством символов передавать наибольшее количество информации.
![]() Создавая
коды, учитывают следующее: наибольшая
энтропия соответствует сигналу ( в нашем
случае – коду), вероятности появления
состояний которого одинаковы; простейшим
является код из двух символов (
выбор одного из двух равновероятностных
состояний).
Создавая
коды, учитывают следующее: наибольшая
энтропия соответствует сигналу ( в нашем
случае – коду), вероятности появления
состояний которого одинаковы; простейшим
является код из двух символов (
выбор одного из двух равновероятностных
состояний).
Код имеет следующие характеристики:
![]() Экономичность-
это отношение энтропии кода к максимальной
энтропии в предположении, что все символы
имеют одинаковую вероятность: Э =Н /
Н мах ;
Экономичность-
это отношение энтропии кода к максимальной
энтропии в предположении, что все символы
имеют одинаковую вероятность: Э =Н /
Н мах ;
![]() Избыточность
кода : И = 1 - Э. Данная характеристика
показывает, какая часть символов лишняя
и не несет информации.
Избыточность
кода : И = 1 - Э. Данная характеристика
показывает, какая часть символов лишняя
и не несет информации.
Для оптимального кода экономичность близка к единице, а избыточность - к нулю.
![]() Кроме
экономичности и избыточности определяют
цену кода, равную среднему числу битов
на один символ (обозначение М(х)):
Кроме
экономичности и избыточности определяют
цену кода, равную среднему числу битов
на один символ (обозначение М(х)):
![]()
где pi – вероятность появления i- го символа в сообщении, si – длина кодовой последовательности, соответствующая i- му символу.
Рассмотрим примеры таких кодов.
![]() Код
Шеннона-Фэно.
Код
Шеннона-Фэно.
Алгоритм построения кода:
1. Все символы записать в порядке не возрастания вероятностей.
2. Символы разбить на две группы с приближенно равными суммами вероятностей.
3. В левой группе символов коды начать с 0, в правой-с1.
4. Каждую группу снова разбить на две по такому же принципу и так же присвоить слева-0, справа-1.
5. Продолжать разбиения до тех пор ,пока в каждой группе не останется по одному символу.
![]() Алгоритм
Хаффмена.
Алгоритм
Хаффмена.
1. Все символы записать в порядке не возрастания вероятностей.
2. Объединить два редких символа в одну группу с вероятностью, равной сумме вероятностей этих символов.
3. Снова упорядочить список.
4. Повторять операции со второго шага, пока все символы не будут разбиты на две группы. В левой группе символов коды начать с 0, в правой- с1.
5. Затем работать с каждой группой следующим образом: отделять крайние символы, присваивая всегда слева 0, а справа-1, пока не будет закодирован каждый символ.
65. Тенденции построения современных графических систем: графическое ядро, приложения, инструментарий для написания приложений (свободен)
66. Уровни представления данных (Нурсиня)
67. Средства моделирования и модели, применяемые в процессе проектирования АСОИУ (свободен)
68. Основные понятия исследования операций и системного анализа (=3)
69. Самосинхронизирующиеся коды (Мирош)
70. Стандарты в области разработки графических систем (свободен)
71. Понятия схемы и подсхемы данных (свободен)
72. Аналитическое моделирование (свободен)
73. Методологические основы теории принятия решений (=8)
74. Способы контроля правильности передачи информации (Лиза)
75. Технические средства компьютерной графики: мониторы, графические адаптеры, плоттеры, принтеры, сканеры
Мониторы.
Монитор (дисплей) является универсальным устройством вывода информации.
Классификация:
• ЭЛТ – на основе электронно-лучевой трубки (англ. cathode ray tube,
CRT);
• ЖК – жидкокристаллические мониторы (англ. liquid crystal display,
LCD);
• плазменный – на основе плазменной панели;
• проекционный – видеопроектор и экран, размещённые отдельно или объединённые в одном корпусе (как вариант – через зеркало или систему зеркал);
• OLED-монитор — на технологии OLED (англ. organic light-emitting diode – органический светоизлучающий диод);
• виртуальный ретинальный монитор – технология устройств вывода, формирующая изображение непосредственно на сетчатке глаза.
