

Эволюция баз данных
.pdfдится хоть один возражающий участник процесса, то транзакция отменяется.
Итак, в случае невыполнения транзакции объекты базы данных, затрагиваемые данной транзакцией, должны быть возвращены в свое исходное состояние. Это действие называется откатом30 . Существуют две схемы отката. В простой модели транзакции, известной также как модель транзакций ANSI/ISO, откат осуществляется к исходному состоянию, которое было до начала транзакции.
В более поздней, расширенной модели транзакций в теле транзак-
ции может определяться несколько промежуточных точек сохранения, и откат может выполняться к любой из них (рис. 33). Для обеспечения восстановления необходимого состояния ведется журнал транзакций, где отображаются все изменения базы данных.
Проблемы параллельного доступа
Из приведенных выше примеров ясно, что наиболее сложный механизм управления транзакциями применяется при многопользовательском режиме доступа к данным, когда СУБД вынуждена параллельно выполнять транзакции нескольких пользователей. Особенностью многопользовательского режима является то, что транзакции разных пользователей должны обрабатываться последовательно, но при этом у каждого пользователя должно быть ощущение, что с базой данных работает только он один. Для иллюстрации возможных проблем вернемся к примеру, когда два пользователя покупают по два билета на рейс с тремя свободными местами. Возможны следующие стратегии работы и проблемы.
1. Клиентские приложения обоих пользователей одновременно получают исходное состояние базы данных – три свободных места (рис. 34). Первый пользователь покупает два билета, его приложение уменьшает число свободных мест до одного и записывает это значение в базу данных. У второго пользователя происходит то же самое – его приложение вычитает из трех мест два и записывает в базу данных единицу, игнорируя обновление, уже сделанное первой транзакцией. Такая ситуация называется потерянным обновлением (lost update) (или пропавшим изменением).
30В SQL фиксация результатов транзакции осуществляется оператором
COMMIT, откат – оператором ROLLBACK.
71
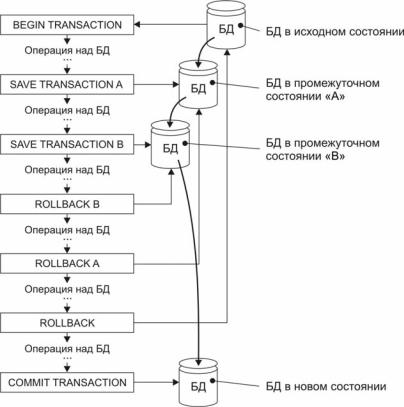
Рис. 33. Расширенная модель транзакции (более детально алгоритм представлен в [3])
2. Как только первый пользователь зарезервировал два билета, число свободных мест уменьшается на два и в базу данных записывается промежуточное значение – одно свободное место (рис. 35). По каким-то причинам в процессе оплаты первый пользователь отказывается от покупки. Одновременно с этим второй пользователь запрашивает свободные места и получает одно место. Тем временем происходит откат первой транзакции, и в базу данных возвращается исходное значение – три свободных места. В итоге второй пользователь имеет недостоверную информацию. Данная проблема называется проблемой недостоверного чтения (dirty read) или проблемой промежуточных данных.
72
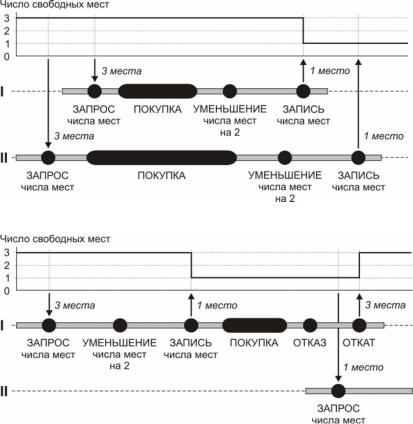
Рис. 34. Проблема потерянных обновлений
Рис. 35. Проблема недостоверного чтения
3.Оба пользователя одновременно получают информацию о трех свободных местах (рис. 36). Первый пользователь совершает покупку двух мест и его приложение завершает транзакцию, несмотря на то, что с этими данными работает второе приложение. Тем временем второй пользователь решил обновить запрос и получил в ответ совершенно иной результат – одно место. Данная про-
блема называется проблемой отсутствия повторяемости чтения
(non-repeatable read).
