

1-41_СИИ
.docx|
32. Эволюционные вычисления. Генетические алгоритмы. Генетические алгоритмы(ГА) - это простая модель эволюции в природе, реализованная в виде компьютерной программы и воспроизводящая механизмы естественного отбора и генетического наследования, которые происходят в процессе эволюции живых организмов. Назначение ГА: применяются для решения поисковых задач, которые имеют большое пространство в поисках решения с целью уменьшения этого пространства поиска. Наиболее распространенное применение- решение задач оптимизации. Основные понятия генетических алгоритмов Хромосома- вектор из нулей и единиц, каждая позиция которых называется геном. Особь(индивидуум)- это генотип(структура)=набор хромосом, который является решением задачи в закодированном виде, иначе это точка в пространстве поиска. Популяция- это множество особей. Фенотип- набор декодированных вариантов решения задачи(соответствует определенному генотипу). Crossover- операция скрещивания хромосом, при котором хромосомы обмениваются своими частями. Мутация- случайное изменение одной или нескольких позиций в хромосоме(значение гена- аллель). Функция приспособленности(fitness function): =функция оценки, это мера приспособленности данной особи в популяции. Именно она позволяет выбирать наиболее приспособленные особи. Виды функции приспособленности:
Локус- позиция гена в хромосоме
Отличие генетических алгоритмов от традиционных методов оптимизации:
Эволюционное (генетическое) программирование
Достоинства:
Блок- схема классического генетического алгоритма
35. Методы озвучивания речи. Системы синтеза речи. Речевой вывод информации.
Методы синтеза речи Рассмотрим какой-нибудь хотя бы минимально осмысленный текст. Текст состоит из слов, разделенных пробелами и знаками препинания. Произнесение слов зависит от их расположения в предложении, а интонация фразы - от знаков препинания. Более того, довольно часто и от типа применяемой грамматической конструкции: в ряде случаев при произнесении текста слышится явная пауза, хотя какие-либо знаки препинания отсутствуют. Наконец, произнесение зависит и от смысла слова. Обобщенная функциональная структура синтезатора Структура идеализированной системы автоматического синтеза речи состоит из нескольких блоков. -Определение языка текста -Нормализация текста -Лингвистический анализ: синтаксический, морфемный анализ и т.д. -Формирование просодических характеристик -Фонемный транскриптор -Формирование управляющей информации -Получение звукового сигнала Она не описывает ни одну из существующих реально систем, но содержит компоненты, которые можно обнаружить во многих системах. Авторы конкретных систем, независимо от того, являются ли эти системы уже коммерческим продуктом или еще находятся в стадии исследовательской разработки, уделяют различное внимание отдельным блокам и реализуют их очень по-разному, в соответствии с практическими требованиями. Методы озвучивания речи Теперь скажем несколько слов о наиболее распространенных методах озвучивания, то есть о методах получения информации, управляющей параметрами создаваемого звукового сигнала, и способах формирования самого звукового сигнала. Самое широкое разделение стратегий, применяемых при озвучивании речи, - это разделение на подходы, которые направлены на построение действующей модели речепроизводящей системы человека, и подходы, где ставится задача смоделировать акустический сигнал как таковой. Первый подход известен под названием артикуляторного синтеза. Второй подход представляется на сегодняшний день более простым, поэтому он гораздо лучше изучен и практически более успешен. Внутри него выделяется два основных направления - формантный синтез по правилам и компилятивный синтез. Формантные синтезаторы используют возбуждающий сигнал, который проходит через цифровой фильтр, построенный на нескольких резонансах, похожих на резонансы голосового тракта. Разделение возбуждающего сигнала и передаточной функции голосового тракта составляет основу классической акустической теории речеобразования. Компилятивный синтез осуществляется путем склейки нужных единиц компиляции из имеющегося инвентаря. На этом принципе построено множество систем, использующих разные типы единиц и различные методы составления инвентаря. Речевой вывод информации Речевой вывод информации из компьютера - проблема не менее важная, чем речевой ввод. Это вторая часть речевого интерфейса, без которой разговор с компьютером не может состояться. Мы имеем в виду прочтение вслух текстовой информации, а не проигрывание заранее записанных звуковых файлов. То есть выдачу в речевой форме заранее не известной информации. Фактически, благодаря синтезу речи по тексту открывается еще один канал передачи данных от компьютера к человеку, аналогичный тому, какой мы имеем благодаря монитору. Конечно, трудновато было бы передать рисунок голосом. Но вот услышать электронную почту или результат поиска в базе данных в ряде случаев было бы довольно удобно, особенно если в это время взгляд занят чем-либо другим.
38. Распознавание символов. Три подхода к распознаванию символов.