Основные параметры мониторов:
• вид экрана — квадратный или широкоформатный (прямоугольный);
• размер экрана — определяется длиной диагонали;
• разрешение — число пикселей по вертикали и горизонтали;
• глубина цвета — число отображаемых цветов (от монохромного до 32-битного);
• размер зерна или пикселя;
• частота обновления экрана;
• скорость отклика пикселей (не для всех типов мониторов).
Графические адаптеры.
Графический адаптер (видео карта) – устройство, преобразующее графический образ, хранящийся как содержимое памяти компьютера (или самого адаптера), в форму, пригодную для дальнейшего вывода на экран монитора.
Обычно видеокарта выполнена в виде печатной платы (плата расширения) и вставляется в разъём расширения, универсальный либо специализированный (AGP, PCI Express). Также широко распространены и встроенные (интегрированные) в системную плату видеокарты — как в виде отдельного чипа, так и в качестве составляющей части северного моста чипсета или ЦПУ; в этом случае устройство, строго говоря, не может быть названо видеокартой.
Видеокарта состоит из следующих частей: графический процессор, видеоконтроллер, видео-ПЗУ, видео-ОЗУ, ЦАП, коннектор и система охлаждения.
Плоттеры.
Графопостроитель, плоттер – устройство для автоматического вычерчивания с большой точностью рисунков, схем, сложных чертежей, карт и другой графической информации на бумаге размером до A0 или кальке.
Типы графопостроителей:
• рулонные и планшетные;
• перьевые, струйные и электростатические;
• векторные и растровые.
Назначение графопостроителей: высококачественное документирование чертёжно-графической информации.
Принтеры.
Принтер – устройство печати цифровой информации на твёрдый носитель, обычно на бумагу. Относится к терминальным устройствам компьютера. Процесс печати называется вывод на печать, а получившийся документ – распечатка или твёрдая копия.
Принтеры бывают струйные, лазерные, матричные и сублимационные; по цвету печати: чёрно-белые (монохромные) и цветные. Иногда из лазерных принтеров выделяют в отдельный вид светодиодные принтеры.
Сканеры.
Сканер – устройство, которое, анализируя какой-либо объект (обычно изображение, текст), создаёт цифровую копию изображения объекта. Процесс получения этой копии называется сканированием.
Сканеры бывают различных конструкций:
• ручной,
• планшетный,
• барабанный,
• проекционный.
Изображение всегда сканируется в формат RAW – а затем конвертируется в обычный графический формат с применением текущих настроек яркости, контрастности, и т. д. Эта конвертация осуществляется либо в самом сканере, либо в компьютере – в зависимости от модели конкретного сканера. На параметры и качество RAW-данных влияют такие аппаратные настройки сканера, как время экспозиции матрицы, уровни калибровки белого и чёрного, и т. п.
76. Классификация информационно-вычислительных сетей (=5)
77. Планирование имитационных экспериментов с моделями (Ира)
78. Задачи выбора решений (=13)
79. Способы конструирования и верификации программ (свободен)
80. Способы коммутации в сетях (Лиза)
81. Оценка точности и достоверности результатов моделирования (свободен)
82. Функции полезности и критерии при принятии решений (17 – первый вариант)
Полезность – некоторое число, приписываемое лицом, принимающим решение, каждому возможному исходу. Функция полезности Неймана-Моргенштерна для лица, принимающего решение, (ЛПР) показывает полезность, которую он приписывает каждому возможному исходу. У каждого ЛПР своя функция полезности, которая показывает его предпочтение тем или иным исходам в зависимости от его отношения к риску.
В Задачах Принятия Решений (ЗПР) значение функции полезности выражает предпочтения, полезность альтернатив. Она может быть оценена на множестве альтернатив и на множестве критериев, при этом критерии могут быть взаимно независимыми и зависимыми.