4.Для иллюстрации четвертой проблемы рассмотрим два способа определения числа свободных мест в самолете. Предположим, что данные хранятся в двух таблицах. В первой (табл. 26) перечис-
73
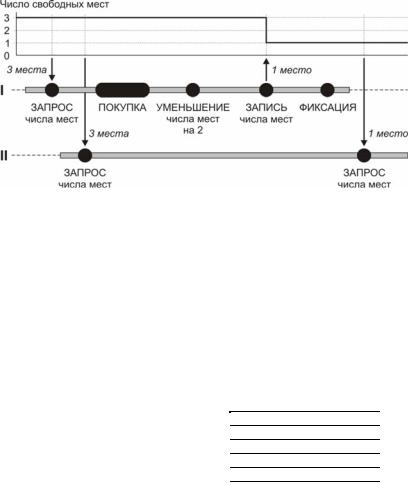
Рис. 36. Проблема отсутствия повторяемости чтения
лены все рейсы авиакомпании, выполняемые на протяжение некоторого периода, например, одного года. Во второй таблице (табл. 27) хранятся все купленные билеты. Число свободных мест можно получить двумя способами:
1)выбрать из таблицы БИЛЕТ все билеты на интересующий рейс, посчитать количество выбранных записей и вычесть сумму из числа мест в самолете;
2)ввести в таблице РЕЙС дополнительную колонку «Число свободных мест», отражающую текущее состояние таблицы БИЛЕТ.
|
|
|
|
Отношение РЕЙС |
|
Таблица 26 |
|||
|
|
|
|
|
|
|
|
||
|
|
|
|
|
Число свободных мест |
|
|
||
Номер |
|
Дата |
|
Число мест |
|
|
|||
КA 683 |
|
12.08.2011 |
|
152 |
|
3 |
|
|
|
КA 683 |
|
13.08.2011 |
|
152 |
|
8 |
|
|
|
КA 125 |
|
14.09.2011 |
|
202 |
|
25 |
|
|
|
КA 683 |
|
15.08.2011 |
|
148 |
|
16 |
|
|
|
|
|
|
|
Отношение БИЛЕТ |
|
Таблица 27 |
|||
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|||
Номер |
Дата |
Пассажир |
|
|
Тариф |
|
|||
КA 683 |
12.08.2011 |
Иванов Игорь Павлович |
|
IRUIV |
|
||||
КA 683 |
12.08.2011 |
Петров Сергей Львович |
|
IRUIV |
|
||||
КA 125 |
12.08.2011 |
Смит Джон Чарлз |
|
QLSALE1M |
|
||||
КA 683 |
12.08.2011 |
Карташева Елена Андреевна |
QLXAPGO |
|
|||||
… |
… |
… |
|
|
… |
|
|||
74
Иллюстрируя предыдущие три проблемы изолированности транзакций, мы предполагали, что используется второй способ. Четвертая проблема может возникнуть, если используется первый способ расчета числа свободных мест. Оба пользователя одновременно запрашивают билет на рейс КA 683 на 12.08.2011 и получают информацию о трех местах. Первый совершает покупку двух билетов и фиксирует транзакцию, в результате чего в таблице БИЛЕТ создаются две новые строки. Второй пользователь обновляет запрос и получает совершенно иной, чем ранее, результат. Такая ситуация называется фантомной вставкой (phantom insert) или проблемой строк-призраков.
Безусловно, в ситуации с покупкой билетов должно действовать правило «кто не успел, тот опоздал». Проблемы возникают не с людьми, которые интуитивно понимают ситуацию и ее причины, а с пользовательскими приложениями, которые анализируют поступающие данные. При наличии противоречий приложения могут квалифицировать базу данных как несогласованную, в то время как на самом деле она находится в непротиворечивом состоянии.
Чтобы избежать эти проблемы и предотвратить конфликтные ситуации, необходимо разработать процедуры, обеспечивающие изолированность транзакций. Стандартом SQL-92 были введены четыре такие процедуры, называемые уровнями изоляции. Они отличаются жесткостью блокирования (захвата) данных каждой конкурирующей транзакцией. На самом верхнем уровне находится процедура так называемого сериального, т.е. последовательного выполнения транзакций. На нижнем уровне предполагается, что разные транзакции могут изменять одну и ту же строку таблицы, в результате чего она будет содержать ту информацию, которую запишет в нее последняя транзакция.
