

§12.9. Архитектура конвейерных систем.
Независимо от цели проектирования, большинство современных конвейерных векторов систем имеет общую архитектуру, показанную на рисунке 12.36.
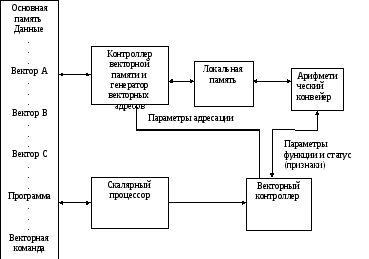
Рисунок 12.36.
Основная память -единая память, содержащая как команды, так и данные в векторных и невекторных формах. Однако поскольку запросное отношение (число обращений на один синхроимпульс ) при использовании векторных команд оказывается гораздо более высоким, организация основной памяти существенно сложнее. Такая память, как правило, сильно расслоена.
Для всякой программы имеется (помимо векторных команд), необходимость в скалярных командах. К ним относятся тесты, операции зависящие от данных, операции ввода вывода, общее управление программой, управление памятью, функции операционной системы, а также определение векторов и настроек на них конвейера. Эти потребности лучше всего обеспечиваются традиционным набором команд. Поэтому в состав конвейерных векторных систем входит скалярный процессор.
Как только векторная команда выбрала вектор, контроллер берет все дальнейшее на себя. В функции этого устройства входит декодирование векторных команд, вычисление параметров адресации операндов, настройка генератора векторных адресов памяти и самого арифметического контроллера и отслеживание исполнения векторных команд. После завершения команды векторный контроллер выполняет все требуемые операции по очистке и выработке признака состояния.
Генератор векторных адресов памяти и контроллер, ответственный за преобразование параметров адресации, сгенерированных векторных контроллером на основе векторной команды, в серию запросов к основной памяти.
В силу различия между операциями векторного контроллера памяти, который за один такт обращается к относительно длинным сегментам векторов и самого арифметического конвейера, которому за один такт нужно иметь по одному операнду от каждого из нескольких входных векторов, большинство векторных процессоров содержит локальную память, которая работает, как буфер.
Арифметический конвейер –это аппаратное устройство, в котором, фактически выполняются арифметические действия, связанные с векторными командами. Конвейерное устройство может быть одно или несколько, при этом с изменяемой конфигурацией. Однако, во время использования отдельной векторной команды все устройства являются обычно устройствами со статической конфигурацией и выполняют повторные инициации желаемой таблицы занятости.
В заключении отметим, что эта типовая архитектура проявляет конвейерные свойства и способность к перекрытию не только на уровне арифметического конвейера. В то время, когда одна или несколько векторных команд используются векторными контроллерами, можно подготавливать следующую векторную команду, тогда как скалярный процессор может исполнять команды для обеспечения очередной векторной команды.
Структура команд.
Любая команда, скалярная или векторная, должна задать информацию, по меньшей мере, четырех общих типов:
функцию, которая должна быть исполнена;
операнды, которые должны быть использованы;
статус, который должен быть зафиксирован;
следующую команду, которая должна быть исполнена.
Задание функции (кода операции), эквивалентно выбору той таблицы занятости, которая должна использовать арифметический конвейер, когда данные будут в наличии.
Обычно это задание является двоично-кодированным индексом, значение которого используется векторным контроллером для выбора, как хранимой где-то таблицы занятости, так и соответствующей ей последовательности инициаций. Эти таблицы занятости и последовательности инициаций реализуются обычно либо аппаратно, либо микропрограммно и не могут непосредственно изменяться машинными командами. Хотя общее число типов операций векторного процессора может быть сравнительно небольшим, все же число векторных кодов операции в два или три раза превышает число сопоставимых с ним скалярных кодов. Причина в том, что если для скалярного процессора имеется только один способ выполнить сложение, а именно сложить данные имеющиеся на двух входах, то в случае сложения векторов допустимо несколько вариантов: поэлементная операция, редукционные команды, которые при сложении векторов вырабатывают единственный выходной скаляр и т.п.
Существенное различие между векторными и невекторными командами состоит в спецификации операндов. В невекторной команде операнд либо задаётся неявно (в аккумуляторе), либо может находиться в одном из доступных программисту регистров, либо является словом памяти, адрес которого вычисляется по базовому индексу или смещению.