Решение задачи выбора оптимального действия полностью определяется двумя факторами: 1) типом и объемом информации о состояниях и 2) критерием оптимальности альтернативы. Собственно говоря, критерий оптимальности также зависит от имеющейся информации о состояниях. Поясним более детально, что подразумевается под понятием информации о состояниях Информация о состояниях отражает степень уверенности в том, какое состояние будет в действительности иметь место, или степень уверенности, что одно состояние более вероятно по сравнению с другим. В то же время, множество самих состояний является известным. Информация о состояниях существенно влияет на решение задачи. Так, например, если с уверенностью 100% известно, что будет иметь место быстрый подъем экономики, то очевидно, что покупка акций предприятия даст наибольший доход. Рассмотренная ситуация является наиболее простой и приводит к принятию решений в условиях полной определенности. Другим крайним случаем является отсутствие какой-либо информации о состояниях. В этой ситуации имеет место задача принятия решений в условиях неопределенности. Это редкий случай, так как обычно, исходя из предыдущего опыта или наблюдений, а также текущих тенденций, можно с некоторой вероятностью говорить о будущих состояниях.
Каждая задача принятия решений имеет свой критерий оптимальности, т.е. некоторое правило, по которому численно определяется условие предпочтения одного действия по отношению к другому. Критерий оптимальности определяет упорядочивание всех альтернатов (множества А) по предпочтению.
При этом, как уже было сказано, критерий оптимальности полностью зависит от информации о состояниях.
Принятие решений в условиях определенности характеризуется однозначной или детерминированной связью между принятым решением и его результатом. Это наиболее простой класс задач принятия решений, когда состояние, которое будет определённо иметь место, известно заранее, т.е. до выполнения действия. ЛПР в данном случае может всегда точно предсказать последствия от выбора каждого действия. Это фактически означает, что число состояний сводится к одному, т.е. m = 1.
Поэтому логично потребовать от рационального лица, принимающего решение, выбрать то действие, которое дает наибольшее значение функции полезности.
В условиях неопределенности лицо, принимающее решение, не может сказать что-либо о возможных состояниях, т.е. абсолютно неизвестно, какое из состояний будет иметь место. Для решения данной задачи наиболее распространенными критериями принятия решений являются:
1) критерий равновозможных состояний (критерий Лапласа):
2) критерий максимина Вачьда:
3) критерий пессимизма-оптимизма Гурвица;
4) критерий минимакса сожалений Сэвиджа.
Следует отметить, что приведенные критерии являются далеко не единственными для принятия решений в условиях неопределенности. Однако остальные критерии являются в основном комбинацией этих критериев.
83. Универсальные ОС и ОС специального назначения (=26, Оля)
84. Модульные программы, пример.
Модульное программирование основано на понятии модуля - логически взаимосвязанной совокупности функциональных элементов, оформленных в виде отдельных программных модулей/
Модуль характеризуют:
один вход и один выход - на входе программный модуль получает определенный набор исходных данных, выполняет содержательную обработку и возвращает один набор результатных данных, т.е. реализуется стандартный принцип IPO (Input - Process - Output) - вход-процесс-выход;
функциональная завершенность – модуль выполняет перечень регламентированных операций для реализации каждой отдельной функции в полном составе, достаточных для завершения начатой обработки;
логическая независимость - результат работы программного модуля зависит только от исходных данных, но не зависит от работы других модулей;
слабые информационные связи с другими программными модулями - обмен информацией между модулями должен быть по возможности минимизирован;
обозримый по размеру и сложности программный элемент.
Программная система обычно является большой, поэтому принимаются меры для ее упрощения. Для этого такую программу разрабатывают по частям, которые называются программными модулями. Программный модуль - это любой фрагмент описания процесса, оформляемый как самостоятельный программный продукт, пригодный для использования в описаниях процесса. Это означает, что каждый программный модуль программируется, компилируется и отлаживается отдельно от других модулей программы, и тем самым, физически разделен с другими модулями программы. Каждый разработанный программный модуль может включаться в состав разных программ, если выполнены условия его использования, декларированные в документации по этому модулю. Таким образом, программный модуль может рассматриваться и как средство борьбы со сложностью программ, и как средство борьбы с дублированием в программировании.
Модульная структура программных продуктов
Принципы модульного программирования программных продуктов во многом сходны с принципами нисходящего проектирования. Сначала определяются состав и подчиненность функций, а затем - набор программных модулей, реализующих эти функции.
