

3. Выборочная функция распределения.
Функция распределения
![]() случайной величиныX
обычно неизвестна, в лучшем случае она
известна с точностью до некоторых
неизвестных параметров. Сведения о
распределении случайной величины и ее
характеристиках можно получить, если
имеются независимые многократные
повторения опыта, в котором измеряются
значения интересующей нас случайной
величины.
случайной величиныX
обычно неизвестна, в лучшем случае она
известна с точностью до некоторых
неизвестных параметров. Сведения о
распределении случайной величины и ее
характеристиках можно получить, если
имеются независимые многократные
повторения опыта, в котором измеряются
значения интересующей нас случайной
величины.
Предположим, что
независимые наблюдения над случайной
величиной X
позволили получить выборочную совокупность
![]() объемаn.
объемаn.
Выборочной
(эмпирической) функцией распределения
случайной величины X,
построенной по выборке
![]() ,
называется функцияFn(x),
равная доле таких значений xi,
что xix,
i=1,2,...,n.
Иначе говоря, Fn(x)
есть частота события (xix)
в выборке
,
называется функцияFn(x),
равная доле таких значений xi,
что xix,
i=1,2,...,n.
Иначе говоря, Fn(x)
есть частота события (xix)
в выборке
![]() .
Таким образом, эмпирическую функцию
выборки
.
Таким образом, эмпирическую функцию
выборки![]() можно рассматривать как функцию
распределения вероятностей, где каждому
значениюxi,
i=1,2,...,n
приписана вероятность
можно рассматривать как функцию
распределения вероятностей, где каждому
значениюxi,
i=1,2,...,n
приписана вероятность
![]() .
Установлено, что с ростом объема выборкиn
эмпирическая функция распределения
равномерно по x
приближается к функции распределения
случайной величины X,
то есть
.
Установлено, что с ростом объема выборкиn
эмпирическая функция распределения
равномерно по x
приближается к функции распределения
случайной величины X,
то есть
![]() при
при![]() с вероятностью 1.
с вероятностью 1.
Кроме эмпирической функции распределения случайную величину X характеризуют также и численные показатели, которые можно разбить на три группы:
характеристики положения,
характеристики разброса,
характеристики асимметрии и эксцесса.
К характеристикам положения относятся:
- выборочное среднее
(среднее арифметическое)
![]() ,
,
- выборочная медиана
- корень уравнения
![]() ,
,
- выборочная мода - наиболее часто встречающееся значение в выборке,
- выборочное среднее
геометрическое значение
![]() .
.
Эти характеристики показывают, где находится центр группирования статистических данных.
К характеристикам разброса относятся:
- выборочная
дисперсия (правильнее говорить,
несмещенная оценка выборочной дисперсии)
![]() ,
,
- выборочное среднее
квадратическое отклонение
![]() ,
,
- коэффициент
вариации
![]() ,
,
- минимальное
значение - наименьшее значение в выборке
![]() ,
,
- максимальное
значение - наибольшее значение в выборке
![]() ,
,
- размах - разность
между максимальным и минимальным
значениями
![]() ,
,
- нижняя квартиль
- корень уравнения
![]() ,
,
- верхняя квартиль
- корень уравнения
![]() ,
,
- межквартильный размах - разность между верхним и нижним квартилями.
Дисперсия, среднее квадратическое отклонение, размах и квартили характеризуют разброс или степень рассеяния статистических данных.
Коэффициент асимметрии определяет насколько асимметрично распределение данных. Положительные значения асимметрии говорят о том, что кривая распределения смещена вправо от среднего значения выборки, а отрицательная - влево.
Коэффициент эксцесса показывает однородным или неоднородным является распределение данных по отношению к нормальному (гауссову) распределению. Для нормального распределения коэффициент эксцесса равен нулю. Если коэффициент эксцесса отрицательный, то кривая будет плоской с короткими «хвостами». Если коэффициент положительный, то кривая либо очень крутая в центре, либо имеет довольно длинные «хвосты».
4. Первичная обработка статистических данных.
Как правило, выборка содержит большое число экспериментальных данных. Чтобы ее сделать более компактной, а также для наглядного представления данных используют группировку. Числовая ось разбивается на промежутки, и для каждого промежутка подсчитывается число элементов выборки, которые в него попали. Укажем порядок группировки данных.
Среди элементов выборки определяется минимальное и максимальное значения.
Вычисляется размах выборки.
Выбирается количество групп k, удовлетворяющее неравенству 6k20; иногда оно определяется по формуле k=[5lgn].
Находится длина промежутка по формуле
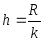
Определяются границы промежутков:
![]() (рис.4).
(рис.4).
Р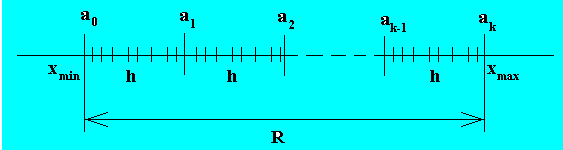 ис.4.
ис.4.
Для каждого
промежутка
![]() находятся
находятся
- число выборочных значений (частоты), попавших в промежуток,
- относительные
частоты
![]() ,
,
- накопленные
частоты
![]() ,
,
- накопленные
относительные частоты
![]() .
.
Полученные данные заносятся в табл.2.
Таблица 2

В таблицу включен еще столбец со средними значениями каждого интервала
![]() .
.
