

Эволюция баз данных
.pdfБазы данных, основанные на триплах, получили название колоночных (column-oriented), поколоночных или баз данных, состоящих из семейства столбцов. Название объясняется тем, что собрав вместе все триплы с одинаковым свойством (атрибутом), получаем одну колонку отношения, например: <Петров С.В., Пол, М>, < Ива-
нова И.В., Пол, Ж>, < Павлова В.Н., Пол, Ж>, < Алексеев А.С., Пол, М>, < Сидоров А.Г., Пол, М> (см. табл. 21). Представителями колоночных СУБД являются упомянутые Cassandra, Mulgara (Tucana Technologies Inc., 2004) и др.22
Объединение триплов, описывающих один объект, называется документом. По существу, документ – это множество пар «атри- бут-значение», например: РАБОТНИК_12 {‘Фамилия И.О.’: Петров С.В., ‘Дата рождения’: 21.09.1978, ‘Пол’: М>, ‘Должность’: Начальник}. В
качестве значения может выступать список или другой документ:
ОТДЕЛ_АНАЛИТИЧЕСКИЙ { ‘Корпус’: 2, ‘Этаж’: 3, ‘Комната’: 2-326, ‘Телефон’: 372-76-39, ‘Работники’: [{ ‘Фамилия И.О.’: Петров С.В., ‘Да-
та рождения’: 21.09.1978, ‘Пол’: М>, ‘Должность’: Начальник }, { ‘Фамилия И.О.’: Сидоров А.Г., ‘Дата рождения’: 13.05.1958, ‘Пол’: М>, ‘Долж-
ность’: Аналитик }]. Для описания документа обычно используется нотация JSON (JavaScript Object Notation) или XML (Extensible Markup Language), вследствие чего базы данных, основанные на документах, получили название документо-ориентированных (do- cument-oriented, англ.) – СУБД CouchDB (Apache Software Foundation, 2005 г.), MongoDB (10gen, 2009 г.) или XML баз данных – СУБД Documentum xDB (EMC Corporation), eXist (коллективная разработка, конец 2000-х гг.) и др.
Наряду с триплом «объект-атрибут-значение» известен и другой вариант трипла – «объект-отношение-объект». Такой трипл предназначен для хранения информации, которая в традиционных базах данных называется связью, например, <Петров С.В., Работает,
Аналитический> (см. табл. 9) или <Петров С.В., Является руково-
дителем, Сидоров А.Г.>. Представление связей между конкретными объектами предметной области позволяет описать ее в виде семантической сети или графа (рис. 22), в котором триплы первого типа образуют узлы, а триплы второго типа – дуги или ребра. Такие базы данных получили название графовых (graph database). Необходимо отметить, что графовые модели – не новость: описание похо-
22 Вследствие неустоявшейся терминологии, разработчики далеко не всегда однозначно классифицируют или вообще классифицируют свои СУБД.
51
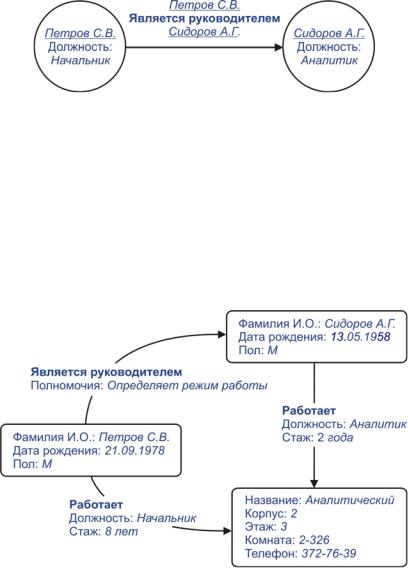
жих баз данных можно найти в монографии [15], изданной еще в 1985 г., где они упоминаются как бинарные базы данных.
Рис. 22. Граф, описываемый триплами (ключи подчеркнуты)
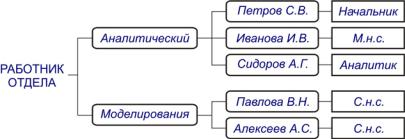
Если расширить триплы до документов, то можно получить более богатое описание объектов и связей между ними (рис. 23). Дальнейшее обобщение такого представления данных приводит нас к диаграммам «сущность-связь» – интенсиональным семантическим сетям, являющимся сегодня основным инструментом концептуального проектирования баз данных.
Благодаря интуитивной простоте и пригодности для описания слабо структурированной информации графовые СУБД – Neo4j (Neo Technology, 2007 г.), AllegroGraph (Franz, Inc., 2010 г.), InfiniteGraph, HyperGraphDB (Kobrix Software, 2010 г.) и другие активно завоевывают рынок.
