

Лекции по компьютерной графике
.pdfКлиментьев К.Е. Компьютерная графика (курс лекций).
+1 |
1 |
0 или 3 – нет палитры, 2 или 5 - есть |
+2 |
1 |
1 |
+3 |
1 |
Число байтов на пиксел |
+4 |
2 |
Xmin |
+6 |
2 |
Ymin |
+8 |
2 |
Xmax |
+10 |
2 |
Ymax |
+52 |
1 |
Число цветовых плоскостей |
+53 |
1 |
Число байтов на строку изображения |
4.1.3. МЕТОД ХАФФМАНА
Автор – D.A. Huffman, 1952. Основная идея: часто встречающиеся байты заменяются кодами, состоящими из меньшего количества битов; и наоборот. Основная проблема – как различать коды друг от друга при распаковке.
Пример. Пусть необходимо закодировать слово КОЛОКОЛЬНЯ.
Шаг 1. Рассчитываются частоты встречаемости букв:
О 3/10 = 0.33 К 2/10 = 0.2 Л 2/10 = 0.2 Ь 1/10 = 0.1 Н 1/10 = 0.1 Я 1/10 = 0.1
Шаг 2. Строится двоичное “дерево Хаффмана” по принципу (см. рис. 41):
•листьям соответствуют наиболее редко встречающиеся буквы;
•внутренним узлам соответствуют более частые буквы (чем ближе к корню, тем более частые) или группы букв.
Шаг 3. Все левые ветви помечаются 1, все правые 0 (или наоборот).
Рис. 41. Дерево Хаффмана
Шаг 4. Каждой букве назначается код, соответствующий битам, лежащим на пути от корня к этой букве, например, букве Ь - код 11111; букве Л - код 110; букве О - код 0. Ни один из этих кодов не является префиксом другого, таким образом раскодирование всегда можно выполнить однозначно.
31

Климентьев К.Е. Компьютерная графика (курс лекций).
Шаг 5. Выполняется кодирование слова 10 0 110 0 10 0 110 11111 11110 1110, всего 27 битов. Исходное сообщение было 10х8 = 80 битов, таким образом Ксж = 80/27 = 2.96.
Особенности метода Хаффмана: Ксж тем выше, чем более различны частоты встречаемости кодов сжимаемых данных.
4.1.4. МЕТОД АРИФМЕТИЧЕСКОГО КОДИРОВАНИЯ
Основная идея: представить сжимаемые данные в виде длинной десятичной дроби, а двоичная форма записи таких дробей, как правило, короче десятичной.
Пример. Пусть необходимо закодировать слово КОЛОКОЛЬНЯ.
Шаг 1. Рассчитываются частоты встречаемости букв:
О0.333333
К0.2
Л0.2
Ь0.1
Н0.1
Я0.1
Шаг 2. Берется отрезок единичной длины и делится на части пропорционально частотам встречаемости букв (см. рис. 42).
Буква |
Начало |
Конец |
------------------------------------------------------ |
||
О |
0 |
0.333333 |
К |
0.333333 |
0.333333+0.2=0.533333 |
Л |
0.533333 |
0.533333+0.2=0.733333 |
Ь |
0.733333 |
0.733333+0.1=0.833333 |
Н |
0.833333 |
0.833333+0.1=0.933333 |
Я |
0.933333 |
1.0 |
Рис. 42. Разбиение отрезка при арифметическом кодировании
Шаг 3. Выполняется кодирование слова по алгоритму:
Min := 0;
Max :=1;
For i:=1 to N do begin C := БукваВСлове[i];
∆ := max-min;
Max := min + ∆*Конец(C);
Min := min + ∆*Начало(C); End;
К0.333333 0.533333 О 0.333333 0.400000 Л 0.368888 0.382222 О 0.368888 0.373333
К0.370370 0.371259 О 0.370370 0.370666 Л 0.370528 0.370587 Ь 0.370571 0.370577
32

Климентьев К.Е. Компьютерная графика (курс лекций).
Н 0.370576 0.370577 Я 0.370577 0.370577
Последнее число и есть сжатое слово “КОЛОКОЛЬНЯ”, оно всегда меньше 1, значит достаточно хранить его дробную часть (мантиссу). Двоичный код мантиссы: 110000111101. Коэффициент сжатия 80/12 = 6.66.