Однотипные функции реализуются одними и теми же модулями. Функция верхнего уровня обеспечивается главным модулем; он управляет выполнением нижестоящих функций, которым соответствуют подчиненные модули.
При определении набора модулей, реализующих функции конкретного алгоритма, необходимо учитывать следующее:
каждый модуль вызывается на выполнение вышестоящим модулем и, закончив работу, возвращает управление вызвавшему его модулю;
принятие основных решений в алгоритме выносится на максимально "высокий" по иерархии уровень;
для использования одной и той же функции в разных местах алгоритма создается один модуль, который вызывается на выполнение по мере необходимости. В результате дальнейшей детализации алгоритма создается функционально-модульная схема (ФМС) алгоритма приложения, которая является основой для программирования.
Пример
Во входном файле приведены координаты точек на плоскости. Необходимо составить из этих точек три треугольника максимальной площади и вывести их в выходной файл.
Какие модули можно выделить в данной задаче?
Есть следующие группы задач:
ввод-вывод (модуль file)
геометрия (модуль geometry) (для рассчета расстояния между двумя точками и нахождения площади по трем координатам)
поиск треугольников наибольшей площади (модуль search)
85. Одноранговые сети
Однора́нговая, децентрализо́ванная или пи́ринговая (англ. peer-to-peer, P2P — равный к равному) сеть — это компьютерная сеть, основанная на равноправии участников. Часто в такой сети отсутствуют выделенные серверы, а каждый узел (peer) является как клиентом, так сервером. В отличие от архитектуры клиент-сервера, такая организация позволяет сохранять работоспособность сети при любом количестве и любом сочетании доступных узлов. В этом случае, операционная система, называемая одноранговой, не только позволяет обращаться к ресурсам других компьютеров, но и предоставляет собственные ресурсы в распоряжение пользователей других компьютеров. Например, если на всех компьютерах сети установлены и клиенты, и серверы файловой службы, то все пользователи сети могут совместно применять файлы друг друга. Компьютеры, совмещающие функции клиента и сервера, называют одноранговыми узлами.
Одноранговые сети называют также рабочими группами. Рабочая группа - это небольшой коллектив, поэтому в одноранговых сетях чаще всего не более 10 компьютеров. Одноранговые сети относительно просты. Поскольку каждый компьютер является одновременно и клиентом, и сервером, нет необходимости в мощном центральном сервере или в других компонентах, обязательных для более сложных сетей. Одноранговые сети обычно дешевле сетей на основе сервера, но требуют более мощных (и более дорогих) компьютеров.
Одноранговая сеть характеризуется рядом стандартных решений:
компьютеры расположены на рабочих столах пользователей;
пользователи сами выступают в роли администраторов и собственными силами обеспечивают защиту информации;
для объединения компьютеров в сеть применяется простая кабельная система.
Одноранговая сеть вполне подходит там, где:
количество пользователей не превышает нескольких человек;
пользователи расположены компактно;
вопросы защиты данных не критичны;
потоки данных невелики;
в обозримом будущем не ожидается значительного расширения конторы и, следовательно, сети
Элементарная защита подразумевает установку пароля на разделяемый ресурс, например на каталог. Централизованно управлять защитой в одноранговой сети очень сложно, так как каждый пользователь устанавливает ее самостоятельно, да и ``общие'' ресурсы могут находиться на всех компьютерах, а не только на центральном сервере. Такая ситуация представляет серьезную угрозу для всей сети, кроме того, некоторые пользователи могут вообще не установить защиту. Одноранговая сеть является крайне неуправляемой с точки зрения системного администратора, и чем больше участников сети, тем более этот факт заметен. Например, чтобы ограничить работу пользователя с теми или иными устройствами, потребуется выполнить определенные настройки операционной системы. Сделать это централизованно невозможно, поэтому требуется личное присутствие администратора возле каждого компьютера либо применение программ удаленного управления компьютером.
