

Лексичний аналізатор
Діаграма станів показує, як ведеться розбір лексеми. На вхід діаграми надходить вхідна послідовність символів, на виході видається код лексеми, після чого діаграма переходить до початкового стану. Дуги діаграми позначені символами, під впливом яких здійснюється перехід від одного стану до іншого,
або підтверджується даний стан. Якщо дуга не позначена, то вона відповідає всім символам, які не збігаються із вказаними а інших дугах, що виходять із даного стану [2].
Для реалізації лексичного аналізатора за допомогою діаграми станів потрібні вхідні символи які приведені в таблиці нижче (таблиця 2.1):
Таблиця 2.1. Таблиця лексем мови програмування
|
Лексема |
Код лексеми |
Лексема |
Код лексеми |
|
program |
1 |
/ |
19 |
|
var |
2 |
( |
20 |
|
begin |
3 |
) |
21 |
|
end |
4 |
< |
22 |
|
float |
5 |
> |
23 |
|
dowhile |
6 |
<= |
24 |
|
enddo |
7 |
>= |
25 |
|
if |
8 |
== |
26 |
|
else |
9 |
<> |
27 |
|
endif |
10 |
[ |
28 |
|
input |
11 |
] |
29 |
|
output |
12 |
or |
30 |
|
: |
13 |
and |
31 |
|
, |
14 |
not |
32 |
|
= |
15 |
idn |
33 |
|
+ |
16 |
con |
34 |
|
- |
17 |
˩ |
35 |
|
* |
18 |
|
|
Перетворимо нашу таблицю лексем в таблицю класів символів. Після перетворення таблиця буде мати вигляд (таблиця 2.2):
Таблиця 2.2. Класи символів
|
Символ |
Клас |
|
a-z |
Б |
|
0-9 |
Ц |
|
() [] , : + - / * |
ОРО |
Продовження таблиці 2.2.
|
= |
= |
|
> |
> |
|
< |
< |
|
. |
. |
Побудуємо діаграму станів (рисунок 2.2).
j<>0-> lex = j

1
2
Б


j=0->lex = id
Ц
3
lex = const


.
.
4
Ц
5
lex
= const




error
=
>
lex = <>
lex
= <=

<
6
lex = <
>
7
lex
= >
=
lex
= >=


=
8
lex
= =
=
lex
= ==


ОР
lex
= j
error
Рисунок 2.2 – Діаграма станів
Результат роботи лексичного аналізатора
Для перевірки роботи лексичного аналізатора використаємо приклад тестової програми приведеної вище (рисунок 2.3).

Рисунок 2.3 – Приклад тестової програми
В результаті роботи лексичного аналізатора отримано таблицю лексем, ідентифікаторів та констант (рисунок 2.4).
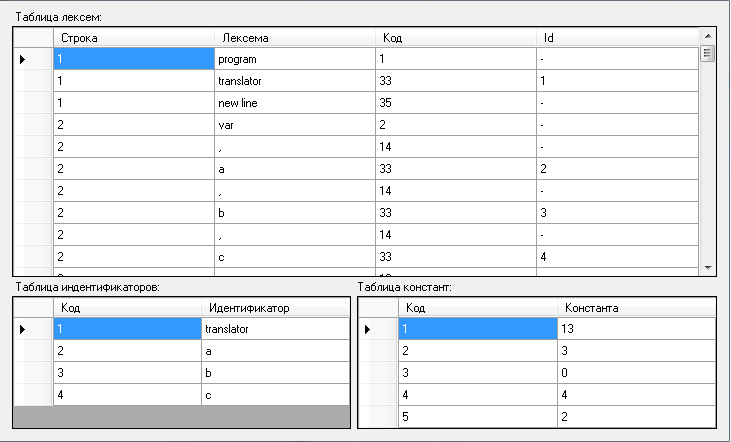
Рисунок 2.4 – Таблиця лексем
Якщо у ході виконання роботи є помилки, то вони будуть виведені у відповідне вікно програми (рисунок 2.5).