Обратное раскодирование выполняется по алгоритму:
N := СжатыеДанные; I:=0;
While NOT Конец do begin
C :=CимволСоотвествующийИнтервалу(N); (* См. рис. 42 *) БукваВСлове[i]:=C;
∆ :=Конец(C) – Начало(С); N := N – Начало(С);
N := N/∆; I:=I+1; End;
4.1.5. МЕТОДЫ LZ77 И LZSS
Авторы: Abraham Lempel и Jakob Ziv, 1977 год. Идея: входной поток данных последовательно просматривается, при этом считается, что он разделен на две части (см. рис. 43):
•словарь – это уже просмотренная часть;
•окно – это небольшой, просматриваемый в текущий момент, фрагмент.
Пример. Пусть необходимо закодировать слово КОЛОКОЛЬНЯ.
Рис. 43. Сжатие данных методом LZ77
Пусть длина окна – 3 символа. Движение окна начинается слева направо, при этом проверяется, не находится ли внутри окна какой-нибудь “образец”, идентичный ранее уже встретившемуся фрагменту. Если нет, то символы копируются на выход без изменения. На рис. 43 показана ситуация, когда такое соответствие обнаружено. В этом случае на выходе записываются: 1) ссылка на первый образец и 2) его длина.
Основная проблема: кодирование “служебной информации”. В алгоритме LZSS (Lempel-Ziv- Storer-Szchimansky) каждые 8 байтов снабжаются префиксным байтом, биты которого указывают позицию “служебных” данных. Например:
<8> К О Л О <-4,3> Ь Н Я
“Служебный” байт со значением “8” в двоичном виде записывается как 00001000 и означает, что первые 4 буквы – обычные, потом идет 1 служебная запись, потом опять 3 обычные буквы.
Особенности алгоритмов LZ77/LZSS:
•хорошо сжимаются данные с повторяющимися фрагментами;
33
Климентьев К.Е. Компьютерная графика (курс лекций).
•с одной стороны, теоретически Ксж возрастает вместе с размером окна;
•с другой стороны, ссылки на длинные совпадения кодируются более громоздкими “служебными” записями, что уменьшает Ксж;
•типичная длина окна, дающая хорошее сжатие, несколько тысяч (например, 4096) байтов.
Различные варианты алгоритма LZSS широко используются в архиваторе ZIP, в стандартных библиотеках LZ32.DLL и пр.
4.1.6. МЕТОД LZW. ФОРМАТ GIF.
Авторы: Abraham Lempel, Jakob Ziv и Terry Welch, 1978 год. Идея сжатия: в процессе обработки входные данные разбиваются на две части: 1) библиотека; 2) каталог. Они и есть сжатые данные. Библиотека состоит из фрагментов исходных данных, каталог содержит ссылки на библиотеку. Алгоритм:
ИнициализироватьБиблиотекуСимволамиАлфавита; While NOT Конец do begin
F := Наидлиннейший фрагмент, присутствующий в библиотеке; K := Символ, следующий за форагментом; ПоместитьВКаталогССылкуНа(F);
ПоместитьВБиблиотеку(F+K); (* Это не сложение, это конкатенация*) CдвинутьсяНаДлину(F+K);
End;
Пример. Пусть необходимо закодировать слово КОЛОКОЛЬНЯ.
Библиотека:={К, Л, О, Ь, Н, Я}; Каталог:={};
Цикл 1. F:=’K’; K:=’О’;
Каталог:= {6}; (* 6 – это ссылка на букву ‘К’ в библиотеке*) Библиотека:={К,Л,О,Ь,Н,Я,<0,2>}; (* 0 и 2 – это ссылки на ‘К’ и ‘О’*)
Цикл 2. F:=’Л’; K:=’О’;
Каталог:= {6,7}; Библиотека:={К,Л,О,Н,Ь,Я,<0,2>,<1,2>};
Цикл 3. F:=’КО’; K:=’Л’;
Каталог:={6,7,6}; Библиотека:{К,Л,О,Н,Ь,Я, <0,2>, <1,2>, <6,1>};
И т.д. Алгоритм требует “раскрутки” и начнет работать хорошо на длинных данных с большой “библиотекой”. LZW считается лучшим по соотношению скорость/сжатие. Он запатентован небольшой компанией Unisys (производитель модемов) и не используется (якобы!) в коммерческих программных продуктах, зато применен в “ничьем” графическом формате .GIF.
34

Климентьев К.Е. Компьютерная графика (курс лекций).
4.2. МЕТОДЫ СЖАТИЯ ДАННЫХ С ЧАСТИЧНОЙ ПОТЕРЕЙ ИНФОРМАЦИИ
4.2.1. СПЕКТРАЛЬНОЕ СЖАТИЕ. ФОРМАТ JPEG.