|
Преимущества сети |
Недостатки сети |
|
Простая и дешевая в создании |
Отсутствует возможность административного управления пользователями и ресурсами |
|
Не требует управляющих компьютеров |
Каждый пользователь должен самостоятельно следить за состоянием программного обеспечения |
|
Работа сети не зависит от работоспособности узлов сети |
За обновление баз данных и другого программного обеспечения отвечает пользователь |
|
легкость в установке и настройке |
Отсутствует централизованное хранилище ресурсов |
|
|
Низкий уровень защиты информации Возможность общего доступа не более 10 пользователям. |
86. Инструментальные средства и языки моделирования
ХУЙНЯ – комментарий Макса
Чтобы реализовать на ЭВМ модель сложной системы, нужен аппарат моделирования, который в принципе должен быть специализированным. Он должен предоставлять исследователю:
- удобные способы организации данных, обеспечивающие простое и эффективное моделирование;
- удобные средства формализации и воспроизведения динамических свойств моделируемой системы;
- возможность имитации стохастических систем, т.е. процедур генерации ПСЧ и вероятностного (статистического) анализа результатов моделирования;
- простые и удобные процедуры отладки и контроля программы;
- доступные процедуры восприятия и использования языка и др.
Классические языки моделирования являются процедурно-ориентированными и обладают рядом специфических черт. Можно сказать, что основные языки моделирования разработаны как средство программного обеспечения имитационного подхода к изучению сложных систем.
Языки моделирования позволяют описывать моделируемые системы в терминах, разработанных на базе основных понятий имитации. Различают языки моделирования непрерывных и дискретных процессов.
Непрерывное представление системы S сводится к составлению уравнений, с помощью которых устанавливается связь между эндогенными и экзогенными переменными модели. Примером такого непрерывного подхода является использование дифференциальных уравнений. Причем в дальнейшем дифференциальные уравнения могут быть применены для непосредственного получения характеристик системы, это, например, реализовано в языке MIMIC. А в том случае, когда экзогенные переменные модели принимают дискретные значения, уравнения являются разностными. Такой подход реализован, например, в языке DYNAMO.
Представление системы S в виде типовой схемы, в которой участвуют как непрерывные, так и дискретные величины, называется комбинированным. Примером языка, реализующего комбинированный подход, является GASP, построенный на базе языка FORTRAN. Язык GASP включает в себя набор программ, с помощью которых моделируемая система S представляется в следующем виде. Состояние модели системы M(S) описывается набором переменных, некоторые из которых меняются во времени непрерывно. Законы изменения непрерывных компонент заложены в структуру, объединяющую дифференциальные уравнения и условия относительно переменных.
В рамках дискретного подхода можно выделить несколько принципиально различных групп языков имитационного моделирования. Первая группа языков имитационного моделирования подразумевает наличие списка событий, отличающих моменты начала выполнения операций, Продвижение времени осуществляется по событиям, в моменты наступления которых производятся необходимые операции, включая операции пополнения списка событий. Примером языка событий является язык SIMSCRIPT. Разработчики языка SIMSCR1FJ исходили из того, что каждая модель Мм состоит из элементов, с которыми происходят события, представляющие собой последовательность предложений, изменяющих состояния моделируемой системы в различные моменты времени.
Язык программирования GPSS.
Язык GPSS представляет собой интерпретирующую языковую систему, применяющуюся для описания пространственного движения объектов. Такие динамические объекты в языке GPSS называются транзактами и представляют собой элементы потока. В процессе имитации транзакты «создаются» и «уничтожаются». Функцию каждого из них можно представить как движение через модель Мм с поочередным воздействием на ее блоки. Функциональный аппарат языка образуют блоки, описывающие логику модели, сообщая транзактам, куда двигаться и что делать дальше. Данные для ЭВМ подготавливаются в виде пакета управляющих и определяющих карт, который составляется по схеме модели, набранной из стандартных символов. Созданная GPSS-программа, работая в режиме интерпретации, генерирует и передает транзакты из блока в блок в соответствии с правилами, устанавливаемыми блоками. Каждый переход транзакта приписывается к определенному моменту системного времени.
Язык программирования SIMULA
Главная роль в языке SIMULA отводится понятию параллельного оперирования с процессами в системном времени, а также универсальной обработке списков с процессами в роли компонент. Специальные языковые средства предусмотрены для манипуляций с упорядоченными множествами процессов.
Основные свойства языков имитационного моделирования
Возможность моделирования стохастических факторов.