Рисунок 2.5 – Приклад роботи програми з помилками
Розроблений лексичний аналізатор здатний виділяти лексеми, ідентифікатори та константи та знаходити зроблені в програмі помилки.
Синтаксичний аналізатор
Задача синтаксичного аналізу – виділення в початковому тексті програми конструкцій мови, що описуються граматикою та перевірка правильності їх слідування (тобто перевірка вхідного тексту програми на відповідність граматиці мови).
На відміну від лексичного аналізатора, який на вході приймає текст, синтаксичний аналізатор працює з вихідною таблицею лексичного, тобто з набором лексем вхідної програми.
Для реалізації алгоритму введемо відношення “<”, “>” та “=” для лексем граматики наступним чином:
якщо символи R та S знаходяться один за одним ( … R S …), тобто існує правило U ::= … R S …, то між ними встановлюється відношення “=” (R = S);
якщо символи R та S знаходяться один за одним ( … R S …), і при цьому символ R є останнім символом основи, тобто існує правило U ::= … R, то між ними встановлюється відношення “>” (R > S);
якщо символи R та S знаходяться один за одним ( … R S …), і при цьому символ S є першим символом основи, тобто існує правило U ::= S …, то між ними встановлюється відношення “<” (R < S).
Таким чином для граматики мови можна побудувати таблицю відношень, що в подальшому буде використовуватись для синтаксичного аналізу вхідного тексту.
Для побудови таблиці відношень введемо 2 множини: first+та last+.
Визначимо множину first+наступним чином: S належить до first+(U), якщо існують правила наступного виду:
U ::= S1 …
S1 ::= S2 …
… … …
Sn ::= S …
Визначимо множину last+наступним чином: S належить до last+(U), якщо існують правила наступного виду:
U ::= … S1
S1 ::= … S2
… … …
Sn ::= … S
Розглянемо алгоритм побудови таблиці.
Проставляємо відношення “=” згідно правилу: R = S якщо U ::= … R S … . Тобто проставляємо відношення “=” між символами граматики, що належать одному й тому самому правилу і знаходяться поруч.
Проставляємо відношення “>” згідно правилу: R < S якщо U ::= … VS … (R належить множині last +(V)) або якщо U ::= … VW … (R належить множині last +(V), а S належить множині first+(W)). Тобто знаходимо відношення “=”, в яких перший символ не термінальний. Потім, якщо другий символ термінальний, то будується множина last+(V) і проставляються відношення “>” між символами множини last+(V) і символом S. Якщо ж другий символ не термінальний, то необхідно побудувати дві множини last+(V) і first+(W) та проставити відношення “>”.
Проставляємо відношення “<” згідно правилу: R < S якщо U ::= … RV … (S належить множині last+(V)). Тобто знаходимо усі рівності, в яких другий символ не термінальний, будуємо множину first+(V) і між символом R та всіма символами множини first+(V) проставляємо відношення “<”.
Синтаксичний розбір виконується наступним чином. Для розбору використовується стек. В початковому стані в стек заносить “#” і вхідний набір символів також закінчується символом “#”. Спочатку визначається відношення між символом на вершині стеку та поточним символом. Якщо це відношення “=” або “<”, то символ із вхідного ланцюжка переноситься в стек. Таким чином символи вхідного ланцюжка розглядаються зліва направо і заносяться до стеку до тих пір, доки не виявиться, що верхній символ стеку знаходиться у відношенні “>” до наступного вхідного символу. Це означає, що верхній символ стеку є хвостом основи, а вся основа вже знаходиться в стеку. Тоді стек проглядається вглиб в пошуках голови основи, тобто першої пари символів, між якими встановлено відношення “<”. Підланцюг, що знаходиться в стеку між знаками відношень “<” та “>” і буде основою. Отриману основу необхідно знайти в списку правил граматики, а в стеку вона замінюється тим не терміналом, до якого вона зводиться. Процес повторюється до тих пір, поки в стеку не опиниться символ, що відповідає аксіомі, а наступним вхідним символом не стане “#”.
При побудові таблиці відношень можуть виникнути конфлікти (тобто в одну комірку таблиці будуть записані 2 і більше знаки відношення), якщо граматика містить ліворекурсивні або праворекурсивні правила.
Якщо граматика містить лівосторонню рекурсію, тобто
V::= …SU…
U::=U… .
Тоді згідно правил побудови таблиці відношень S=U.U– нетермінал, томуS<first+(U), тобтоS<U. Такий конфлікт можна вирішити наступним чином:
V::= …SU1 …
U1 ::=U…
U::=U…
Отримаємо S=U1.U1 – нетермінал,S<first+(U1),S<U.
Це називається стратифікацією граматики.
При правосторонній рекурсії аналогічна ситуація виникає зі знаками “=” та “>”.
Якщо одночасно виникає відношення “<” і “>”, то таким чином конфлікт вирішити неможливо. Треба змінювати граматику.
Перетворена граматика має вигляд.
< Програма > ::= program id Var < Список объявлений 1 > begin < Enter > < Список операторов 1 > end
< Enter > ::= enter
< Список объявлений 1 > ::= < Список объявлений >
< Список объявлений > ::= < Объявление > enter
< Список объявлений > ::= < Список объявлений > < Объявление > enter
< Объявление > ::= < Список идентификаторов 1 > : float
< Список идентификаторов 1 > ::= < Список идентификаторов >
< Список идентификаторов > ::= , id
< Список идентификаторов > ::= < Список идентификаторов > , id
< Список операторов 1 > ::= < Список операторов >
< Список операторов > ::= < Список операторов > < Оператор 1 > enter
< Список операторов > ::= < Оператор 1 > enter
< Оператор 1 > ::= < Оператор >
< Оператор > ::= id := < Выражение 1 >
< Оператор > ::= input< Список идентификаторов 1 >
< Оператор > ::= output< Список идентификаторов 1 >
< Оператор > ::= if < ЛВ1 > < Enter > < Список операторов 1 > else < Enter > < Список операторов 1 > endif
< Оператор > ::= dowhile < ЛВ1 > < Enter > < Список операторов 1 > enddo
< ЛВ1 > ::= < ЛВ >
< ЛВ > ::= < ЛТ1 >
< ЛВ > ::= < ЛВ > or < ЛТ1 >
< ЛТ1 > ::= < ЛТ >
< ЛТ > ::= < ЛМ1 >
< ЛТ > ::= < ЛТ > and < ЛМ1 >
< ЛМ1 > ::= < ЛМ >
< ЛМ > ::= < Выражение 1 > < Знак отношения > < Выражение 1 >
< ЛМ > ::= [ < ЛВ1 > ]
< ЛМ > ::= not < ЛM1 >
< Знак отношения > ::= >
< Знак отношения > ::= <
< Знак отношения > ::= ==
< Знак отношения > ::= <>
< Знак отношения > ::= >=
< Знак отношения > ::= <=
< Выражение 1 > ::= < Выражение >
< Выражение > ::= < Терм 1 >
< Выражение > ::= < Выражение > + < Терм 1 >
< Выражение > ::= < Выражение > - < Терм 1 >
< Терм 1 > ::= < Терм >
< Терм > ::= < Множитель 1 >
< Терм > ::= < Терм > * < Множитель 1 >
< Терм > ::= < Терм > / < Множитель 1 >
< Множитель 1 > ::= < Множитель >
< Множитель > ::= id
< Множитель > ::= const
< Множитель > ::= ( < Выражение1 > )