Информационные сигналы в природе – результат сложения большого количества колебаний (например, звуковых волн) с разными частотами и амплитудами. Разложением сигналов на суммы гармонических функций занимается спектральный анализ:
•сумма синусоид – преобразование Фурье;
•сумма прямоугольных волн – преобразование Уолша;
•сумма косинусоид – косинусное преобразование и т.п.
Органы чувств человека в большей степени реагируют на низкочастотные колебания (они – более информативны!), и в меньшей – на высокочастотные
Пример. Графический формат JPEG (Joint Photographic Experts Group – Объединенная группа экспертов по фотографии).
Шаг 1. Изображение разбивается на квадратики, каждый размером 8х8 пикселов (см. рис. 44,
а).
Шаг 2. Пикселы внутри квадратиков нумеруются “косой змейкой” (см. рис. 44, б) и “вытягиваются” в последовательность чисел (яркостей).
Шаг 3. Эти 64 числа рассматриваются как “сигнал” и к ним применяется дискретное косинусное преобразование, получается спектр.
Шаг 4. В спектре искусственно ослабляются высокочастотные компоненты. Для этого 64 отсчета спектра вновь собираются в матрицу 8х8 и эта матрица делится (почленно!) на матрицу коэффициентов ослабления (см. рис. 44, в). Коэффициенты в матрице не предопределенные, они выбираются самим пользователем в зависимости от желаемой степени сжатия (обычно при помощи “бегунка” в графическом редакторе).
а) разбиение рисунка б) обход матрицы в) матрица ослабления Рис. 44. Этапы алгоритма JPEG
Шаг 5. В “ослабленном” спектре очень много повторяющихся фрагментов, поэтому он дополнительно “дожимается”методом RLE.
4.2.2. ФРАКТАЛЬНОЕ СЖАТИЕ
Фракталы – это самоподобные объекты, обладающие дробной размерностью Хаусдорфа (у точки размерность – 0, у прямой – 1, у плоскости – 2 и пр.). Есть две формы описания фракталов: 1) геометрическая; 2) аналитическая. Геометрически можно описать, например “губку Серпинского”; аналитически можно описать, например, “множество Мандельброта”.
35

Климентьев К.Е. Компьютерная графика (курс лекций).
а) “Губка |
Серпинского” |
б) “Множество Мандельброта” |
|
Рис. 45. Примеры фракталов |
|
Самоподобный элемент фрактала (например, треугольник в “губке Серпинского”) называется аттрактором. Весь фрактал можно описать, задав для единственного аттрактора систему аффинных преобразований: поворотов, сдвигов, изменений масштаба и пр. Для фракталов такая система преобразований называется системой итерирующих функций (IFS). Принцип построения IFS лежит в основе идеи фрактального сжатия изображенй.
Шаг 1. Исходное изображение разбивается на ряд фрагментов (обычно перекрывающихся прямоугольников) - доменов.
Шаг 2. Для каждого домена производится попытка найти на том же изображении более маленький фрагмент – ранговый блок, такой, чтобы его можно было преобразовать в домен при помощи аффинных преобразований (возможно, с изменением яркости). При этом:
•совпадение домена и преобразованного рангового блока на “похожесть” проверяется по критерию среднеквадратичного отклонения: ∑(xдом − xблк )2 < εдоп , где xдом – точка в домене; xблк – точка в блоке; εдоп – пороговое значение “похожести”;
•ранговые блоки просматриваются рекурсивно по методу “квадродерева” – сначала квадрат, потом все четверти квадрата, потом шестнадцатые и т.д.
Рис. 46. Фрактальное сжатие Фрактальное сжатие – очень медленный метод, но позволяет достигать больших Ксж.
4.2.3. ВОЛНОВОЕ (WAVELET) СЖАТИЕ
Основано на wavelet-преобразованиях. Простейшее преобразование: представление пары чисел {p1,p2} в виде {q1,q2}, где q1=(p1+p2)/2 и q2=(p1-p2)/2. Из q1 и q2 всегда можно точно восстановить p1 и p2. Если q1 и q2 – дробные, то их можно округлить до целых, и тогда исходные p1 и p2 восстановятся с некоторой погрешностью. Операцию можно повторять неоднократно, каждый раз теряя часть информации.
36

Климентьев К.Е. Компьютерная графика (курс лекций).