Управление модельным временем.
Возможность описания сложных динамических процессов, происходящих в реальной системе.
Наличие средств управления имитационным экспериментом.
Наличие средств для сбора статистики о характеристиках исследуемой системы с последующим статистическим анализом их значений.
Классификация языков имитационного моделирования
 ЯИМ
ЯИМ
Универсальные алгоритмические языки Проблемно-ориентированные языки
Специализированные языки
Моделирование Моделирование
непрерывных дискретных
 процессов процессов
процессов процессов
Dynamo-III
CSMP Схема Схема Схема
DIHYSYS событий активностей процессов
SIMSCRIPT-II CSL SIMULA
SLAM-II ESL ASPOL
GASP-V GPSS
Использование общеалгоритмических языков для программирования имитационных моделей возможно, но неэффективно, т.к. необходимо обеспечивать свойства, которые в языки имитационного моделирования уже встроены. Специализированные ЯИМ подразделяются на две самостоятельные группы, в соответствии с двумя независимыми видами имитации.
В языках моделирования непрерывных процессов для их описания используются дифференциальные уравнения. Изменение состояния системы описывается с помощью переменных состояний и выходных переменных, динамика изменения которых задается уравнениями уровней и скоростей соответственно. Переменные состояний (уровни) описывают состояние системы в данный момент времени. Уравнения скоростей описывают, как изменяется состояние системы за некоторый отрезок времени.
Языки моделирования дискретных процессов реализуют одну из трех основных схем функционирования дискретно-событийных мониторов.
В языках, ориентированных на схему активностей, реализована схема интеррогативного управления. Программа состоит из двух частей: проверка условий и выполнение активностей. Перед очередным сдвигом модельного времени проверяются все контролирующие условия. В зависимости от того, какие из них выполняются, происходит исполнение команд изменения состояния, связанных с выполнением определенной активности, и сдвиг модельного времени.
В языках, ориентированных на схему событий, реализовано императивное управление. Каждое событие происходит мгновенно в модельном времени в тот момент, когда динамическое состояние модели показывает, что сложились условия для его наступления.
В основе языков, ориентированных на процессы, лежит понятие процесса как совокупности событий, описывающих поведение системы. Написанная на таком языке программа работает так же, как несколько программ, управляемых независимо одна от другой, либо посредством просмотра активностей, либо посредством регламентирования событий. Особенностью программирования по схеме процессов является использование точек реактивации и механизмов синхронизации. Частным случаем схемы процессов является схема транзактов.
При выборе того или иного из специализированных языков моделирования необходимо произвести их сравнение с позиций эффективности реализации, возможности разрешения динамических коллизий (синхронизация, временные узлы), адекватности декомпозиции предметной области.
В настоящее время существует несколько десятков специализированных систем имитационного моделирования и их число растет.
87. Классы задач исследования операций (свободен, =22)
88. Классификация ОС (=31)
89. Линейные списки и способы их реализации, пример программы (Рома)
90. Анализ и интерпретация результатов моделирования на ЭВМ (свободен)
91. Детерминированные задачи исследования операций (свободен, =27)
92. Модульная
структура построения ОС и их переносимость

93. Общие принципы системной организации в системах управления (свободен)
94. Уровни и протоколы в сетях Лиза, Дима Кипоров, =24)
95. Имитационные модели систем (Ира)
96. Стохастические задачи исследования операций (свободен, =32)
97. Управление памятью (ниже)



98. Устойчивость систем управления (Дима Кипоров)
99. Эталонная модель взаимосвязи открытых систем (Нурсиня, =29)
100. Концептуальные модели систем
Концептуальная модель описывается с помощью специальных символов, знаков, операций над ними или с помощью естественного или искусственного языков.
1) Модель "Черный ящик"
Одной из первых и самых простых концептуальных моделей системы стал так называемый "Черный ящик". Он представляет собой часть окружающей среды, выделенной с определенной целью. При этом внутреннее устройство "ящика" считается неизвестным, поэтому он и называется "черным". В этой самой простой модели отражаются следующие важные свойства системы: целостность, обособленность от среды и вместе с тем связь с ней. Графически система представляется как "Черный ящик" следующим образом:

Воздействие внешней среды на систему выражается в виде "входов", а системы на среду в виде - "выходов". Входы-выходы могут выражаться как словесно, так и формально.