Типичный формат команды - двухадресный. В векторной машине операнд может состоять из многих элементов, а его длину обычно нельзя предсказать. Вследствие этого почти все элементы векторного процессора хранят свои операнды в памяти. Это означает, что форматы большинства векторных команд трехадресные (два входа, один результат), причем каждое адресное поле задает отдельную область памяти. Неявная адресация встречается весьма редко. В типичной векторной команде имеется несколько адресных полей памяти и любое из них должно задать гораздо больше информации, чем в случае невекторных команд. В эту информацию входит: начало вектора в памяти, размерность вектора (например, одномерная решетка или двумерная матрица), число градаций по каждой размерности (размер), тип данных (целое число, плавающая запятая, полуслово или байт), расположение элементов в памяти. По целому ряду причин элементы векторов не всегда попадают в смежные слова памяти. В качестве примера можно привести обращение к столбцу матрицы, хранимой по строкам, т.е. важным является расположение элементов памяти.
Помимо выполнения заданной функции, типичная скалярная команда, такая как сложение, обнаруживает и фиксирует информацию о статусе (признак). Имеется, по меньшей мере, два рода такой информации. Первый относится к таким свойствам, как знак результата или равенство его нулю. Второй указывает на зависящие от данных ошибки (переполнения, деление на нуль и т.п.). Признаки запоминаются в специальных регистрах - регистре признаков. Затем команды перехода проверяют содержимое этих разрядов. Обнаружение состояний, к которым приводят ошибки, зависящие от данных, вызывает прерывание, приводящее к выходу из исполняемой программы на специальную подпрограмму, обрабатывающую прерывание.
Векторные команды должны оперировать с признаком такого же рода, но поскольку они имеют дело не с одноэлементным, а с многоэлементным результатом, для них используются другие методы. Например, было предложено, по меньшей мере, четыре способа оперирования с признаком таким как равенство результата нулю. Первый способ состоит в том, чтобы расширить состав информации в регистре, аналогичном регистру признаков, и помещать в него информацию о том, что ни один из результатов не равен нулю, или что некоторые результаты равны нулю, или что все они равны нулю. Второй способ заключается в регистрации числа нулей и места, где встречается первый из них. Третий способ состоит в формировании вектора кодов признаков, вследствие чего каждый элемент на выходе будет иметь не только значение, но и связанный с ним его собственный код признаков. Для этого требуется, что бы векторные команды содержали не только адресацию результатов, но и адресацию вектора признаков. Наконец, распространенный подход состоит в том, чтобы признаки вообще не запоминаются . Вместо этого, набор команд расширяется векторными командами типа: «сравнить векторы на равенство», «проверить на отрицательность». Каждая из этих команд принимает входные векторные операнды и вырабатывает на выходе другой вектор, имеющий ту же длину, что и входной, но такой, что каждый элемент в нем является отдельным разрядом фиксирующим результат проверок. Такие вектора называются двоичными векторами. Как только в архитектуру включаются двоичные вектора, становится потенциально полезным целый набор дополнительных команд. Сюда относятся полный набор векторных логических операций, которые производят поэлементные логические операции. Эти команды позволяют покаскадно осуществлять проверки. Например, найти все элементы вектора X, значения которых равны нулю или отрицательны, но не превышают соответствующих значений элементов вектора Y.
Обработка особых состояний в случае векторных команд также отличается от их обработки в случае скалярных команд, потому, что векторная команда выполняет более одной операции. В конвейерной машине в момент обнаружения одной ошибки может использоваться несколько инициаций соответствующих таблиц занятости и может оказаться неосуществимым «мягкий» останов процесса, после которого вычисления могли бы начаться с помощью подпрограммы, выполняющей исправления. Поэтому, управляющую информацию, задаваемую программистом, можно расширить так, чтобы она содержала разряды, предписывающие аппаратуре фиксировать события, но продолжать исполнение команды и накладывать на выходные данные «заплаты» некоторым стандартным способом. Типичный способ наложения «заплат» может состоять в замене результата нулём, если произошло переполнение в сторону младших разрядов, или замене его максимально большим числом, которое можно представить в разрядной сетке машины.