Данные, собранные в таблицу, нуждаются в наглядном представлении. Формами такого наглядного представления являются
полигоны частот - графическая зависимость (относительных) частот от середин интервалов,
графики накопленных частот - график зависимости накопленных (относительных) частот от середин интервалов,
гистограмма - графическое изображение зависимости плотности относительных частот
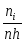 от соответствующего интервала
группировки. В этом случае площадь
гистограммы равна единице, и она может
служить аналогом плотности распределения
вероятностей.
от соответствующего интервала
группировки. В этом случае площадь
гистограммы равна единице, и она может
служить аналогом плотности распределения
вероятностей.
Величина интервала группировки h существенно влияет на общий вид гистограммы. Если h мало, то влияние случайных колебаний начинает преобладать, так как каждый интервал содержит при этом лишь небольшое число наблюдений.
Если все данные разбиты на группы, то выборочные характеристики можно вычислять по более простым формулам. Так выборочное среднее и выборочная дисперсия определяется по формулам
![]() ,
,
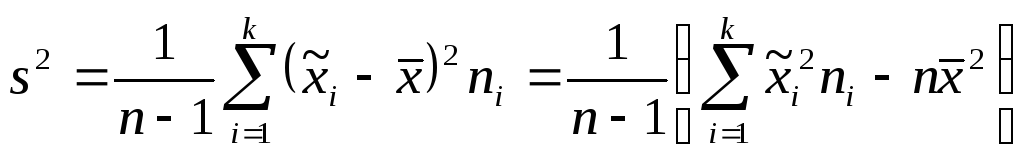 .
.
Пример. Генеральная совокупность X - месячный объем выпуска продукции. За 10 месяцев работы получены следующие значения (в стоимостном выражении) объемов выпуска продукции: 6; 5,5; 1,3; 4,1; 8,5; 5,8; 7,5; 6,3; 3,7; 4,4 млн.руб. Требуется
провести первичную обработку этих статистических данных;
определить основные выборочные характеристики.
Находим минимальное
и максимальное значения выборки:
![]() ,
,![]() .
Эти значения соответственно уменьшим
и увеличим до ближайших целых чисел: 1
и 9. Размах выборки
.
Эти значения соответственно уменьшим
и увеличим до ближайших целых чисел: 1
и 9. Размах выборки![]() .
Примемk=4,
тогда длина частичного интервала равна
.
Примемk=4,
тогда длина частичного интервала равна
![]() .
Определяем границы промежутков:
.
Определяем границы промежутков:
![]() .
.
Составляем таблицу распределения частот
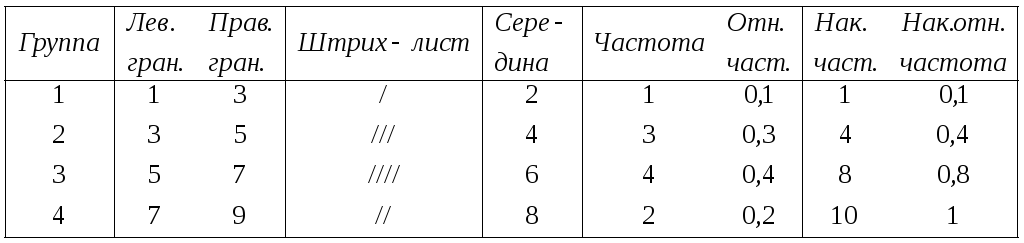
По данным таблицы построим графики, изображенные на рис.5, 6 и 7.
Р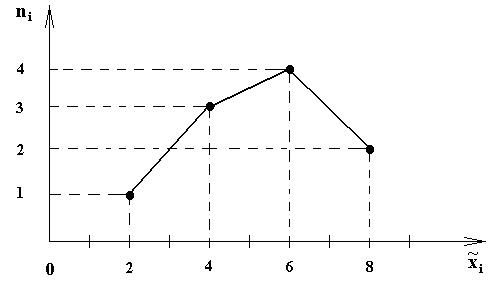 ис.5.
Полигон частот
ис.5.
Полигон частот
Р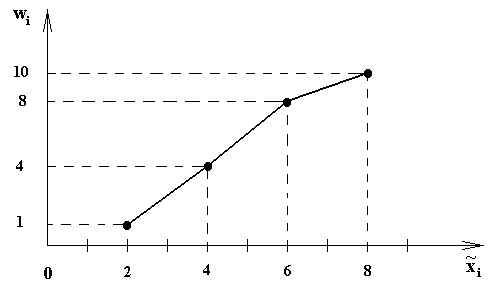
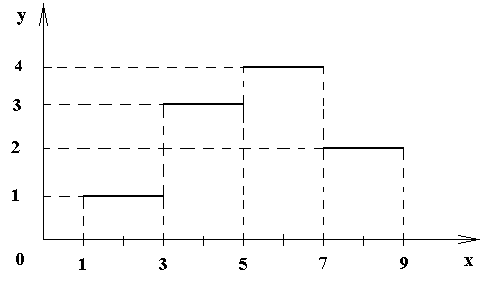 ис.6.
Кумулята частот
ис.6.
Кумулята частот
Рис.7. Гистограмма частот
Находим выборочные характеристики: выборочное среднее
![]() млн.руб.,
млн.руб.,
выборочная дисперсия
![]() млн.руб.
млн.руб.![]() ,
,
выборочное среднее квадратическое отклонение
![]() млн.руб.,
млн.руб.,
выборочный коэффициент вариации
![]() .
.
Так как коэффициент вариации больше 35%, можно сделать вывод о том, что изучаемая совокупность объемов выпуска продукции не является однородной.