

Построение модели
Для анализа было выбрано 20 шуток в жанре one-liner (короткая шутка, длиной в одну строку – line), взятых с ресурсов www.vkontakte.ru и www.bash.org.ru. Они были слегка изменены для облегчения поиска в Национальном корпусе русского языка: некоторые сленгизмы заменены стандартной лексикой (чё/что, комп/компьютер), иностранные слова записаны латиницей (windows, hello world), произведена замена некоторых малоупотребительных с точки зрения корпуса неполных синонимов (переустанавливаю/устанавливаю; приучила/научила).
Теоретико-графовая модель высказывания-шутки в жанре one-liner конструируется следующим образом.
Из всех слов в высказывании составляются все возможные пары.
На базе Национального корпуса русского языка проверяется их встречаемость в корпусе (с сохранением грамматической формы слов, т.е. в той форме, в какой они встретились в тексте шутки).
Пары слов сортируются по показателю их частотности – от наиболее частых к наименее.
Дискриминация пар. Допустим, пара слов – это две вершины, соединенные ребром. Пусть правая вершина будет доминантной, а левая – рецессивной (допустим и обратный порядок). Тогда в выборку войдут все наиболее частотные пары с правой вершиной – словом в высказывании. Менее частотные пары с такими же правыми вершинами отсекаются. Количество доминантных пар будет равно количеству слов в высказывании, если для всех пар с доминантными вершинами статистическая встречаемость в корпусе равна или больше 1. Пары с нулевой встречаемостью не учитываются, а слова, не попавшие в доминантные пары, записываются как изолированные вершины.
Полученные в результате статистического анализа доминантные пары составляют граф.
Разметка вершин. На основе концепции инвективных имен производится разбиение шутки на компоненты и все вершины полученного графа помечаются следующей разметкой: R, r, I, i и т.д.5
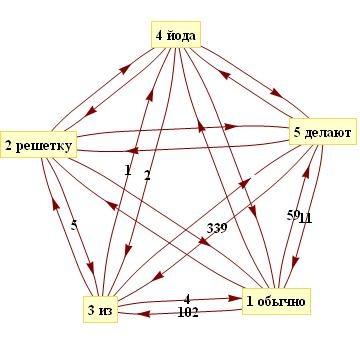
Рассмотрим модель на примере следующей шутки: "Обычно (1) решетку (2) из (3) йода (4) делают (5)". Она раскладывается на пары следующим образом.
Таблица 1. Все возможные комбинации пар слов в шутке
|
I. |
II. |
III. |
IV. |
|
решетку обычно |
из обычно |
йода обычно |
делают обычно |
|
из решетку |
йода решетку |
делают решетку |
обычно решетку |
|
йода из |
делают из |
обычно из |
решетку из |
|
делают йода |
обычно йода |
решетку йода |
из йода |
|
обычно делают |
решетку делают |
из делают |
йода делают |
Если представить данные пары в графической форме в виде помеченного орграфа, то получится пятиконечная фигура, внутри которой все вершины также соединены между собой, причем каждые две вершины соединены двумя параллельными ребрами. Первый и четвертый столбцы таблицы описывают связи между вершинами по внешнему кругу фигуры; второй и третий – внутри фигуры.
Рис. 1. Представление комбинаций слов в виде графа6
Статистический анализ сочетаний слов (табл. 1) в НКРЯ показал, что следующие из них являются коллокациями или встречаются в корпусе, по крайней мере, один раз:
Таблица 2. Дискриминация представленных в корпусе словосочетаний
|
№ |
Словосочетание |
Кол-во употреблений в корпусе |
Дискриминация по правой вершине |
Дискриминация по левой вершине |
|
1. |
делают из |
339 |
x |
x |
|
2. |
обычно из |
102 |
|
x |
|
3. |
обычноделают |
59 |
x |
|
|
4. |
делаютобычно |
11 |
x |
|
|
5. |
решетку из |
5 |
|
x |
|
6. |
изобычно |
4 |
|
x |
|
7. |
йодаиз |
2 |
|
x |
|
8. |
из йода |
1 |
x |
|
При дискриминации пар происходит последовательный выбор одной пары из каждой строки таблицы, так что получившийся граф обязательно будет содержать цикл. Тем не менее, не всегда после дискриминации пар все слова попадают в связные цепочки (например, если все пары с одинаковой доминантной вершиной ни разу не встретились в корпусе) – в таком случае эти слова образуют изолированную вершину, и есть вероятность, что граф окажется деревом. Данный пример в результате дискриминации по правой и левой вершинам дал два графа, в каждом из который есть цикл.
Таким образом, графы, полученные двумя способами дискриминации словосочетаний, выглядят следующим образом:
Рис. 2. Дискриминация по правой вершине
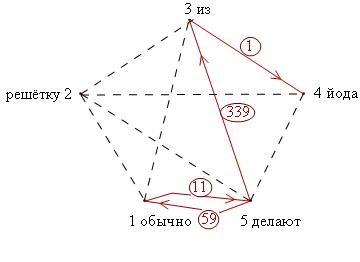
Рис. 3. Дискриминация по левой вершине

Теперь производим разметку вершин по компонентам инвективного имени: Обычно (r1) решетку (r2) из (r3) йода (i) делают (do).
Рис. 4. Граф с размеченными компонентами шутки (дискриминация по правой вершине)
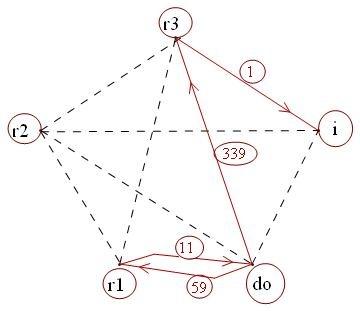
Рис. 5. Граф с размеченными компонентами шутки (дискриминация по правой вершине)
