

6.7.4. Анализ эффективности
Выполним анализ эффективностипараллельного алгоритма умножения матрицы на вектор при обычных уже предположениях, что матрицаАявляется квадратной, т.е.m=n. Будем предполагать также, что процессоры, составляющие многопроцессорную вычислительную систему, образуют прямоугольную решеткуp=s×q(s– количество строк в процессорной решетке,q– количество столбцов).
Общий анализ эффективностиприводит к идеальным показателям параллельного алгоритма:
|
|
(6.16) |
Для уточнения полученных соотношений оценим более точно количество вычислительных операций алгоритма и учтем затраты на выполнение операций передачи данных между процессорами.
Общее время умножения блоков матрицы Аи вектораbможет быть определено как
|
|
(6.17) |
Операция
редукции данных может быть выполнена
с использованием каскадной схемы и
включает, тем самым, log2qитераций передачи сообщений размера![]() .
Как результат, оценка коммуникационных
затрат параллельного алгоритма при
использовании модели Хокни может быть
определена при помощи следующего
выражения
.
Как результат, оценка коммуникационных
затрат параллельного алгоритма при
использовании модели Хокни может быть
определена при помощи следующего
выражения
|
|
(6.18) |
Таким образом, общее время выполнения параллельного алгоритма умножения матрицы на вектор при блочном разделении данных составляет
|
|
(6.19) |
6.7.5. Результаты вычислительных экспериментов
Вычислительные экспериментыдля оценкиэффективностипараллельного алгоритма проводились при тех же условиях, что и ранее выполненные расчеты (см. п. 6.5.5). Результаты экспериментов приведены втаблице 6.5. Вычисления проводились с использованием четырех и девяти процессоров.
Сравнение
экспериментального времени
![]() выполнения
эксперимента и теоретического времениT
p, вычисленного в соответствии
с выражением (6.19), представлено втаблице
6.5и нарис.
6.10.
выполнения
эксперимента и теоретического времениT
p, вычисленного в соответствии
с выражением (6.19), представлено втаблице
6.5и нарис.
6.10.
|
Таблица 6.5. Результаты вычислительных экспериментов по исследованию параллельного алгоритма умножения матрицы на вектор при блочном разделении данных | |||||
|
Размер матриц |
Последовательный алгоритм |
Параллельный алгоритм | |||
|
4 процессора |
9 процессоров | ||||
|
Время |
Ускорение |
Время |
Ускорение | ||
|
1000 |
0,0041 |
0,0028 |
1,4260 |
0,0011 |
3,7998 |
|
2000 |
0,016 |
0,0099 |
1,6127 |
0,0095 |
3,2614 |
|
3000 |
0,031 |
0,0214 |
1,4441 |
0,0095 |
3,2614 |
|
4000 |
0,062 |
0,0381 |
1,6254 |
0,0175 |
3,5420 |
|
5000 |
0,11 |
0,0583 |
1,8860 |
0,0263 |
4,1755 |
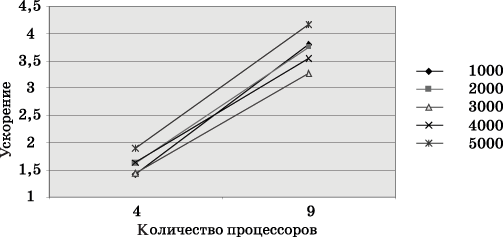
Рис. 6.9. Зависимость ускорения от количества процессоров при выполнении параллельного алгоритма умножения матрицы на вектор (блочное разбиение матрицы) для разных размеров матриц
|
Таблица 6.5. Сравнение экспериментального и теоретического времени выполнения параллельного алгоритма умножения матрицы на вектор при блочном разделении данных | ||||
|
Размер матриц |
Последовательный алгоритм |
Параллельный алгоритм | ||
|
|
|
|
| |
|
1000 |
0,0025 |
0,0028 |
0,0012 |
0,0011 |
|
2000 |
0,0095 |
0,0099 |
0,0043 |
0,0042 |
|
3000 |
0,0212 |
0,0214 |
0,0095 |
0,0095 |
|
4000 |
0,0376 |
0,0381 |
0,0168 |
0,0175 |
|
5000 |
0,0586 |
0,0583 |
0,0262 |
0,0263 |
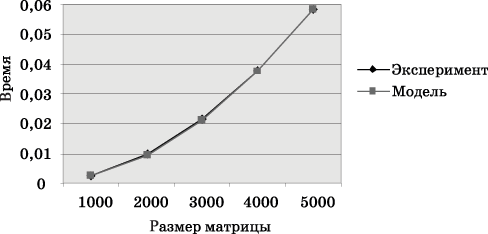
Рис. 6.10. График зависимости экспериментального и теоретического времени проведения эксперимента на четырех процессорах от объема исходных данных (блочное разбиение матрицы)