Сегодня известно три подхода к распознаванию символов - шаблонный, структурный и признаковый. Но принципу целостности отвечает лишь первые два. Шаблонное описание проще в реализации, однако, в отличие от структурного, оно не позволяет описывать сложные объекты с большим разнообразием форм. Именно поэтому шаблонное описание применяется для распознавания лишь печатных символов, в то время как структурное - для рукописных, имеющих, естественно, гораздо больше вариантов начертания. Шаблонные системы Такие системы преобразуют изображение отдельного символа в растровое, сравнивают его со всеми шаблонами, имеющимися в базе и выбирают шаблон с наименьшим количеством точек, отличных от входного изображения. Шаблонные системы довольно устойчивы к дефектам изображения и имеют высокую скорость обработки входных донных, но надежно распознают только те шрифты, шаблоны которых им "известны". И если распознаваемый шрифт хоть немного отличается от эталонного, шаблонные системы могут делать ошибки даже при обработке очень качественных изображений! Структурные системы В таких системах объект описывается как граф, узлами которого являются элементы входного объекта, а дугами - пространственные отношения между ними . Система реализующие подобный подход, обычно работают с векторными изображениями. Структурными элементами являются составляющие символ линии. Так, для буквы "р" - это вертикальный отрезок и дуга. К недостаткам структурных систем следует отнести их высокую чувствительность к дефектам изображения, нарушающим составляющие элементы. Также векторизация может добавить дополнительные дефекты. Кроме того, для этих систем, в отличие от шаблонных и признаковых, до сих пор не созданы эффективные автоматизированные процедуры обучения. Поэтому для Fine Reader структурные описания пришлось создать в ручную. Признаковые системы В них усредненное изображение каждого символа представляется как объект в n-мерном пространстве признаков. Здесь выбирается алфавит признаков, значения которых вычисляются при распознавании входного изображения. Полученный n-мерный вектор сравнивается с эталонными, и изображение относится к наиболее подходящему из них. Признаковые системы не отвечают принципу целостности. Необходимое, но недостаточное условие целостности описания класса объектов (в нашем случае это класс изображений, представляющих один символ)состоит в том, что описанию должны удовлетворять все объекты данного класса и ни один из объектов других классов. Но по-скольку при вычислении признаков теряется существенная часть информации, трудно гарантировать, что к данному классу удастся отнести только <родные> объекты.
31. Перцептроны. Алгоритм обучения перцептрона.
Перцептро́н, или персептрон[nb 1] (англ. perceptron от лат. perceptio — восприятие; нем. perzeptron) — математическая и компьютерная модель восприятия информации мозгом (кибернетическая модель мозга), предложенная Фрэнком Розенблаттом в 1957 году и реализованная в виде электронной машины «Марк-1»[nb 2] в 1960 году. Перцептрон стал одной из первых моделей нейросетей, а «Марк-1» — первым в мире нейрокомпьютером. Несмотря на свою простоту, перцептрон способен обучаться и решать довольно сложные задачи. Перцептрон состоит из трёх типов элементов, а именно: поступающие от сенсоров сигналы передаются ассоциативным элементам, а затем реагирующим элементам. Таким образом, перцептроны позволяют создать набор «ассоциаций» между входными стимулами и необходимой реакцией на выходе. В биологическом плане это соответствует преобразованию, например, зрительной информации в физиологический ответ от двигательных нейронов. Согласно современной терминологии, перцептроны могут быть классифицированы как искусственные нейронные сети:
Логическая схема перцептрона с тремя выходами Схема искусственного нейрона — базового элемента любой нейронной сети Элементарный перцептрон состоит из элементов 3-х типов: S-элементов, A-элементов и одного R-элемента. S-элементы — это слой сенсоров, или рецепторов. В физическом воплощении они соответствуют, например, светочувствительным клеткам сетчатки глаза или фоторезисторам матрицы камеры. Каждый рецептор может находиться в одном из двух состояний — покоя или возбуждения, и только в последнем случае он передаёт единичный сигнал в следующий слой, ассоциативным элементам. A-элементы называются ассоциативными, потому что каждому такому элементу, как правило, соответствует целый набор (ассоциация) S-элементов. A-элемент активизируется, как только количество сигналов от S-элементов на его входе превысило некоторую величину θ.[nb 5] Таким образом, если набор соответствующих S-элементов располагается на сенсорном поле в форме буквы «Д», A-элемент активизируется, если достаточное количество рецепторов сообщило о появлении «белого пятна света» в их окрестности, то есть A-элемент будет как бы ассоциирован с наличием/отсутствием буквы «Д» в некоторой области. Сигналы от возбудившихся A-элементов, в свою очередь, передаются в сумматор R, причём сигнал от i-го ассоциативного элемента передаётся с коэффициентом wi.[9] Этот коэффициент называется весом A—R связи. Так же как и A-элементы, R-элемент подсчитывает сумму значений входных сигналов, помноженных на веса (линейную форму). R-элемент, а вместе с ним и элементарный перцептрон, выдаёт «1», если линейная форма превышает порог θ, иначе на выходе будет «−1». Математически, функцию, реализуемую R-элементом, можно записать так:
Обучение элементарного перцептрона состоит в изменении весовых коэффициентов wi связей A—R. Веса связей S—A (которые могут принимать значения {−1; 0; +1}) и значения порогов A-элементов выбираются случайным образом в самом начале и затем не изменяются. (Описание алгоритма см. ниже.) После обучения перцептрон готов работать в режиме распознавания[10] или обобщения[11]. В этом режиме перцептрону предъявляются ранее неизвестные ему объекты, и перцептрон должен установить, к какому классу они принадлежат. Работа перцептрона состоит в следующем: при предъявлении объекта, возбудившиеся A-элементы передают сигнал R-элементу, равный сумме соответствующих коэффициентов wi. Если эта сумма положительна, то принимается решение, что данный объект принадлежит к первому классу, а если она отрицательна — то ко второму.[12]
1. Искусственный интеллект. Основные понятия и определения. Иску́сственный интелле́кт (ИИ, англ. Artificial intelligence, AI, ИскИн [1]) — наука и технология создания интеллектуальных машин, особенно интеллектуальных компьютерных программ. ИИ связан со сходной задачей использования компьютеров для понимания человеческого интеллекта, но не обязательно ограничивается биологически правдоподобными методами[2]. Другие определения искусственного интеллекта:
Предметом информатики является обработка информации по известным законам. Предметом ИИ является изучение интеллектуальной деятельности человека, подчиняющейся заранее неизвестным законам. ИИ это все то, что не может быть обработано с помощью алгоритмических методов. Системой будем называть множество элементов, находящихся в отношениях друг с другом и образующих причинно-следственную связь. Адаптивная система - это система, которая сохраняет работоспособность при непредвиденных изменениях свойств управляемого объекта, целей управления или окружающей среды путем смены алгоритма функционирования, программы поведения или поиска оптимальных, в некоторых случаях просто эффективных, решений и состояний. Традиционно, по способу адаптации различают самонастраивающиеся, самообучающиеся и самоорганизующиеся системы. Под алгоритмом будем понимать последовательность заданных действий, которые однозначно определены и выполнимы на современных ЭВМ за приемлемое время для решаемой задачи. Под ИС будем понимать адаптивную систему, позволяющую строить программы целесообразной деятельности по решению поставленных перед ними задач на основании конкретной ситуации, складывающейся на данный момент в окружающей их среде. Предметом ИИ является изучение интеллектуальной деятельности человека, подчиняющейся заранее неизвестным законам. ИИ это все то, что не может быть обработано с помощью алгоритмических методов. Другие области исследований Наконец, существует масса приложений искусственного интеллекта, каждое из которых образует почти самостоятельное направление. В качестве примеров можно привести программирование интеллекта в компьютерных играх, нелинейное управление, интеллектуальные системы информационной безопасности.