В современных СУБД используются довольно сложные многочисленные алгоритмы блокировок и изоляции транзакций. Для более подробного изучения следует воспользоваться учебником [3].
3.4. Архитектура распределенных баз данных
По большому счету, любая клиент-серверная архитектура уже является распределенной, т.к. разные функциональные компоненты базы данных функционируют на разных и, возможно, территориально удаленных компьютерах. В данном разделе мы сосредоточимся на другом аспекте – распределенном хранении данных.
75

При распределенном хранении фрагменты базы данных могут быть разбросаны по нескольким географически распределенным компьютерам, называемым узлами. Такая ситуация возникает на предприятиях, имеющих отделения в разных городах (например, розничные сети, такие как IKEA или «Ашан»), или в организации, одновременно реализующей проекты в разных местах. В принципе,
втаких случаях можно использовать три архитектурных решения.
1.Первое решение – уже рассмотренная ранее клиент-сервер- ная архитектура с централизованным хранением данных на одном физическом сервере (рис. 37). Такая архитектура требует постоянного надежного соединения клиентов с сервером. В противном случае географически удаленные пользователи теряют возможность доступа к базе данных и, следовательно, останавливают свою работу. Кроме того, данная архитектура способна перегрузить трафик, что может существенно замедлить работу системы.
Рис. 37. Модель централизованного хранения данных
2.Второй подход состоит в тиражировании данных, т.е. хранении точных копий базы данных во всех узлах (рис. 38,а). В этом случае узлы обмениваются друг с другом лишь происшедшими в них изменениями. Достоинствами такой архитектуры является высокая надежность хранения данных, достигаемая благодаря наличию большого числа копий, и высокая скорость и независимость доступа локальных пользователей к любым данным. При потере связи между узлами возможна задержка актуализации копий, что может поставить под угрозу целостность данных, однако сохранит общую работоспособность системы.
3.Третье решение – фрагментация базы данных на части с последующим их хранением в соответствующих узлах (рис. 38,б). Например, каждый магазин розничной сети может вести свою не-
76
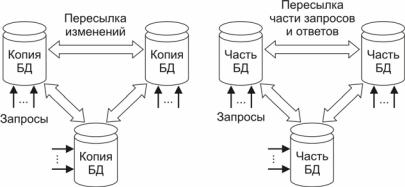
зависимую часть общей базы данных товаров. Все части базы данных имеют идентичную структуру. Если в одном магазине не оказалось нужного товара, то посылается запрос в другие узлы.
а) |
б) |
Рис. 38. Модели распределенной базы данных: а) тиражированная, б) фрагментированная [14]
Такая архитектура имеет практически неоспоримые достоинства – она не слишком перегружает трафик, узлы до определенной степени независимы, доступ к локальным данным практически мгновенный, целостность неуязвима. Проблему могут составлять только те запросы, которые обращаются к данным, хранящимся в разных узлах. В этом случае в системе должна быть обеспечена связь и досконально продуман механизм управления транзакциями.
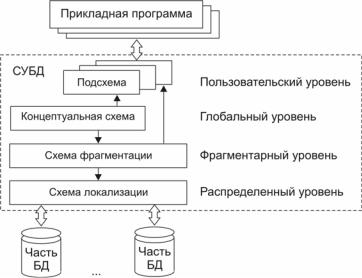
Фрагментированная распределенная база данных описывается четырехуровневой моделью, включающей в себя пользовательский, глобальный (концептуальный), фрагментарный (логический) и распределенный (локализационный) уровни представления данных
[16] (рис. 39).
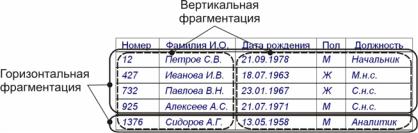
Основу архитектуры составляет глобальный уровень, на котором предметная область представляется в виде обычной концептуальной схемы. При использовании реляционной СУБД концептуальная схема превращается в совокупность таблиц, наполненных данными о конкретных объектах предметной области. Далее выполняется фрагментация этих таблиц. Фрагментация может быть горизонтальной, когда из таблицы выбираются отдельные строки, или вертикальной, когда выбираются столбцы (рис. 40). Совокуп-
77
ность выделенных из таблиц фрагментов образует фрагментарный уровень модели данных.
