

5.2. Методы архивации
Несмотря на то что объемы внешней памяти ЭВМ постоянно растут, потребность в архивации не уменьшается. Это объясняется тем, что архивация необходима не только для экономии места в памяти, но и для надежного хранения копий ценной информации, а также для быстрой передачи информации по сети на другие ЭВМ.
Кроме того, возможность отказа магнитных носителей информации, разрушающее действие вирусов заставляют пользователей делать резервное копирование ценной информации на другие (запасные) носители информации.
Процесс записи файла в архивный файл называется архивированием (упаковкой, сжатием), а извлечение файла из архива – разархивированием (распаковкой). Упакованный (сжатый) файл называется архивом.
Архивация информации – это такое преобразование информации, при котором объем информации уменьшается, а количество информации остается прежним.
Степень сжатия информации зависит от типа файла, а также от выбранного метода упаковки.
Степень (качество) сжатия файлов характеризуется коэффициентом сжатия Кс, определяемым как отношение объема сжатого файла Vс к объему исходного файла Vo, выраженное в процентах:
![]()
Чем меньше величина Кc, тем выше степень сжатия информации.
Заметим, что в некоторых литературных источниках встречается определение коэффициента сжатия, обратное приведенному отношению.
Проблемы архивации (упаковки) тесно переплетены с проблемами кодирования (замена символов текста двоичными кодами с помощью кодовой таблицы), шифрования (криптография), компрессией звуковых и видеосигналов.
Все используемые методы сжатия информации можно разделить на два класса: упаковка без потерь информации (обратимый алгоритм) и упаковка с потерей информации (необратимый алгоритм). В первом случае исходную информацию можно точно восстановить по имеющейся упакованной информации. Во втором случае распакованное сообщение будет отличаться от исходного сообщения.
В настоящее время разработано много алгоритмов архивации без потерь. Однако все они используют в основном две простые идеи.
Первая идея, основанная на учете частот символов, была разработана Хаффманом (D.A. Huffman) в 1952 г. Она базируется на том факте, что в обычном тексте частоты появления различных символов неодинаковые.
При кодировании символов в ЭВМ используют кодовые таблицы. При этом каждый символ кодируется одним (СР-1251, КОИ-8) либо двумя байтами (Unicode). Кодовые таблицы упрощают процедуру кодирования. Однако для длительного хранения информации или для ее передачи по каналу связи можно использовать более сложную процедуру кодирования, которая обеспечит уменьшение размера файла при сохранении исходной информации.
При упаковке по методу Хаффмана часто встречающиеся символы кодируются короткими последовательностями битов, а более редкие символы – длинными последовательностями. К каждому сжатому архиву прикладывается таблица соответствия имеющихся символов и кодов, заменяющих эти символы.
Рассмотрим пример.
Пусть входной алфавит сообщения состоит всего из четырех символов: а, b, с, d, частоты появления которых в исходном (несжатом) документе равны соответственно, 1/2, 1/4, 1/8 и 1/8. Кодирование Хаффмана для этого алфавита задается табл:
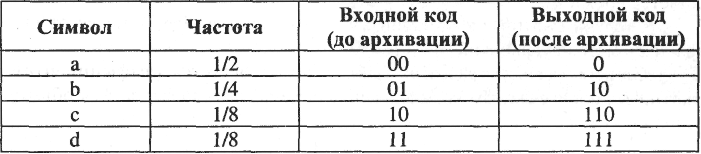
Текст abbadaca, представленный на входе кодом 00 01 01 00 11 00 10 00, после архивации будет иметь вид: 0 10 10 0 111 0 1100. Таким образом, 16 битов исходного текста превратились в 14 битов упакованной информации. Заметим, что указанные в таблице частоты не отражают реальной статистической картины частот появления букв английского алфавита, а взяты такими лишь для иллюстрации данной идеи (только для учебных целей).
Сжатие данных по методу Хаффмана производится в следующей последовательности .
Вначале производится анализ частоты повторения каждого символа сообщения. Затем наиболее часто встречающийся символ заменяется самым коротким кодом, а следующий по частоте появления символ кодируется более длинной последовательностью и т. д. К архиву прикладывается таблица соответствия сжатых и несжатых символов.
Вторая основная идея упаковки состоит в использовании того факта, что в сообщениях часто встречаются несколько подряд идущих одинаковых байтов, а некоторые последовательности байтов повторяются многократно. При упаковке такие места можно заменить командами вида «повторить данный байт п раз» или «взять часть текста длиной k байтов, которая встречалась т байтов назад». Такой алгоритм архивации носит имя RLE (Run Length Encoding – кодирование путем учета повторений).
При упаковке графической информации чаще встречается первая ситуация, а при упаковке текстов – вторая ситуация.
Понять идею этого метода упаковки позволяет следующий анекдот.
Один в прошлом известный полководец решил написать достаточно объемные мемуары. Составленные воспоминания звучали примерно так.
«Утром я вскочил на своего коня и помчался в штаб армии. Подковы коня издавали звук «цок-цок-цок-цок-цок-цок-цок-цок-цок-цок-цок-цок-цок-цок-цок-цок ...». Через двое суток я соскочил с коня и вошел в штаб».
Для увеличения объема литературного произведения словосочетание «цок» было написано «писателем» на двухстах страницах. Очевидно, что информативность «мемуаров» не изменилась бы, если вместо 200 страниц перечисления цокающих звуков было бы указано: «Затем следуют 64 000 раз звуки «цок-цок».
Проиллюстрируем эту же идею другим примером.
Пусть имеется следующее изображение звездного неба: на черном фоне видны редкие белые звезды. При растровом представлении неба информация в ЭВМ будет храниться в таком виде: черное-черное-черное-черное-черное-белое-черное-черное-черное-черное-черное и т. д.
Естественно, что значительно компактнее хранить информацию, указав, сколько раз подряд идут черные пиксели, сколько раз белые и т. д. Рассмотрим детально метод упаковки – RLE.
Упакованная этим методом последовательность состоит из управляющих байтов, за которым следуют один или несколько байтов данных. При этом если старший бит управляющего байта равен 1, то следующий байт данных нужно повторить при распаковке столько раз, сколько указано в оставшихся 7 байтах управляющего байта. Например, управляющий байт 10001001 говорит, что следующий за ним байт нужно повторить 9 раз, так как 10012 = 910.
Если старший бит управляющего байта равен 0, то при распаковке надо взять следующие байты без изменений. Число байтов, которые берутся без изменений, указывается в оставшихся 7 битах. Например, управляющий байт 00000011 говорит, что следующие за ним 3 байта нужно взять без изменений.