Можно заметить, что многие области исследований пересекаются. Это свойственно для любой науки. Но в искусственном интеллекте взаимосвязь между, казалось бы, различными направлениями выражена особенно сильно, и это связано с философским спором о сильном и слабом ИИ. В 1954 году А. Ньюэлл задумал создать программу для игры в шахматы. Дж. Шоу и Г. Саймон объединились в работе по проекту Ньюэлла и в 1956 году они создали язык программирования IPL-I (предшественник LISPа) для работы с символьной информацией. Их первыми программами стала программа LT (Logic Theorist) для доказательства теорем и исчисления высказываний (1956 год), а также программа NSS (Newell, Shaw, Simon) для игры в шахматы (1957 год). LT и NSS привели к созданию А. Ньюэллом, Дж. Шоу и Г. Саймоном программы GPS (General Problem Solver) в 1957–1972 годах. Программа GPS моделировала используемые человеком общие стратегии решения задач и могла применяться для решения шахматных и логических задач, доказательства теорем, грамматического разбора предложений, математического интегрирования, головоломок типа «Ханойская башня» и т. д. Специализированные «решатели задач» – STUDENT (Bobrov, 1964) и др. лучше проявляли себя при поиске решения в своих предметных областях. GPS оказалась первой программой (она была написана на языке IPL-V), в которой предусматривалось планирование стратегии решения задач. Для решения трудно формализуемых задач и, в частности, для работы со знаниями были созданы языки программирования для задач ИИ: LISP (1960 год, J. MacCatthy), Пролог (1975-79 годы, D. Warren, F. Pereira), ИнтерLISP, FRL, KRL, SMALLTALK, OPS5, PLANNER, QA4, MACSYMA, REDUCE, РЕФАЛ, CLIPS. К числу наиболее популярных традиционных языков программирования для создания ИС следует также отнести С++ и Паскаль. 6. Представление знаний в интеллектуальных системах. Данные и знания. Основные определения.
В настоящее время в исследованиях по искусственному интеллекту (ИИ) выделились шесть направлений:
В рамках направления "Представление знаний" решаются задачи, связанные с формализацией и представлением знаний в памяти интеллектуальной системы (ИС). Для этого разрабатываются специальные модели представления знаний и языки для описания знаний, выделяются различные типы знаний. Изучаются источники, из которых ИС может черпать знания, и создаются процедуры и приемы, с помощью которых возможно приобретение знаний для ИС. Проблема представления знаний для ИС чрезвычайно актуальна, т.к. ИС - это система, функционирование которой опирается на знания о проблемной области, которые хранятся в ее памяти. Следует определить также понятие знания - центрального понятия в ИС. Рассмотрим несколько определений.
Например, если X истинно и Y истинно, то Z истинно с достоверностью P.