Рис. 23. Граф, описывающий структуру предприятия
52
Заметим, что объекты, ассоциативные массивы, триплы и документы – похожие понятия. В [26] рассматривается универсальная структура – «глобал» (global), с помощью которой можно представить любой из этих элементов. В общем случае, глобал – это структура данных, ассоциированных с деревом ключей, пример которого показан на рис. 24. Понятие глобала используется в известной СУБД Cache (InterSystems Corporation), которая с начала 2000-х гг.
позиционируется как универсальная свободно распространяемая объектно-ориентированная база данных, поддерживающая нереляционные модели.
Рис. 24. Глобал, описывающий структуру предприятия
Сопоставим еще раз базовые понятия моделей данных (табл. 22).
|
Базовые понятия моделей данных |
Таблица 22 |
||||
|
|
|||||
|
|
|
|
|
|
|
Плоские |
С инвертиро- |
Иерархи- |
Сете- |
Реляци- |
Объектно- |
|
файлы |
ванными спи- |
ческая |
вая |
онная |
ориенти- |
|
|
сками |
|
|
|
рованная |
|
|
|
Схема |
Схема |
Схема |
Диаграмма |
|
|
|
классов |
||||
|
|
|
|
|
||
Файл |
Файл |
Тип сег- |
Тип |
Отноше- |
Класс |
|
мента |
записи |
ние |
||||
|
|
|
||||
Запись |
Запись |
Экземпляр |
Запись |
Кортеж |
Объект |
|
|
|
сегмента |
|
|
|
|
Поле |
Поле |
Поле |
Элемент, |
Элемент |
Атрибут |
|
агрегат |
кортежа |
|||||
|
|
|
|
|||
|
|
|
Тип |
|
|
|
|
|
|
набора |
|
|
|
|
Инвертирован- |
Набор |
Набор |
Отноше- |
Иерархия |
|
|
ный список |
ние |
классов |
|||
|
|
|
||||
|
|
|
|
|
Метод |
|
53
Контрольные вопросы
1.Есть ли что-то общее между компьютерным и пластиковым файлами?
2.В каких случаях логическая и физическая записи совпадают?
3.Может ли существовать файл прямого доступа с последовательной организацией?
4.Как организовать файл, чтобы быстро находить нужную запись?
5.Чем файловая система не устраивала разработчиков информационных систем?
6.Чем отличается первичный ключ от вторичного?
7.Достаточно ли выполнить сортировку строк таблицы, чтобы получить инвертированный список?
8.Что содержит физическая запись иерархической базы данных?
9.Чем знамениты Ч. Бахман, Э. Кодд, Р. Баркер и П. Чен?
10.В чем состоит отличие иерархической и сетевой баз данных?
11.Можно ли иерархическую и сетевую базы данных преобразовать в реляционную?
12.В чем отличие языка SQL от других языков программирования?
13.Почему в сложных задачах обработки данных многомерный куб эффективнее традиционных структур?
3.ЭВОЛЮЦИЯ АРХИТЕКТУР БАЗ ДАННЫХ
3.1. Уровни представления данных
При файловой организации данных каждое приложение (application – прикладная программа, англ.) «привязывается» к одному или нескольким конкретным файлам на «логическом» уровне. Это означает, что в программе с помощью определенных операторов и синтаксических конструкций языка программирования должно быть указано имя файла, определены идентификаторы и длины полей его записей. Задача манипулирования данными сводится к операциям ввода-вывода записей и их программной обработке, в ходе которой реализуется поиск и модификация нужной записи. Каждый файл обрабатывается независимо от других. Привязка логического файла, описанного в прикладной программе, к физическому файлу,
54
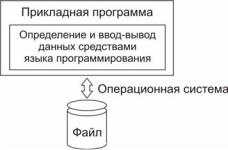
существующему на носителе, выполняется операционной системой
(рис. 25).
Очевидно, что при такой архитектуре все задачи сопровождения данных полностью ложились на прикладную программу. В случае изменения структуры данных соответствующие изменения вносились в исходный текст программы.
Рис. 25. Архитектура файловой организации данных
Одноуровневая и двухуровневая модели
С появлением первых иерархических и сетевых СУБД возникло новое понятие – схема данных, немыслимое при файловой организации, отвергающей всяческие взаимосвязи между данными. Спецификация этой схемы, а также манипулирование данными выполняется уже языковыми средствами СУБД – ЯОД и ЯМД. Взаимодействие СУБД с прикладной программой осуществлялось по-раз- ному. Так, в СУБД ДИСОД – советском аналоге ADABAS взаимодействие с приложением обеспечивалось с помощью «функционального интерфейса» [11]. Для каждой прикладной программы администратор СУБД разрабатывал специальный интерфейсный модуль, в котором специфицировались объекты базы данных, требуемые этой программе, и необходимые операции (рис. 26,а). Прикладная программа обращалась к этому модулю через соответствующую точку входа и передавала ему определенные параметры, уточняющие запрос. В ответ программа получала требуемые данные.
Подобная архитектура использовалась и в СУБД СЕТЬ, поддерживающей сетевую модель CODASYL. В ней для каждого приложения создавалась подсхема – фрагмент общей схемы, описывающий те записи и наборы, которые требовались данному приложению (рис. 26,б). Кроме того, в подсхеме могли создаваться «ло-
55
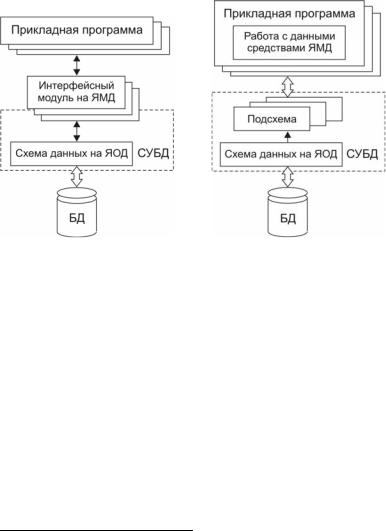
гические записи», представляющие собой искусственное соединение записей данной подсхемы (аналог оператора JOIN в SQL). Доступ к данным из прикладных программ обеспечивался с помощью операторов ЯМД, которые включались в исходный текст на COBOL, PL/1 или Assembler ЕС ЭВМ.
а) |
б) |
Рис. 26. Одноуровневая (а) и двухуровневая (б) |
|
архитектуры представления данных |
|
Трехуровневая модель
Использование подсхем стало прообразом новой архитектуры баз данных, предложенной в 1975 г. рабочей группой, функционирующей под патронажем Американского института стандартов ANSI. Побудительным мотивом стали три причины: обилие разных методов физической организации данных, необходимость описания данных на языках, понятных только программистам, и отсутствие стандарта такого языка23. Выходом из этой ситуации стало введение «надфизического» уровня описания данных.
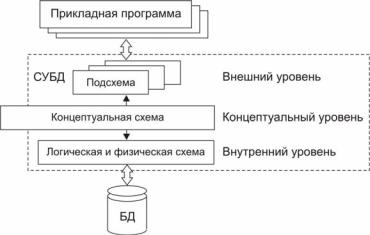
Новая архитектура впервые описана в знаменитом отчете [17]. Ее суть состоит в том, что данные рассматриваются на трех уровнях: концептуальном, внутреннем и внешнем (рис. 27). На концептуальном уровне все данные должны быть описаны в обобщенном виде в терминах, применяемых в моделируемой предметной облас-
23 SQL появился только в 1980-е гг.
56
ти. На этом уровне предметная область представляется как совокупность связанных друг с другом объектов, обладающих определенными свойствами. Такое представление получило название кон-
цептуальная модель (или концептуальная схема). Основным свой-
ством концептуальной модели является ее независимость от физической организации данных; от того, какой подход – иерархический, сетевой или реляционный будет применяться и с помощью какой СУБД будет реализована база данных.
Концептуальная модель образует базис, на котором строится внутреннее (физическое) и внешнее (пользовательское) представление. На внутреннем уровне данные описываются в терминах отношений, записей, полей, методов доступа, индексов, т.е. в том виде, в котором они будут храниться на носителе. На внутреннем уровне описание выполняется в два этапа. На первом этапе концептуальная модель преобразуется в логическую модель (или логическую схему) данных, отвечающую требованиям и ограничениям выбранного подхода – реляционного, сетевого, иерархического или объектного. На втором этапе выполняется описание этой схемы на языке выбранной СУБД. В показанном на рис. 28 примере выбран реляционный подход, вследствие чего логическая схема представляет собой набор отношений (таблиц), а физическое описание выполняется на языке SQL.
Рис. 27. Трехуровневая архитектура представления данных ANSI-SPARC
57

Проектируя базу данных, разработчик всегда должен опираться на те производственные задачи, которые с помощью его системы будет решать каждый конкретный пользователь. Зная задачи пользователя, мы можем определить, какая информация нужна ему для работы. В примере на рис. 28 показано, что менеджера проекта интересует информация о работниках, ответственных за выполнение каждой задачи проекта, инспектора отдела кадров – информация о расстановке работников по подразделениям, а бухгалтера – информация о начисленной работнику заработной плате. Иначе говоря, каждый пользователь работает со своей частью базы данных, которая описывается подсхемой, являющейся фрагментом концептуальной схемы. Совокупность пользовательских подсхем образует внешний уровень представления данных.
