

5.4.3. Общая передача данных от всех процессов всем процессам
Передача данных от всех процессоввсемпроцессамявляется наиболее общей операцией передачи данных (см.рис. 5.6). Выполнение данной операции может быть обеспечено при помощи функции:
int MPI_Alltoall(void *sbuf,int scount,MPI_Datatype stype,
void *rbuf,int rcount,MPI_Datatype rtype,MPI_Comm comm),
где
sbuf, scount, stype — параметры передаваемых сообщений;
rbuf, rcount, rtype — параметры принимаемых сообщений;
comm — коммуникатор, в рамках которого выполняется передача данных.
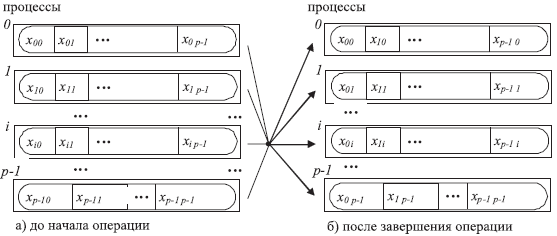
Рис. 5.6. Общая схема операции передачи данных от всех процессов всем процессам
При выполнении функции MPI_Alltoallкаждыйпроцессв коммуникаторе передает данные изscountэлементов каждомупроцессу(общий размер отправляемых сообщений впроцессахдолжен быть равенscount * pэлементов, гдеpесть количествопроцессовв коммуникатореcomm) и принимает сообщения от каждогопроцесса.
Вызов функции MPI_Alltoallпри выполнении операции общего обмена данными должен быть выполнен в каждомпроцессекоммуникатора.
Вариант операции общего обмена данных, когда размеры передаваемых процессамисообщений могут быть различны, обеспечивается при помощи функцийMPI_Alltoallv.
Пример использования функции MPI_Alltoallрассматривается влекции 6при разработкепараллельных программумножения матрицы на вектор как задание для самостоятельного выполнения.
5.4.4. Дополнительные операции редукции данных
Рассмотренная в п. 5.2.3.2 функция MPI_Reduceобеспечивает получение результатов редукции данных только на одномпроцессе. Для получения результатов редукции данных на каждом изпроцессовкоммуникатора необходимо использовать функцию редукции и рассылки:
int MPI_Allreduce(void *sendbuf, void *recvbuf, int count,
MPI_Datatype type, MPI_Op op, MPI_Comm comm),
где
sendbuf — буфер памяти с отправляемым сообщением;
recvbuf — буфер памяти для результирующего сообщения;
count — количество элементов в сообщениях;
type — тип элементов сообщений;
op — операция, которая должна быть выполнена над данными;
comm — коммуникатор, в рамках которого выполняется операция.
Функция MPI_Allreduceвыполняет рассылку междупроцессамивсех результатов операции редукции. Возможность управления распределением этих данных междупроцессамипредоставляется функцийMPI_Reduce_scatter.
И еще один вариант операции сбора и обработки данных, при котором обеспечивается получение всех частичных результатов редуцирования, может быть реализован при помощи функции:
int MPI_Scan(void *sendbuf, void *recvbuf, int count,
MPI_Datatype type, MPI_Op op, MPI_Comm comm),
где
sendbuf — буфер памяти с отправляемым сообщением;
recvbuf — буфер памяти для результирующего сообщения;
count — количество элементов в сообщениях;
type — тип элементов сообщений;
op — операция, которая должна быть выполнена над данными;
comm — коммуникатор, в рамках которого выполняется операция.
Общая
схема выполнения функции MPI_Scanпоказана нарис.
5.7. Элементы получаемых сообщений
представляют собой результаты обработки
соответствующих элементов передаваемыхпроцессамисообщений, при этом для
получения результатов напроцессес рангомi,
0![]() i<n,
используются данные отпроцессов,
ранг которых меньше или равенi,
т.е.
i<n,
используются данные отпроцессов,
ранг которых меньше или равенi,
т.е.
![]()
где
![]() есть
операция, задаваемая при вызове функцииMPI_Scan.
есть
операция, задаваемая при вызове функцииMPI_Scan.
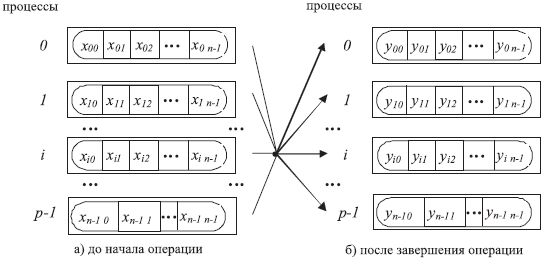
Рис. 5.7. Общая схема операции редукции с получением частичных результатов обработки данных