2) Модель состава системы.
Модель состава системы представляется как множество элементов, некоторые из которых объединены в более крупные части системы - подсистемы. Графически модель состава может быть представлена следующим образом:
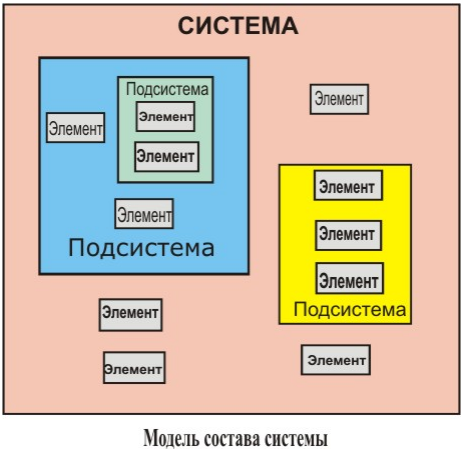
3) Модель структуры системы.
Совокупность необходимых и достаточных для достижения цели отношений между элементами называется структурой системы. Перечень связей между элементами является абстрактной моделью структуры. В любой системе существует практически бесконечное число отношений между элементами. Но обычно выделяется конечное число отношений наиболее важных с точки зрения достижения цели. В качестве основного языка описания используется теоретико-множественный язык:

В наиболее общем виде модели системы с акцентом на её структуру представляются в виде матриц и графов. Граф состоит из вершин, обозначающих элементы любой природы, и ребер, обозначающих связи между элементами. Если связи симметричны, то ребра графа неориентированные, если асимметричны - ориентированные. Графы могут изображать любые структуры. Пример моделей структуры системы представлен на рисунке:
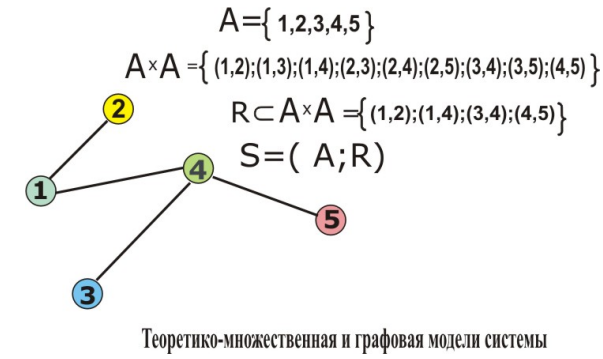
4) Модель динамики системы.
Системы, в которых происходят изменения со временем, называются динамичными, а модели, отображающие эти изменения динамическими моделями. Уже на этапе представления системы в виде "Черного ящика" различают два типа динамики функционирование и развитие. Под функционированием подразумевают процессы, которые происходят в системе (окружающей среде), стабильно реализующей фиксированную цель. Развитием называют то, что происходит с системой при изменении ее целей. Т.е. характерной чертой развития является необходимость изменения структуры системы. Все выше рассмотренные модели могут иметь динамическое представление.
Динамическая система без памяти

Входы и выходы системы есть функции времени. При этом выход системы Y(t) - есть реакция на вход X(t). Тогда если модель динамики системы может быть представлена следующим образом: Y(t) = F(X(t)).
В этом случае имеем динамическую систему без памяти, то есть выход в определенный момент времени зависит только от входа в тот же момент времени. Если оператор F неизвестен, то имеем "черный ящик", если известен, то имеем "белый ящик". Одной из важнейших задач исследования является восстановление функции F только по наблюдению входа и соответствующих выходов.
Динамическая система с памятью
В общем случае выход системы определяется не только значением входа в данный момент времени, но и теми значениями, которые были на входе в предыдущие моменты, то есть система обладает "памятью". Для обобщения модели вводится понятие состояние системы как некоторой (внутренней) характеристики, значение которой в настоящий момент времени определяет текущее значение выходной величины. Состояние можно рассматривать как своего рода хранилище информации, необходимое для предсказания влияния настоящего на будущее. Динамическую систему с памятью можно представить следующим образом:
