

Харке-бера
|
Type |
h |
p-value |
jbstat |
critval |
|
Daily Simple Returns |
|
|
|
|
|
Daily Log Returns |
|
|
|
|
|
Month Simple Returns |
|
|
|
|
|
Month Log Returns |
|
|
|
|
общее
|
Type |
Start |
Finish |
Size |
Mean |
Standard Deviation |
Skewness |
Excess Kurtosis |
Minimum |
Maximum |
|
Daily Simple |
|
|
|
|
|
|
|
|
|
|
Daily Log |
|
|
|
|
|
|
|
|
|
|
Monthly Simple |
|
|
|
|
|
|
|
|
|
|
Monthly Log |
|
|
|
|
|
|
|
|
|
Введение.
В данной работе мы рассмотрим доходности некоторых российских компаний в девятилетний период с 01.01.2005 по 31.05.2014. Мы рассмотрим три различных периода: 1) докризисный период – с 01.01.2005 по 31.12.2007, 2) период кризиса – с 01.01.2008 по 31.12.2010, 3) посткризисный период – с 01.01.2011 по 31.12.2013.
Примечание автора: Эти даты взяты для необходимости получить сравнительный анализ доходностей различных российских компаний в различных периодах. Это не означает, что кризис начался и закончился в конкретные, строго определённые сроки. Ведь, по мнению, в первую очередь, различных экспертов, во вторую очередь, в отношении к разным странам, кризис начался в разное время и по разным причинам. Более того, большинство финансовых аналитиков считают, что мировой финансовый кризис 2008 года не закончился до сих пор и ещё некоторое время будут заметны его последствия. Мы взяли эти даты, чтобы графически и аналитически пронаблюдать возможные отличия доходностей компаний в различные периоды.
В настоящее время для анализа изменения цен различных компаний используются наблюдения за изменением величины различных индексов.
Мы
получим для наших выборок некоторые
статические показатели, такие как
математическое ожидание (mean),
стандартное отклонение (standard
deviation), коэффициент
асимметрии (skewness) и
коэффициент эксцесса (excess
kurtosis). Так же для наших
выборок мы проведём тест Харке – Бера,
который проверяет
нулевую гипотезу
 о том, что
распределение генеральной совокупности
значений случайной величины (доходностей)
не противоречит нормальному закону.
о том, что
распределение генеральной совокупности
значений случайной величины (доходностей)
не противоречит нормальному закону.
Мы использовали для наблюдений данные с интернет ресурса www.finam.ru. Анализ доходностей различных компаний производился на основе индекса ММВБ.
 - простые
доходности (simple returns).
Определяются как разность текущей цены
и цены в прошлом периоде, делённую на
цену в прошлом периоде.
- простые
доходности (simple returns).
Определяются как разность текущей цены
и цены в прошлом периоде, делённую на
цену в прошлом периоде.

 - логарифмические
доходности (log returns).
Определяются как натуральный логарифм
частного текущей цены и цены в прошлом
периоде.
- логарифмические
доходности (log returns).
Определяются как натуральный логарифм
частного текущей цены и цены в прошлом
периоде.

 (mean) – математическое
ожидание случайной величины. В нашем
случае случайной величиной является
доходность компании, выраженная в
процентах. У нас есть две выборки, по
которым мы считаем простые доходности
и логарифмические доходности, выраженные
в процентах в 5 летний период с 01.01.2009 по
31.12.2013 - по 60 элементов – месяцы, по 1250
элементов - дни. Математическое ожидание
есть среднее значение случайной величины,
а в нашем случае, так как случайные
величины считаются равновероятными –
математическое ожидание есть среднее
арифметическое случайной величины.
(mean) – математическое
ожидание случайной величины. В нашем
случае случайной величиной является
доходность компании, выраженная в
процентах. У нас есть две выборки, по
которым мы считаем простые доходности
и логарифмические доходности, выраженные
в процентах в 5 летний период с 01.01.2009 по
31.12.2013 - по 60 элементов – месяцы, по 1250
элементов - дни. Математическое ожидание
есть среднее значение случайной величины,
а в нашем случае, так как случайные
величины считаются равновероятными –
математическое ожидание есть среднее
арифметическое случайной величины.