Даже простая фиксация особого состояния создает в векторном процессоре проблемы с организацией работы. Расширенный скалярный код признаков может показать, имеются ли ошибки, и быть может, где произошла одна из них, но он не покажет, сколько всего было ошибок и где произошли остальные. Вектор кодов признаков может показать, где именно произошли ошибки в многих векторных командах, но он бесполезен, когда каждый результат зависит от нескольких операций и от нескольких или даже всех входных данных (скалярное, матричное умножение). Поэтому большинство векторных архитектур в таких случаях либо прекращает выполнение команд, либо производят некоторые автоматические исправления и продолжают её исполнение, причем пользователю выдается, самое большее, расширенный код признаков.
Есть еще некоторые особенности в векторных конвейерных системах. К ним относятся заполнение и специальный формат данных - векторный с плавающей запятой.
Заполнение – это автоматическое удлинение вектора для уравнивания его длины с длиной некоторого другого вектора, который также служит входным для одной и той же команды. Здесь используются два метода: либо последний элемент повторяется столько раз, сколько нужно, либо производится заполнение нулями.
Использование специального формата данных – векторного с плавающей запятой - заключается в следующем. Стандартное представления числа с плавающей запятой содержит три компонента: знак, порядок и мантиссу. Однако, если известно, что элементы вектора примерно одинаковы, то можно достичь экономии памяти, если использовать единый порядок во всех элементах вектора. Как правило, этот общий порядок должен быть наибольшим из порядков, используемых любым элементом вектора. Можно использовать память, сэкономленную благодаря устранению индивидуального порядка для расширения мантисс. Это значительно повышает относительную точность представления чисел.
Способы адресации векторов.
Производительность векторных команд очень часто полностью определяет скоростью, с которой операнды могут извлекаться из основной памяти, а производительность арифметического конвейера оказывает на неё лишь второстепенное воздействие. Поэтому способы адресации имеют большое значение. Имеются два общих класса адресации векторов: плотный/регулярный и разряженный. Первый соответствует случаю, когда схемы расположения данных в памяти более или менее известны заранее. Второй – случаю, когда желаемая схема расположения данных должна вычисляться динамически.
Плотные/ регулярные схемы адресации. Обычный метод хранения векторов в памяти, при котором соседние элементы хранятся в ячейках, адреса которых достаточно близки и структурно упорядочены, называются плотным или регулярным. Имеются три разновидности таких схем: последовательные, непоследовательные но регулярные, подматричные. При последовательном способе соседние элементы вектора хранятся в соседних ячейках. Так, если элемент V(i) хранится в ячейке k, то V(i+1) в ячейке k+1 и так далее. Это можно распространить на двумерные матрицы одним из двух способов: размещение по строкам (строка занимает N последовательных ячеек, а сами строки также хранятся последовательно) или размещение по столбцам (аналогичное).
Следующий способ используется, когда нужен столбец матрицы, хранимой по строкам или нужна строка, хранимая по столбцам. В этом случае соседние элементы расположены не в последовательных ячейках, а по регулярной схеме: по одному элементу в каждом N слове (матрица RxN). Генератор векторных адресов должен сгенерировать серию адресов, значение которых отличается от N. Поскольку матрицы могут быть разные, значение N должно быть включено в команду.
При третьем способе требуется обращение, упорядоченное по строкам, к подматрице mxn матрицы RxN, хранимой по строкам. Здесь требуется m наборов по n последовательных адресов, причем начало любого набора на N единиц больше начала предыдущего. Это соответствует чтению n последовательных слов, пропуску следующих N-n ячеек и снова чтению. Этот способ требует включения в векторную команду двух параметров: n и N-n или некоторой их разновидности. Время доступа к вектору при любом из этих способов сильно зависит от структуры памяти (простое или сложное расслоение).
Разрешенные схемы адресации. Хотя схемы адресации, описанные выше, являются самыми распространенными, все же во многих приложениях они являются непригодными и неэффективными. К таким приложениям относятся: операции, зависящие от данных, обработка разреженных векторов, косвенный просмотр таблиц. В операциях, зависящих от данных, участие элемента вектора в операции зависит от его значения, у разреженных векторов большинство значений равно нулю. Хранение полного вектора в таких задачах требует огромных объемов памяти и сильно снижает потенциальную производительность, так как большинство операций тривиально (в них участвуют одни нули).