Под статическими знаниями будем понимать знания, введенные в ИС на этапе проектирования. Под динамическими знаниями (опытом) будем понимать знания, полученные ИС в процессе функционирования или эксплуатации в реальном масштабе времени. Знания можно разделить на факты и правила. Под фактами подразумеваются знания типа «A это A», они характерны для баз данных. Под правилами (продукциями) понимаются знания вида «ЕСЛИ - ТО». Кроме этих знаний существуют так называемые метазнания (знания о знаниях). Создание продукционных систем для представления знаний позволило разделить знания и управление в компьютерной программе, обеспечить модульность продукционных правил, т. е. отсутствие синтаксического взаимодействия между правилами. При создании моделей представления знаний следует учитывать такие факторы, как однородность представления и простота понимания. Выполнить это требование в равной степени для простых и сложных задач довольно сложно. Данные – отдельные факты, характеризующие объекты, процессы и явления, а также их свойства. Да́нные (калька от лат. data) — это представление фактов и идей в формализованном виде, пригодном для передачи и обработки в некотором информационном процессе. Изначально - данные величины, т.е. величины, заданные заранее, вместе с условием задачи. Противоположность - переменные величины. При обработке на ЭВМ трансформируются, проходя следующие этапы:
8. Системы представления знаний. В рамках направления "Представление знаний" решаются задачи, связанные с формализацией и представлением знаний в памяти интеллектуальной системы (ИС). Для этого разрабатываются специальные модели представления знаний и языки для описания знаний, выделяются различные типы знаний. Изучаются источники, из которых ИС может черпать знания, и создаются процедуры и приемы, с помощью которых возможно приобретение знаний для ИС. Проблема представления знаний для ИС чрезвычайно актуальна, т.к. ИС - это система, функционирование которой опирается на знания о проблемной области, которые хранятся в ее памяти. Существуют два типа методов представления знаний (ПЗ):
-Логические модели. -Сетевые модели. -Продукционные модели -Фреймовые модели
-Продукционные системы(это система правил, на которых основана продукционная модель представления знаний) -Семантические Очевидно, все методы представления знаний, которые рассмотрены выше, включая продукции (это система правил, на которых основана продукционная модель представления знаний), относятся к неформальным моделям. В отличие от формальных моделей, в основе которых лежит строгая математическая теория, неформальные модели такой теории не придерживаются. Каждая неформальная модель годится только для конкретной предметной области и поэтому не обладает универсальностью, которая присуща моделям формальным. Логический вывод - основная операция в СИИ - в формальных системах строг и корректен, поскольку подчинен жестким аксиоматическим правилам. Вывод в неформальных системах во многом определяется самим исследователем, который и отвечает за его корректность. Каждому из методов ПЗ соответствует свой способ описания знаний. 1. Логические модели. В основе моделей такого типа лежит формальная система, задаваемая четверкой вида: M = <T, P, A, B>. Множество T есть множество базовых элементов различной природы. Множество P есть множество синтаксических правил. С их помощью из элементов T образуют синтаксически правильные совокупности. В множестве синтаксически правильных совокупностей выделяется некоторое подмножество A. Элементы A называются аксиомами. Множество B есть множество правил вывода. Применяя их к элементам A, можно получать новые синтаксически правильные совокупности, к которым снова можно применять правила из B. Так формируется множество выводимых в данной формальной системе совокупностей. 2. Сетевые модели. В основе моделей этого типа лежит конструкция, названная ранее семантической сетью. Сетевые модели формально можно задать в видеH = <I, C1, C2, ..., Cn, Г>. Здесь I есть множество информационных единиц; C1, C2, ..., Cn - множество типов связей между информационными единицами. Отображение Г задает между информационными единицами, входящими в I, связи из заданного набора типов связей. 3. Продукционные модели. В моделях этого типа используются некоторые элементы логических и сетевых моделей. Из логических моделей заимствована идея правил вывода, которые здесь называются продукциями, а из сетевых моделей - описание знаний в виде семантической сети. В результате применения правил вывода к фрагментам сетевого описания происходит трансформация семантической сети за счет смены ее фрагментов, наращивания сети и исключения из нее ненужных фрагментов. Таким образом, в продукционных моделях процедурная информация явно выделена и описывается иными средствами, чем декларативная информация. Вместо логического вывода, характерного для логических моделей, в продукционных моделях появляется вывод на знаниях. 4. Фреймовые модели. В отличие от моделей других типов во фреймовых моделях фиксируется жесткая структура информационных единиц, которая называется протофреймом. В общем виде она выглядит следующим образом: (Имя фрейма: Имя слота 1(значение слота 1) Имя слота 2(значение слота 2) . . . . . . . . . . . . . . . . . . . . . . Имя слота К (значение слота К)). Значением слота может быть практически что угодно (числа или математические соотношения, тексты на естественном языке или программы, правила вывода или ссылки на другие слоты данного фрейма или других фреймов). В качестве значения слота может выступать набор слотов более низкого уровня, что позволяет во фреймовых представлениях реализовать "принцип матрешки".
12. Системы представления знаний. Семантические сети.
Семантика в бытовом понимании означает смысл слова, художественного произведения, действия и т.д. Семантическая сеть (СС) - это граф, дуги которого есть отношения между вершинами (значениями). Семантические сети появились как модель СПЗ при решении задач разбора и понимания смысла естественного языка. Модели в виде СС активно развиваются в работах зарубежных и отечественных ученых, вбирая в себя важнейшие свойства других типов моделей. Пример семантической сети для предложения типа "Поставщик осуществил поставку изделий по заказу клиента до 1 июня 2004 года в количестве 1000 штук" приведен на рис. 2.3.
Рис. 2.3. Пример семантической сети На этом примере видно, что между объектами Поставщик и Поставка определено отношение "агент", между объектами Изделие и Поставка определено отношение "объект" и т.д. Число отношений, используемых в конкретных семантических сетях, может быть самое разное. К.Филмор, один из первых поборников идеи семантических падежей при разборе предложений, проводил свои рассуждения, пользуясь дюжиной отношений. Неполный список возможных отношений, используемых в семантических сетях для разбора предложений, выглядит следующим образом. Агент - это то, что (тот, кто) вызывает действие. Агент часто является подлежащим в предложении, например, "Робби ударил мяч". Объект - это то, на что (на кого) направлено действие. В предложении объект часто выполняет роль прямого дополнения, например, "Робби взял желтую пирамиду ". Инструмент - то средство, которое используется агентом для выполнения действия, например, "Робби открыл дверь с помощью ключа ". Соагент служит как подчиненный партнер главному агенту, например, "Робби собрал кубики с помощью Суззи". Пункт отправления и пункт назначения - это отправная и конечная позиции при перемещении агента или объекта: "Робби перешел из комнаты в библиотеку ". Траектория - перемещение от пункта отправления к пункту назначения: "Они прошли через дверь по ступенькам на лестницу ". Средство доставки - то в чем или на чем происходит перемещение: "Он всегда едет домой на метро ". Местоположение - то место, где произошло (происходит, будет происходить) действие, например, "Он работал за столом ". Потребитель - то лицо, для которого выполняется действие: "Робби собрал кубики для Суззи". Сырье - это, как правило, материал, из которого что-то сделано или состоит. Обычно сырье вводится предлогом из, например, "Робби собрал Суззи из интегральных схем ". Время - указывает на момент совершения действия: "Он закончил свою работу поздно вечером ". Наиболее типичный способ вывода в семантических сетях (СС) - это способ сопоставления частей сетевой структуры. Это видно на следующем простом примере, представленном на рис. 2.4.