В отечественной практике работы с базами данных укоренились еще два термина для обозначения уровней представления данных – даталогическая и инфологическая модели.
Под инфологической понимается модель предметной области, построенная на языке и с участием экспертов, владеющих содержательной стороной предметной области. Вместо понятий «сущность», «атрибут» и «связь» в инфологической модели используются «объект», «реквизит» и «ассоциация». На сегодняшний день нет устоявшихся требований и нотаций для построения инфологической модели. Поэтому большая часть современных специалистов не различает концептуальную и инфологическую модели.
Аналогично дело обстоит и с даталогической моделью. Большинство специалистов (например, [3]), считает, что даталогическая модель – это отображение инфологической модели на структуру данных, поддерживаемую выбранной СУБД, например, реляционную, сетевую, иерархическую24. Предполагается, что даталогическая модель не должна отражать физическую организацию данных, однако должна учитывать специфику, ограничения и термины используемой СУБД. Например, при использовании реляционной СУБД даталогическая модель представляет собой схемы таблиц, реализующих инфологическую модель. Таким образом, даталогическая модель является синонимом логической модели.
24В цитируемом учебнике к даталогическим моделям отнесены также тезаурусы, дескрипторы, размеченные документы и др.
58
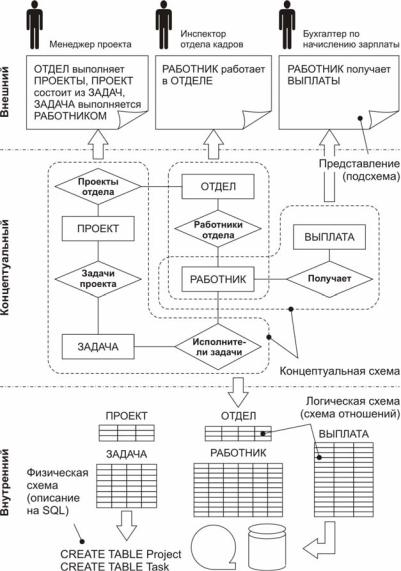
Рис. 28. Пример базы данных с трехуровневой архитектурой
59

Диаграммы «сущность-связь»
Из приведенного описания архитектур видно, что базовый уровень составляет концептуальная схема данных. Наиболее наглядным и удобным способом ее изображения считается структурная диаграмма, представляющая собой граф, в котором объекты предметной области представлены вершинами-прямоугольниками, а связи между этими объектами – дугами. Учитывая, что в концептуальном моделировании вместо понятия «объект» традиционно используется понятие «сущность» (entity, англ.), такие диаграммы стали называться диаграммами «сущность-связь» (entity-relationship diagram или ER-model).
Известно большое число графических нотаций для изображения ER-моделей. Их прообразом стала диаграмма, предложенная в 1969 г. Ч. Бахманом для изображения схемы сетевой модели данных в терминах типов записей, типов наборов, членов и владельцев наборов [19]25. Следующий шаг был сделан в 1975 г. П. Ченом [21], предложившим нотацию для изображения элементов не только концептуального, но и логического уровня. В 1986 г. Р. Баркер, используя идеи Бахмана и Чена, разрабатывает собственную нотацию [20], ставшую основой для многочисленных последователей. Подробное рассмотрение и анализ этих и других нотаций концептуального моделирования выходит за рамки данного пособия.
Для построения ER-моделей используется специальное программное обеспечение – так называемые CASE-средства, появившиеся в начале 1980-х гг. Аббревиатура CASE имеет две расшиф-
ровки: Computer-Aided Software Engineering (разработка программ с помощью компьютера) и Computer-Aided System Engineering (про-
ектирование систем с помощью компьютера). Сегодня под CASEсредствами понимается широкий спектр инструментария, предназначенного для разработки структурных моделей программ, процессов и систем. Часть этих средств предназначена для построения ER-моделей с использованием наиболее популярных графических нотаций. В нашей стране наиболее широкое распространение полу-
чили CA ERwin Data Modeler (производитель – Computer Associates), Oracle Designer (Oracle Corporation), Power Designer (Sybase), Microsoft Visio (Microsoft Corporation) и др. Большинство из этих продуктов поддерживает нотацию Баркера или Мартина, реже –
25 По-существу, эти термины идентичны понятиям сущности и связи.
60