

Практикум по прикладой статистике
.pdfструктурные коэффициенты, которые представляют собой коэффициенты корреляции между значениями функции для объектов и соответствующими значениями дискриминатных переменных.
Задача определения принадлежности нового объекта к одному из заданных классов может быть решена с помощью:
1)расчета значений канонических дискриминатных функций для новых объектов;
2)линейного дискриминантного анализа;
3)определения расстояний от нового объекта до центра
классов;
4)расчета вероятностей отнесения нового объекта к классам.
Линейный дискриминантный анализ
Идея линейного дискриминатного анализа заключается в определении линейной комбинации дискриминантных переменных, позволяющих максимизировать межклассовую дисперсию и минимизировать внутриклассовую. Для отнесения нового объекта к одному из классов рассчитываются значения линейных классификационных функций, далее объект относится к тому классу, для которого значение соответствующей функции наибольшее.
Рассмотрим алгоритм линейного дискриминантного анализа в
случае наличия обучающих выборок из двух классов Х1 и Х2
объемом n1 |
и n2, р дискриминатных переменных и равенства |
||
априорных |
вероятностей принадлежности |
объекта |
к классам |
π1=π2=0,5. |
|
|
|
1. Определение оценок вектора |
средних |
значений |
|
переменных по имеющимся выборкам из каждого класса объектов:
|
ˆ |
ˆ |
ˆ |
ˆ |
T |
|
ˆ |
|
ˆ |
ˆ |
ˆ |
T |
Х1 х11, х12 ,..., х1 p |
, Х 2 |
х21, х22 ,..., х2 p . |
||||||||||
|
|
2. |
Определение |
оценок |
соответствующих ковариационных |
|||||||
матриц |
ˆ |
ˆ |
|
для |
классов Х1 |
и Х2. Элементы матриц |
||||||
1 |
и 2 |
|
||||||||||
определяются по формуле
100

|
|
|
|
|
|
n |
|
|
|
|
|
|
|
1 |
n |
xi xlj |
x j |
xli xlj |
|
|
|
|
|
|
|
xli |
l 1 |
|
|
|
|
||||
ij |
|
xi x j |
xi x j |
xi x j , |
|||||||
|
n |
||||||||||
|
|
n l 1 |
|
|
|
|
|
|
|||
где i, j=1,2,…,k номера переменных (столбцов); l=1,2,…n – номера объектов (строк); n – количество объектов в соответствующей выборке из классов.
|
3. |
Определение |
несмещенной |
оценки |
совместной |
|||||||
|
|
|
|
|
|
ˆ |
1 |
|
|
ˆ |
ˆ |
|
ковариационной матрицы |
|
|
n1 1 |
n2 2 |
. |
|||||||
|
|
|
|
|
|
|
n1 n2 |
2 |
|
|
|
|
|
4. |
Расчет обратной матрицы для совместной ковариационной |
||||||||||
|
|
ˆ |
1 |
. |
|
|
|
|
|
|
|
|
матрицы |
|
|
|
|
|
|
|
|
||||
|
5. |
Вычисление |
вектора |
оценок |
коэффициентов |
|||||||
дискриминантной функции |
Â=(â1, |
â2, |
…, |
âр)Т |
по формуле |
|||||||
ˆ |
ˆ 1 |
ˆ |
|
|
ˆ |
|
|
|
|
|
|
|
А |
Х1 |
Х 2 . |
|
|
|
|
|
|
|
|||
|
6. |
Установление принадлежности нового объекта из группы |
||||||||||
Х* к одному из классов на основе определения значения выражения
|
* |
|
1 |
ˆ |
|
ˆ |
|
T |
ˆ |
|
|
|
X |
|
|
|
X |
1 |
X |
2 |
|
A . |
Если |
полученное |
значение |
|
|
|
2 |
|
|
|
|
|
|
|
|
|
неотрицательно, тогда объект из группы Х* относится к классу Х1 , в противном случае к классу Х2.
Пример 5.1. Имеются данные по двум группам объектов Х1 и Х2, характеризующиеся тремя показателями. Необходимо провести классификацию группы новых объектов Х*.
|
56 |
0,8 |
8,7 |
|
32 |
1,2 |
5,4 |
|
|
|
40 |
1,13 |
3,9 |
|||||
|
|
|
|
|
|
|
|
|
|
|
|
, Х * |
|
|
|
|
|
|
Х1 |
|
49 |
0,96 |
6,9 |
|
, Х 2 |
|
45 |
1,5 |
4,8 |
|
|
56 |
0,75 |
7,2 |
. |
||
|
|
68 |
0,84 |
7,6 |
|
|
|
39 |
1,49 |
6,1 |
|
|
|
|
32 |
1,35 |
5,4 |
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
Решение. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1. Рассчитать вектор средних значений по двум классам из |
|||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
ˆ |
|
|
|
|
|
T |
обучающей |
|
|
выборки: |
|
|
Х1 |
57,67;0,87; 7,73 , |
|||||||||||
ˆ |
|
|
|
|
|
T |
|
|
|
|
|
|
|
|
|
|
|
|
Х 2 |
38,67;1,40;5,43 . |
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
101 |
|
|
|
|
|
|
|
|
|

|
2. Найти оценки ковариационных матриц: |
|
|
||||||||
|
61,56 |
0,32 |
1,41 |
|
|
|
28,22 |
0,67 |
1,19 |
|
|
ˆ |
|
|
|
|
|
ˆ |
|
|
|
|
|
|
0,32 |
0,00 |
0,05 |
|
|
0,67 |
0,02 |
0,00 |
. |
||
1 |
, |
2 |
|||||||||
|
|
1,41 |
0,05 |
0,55 |
|
|
|
|
0,00 |
0,28 |
|
|
|
|
|
|
1,19 |
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ˆ |
|
1 |
|
|
ˆ |
ˆ |
|
|
|
||
|
|
|
|
|
3. |
|
|
По |
формуле |
|
n1 |
n2 |
2 |
n1 1 n2 2 |
|
определить |
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
совместную |
|
|
|
|
|
|
|
|
|
ковариационную |
|
|
|
|
матрицу |
|||||||||||||||||
|
|
|
67,33 |
0,26 |
|
0,17 |
|
|
|
|
|
|
|
|
|
|
||||||||||||||||
ˆ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
0,26 |
|
|
|
|
0,02 |
0,03 . |
|
|
|
|
|
|
|
|
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||
|
|
|
|
0,17 |
|
|
0,03 |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
0,62 |
|
|
|
|
|
|
|
|
|
|
|||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0,02 |
0,26 |
0,02 |
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ˆ 1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0,26 |
66,21 |
3,66 . |
||||||
|
|
|
|
|
4. Обратная матрица равна: |
|||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0,02 |
3,66 |
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1,81 |
|||||||
|
|
|
|
|
5. Определить вектор оценок коэффициентов дискрими- |
|||||||||||||||||||||||||||
нантной функции |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0,02 |
0,26 |
0,02 |
57,67 38,67 |
0,40 |
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ˆ |
|
ˆ 1 |
|
|
ˆ |
|
|
|
ˆ |
|
0,26 |
66,21 |
3,66 |
|
0,87 1,40 |
31,62 |
. |
|||||||||||||||
А |
|
|
Х1 |
Х 2 |
||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0,02 |
3,66 |
1,81 |
|
|
7,73 |
5,43 |
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1,87 |
|
|||||||||||
|
|
|
|
|
6. Определить принадлежность новых объектов к классам на |
|||||||||||||||||||||||||||
основе |
|
|
|
|
|
|
|
расчета |
|
|
численных |
|
значений |
|
|
выражения |
||||||||||||||||
|
|
|
* |
|
|
|
1 |
|
ˆ |
|
|
|
|
ˆ |
|
|
T |
|
|
ˆ |
|
|
|
|
|
|
|
|
|
|
||
X |
|
|
2 |
|
X1 |
X 2 |
|
A : |
|
|
|
|
|
|
|
|
|
|
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
40 |
|
1,13 |
|
|
3,9 |
|
|
57,67 38,67 Т |
|
|
0,40 |
|
|
281,10 |
|||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
56 |
|
|
0,75 |
7,2 |
|
|
|
0,87 1,40 |
|
|
|
31,62 |
|
|
12,47 |
|
||||||||||||||
|
|
2 |
||||||||||||||||||||||||||||||
|
|
32 |
|
|
1,35 |
5,4 |
|
|
7,73 5,43 |
|
|
|
1,87 |
|
|
22,77 |
|
|||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||
Таким образом, первый и второй объекты из группы, которые необходимо классифицировать, относятся к классу Х2, так как
102
соответствующее значение вектора решений отрицательно, второй объект относится к Х1.
Следующий способ дискриминации новых объектов заключается в определении расстояния до центра каждого класса. В качестве меры расстояния от нового объекта Х* до класса Хk
используется |
квадрат |
обобщенного |
расстояния |
Махаланобиса |
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
d 2 X * , X |
|
X * X |
|
1 X * X |
|
. В этом |
случае объект |
||||
k |
k |
|
k |
||||||||
|
|
|
|
|
|
|
|
|
|||
относится к классу, расстояние до центра которого, наименьшее. Использование расстояний в качестве критерия определения
принадлежности объекта к классу имеет существенный недостаток: объект может находиться на большом расстоянии от всех классов и отнесение его к более близкому классу может оказаться ошибочным. В этом случае целесообразно использовать вероятностную характеристику, которая позволяет оценить вероятность того, что объект, удаленный на определенное расстояние от центра класса, с определенной вероятностью относится к нему. Формула вероятности принадлежности объекта
Х* к классу Хk имеет вид: |
|
|
|
P X * | X k |
|
|
|
|||
|
|
|
P X |
|
| X |
* |
|
|
, |
|
|
|
|
k |
m |
|
|||||
|
|
|
|
|
|
|
P X * | X l |
|
||
где P X * | X |
|
|
|
|
|
|
l 1 |
|
|
|
l |
- вероятность |
того, что объект |
принадлежит к |
|||||||
|
|
|
|
|
|
|
|
|
|
|
классу Хl, определенная как доля объектов в этом классе, расположенных на большем расстоянии от центра класса, чем объект Х*; l=1,2…, k,…m - номера классов.
Метрика Махаланобиса используется и для оценки качества различения классов. Чем больше квадрат расстояния Махаланобиса между центрами классов, тем больше различаются классы по дискриминантным переменным и лучше проведена дискриминация.
В качестве критерия значимости различий между классами также используется статистика λ-Уилкса. Значение λ-Уилкса вычисляется как отношение определителя матрицы внутриклассовой ковариации к определителю общей ковариационной матрицы. Если показатель принимает значение близкое к единице, то средние значения дискриминантных
103
переменных для разных классов не различаются; если значение близко к нулю, то внутригрупповая дисперсия мала по сравнению с общей дисперсией. Значения показателя близкие к нулю свидетельствуют о хорошем различении классов. Преимуществом использования статистики λ-Уилкса для оценки качества дискриминации является то, что она учитывает как различия между классами, так и однородность каждого класса.
Пошаговый дискриминантный анализ
Проведение дискриминантного анализа сопряжено с определением набора переменных, которые позволяют наилучшим образом различать классы и классифицировать новые объекты. Эта задача решается с помощью последовательного отбора переменных
(пошагового дискриминантного анализа).
Рассмотрим процедуру последовательного отбора дискриминантных переменных, наилучшим образом различающих классы. Прямая процедура последовательного отбора начинается с выбора переменной, обеспечивающей наилучшее одномерное различение классов. На следующем шаге рассматривается сочетание выбранной переменной с остальными переменными. Здесь находится пара, дающая наилучшее двумерное различение классов. Далее процедура переходит к отбору наилучшего набора из трех переменных, две из которых отобраны на предыдущих шагах. На каждом шаге прямой процедуры последовательного отбора отбирается новая переменная, которая в сочетании с ранее полученным набором переменных дает наилучшее различение классов. Процесс продолжается до тех пор, пока не будут рассмотрены все переменные или включение новой переменной даст худшее или такое же различение [3, с. 122].
Процедура последовательного отбора может работать и в обратном направлении: на первом шаге различение проводится одновременно по всем переменным, на последующих шагах из анализа исключаются переменные, наихудшим образом дискриминирующие классы. Прямая и обратная процедуры могут использоваться как самостоятельно, так и совместно, но чаще на практике применяется прямой метод.
104
Для принятия решения о включении или исключении отдельной переменной из анализа рассчитываются значения частных F-статистик (f-включения и f-удаления) и теста толерантности.
Статистика f-включения оценивает улучшение различия между классами в результате включения переменной в анализ по сравнению с различием, достигнутым с помощью других переменных, участвующих в дискриминации. Если значение f- включения с числом степеней свободы (m-1) и (n-p-m+1) (m – количество классов, n – число объектов наблюдений по всем классам, p – количество дискриминантных переменных) меньше соответствующего табличного значения, то включение данной переменной в анализ не улучшает различение классов.
Статистика f-удаления оценивает значимость ухудшения различия классов после удаления переменной из анализа. Если значение f-удаления (m-1, n-p-m+1) больше соответствующего табличного значения, тогда исключение переменной из анализа ухудшает различение классов. Статистика f-удаления также используется для ранжирования дискриминационных способностей переменных.
Толерантность переменной равна единице минус квадрат множественной корреляции между этой переменной и всеми другими переменными, участвующими в анализе. Толерантность является мерой линейной зависимости между переменной и набором других переменных. Значение показателя близкое к нулю свидетельствует о том, что переменная приблизительно является линейной комбинацией одной или нескольких, включенных в анализ. Такую переменную нежелательно использовать в анализе, так как она не несет в себе новой информации.
Решение типовой задачи с помощью ППП Statistica
Задача. У исследователя имеются данные выборочного обследования выпускников, которые окончили школу в предыдущем учебном году, также школьников, выпускающихся в текущем году, по следующим показателям:
х1 – уровень образования матери; х2 – среднемесячный доход на одного члена семьи;
105
х3 – значение, придаваемое наличию высшего образования.
Показатель х1 принимает следующие значения: среднее (полное) – 0, среднее специальное – 1, неоконченное высшее – 2, высшее – 3; показатель х2: до 5 тыс. руб. – 0, до 10 тыс. руб. – 1, до 15 тыс. руб. – 2, до 20 тыс. руб. – 3, до 25 тыс. руб. – 4, свыше 25 тыс. руб. – 5, показатель х3: от 0 до 5 по мере возрастания значимости.
В таблице представлены данные обследования выпускников и школьников. В группу №1 входят выпускники, которые не продолжили обучение после окончания школы, группа № 2 - продолжили обучение в учебных заведениях среднего профессионального образования, группа № 3 - поступили в высшие учебные заведения. Необходимо определить наиболее вероятный выбор каждого школьника.
Таблица 5.1 Результаты обследования выпускников и школьников
|
|
|
Показатели |
|
|
|
|
х1 |
х2 |
х3 |
|
|
группа №1 |
0 |
1 |
2 |
|
|
0 |
2 |
1 |
||
|
|
||||
Выпускники |
группа №2 |
1 |
0 |
3 |
|
2 |
3 |
2 |
|||
|
|
||||
|
группа №3 |
3 |
3 |
3 |
|
|
2 |
4 |
4 |
||
|
|
||||
|
|
1 |
0 |
1 |
|
|
|
2 |
3 |
4 |
|
|
|
2 |
3 |
5 |
|
|
|
2 |
1 |
2 |
|
Школьники |
0 |
2 |
2 |
||
|
|
1 |
2 |
2 |
|
|
|
3 |
0 |
4 |
|
|
|
3 |
4 |
4 |
|
|
|
2 |
1 |
0 |
|
106
Решение:
1.Ввести данные в ППП Statistica путем непосредственного набора данных в рабочий лист (Spreadsheet) или переноса подготовленной таблицы данных из MS Excel. Ввести новую переменную Var 4 (группировочную) в анализ со значениями для группы №1 - 0, группы №2 - 1, группы №3 - 2.