Рис. 2.4. Процедура сопоставления в СС
Куб Cube принадлежит миру BlockWorld. Куб Cube_001 есть разновидность куба Cube. Легко сделать вывод: Куб Cube_001 есть часть мира BlockWorld.
16. Методы поиска решений на основе исчисления предикатов В дедуктивных моделях представления и обработки знании решаемая проблема записывается в виде утверждении формальной системы, цель - в виде утверждения, справедливость которого следует установить или опровергнуть на основании аксиом (общих законов) и правил вывода формальной системы. В качестве формальной системы используют исчисление предикатов первого порядка. Существует возможность доказательства теорем неаксиоматическим путем: прямым выводом, обратным выводом. Метод резолюции используется в качестве полноценного (формального) метода доказательства теорем. Для применения этого метода исходную группу заданных логических формул требуется преобразовать в некоторую нормальную форму. Это преобразование проводится в несколько стадий, составляющих машину вывода. Семантика исчисления предикатов обеспечивает основу для формализации логического вывода. Возможность логически выводить новые правильные выражения из набора истинных утверждений очень важна. Логически выведенные утверждения корректны, и они совместимы со всеми предыдущими интерпретациями первоначального набора выражений. Обсудим вышесказанное неформально и затем введем необходимую формализацию. В исчислении высказываний основным объектом является переменное высказывание (предикат), истинность или ложность которого зависит от значений входящих в него переменных. Если из A следует B и B ложно, то и A ложно. Если A и B не могут быть истинными и A истинно, то B ложно. Если либо A, либо B является истинным и A не истинно, то B истинно. Решаемая задача представляется в виде утверждений (аксиом) f1, F2... Fn исчисления предикатов первого порядка. Цель задачи B также записывается в виде утверждения, справедливость которого следует установить или опровергнуть на основании аксиом и правил вывода формальной системы. Тогда решение задачи (достижение цели задачи) сводится к выяснению логического следования (выводимости) целевой формулы B из заданного множества формул (аксиом) f1, F2... Fn. На доказательстве от противного основано и ведущее правило вывода, используемое в логическом программировании, - принцип резолюции. Робинсон открыл более сильное правило вывода, чем modus ponens, которое он назвал принципом резолюции
Главная
идея этого правила вывода заключается
в проверке того, содержит ли множество
дизъюнктов R пустой (ложный) дизъюнкт.
Обычно резолюция применяется с прямым
или обратным методом рассуждения.
Прямой метод из посылок A,
A
Процесс доказательства методом резолюции (от обратного) состоит из следующих этапов:
Подстановки, использованные для получения пустого выражения, свидетельствуют о том, что отрицание отрицания истинно. В методе резолюции порядок комбинации дизъюнктивных выражений не устанавливался. Значит, для больших задач будет наблюдаться экспоненциальный рост числа возможных комбинаций. Поэтому в процедурах резолюции большое значение имеют также эвристики поиска и различные стратегии. Одна из самых простых и понятных стратегий - стратегия предпочтения единичного выражения, которая гарантирует, что резольвента будет меньше, чем наибольшее родительское выражение. Ведь в итоге мы должны получить выражение, не содержащее литералов вообще. 20. Нечеткие системы. Понятие лингвистической переменной.
Нечеткие системы опираются на описание отношений между переменными процессов с помощью лингвистических значений. В противоположность нечеткой традиционная система управления процессами объектной переменной использует множества базовых значений (четкие значения) для определения их поведения во времени. При этом базовые и нечеткие значения объектной переменной в зависимости от исследуемого приложения должны быть согласованы. В отличие от базовых значений нечеткие значения не должны быть исключительными, а представляют собой слова повседневного языка. Следовательно, они могут описывать человеческий опыт и знания о процессах с нечеткими значениями и отношениями между переменными. В разговорной речи вместо четких терминов из согласованного множества базовых значений часто используются лингвистические множества, и не всегда определено, какое из них соответствует настоящему моменту. Лингвистические значения нечетки в этом смысле. Определение: Переменная значениями которой являются термы (слова, фразы на естественном языке) называется лингвистической. Например, ЛП "рост" определяется через набор {карликовый, низкий, средний, высокий, очень высокий}. В любой ситуации признак объекта проблемной области имеет одно и только одно четкое значение из согласованного множества базовых и одно или более чем одно нечеткое значение из соответствующего множества нечетких значений. Выберем для объектной переменной «дата» множество базовых значений: В={Пн., Вт., Ср., Чт., Пт., Сб., Вс.} и множество нечетких значений: F={начало недели, середина недели, конец недели}. Сущности «дата» и четкому значению «среда» соответствует нечеткое - «середина недели». «Среду» с трудом можно отнести на «начало недели» или «конец недели». Таким образом, для проектирования нечеткой системы необходимо все переменные описать как лингвистические: задать для каждой переменной множество термов, а каждый терм описать как нечеткое множество со своей функцией принадлежности. х – температура воды Таким образом, граница между нечеткими подмножествами является размытой и переход из одного подмножества в другое осуществляется плавно без скачков.
22. Нечеткие системы. Задача нечеткого управления. Нечеткие алгоритмы - это упорядоченное множество нечетких инструкций (правил) в формулировке которых содержатся нечеткие указания (термы). Характеристикой нечеткого множества выступает функция принадлежности (Membership Function). Обозначим через MFc(x) – степень принадлежности к нечеткому множеству C, представляющей собой обобщение понятия характеристической функции обычного множества. Тогда нечетким множеством С называется множество упорядоченных пар вида C={MFc(x)/x}, MFc(x) [0,1]. Значение MFc(x)=0 означает отсутствие принадлежности к множеству, 1 – полную принадлежность. Пример. Формализуем неточное определение "горячий чай". В качестве x (область рассуждений) будет выступать шкала температуры в градусах Цельсия. Она будет изменяется от 0 до 100 градусов. Нечеткое множество для понятия "горячий чай" может выглядеть следующим образом: C={0/0; 0/10; 0/20; 0,15/30; 0,30/40; 0,60/50; 0,80/60; 0,90/70; 1/80; 1/90; 1/100}. Так, чай с температурой 60 С принадлежит к множеству "Горячий" со степенью принадлежности 0,80. Для одного человека чай при температуре 60 С может оказаться горячим, для другого – не слишком горячим. Именно в этом и проявляется нечеткость задания соответствующего множества. Для нечетких множеств, как и для обычных, определены основные логические операции – пересечение и объединение. Для описания нечетких множеств вводятся понятия нечеткой и лингвистической переменных.
Задача нечеткого управления. Разработка нечетких правил На этом этапе определяются продукционные правила, связывающие лингвистические переменные. Совокупность таких правил описывает стратегию управления, применяемую в данной задаче. Большинство нечетких систем используют продукционные правила для описания зависимостей между лингвистическими переменными. Типичное продукционное правило состоит из антецедента (часть ЕСЛИ …) и консеквента (часть ТО …). Антецедент может содержать более одной посылки. В этом случае они объединяются посредством логических связок И или ИЛИ. Процесс вычисления нечеткого правила называется нечетким логическим выводом и подразделяется на два этапа: обобщение и заключение. Пусть мы имеем следующее правило: ЕСЛИ ДИСТАНЦИЯ=средняя И УГОЛ=малый, ТО МОЩНОСТЬ=средняя. Обратимся к примеру с контейнерным краном и рассмотрим ситуацию, когда расстояние до платформы равно 20 метрам, а угол отклонения контейнера на тросе крана равен четырем градусам. После фаззификации исходных данных получим, что степень принадлежности расстояния в 20 метров к терму СРЕДНЯЯ лингвистической переменной ДИСТАНЦИЯ равна 0,9, а степень принадлежности угла в 4 градуса к терму МАЛЫЙ лингвистической переменной УГОЛ равна 0,8. На первом шаге логического вывода необходимо определить степень принадлежности всего антецедента правила. Для этого в нечеткой логике существуют два оператора: MIN(…) и MAX(…). Первый вычисляет минимальное значение степени принадлежности, а второй - максимальное значение. Если использована связка И, применяется оператор MIN(…). Если же посылки объединены связкой ИЛИ, необходимо применить оператор MAX(…). Ну а если в правиле всего одна посылка, операторы не нужны. Для нашего примера применим, оператор MIN. Получим: MIN(0,9;0,8)=0,8. Следовательно, степень принадлежности антецедента такого правила равна 0,8. Операция, описанная выше, отрабатывается для каждого правила в базе нечетких правил. Следующим шагом является собственно вывод или заключение. Подобным же образом посредством операторов MIN/MAX вычисляется значение консеквента. Исходными данными служат вычисленные на предыдущем шаге значения степеней принадлежности антецедентов правил. После выполнения всех шагов нечеткого вывода мы находим нечеткое значение управляющей переменной. Чтобы исполнительное устройство смогло отработать полученную команду, необходим этап управления, на котором мы избавляемся от нечеткости и который называется дефаззификацией. ***Дефаззификация – устранение нечеткости. ***Фаззификация – переход к нечеткости.
Области применения нечетких систем.
Достоинства:
Недостатки:
27. Нейронные сети. Модель нейрона. Типы нейронов.
Нейронные сети начали активно распространяться 20 лет назад, они позволяют решать сложные задачи обработки данных. Биологический нейрон состоит из тела диаметром от 3 до 100 мкм, содержащего ядро (с большим количеством ядерных пор) и другие органеллы, и отростков. Выделяют два вида отростков. Каждый нейрон состоит из сомы и отростков — аксонов и дендритов. Аксоны — это передатчики сигналов, а дендриты — сильно разветвлённые отростки — приёмники сигналов. Нейрон может иметь несколько дендритов и обычно только один аксон. Один нейрон может иметь связи с 20-ю тысячами других нейронов. Кора головного мозга человека содержит 10—20 миллиардов нейронов. Искусственный нейрон — моделирует основные функции естественного нейрона.