Пример. Исходная последовательность: (30, 10) , (30, 20).
Цикл 1. (20, 10), (25,5). Цикл 2. (15, 5), (15, 10).
Цикл 3. (10, 5), (12, 2) – допустим, решили остановиться. Эти числа записываются меньшим количеством битов, т.е. достигнут Ксж > 1. Теперь пробуем восстановить:
Цикл 3. (15, 5), (14, 10) Цикл 2. (20, 10), (24, 4)
Цикл 1. (30, 10), (28, 20) – восстановили с небольшой погрешностью.
Для изображений лучше модифицировать не пары, а группы соседствующих точек,
например, {p(x,y), p(x+1,y), p(x,y+1), p(x+1,y+1)}. Для этого случая:
q1 = (p(x,y) + p(x+1,y) + p(x,y+1) + p(x+1,y+1))/4;
q2 = (p(x,y) + p(x+1,y) - p(x,y+1) - p(x+1,y+1))/4;
q3 = (p(x,y) - p(x+1,y) + p(x,y+1) - p(x+1,y+1))/4;
d4 = (p(x,y) - p(x+1,y) - p(x,y+1) + p(x+1,y+1))/4.
Если последовательно применять преобразования (с округлениями), то каждый раз исходное изображение оказывается разбито на 4 части (см. рис. 47): изображение, состоящее из q1 - уменьшенная копия исходного; изображение q2 характеризует перепад яркостей по горизонтали; изображение q3 - по вертикали; изображение q4 - по диагонали.
Рис. 47. Иллюстрация wavelet-сжатия
Для реальных изображений по какому-то направлению перепады будут малы, значит, эта часть будет хорошо сжиматься.
ТЕМА 5. РАСПОЗНАВАНИЕ ИЗОБРАЖЕНИЙ
Распознавание изображений - часть более общей задачи распознавания образов. Пример распознавания образов: постановка диагноза по результатам анализов. Примеры распознавания изображений: распознавание отсканированного текста; поиск военной техники на фотографиях со спутника. Образ – формальная модель объекта, набор числовых значений и/или логических признаков. Два класса методов распознавания:
•без предварительного обучения;
•с предварительным обучением.
1. Распознавание без предварительного обучения сводится к задаче классификации (или
таксономии) и решается методами кластерного анализа. Типичный пример: есть множество объектов, надо разбить их на классы, причем число классов заранее неизвестно. Первый рассмотренный объект становится “зародышем” первого класса. Второй рассмотренный объект сравнивается с объектами первого класса (например, по критерию среднеквадратичного отклонения) и, если он “похож”, то добавляется в первый класс; если
37
Климентьев К.Е. Компьютерная графика (курс лекций).
нет, то становится “зародышем” нового класса, и так далее. Полное разбиение на классы достигается после просмотра всего множества объектов.
2. При распознавании с предварительным обучением заранее известно общее количество классов и их типичные представители (“обучающая выборка”). В процессе “обучения” по обучающей выборке строятся обобщенные образы (шаблоны) “типичных” для того или иного класса объектов. Собственно распознавание - сравнение исследуемого объекта с шаблонами и выбор наиболее подходящего класса.
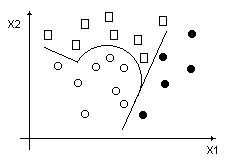
Наглядное представление задачи распознавания. Пространство объектов - многомерное пространства, каждый объект в нем – некая точка с координатами (x1, x2…xN). Задача: построить семейство поверхностей (гиперплоскостей, плоскостей, линий и пр.), разбивающих пространство на требуемое число областей так, чтобы все объекты одного класса оказывались бы вместе (см. рис. 48).
Рис. 48. Разбиение пространства объектов на классы
Методы построения разделяющих поверхностей делятся на два класса:
•структурные;
•неструктурные.
5.1. СТРУКТУРНЫЕ МЕТОДЫ
Считается, что человеку заранее известна “структура” объекта, т.е. отношения между отдельными элементами объекта, и он использует это знание для целенаправленного формирования распознающего алгоритма.
5.1.1. ПРЕДВАРИТЕЛЬНАЯ ПОДГОТОВКА ИЗОБРАЖЕНИЯ
Пусть задано расплывчатое и искаженное цветное изображение.
Шаг 1. Переход из цветовой гаммы (R,G,B) в серую (см. рис. 49, б). Для каждой точки изображения:
Rн =Gн = Bн = 0.3 R + 0.59 G + 0.11 B.