Рассмотрим пример архивации методом RLE.
Пусть дана не запакованная последовательность из 12 байтов:
![]()
В начале последовательности 5 раз подряд повторяется байт 11111111. Чтобы упаковать эти 5 байтов, нужно записать сначала управляющий байт 10000101, а затем повторяемый байт 11111111. В результате архивации выигрыш составит 3 байта. Далее идут 3 разных (неповторяющихся) байта 11110000 00001111 и 11000011. Чтобы их упаковать, нужно записать управляющий байт 00000011, а затем эти 3 байта. В результате архивации этого фрагмента последовательности получается проигрыш (увеличение объема архива) на 1 байт. Далее в последовательности 4 раза повторяется байт 10101010. Для архивации этого фрагмента нужно сформировать управляющий байт 10000100 и записать повторяемый байт 10101010. Сжатие последнего фрагмента даст выигрыш 2 байта.
В результате упаковки получена новая последовательность из 8 байтов:
![]()
Таким образом, 12 байтов удалось сжать до 8 байтов.
Данный метод может успешно использоваться для сжатия растровых графических изображений (BMP, PCX, TIP, GIF), так как картинки и фотографии содержат много повторяющихся байтов. Недостатком метода RLE является низкая степень сжатия файлов с малым числом повторяющихся байтов.
На рисунке показан пользовательский интерфейс одного из наиболее популярных архиваторов – WinZip.
Выделим важные возможности архиваторов:

создание многотомных архивов с возможностью задания произвольного размера тома;
создание самораспаковывающихся SFX-архивов;
создание пароля для доступа к архиву.