Здесь
θ (тета) — вес смещения, на входе единица. Типы нейронов. Униполярные клетки. Клетки, от тела которых отходит только один отросток. Для этих клеток характерна определенная локализация. Они принадлежат неспецифическим сенсорным модальностям (болевая, температурная, тактильная, проприоцептивная) и расположены в сенсорных узлах: спинальных, тройничном, каменистом. Биполярные клетки — это клетки, которые имеют один аксон и один дендрит. Они характерны для зрительной, слуховой, обонятельной сенсорных систем. Мультиполярные клетки имеют один аксон и множество дендритов. К такому типу нейронов принадлежит большинство нейронов ЦНС. Исходя из особенностей формы этих клеток их делят на веретенообразные, корзинчатые, звездчатые, пирамидные. Входные сигналы, взвешенные весовыми коэффициентами складываются, проходят через передаточную функцию, которая генерирует результат, который, собственно, и выводится. (Как бы аксоном.) В существующих нынче пакетах программ искусственные нейроны называются элементами обработки и имеют больше возможностей, чем простой искусственный нейрон, который мы сейчас представили.
|
Секция clauses – это ядро программы, содержащее факты и правила, с которыми будет работать Турбо Пролог, пытаясь разрешить внутреннюю или внешнюю цель программы. Последовательность предложений, описывающих один предикат, называется процедурой. В секции goal задается внутренняя цель программы, что позволяет программе запускаться независимо от среды разработки. Использование внешних целей удобно в том случае, когда производится запуск программ из среды разработки Турбо Пролога. Однако, если планируется получить автономную исполняемую программу, то необходимо включить секцию goal в эту программу. Цели, заданные в этой секции, называются внутренними целями, т.к. они являются частью исходного текста программы и в ней же компилируются. Секция goal аналогична телу правила и отличается от правила лишь следующим: 1) за ключевым словом goal не следует «:-» или «if»; 2) при запуске программы Турбо Пролог автоматически выполняет цель. Это происходит так, как будто Турбо Пролог вызывает goal, запуская тем самым программу, которая пытается разрешить тело правила goal. Если все подцели в секции goal истинны – программа завершается успешно. Если же какая-то подцель из секции goal ложна, то считается, что программа ложна. (Хотя чисто внешне никакой разницы в этих случаях нет – программа просто завершит свою работу.) Программа на Турбо Прологе представляет собой набор фактов и правил. Иногда, в процессе работы программы, возникает необходимость модифицировать (изменить, удалить или добавить) некоторые из фактов, с которыми она работает. В этом случае факты рассматриваются как динамическая или внутренняя база данных, которая в процессе работы программы может изменяться. Для объявления фактов программы, рассматривающихся как часть динамической (или изменяющейся) базы данных, Турбо Пролог включает специальную секцию – database. В программах на Турбо Прологе можно объявлять и использовать символические константы. Секция для объявления констант обозначается ключевым словом constants, за которым следуют сами объявления, использующие следующий синтаксис: ID = макроописание
где ID – имя символической константы, а макроописание – это то, что вы присваиваете этой константе. Каждое завершается символом новой строки и, следовательно, на одной строке может быть только одно описание константы. Объявленные таким образом константы могут позже использоваться в программах.
36.Системы машинного зрения. Общая характеристика задач распознавания.
Под образом понимается структурированное описание изучаемого объекта или явления, представленное вектором признаков, каждый элемент которого представляет числовое значение одного из признаков, характеризующих соответствующий объект. Общая структура системы распознавания и этапы в процессе ее разработки показаны на рис. 4.1.
Суть задачи распознавания - установить, обладают ли изучаемые объекты фиксированным конечным набором признаков, позволяющим отнести их к определенному классу. Задачи распознавания имеют следующие характерные черты.
Целесообразно выделить следующие типы задач распознавания.
39. Распознавание символов. Структурно-пятенный эталон.
Фонтанное преобразование совмещает в себе достоинства шаблонной и структурной систем и, по нашему мнению, позволяет избежать недостатков, присущих каждой из них по отдельности. В основе этой технологии лежит использование структурно-пятенного эталона. Он позволяет представить изображения в виде набора пятен, связанных между собой n-арными отношениями, задающими структуру символа. Эти отношения (то есть расположение пятен друг относительно друга) образуют структурные элементы, составляющие символ. Так, например, отрезок - это один тип n-арных отношений между пятнами, эллипс -другой, дуга - третий. Другие отношения задают пространственное расположение образующих символ элементов.
В эталоне задаются: - имя; - обязательные, запрещающие и необязательные структурные элементы; - отношения между структурными элементами; - отношения, связывающие структурные элементы с описывающим прямоугольником символа; - атрибуты, используемые для выделения структурных элементов; - атрибуты, используемые для проверки отношений между элементами; - атрибуты, используемые для оценки качества элементов и отношений; - позиция, с которой начинается выделение элемента (отношения локализации элементов). Структурные элементы, выделяемые для класса изображений, могут быть исходными и составными. Исходные структурные элементы - это пятна, составные - отрезок, дуга, кольцо, точка. В качестве составных структурных элементов, в принципе, могут быть взяты любые объекты, описанные в эталоне. Кроме того, они могут быть описаны как через исходные, так и через другие составные структурные элементы. Например, для распознавания корейских иероглифов (слоговое письмо) составными элементами для описания слога являются описания отдельных букв (но не отдельные элементы букв). В итоге, использование составных структурных элементов позволяет строить иерархические описания классов распознаваемых объектов. В качестве отношений используются связи между структурными элементами, которые определяются либо метрическими характеристиками этих элементов (например, <длина больше>), либо их взаимным расположением на изображении (например, <правее>,<соприкасается>). При задании структурных элементов и отношений используются конкретизирующие параметры, позволяющие доопределить структурный элемент или отношение при использовании этого элемента в эталоне конкретного класса. Для структурных элементов конкретизирующими могут являться, например, параметры, задающие диапазон допустимой ориентации отрезка, а для отношений -параметры, задающие предельное допустимое расстояние между характерными точками структурных элементов в отношении <соприкасается>. Конкретизирующие параметры используются также для вычисления <качества> конкретного структурного элемента изображения и <качества> выполнения данного отношения. Построение и тестирование структурно-пятенных эталонов для классов распознаваемых объектов - процесс сложный и трудоемкий. База изображений, которая используется для отладки описаний, должна содержать примеры хороших и плохих (предельно допустимых) изображений для каждой графемы, а изображения базы разделяются на обучающее и контрольное множества. Разработчик описания предварительно задает набор структурных элементов (разбиение на пятна) и отношения между ними. Система обучения по базе изображений автоматически вычисляет параметры элементов и отношений. Полученный эталон проверяется и корректируется по контрольной выборке изображений данной графемы. По контрольной же выборке проверяется результат распознавания, то есть оценивается качество подтверждения гипотез. <Распознавание с использованием структурно-пятенного эталона происходит следующим образом. Эталон накладывается на изображение, и отношения между выделенными на изображении пятнами сравниваются с отношениями пятен в эталоне. Если выделенные на изображении пятна и отношения между ними удовлетворяют эталону некоторого символа, то данный символ добавляется в список гипотез о результате распознавания входного изображения.