Рис. 39. Четырехуровневая архитектура представления данных в распределенной базе данных
После того, как фрагменты выделены, они распределяются по пользователям и по узлам. Совокупность фрагментов, необходимых определенному пользователю базы данных, образует пользо-
вательский уровень. Распределенный уровень (или уровень локали-
зации) представляет собой распределение фрагментов на хранение в определенные узлы. Один и тот же фрагмент может храниться одновременно в нескольких узлах, т.е. дублироваться. При локализации фрагментов необходимо предварительно определить критерии, которым должна отвечать база данных, например, минимизация пересылаемых данных, минимизация времени обработки запроса и др.
Особую проблему составляет управление транзакциями в распределенных базах данных. СУБД, обслуживающая «свой» узел, не знает о тех событиях, которые в это время происходят в других узлах. Если, например, один и тот же фрагмент продублирован в нескольких узлах, то к традиционным коллизиям параллельного дос-
78
тупа к данным добавляется еще и угроза нарушения репликации (обеспечения полной идентичности фрагментов).
Рис. 40. Фрагментация отношения
Для управления транзакциями в распределенных базах данных используются несколько моделей, например двухфазная, фиксация изменений [14]. Ее упрощенное описание сводится к следующему. На первом этапе выполняются «локальные» или «субтранзакции» в тех узлах, которые затрагиваются запросом и в которых производятся изменения данных. Результаты этих транзакций условно фиксируются, но при этом остаются обратимыми. На втором этапе с главного узла контролируется отсутствие сбоев во всех задействованных узлах и успешное окончание репликации данных, после чего изменения фиксируются окончательно и необратимо.
Контрольные вопросы
1.Как взаимодействуют СУБД и операционная система?
2.По какому принципу из схемы выделяются подсхемы?
3.При использовании какой модели данных – иерархической, сетевой или реляционной – необходимо создавать концептуальную схему?
4.Когда удобнее пользоваться нотацией Чена и когда – Баркера?
5.Является ли файл-серверная модель разновидностью клиент-сер- верной архитектуры?
6.Повышает ли скорость обработки запросов архитектура с сервером базы данных?
7.В каких случаях следует создавать архитектуру с тонким клиентом?
8.Зачем нужно тратить столько сил на обработку транзакций?
9.Чем отличается расширенная транзакция от обычной?
79
10.Может ли привести потерянное обновление к отсутствию повторяемости чтения?
11.Кому мешает фантомная вставка?
12.Что лучше – фрагментирование или тиражирование данных в распределенной базе данных?
13.В каких случаях выполняется горизонтальная, а в каких – вертикальная фрагментация?
ЗАКЛЮЧЕНИЕ
В качестве заключения проведем линию времени с указанием наиболее значимых событий в области баз данных:
1964 г. – файловая организация данных IBM/360;
1965 г. – формирование рабочей группы по базам данных; 1968 г. – первая иерархическая СУБД IMS;
1969 г. – сетевая модель данных CODASYL;
1970 г. – СУБД ADABAS на инвертированных списках; 1970 г. – реляционная модель данных;
1971 г. – первая сетевая СУБД IDMS;
1975 г. – первая реляционная СУБД System R;
1975 г. – трехуровневая архитектура баз данных ANSI-SPARC; 1975 г. – диаграммы «сущность-связь»;
1979 г. – СУБД Oracle;
1980 г. – первая СУБД для микро- (персональных) ЭВМ dBase; 1981 г. – механизм управления транзакциями;
1986 г. – первая редакция стандарта SQL;
1989 г. – манифест объектно-ориентированных баз данных; 1993 г. – стандарт ODMG объектно-ориентированных баз дан-
ных; 1993 г. – концепция многомерного представления данных;
1994 г. – стандарт RSQL2 темпоральных баз данных; 2003 г. – концепция XML баз данных.
Из приведенного списка видно, что наиболее принципиальные идеи, сформировавшие философию баз данных, выработаны в 1970-е гг. Это вовсе не означает, что базы данных – сформировав-
80