Все эти приложения требуют методов доступа, называемых разреженной адресацией. Двумя, наиболее распространенными средствами, обеспечивающими такую адресацию, являются двоичные векторы и векторы индексов.
Двоичный вектор имеет в качестве компонент 1 или 0.
Имеются три способа встраивания управления на основе двоичного вектора в векторные команды: селективное запоминание, сжатие, расширение.
При селективном запоминании векторная команда содержит для выходного вектора не только его адрес, но и двоичный вектор такой же длины. I-я компонента выходного вектора запоминается в том случае, если i-ый разряд двоичного вектора содержит единицу. Если в разряде находится нуль, то запоминание блокируется, и соответствующие значения в памяти остаются неизменными. Операции сжатия и расширения являются взаимно обратными. При сжатии (таблица 4) двоичный вектор имеет такую же длину, как и вектор данных. При этом используются только те компоненты вектора данных, для которых соответствующий разряд двоичного вектора равен единице. При этом сильно сокращается количество данных, подаваемых, например, на конвейер.
Операция расширения (таблица 5) расширяет вектор данных до размерности двоичного вектора.
|
Таблица 4. |
Таблица 5. | ||||||||||||
|
Вектор данных Двоичный вектор После расширения
1.1
4.4
5.5 8.8
1
0
0
1
1
0
0 1
1.1
0
0
4.4
5.5
0
0 8.8 | ||||||||||||
|
Сжатие данных. |
Расширение данных. |
Однако реализация двоичных векторов имеет свои последствия. Структура генератора векторных адресов является более сложной, так как генератор должен получать доступ к двоичным векторам и использовать их для своих целей: просмотр и генерация адресов памяти. Кроме того, структура арифметического конвейера также должна быть расширена для генерирования двоичных векторов и для операций над ними (И, ИЛИ, сравнение). Необходим расширенный набор команд управляющих двоичными векторами.
Второй основной метод разреженного доступа – это использование векторов индексов разрежения, являющихся векторами, составленными из чисел, используемых либо непосредственно как адреса памяти, либо как смещения по отношению к некоторому указателю памяти.
Доступ к вектору при управлении с помощью индексов разрежения включает в себя чтение элементов вектора индексов разрежения и применения его для образования другого адреса памяти, указывающего фактические данные.
Здесь также возможно несколько основных вариантов, включая разреженное сдваивание и селективное чтение /запись.
При разреженном сдваивании вектор индексов указывает, какие элементы векторных данных не равны нулю. Не нулевые значения хранятся как отдельный вектор данных той же длины, что и у вектора индекса (таблица 6).
Таблица 6.
|
Вектор индексов |
Вектор данных |
Эквивалентное представление |
|
1 3 7 8 |
3.1 4.7 3.14 2 |
3.1 0 4.7 0 0 0 3.14 2 0 . . . |
Разреженное сдваивание.
Селективное чтение/запись сходно со сжатием и расширением под управлением двоичных векторов (таблица 7). Каждый элемент вектора индексов указывает номер компоненты вектора данных.
Вектор индексов обеспечивает единственный и эффективный способ реализации просмотра таблиц.
Таблица 7.
|
Вектор данных |
Вектор индексов |
После сжатия |
|
1.1 2.2 3.3 4.4 5.5 6.6 7.7 8.8 |
1 4 5 8 1 |
1.1 4.4 5.5 8.8 |
Сжатие с помощью векторных индексов.
Полная реализация векторов индексов (таблица 8) еще более сложна, чем реализация двоичного вектора, так как генератор векторных адресов должен выполнять два доступа памяти на одно слово данных: один доступ для вектора индексов, второй для данных. Кроме того генератор векторных адресов должен также складывать базы, сравнивать наборы индексов и объединять их. Таким образом, генератор векторных адресов сам становится подобным целому векторному процессору.
Таблица 8.
|
Вектор данных |
Векторных индексов |
После расширения |
|
1.1 4.4 5.5 8.8 |
1 4 5 8 |
1.1 0* 0* 4.4 5.5 0* 0* 8.8 |
Расширение с помощью векторных индексов.
* - в зависимости от реализации эти значения могут быть и старыми.