Шаг 2. Улучшение качества изображения. Достигается при помощи “матричных фильтров” (они активно используются в Adobe Fotoshop, Corel Fotopaint и пр.). Над каждой точкой
N / 2 N / 2
C(X,Y) производится преобразование C(X,Y) = A +B ∑ ∑C(X +i,Y + j)*M(X +i,Y + j) ,
i=−N / 2 j=−N / 2
где A и B - некие константы, M - некая матрица размерности (N*2+1)x(N*2+1). Обычно N=1, тогда матрица 3x3, но бывает 5х5, 7х7 и пр. Их много, вот типичные преобразования (см. рис
49):
38

Климентьев К.Е. Компьютерная графика (курс лекций).
а) Исходное б) Серое в) Blur г) Контраст д) Выпуклость Рис. 49. Преобразования изображений
1. Blur - размывание резкости и контрастности с одновременным удалением мелких деталей
1 |
0 |
1 |
(см. рис. 49, в). A=0, B=1/8, M= 0 |
8 |
0 Увеличение контрастности (в пределе - с |
|
0 |
|
1 |
1 |
0 |
−1 |
0 |
выделением контуров) (см. рис. 49, г). A=0, B=1/6, M= −1 |
8 |
−1 . |
|
−1 |
|
0 |
0 |
2. Придание изображению рельефности, выпуклости (см. рис. 49, д). A=32, B=1/2,
−1 |
0 |
0 |
|
M= 0 |
0 |
0 |
. |
|
0 |
|
|
0 |
−1 |
||
Обычно константы A, B и центральное число в матрице подбираются экспериментально.
Шаг 3. Переход из серой гаммы в монохромную (черный + белый), т.е. из полутонового изображения в штриховое. Предположим, что яркости серых точек находятся в интервале
Min=0, Max=63. Алгоритм:
•вводится среднее значение яркости ρ=(Max-Min)/2 = 32;
•яркости точек изображения С(X,Y) пересчитываются: С(X,Y)=|C(X,Y)- ρ|;
•к каждой точке добавляются “кусочки” яркостей от некоторых соседних точек, а от них в свою очередь эти “кусочки” отнимаются (см. рис. 50);
•наконец, каждая точка сравнивается с ρ: если C(X,Y)> ρ, то C(X,Y):=63 (белый), иначе
C(X,Y):=0 (черный).
Рис. 50. Собирание яркостей в кучку Шаг 4. Утончение линий и выделение связных контуров (см. рис. 51).
Рис. 51. Утончение линий и выделение связных контуров
39

Климентьев К.Е. Компьютерная графика (курс лекций).
Есть много алгоритмов (алгоритм Rutovitz, алгоритм Doicsh и пр.). Алгоритм Рутовица:
• вводятся следующие обозначения для точки р и ее соседей (см. рис. 52);
Рис. 52. Обозначения, принятые в алгоритме Рутовица
•для каждой точки p вводится B(p) - число “черных” соседей, и B’(p) - число “крестообразных” “черных”соседей (т.е. диагональные соседи не считаются);
3
• рассчитываются параметры пересеченности R(p)=2*B’(p) и H(p) = ∑b(i) , где b(i)=1, если
i=1
((X(2i)=0 и X(2i+1)=1)) или X(2i+2)=1; иначе b(i)=0;
• точка p удаляется, если B(p)>1, и R(p)=2, и X(0)*(X2)*X(4)=0, и X(6)*X(0)*X(2)=0.
Шаг 5. Векторизация - преобразование штрихового растрового изображения в векторное, в набор аналитических формул. Можно использовать преобразование Хафа (Hough). Вместо декартовой системы координат вводится полярная (см. рис. 53), с координатами (ρ,θ).
Рис. 53. Полярная система координат
Алгоритм преобразования Хафа:
for x:=0 to MaxX do for y:=0 to MaxY do
if p(x,y)=Черная then (* Только для точек, не принадлежащих фону *) for θ:=0 to 2π by ∆θ do begin
ρ := x*cos(θ)+y*sin(θ);
Hough[ρ,θ]:=Hough[ρ,θ]+1; end;
Таким образом матрица {X,Y} переводится в 3-мерную матрицу {ρ,θ, h}, где h - значение функции Хафа. Значения h везде маленькие, кроме точек, в которых пересекаются отрезки прямых. Это позволяет выделять на изображении отрезки, аппроксимирующие “кривые” контуры (см. рис. 54). Есть вариант преобразования Хафа для выделения окружностей и пр.
40