2.Запустить диалоговое окно дискриминантного анализа: открыть меню Статистика (Statistics) и выбрать команду Многомерные исследовательские методы (Multivariate Exploratory Techniques) → Дискриминантный анализ (Discriminant Analysis).
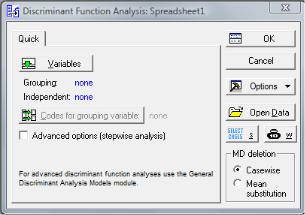
Откроется стартовая панель дискриминантного анализа (рис. 5.1).
Рис. 5.1. Диалоговое окно дискриминантного анализа
3.Выбрать переменные для анализа: на стартовой панели дискриминантного анализа нажать кнопку Переменные (Variables). Откроется окно выбора переменных (рис. 5.2).
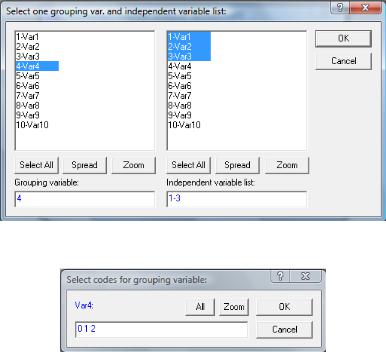
4.В открывшемся окне в качестве группировочной переменной задать Var 4, дискриминантных переменных – Var 1- Var 3. Нажать кнопку Ok.
5.Вернуться в диалоговое окно дискриминантного анализа нажать кнопку Коды группировочной переменной (Codes for grouping variables). В открывшемся окне нажать кнопу Все (All) для
107
выбора всех значений группировочной переменной (рис. 5.3). Нажать кнопку Ok.
Рис. 5.2. Окно выбора переменных для анализа
Рис. 5.3. Окно выбора кодов группировочной переменной
6.В поле Дополнительные параметры (пошаговый анализ)
(Advanced options (stepwise analysis)) установить флажок.
Диалоговое окно дискриминантного анализа примет следующий вид (рис. 5.4). Нажать кнопку Ok.
7.Откроется диалоговое окно задания параметров дискриминантной модели. Для корректного определения параметров модели необходимо просмотреть описательные статистики: перейти на вкладку Описательные (Descriptives) и нажать на кнопку Просмотреть описательные статистики (Review Descriptive Statistics). Откроется панель описательных статистик.
108
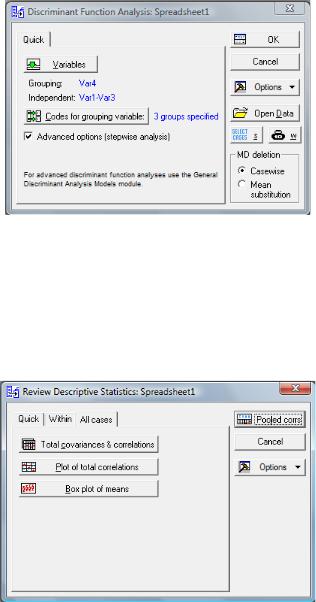
Рис. 5.4. Диалоговое окно дискриминантного анализа
8. На вкладке Все наблюдения (All cases) представлены следующие описательные статистики: Объединенные внутригрупповые ковариации и корреляции (Pooled within-groups covariance&correlations), Поле корреляций (Plot of total correlations), Диаграмма размаха средних значений (Box plot of means) (рис. 5.5).
Рис. 5.5. Описательные статистики
109