 (sample variance)
- несмещённая (исправленная) выборочная
дисперсия. Вообще говоря, дисперсия
случайной - есть
мера разброса данной случайной
величины,
то есть её отклонения от математического
ожидания.
(sample variance)
- несмещённая (исправленная) выборочная
дисперсия. Вообще говоря, дисперсия
случайной - есть
мера разброса данной случайной
величины,
то есть её отклонения от математического
ожидания.
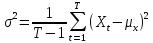
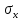 (standard deviation)
- стандартное отклонение случайной
величины. Это есть оценка
среднеквадратического отклонения
случайной величины относительно
её математического ожидания на
основе несмещённой
оценки её
дисперсии. Стандартное отклонение равно
квадратному корню из несмещённой
выборочной дисперсии. Вообще говоря,
стандартное отклонение показывает на
сколько в среднем случайная величина
отличается от её математического
ожидания.
(standard deviation)
- стандартное отклонение случайной
величины. Это есть оценка
среднеквадратического отклонения
случайной величины относительно
её математического ожидания на
основе несмещённой
оценки её
дисперсии. Стандартное отклонение равно
квадратному корню из несмещённой
выборочной дисперсии. Вообще говоря,
стандартное отклонение показывает на
сколько в среднем случайная величина
отличается от её математического
ожидания.
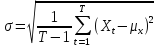
 (sample skewness)
– коэффициент асимметрии. Можно сказать,
что если коэффициент асимметрии
положителен, если правый хвост
распределения длиннее левого, и
отрицателен в противном случае. Если
распределение симметрично
относительно математического
ожидания, то его коэффициент асимметрии
равен нулю. В нашем случае это означает,
что если
коэффициент асимметрии > 0, то это
означает, что преобладают данные с
большими значениями, а если < 0, то
больше данных с меньшими значениями,
чем среднее арифметическое.
(sample skewness)
– коэффициент асимметрии. Можно сказать,
что если коэффициент асимметрии
положителен, если правый хвост
распределения длиннее левого, и
отрицателен в противном случае. Если
распределение симметрично
относительно математического
ожидания, то его коэффициент асимметрии
равен нулю. В нашем случае это означает,
что если
коэффициент асимметрии > 0, то это
означает, что преобладают данные с
большими значениями, а если < 0, то
больше данных с меньшими значениями,
чем среднее арифметическое.

 (sample kurtosis)
– коэффициент эксцесса. Есть мера
остроты пика распределения случайной
величины. Excess kurtosis
=
(sample kurtosis)
– коэффициент эксцесса. Есть мера
остроты пика распределения случайной
величины. Excess kurtosis
=
 – 3. Минус три в
конце формулы введено для того, чтобы
коэффициент эксцесса нормального
распределения был
равен нулю. В дальнейшем всегда будем
принимать
– 3. Минус три в
конце формулы введено для того, чтобы
коэффициент эксцесса нормального
распределения был
равен нулю. В дальнейшем всегда будем
принимать
 ,
как excess kurtosis.
Коэффициент эксцесса
положителен, если пик распределения
около математического
ожидания острый,
и отрицателен, если пик гладкий.
,
как excess kurtosis.
Коэффициент эксцесса
положителен, если пик распределения
около математического
ожидания острый,
и отрицателен, если пик гладкий.
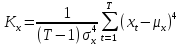

Тест Харке – Бера.
Тест Харке - Бера
- это статистический
тест,
проверяющий ошибки наблюдений
на нормальность посредством
сверки их третьего
момента (асимметрия) и
четвёртого
момента (эксцесса) с моментами нормального
распределения,
у которого
 = 0,
= 0,
 = 3. По сути дела он
проверяет нулевую гипотезу
= 3. По сути дела он
проверяет нулевую гипотезу
 о том, что
распределение генеральной совокупности
значений случайной величины не
противоречит нормальному закону. Если
эта гипотеза верна, то при большом
количестве наблюдений
о том, что
распределение генеральной совокупности
значений случайной величины не
противоречит нормальному закону. Если
эта гипотеза верна, то при большом
количестве наблюдений
 статистика
статистика
 имеет распределение, близкое к
распределению хи-квадрат с 2 степенями
свободы.
имеет распределение, близкое к
распределению хи-квадрат с 2 степенями
свободы.

При нарушении условия нормальности
распределения ошибок значения статистики
 имеют тенденцию к возрастанию. Поэтому
гипотеза нормальности ошибок отвергается,
если значения этой статистики слишком
велики.
имеют тенденцию к возрастанию. Поэтому
гипотеза нормальности ошибок отвергается,
если значения этой статистики слишком
велики.
В данной работе для подсчёта вышеописанных величин для наших выборок использовалась программа matlab. Использовались следующие функции: mean(), std(), skewness(),kurtosis().
Для проведения теста Харке – Бера использовался метод [h,p,jbstat,critval] = jbtest(), где на выходе мы получаем 4 значения: h – индикатор, который принимает значение 1, если отвергается нулевая гипотеза о том, что распределение совокупности значений случайной величины не противоречит нормальному закону и 0 если принимается; p - (p-value) Обычно равно вероятности того, что случайная величина с данным распределением (распределением тестовой статистики при нулевой гипотезе) примет значение, не меньшее, чем фактическое значение тестовой статистики. Если p мало, но нулевая гипотеза отвергается. В нашем случае если p больше 0,05, то нулевая гипотеза о нормальности распределения доходностей принимается, в противном случае отвергается; jbstat – значение статистики Харке - Бера; critval – критическое значение – если jbstat > critval, то нулевая гипотеза отвергается.
Рассмотрим нефтегазовую отрасль.
В данной отрасли мы рассмотрим 6 российских компаний: НОВАТЭК, Роснефть, Лукойл, Газпром, Татнефть и Сургутнефтегаз.
|
Акция |
Доля в отрасли, % |
|
НОВАТЭК, акция об. |
15.72 % |
|
Роснефть, акция об. |
15.42 % |
|
Лукойл, акция об. |
14.97 % |
|
Газпром, акция об. |
14.29 % |
|
Татнефть, акция об. |
9.69 % |
|
Сургутнефтегаз, акция об. |
9.17 % |
|
Транснефть, акция прив. |
7.37 % |
|
Сургутнефтегаз, акция прив. |
6.02 % |
|
Башнефть, акция прив. |
3.37 % |
|
Башнефть, акция об. |
2.72 % |
|
Татнефть, акция прив. |
1.17 % |
|
Славнефть-Мегионнефтегаз, акция прив. |
0.09 % |
Данные взяты с сайта www.stocks.investfunds.ru по состоянию на 19.06.2014.
Как видно из таблицы, эти первые 6 типов акций компаний занимают 68,9% нефтегазового сектора, учитываемого в индексе ММВБ. Так как эти 6 акций из 12 представленных имеют наибольшую долю в данной отрасли, то именно их мы и будем рассматривать.
1.Компания НОВАТЭК.
1 период.
|
Type |
Start |
Finish |
Size |
Mean |
Standard Deviation |
Skewness |
Excess Kurtosis |
Minimum |
Maximum |
|
Daily Simple |
18.08.2006 |
31.12.2007 |
342 |
0.1364 |
2.3310 |
0.3617 |
3.5669 |
-10.4567 |
12.0794 |
|
Daily Log |
18.08.2006 |
31.12.2007 |
342 |
0.1094 |
2.3216 |
0.1741 |
3.4143 |
-11.0448 |
11.4038 |
|
Monthly Simple |
18.08.2006 |
31.12.2007 |
17 |
1.6554 |
9.5145 |
0.0195 |
-0.9792 |
-13.7500 |
17.7295 |
|
Monthly Log |
18.08.2006 |
31.12.2007 |
17 |
1.2266 |
9.4131 |
-0.1172 |
-1.0023 |
-14.7920 |
16.3219 |
Простые дневные доходности компании НОВАТЭК в первом периоде.

Простые месячные доходности компании НОВАТЭК в 1 периоде.

|
Type |
h |
p-value |
jbstat |
critval |
|
Daily Simple Returns |
1 |
0.001 |
188.7615 |
5.7979 |
|
Daily Log Returns |
1 |
0.001 |
167.8435 |
5.7979 |
|
Month Simple Returns |
0 |
0.5 |
0.6802 |
3.5227 |
|
Month Log Returns |
0 |
0.5 |
0.7505 |
3.5227 |