Логическая схема элементарного перцептрона. Веса S—A связей могут иметь значения −1, +1 или 0 (то есть отсутствие связи). Веса A—R связей W могут быть любыми. Алгоритмы обучения Важным свойством любой нейронной сети является способность к обучению. В своей книге Розенблатт пытался классифицировать различные алгоритмы обучения перцептрона, называя их системами подкрепления. Система подкрепления Это любой набор правил, на основании которых можно изменять с течением времени матрицу взаимодействия (или состояние памяти) перцептрона.[21] Описывая эти системы подкрепления и уточняя возможные их виды, Розенблатт основывался на идеях Д. Хебба об обучении, предложенных им в 1949 году[2], которые можно перефразировать в следующее правило, состоящее из двух частей:
Обучение с учителем Классический метод обучения перцептрона — это метод коррекции ошибки.[8] Он представляет собой такой вид обучения с учителем, при котором вес связи не изменяется до тех пор, пока текущая реакция перцептрона остается правильной. При появлении неправильной реакции вес изменяется на единицу, а знак (+/-) определяется противоположным от знака ошибки. Допустим, мы хотим обучить перцептрон разделять два класса объектов так, чтобы при предъявлении объектов первого класса выход перцептрона был положителен (+1), а при предъявлении объектов второго класса — отрицательным (−1). Для этого выполним следующий алгоритм:[5]
Обе части шага 3 выполним для всей обучающей выборки. В результате обучения сформируются значения весов связей wi. Теорема сходимости перцептрона[8], описанная и доказанная Ф. Розенблаттом (с участием Блока, Джозефа, Кестена и других исследователей, работавших вместе с ним), показывает, что элементарный перцептрон, обучаемый по такому алгоритму, независимо от начального состояния весовых коэффициентов и последовательности появления стимулов всегда приведет к достижению решения за конечный промежуток времени. Обучение без учителя Кроме классического метода обучения перцептрона Розенблатт также ввёл понятие об обучении без учителя, предложив следующий способ обучения: Альфа-система подкрепления Это система подкрепления, при которой веса всех активных связей cij, которые ведут к элементу uj, изменяются на одинаковую величину r, а веса неактивных связей за это время не изменяются.[23] Затем, с разработкой понятия многослойного перцептрона, альфа-система была модифицирована и её стали называть дельта-правило. Модификация была проведена с целью сделать функцию обучения дифференцируемой (например, сигмоидной), что в свою очередь нужно для применения метода градиентного спуска, благодаря которому возможно обучение более одного слоя. Метод обратного распространения ошибки Для обучения многослойных сетей рядом учёных, в том числе Д. Румельхартом, был предложен градиентный алгоритм обучения с учителем, проводящий сигнал ошибки, вычисленный выходами перцептрона, к его входам, слой за слоем. Сейчас это самый популярный метод обучения многослойных перцептронов. Его преимущество в том, что он может обучить все слои нейронной сети, и его легко просчитать локально. Однако этот метод является очень долгим, к тому же, для его применения нужно, чтобы передаточная функция нейронов была дифференцируемой. При этом в перцептронах пришлось отказаться от бинарного сигнала, и пользоваться на входе непрерывными значениями.
2. Область применения ИИ. Исторический обзор развития ИИ.
Символьное моделирование мыслительных процессов Анализируя историю ИИ, можно выделить такое обширное направление как моделирование рассуждений. Долгие годы развитие этой науки двигалось именно по этому пути, и теперь это одна из самых развитых областей в современном ИИ. Моделирование рассуждений подразумевает создание символьных систем, на входе которых поставлена некая задача, а на выходе требуется её решение. Как правило, предлагаемая задача уже формализована, то есть переведена в математическую форму, но либо не имеет алгоритма решения, либо он слишком сложен, трудоёмок и т. п. В это направление входят: доказательство теорем, принятие решений и теория игр, планирование и диспетчеризация, прогнозирование. Работа с естественными языками Немаловажным направлением является обработка естественного языка, в рамках которого проводится анализ возможностей понимания, обработки и генерации текстов на «человеческом» языке. В частности, здесь ещё не решена проблема машинного перевода текстов с одного языка на другой. В современном мире большую роль играет разработка методов информационного поиска. По своей природе, оригинальный тест Тьюринга связан с этим направлением. Накопление и использование знаний Согласно мнению многих учёных, важным свойством интеллекта является способность к обучению. Таким образом, на первый план выходит инженерия знаний, объединяющая задачи получения знаний из простой информации, их систематизации и использования. Достижения в этой области затрагивают почти все остальные направления исследований ИИ. Здесь также нельзя не отметить две важные подобласти. Первая из них — машинное обучение — касается процесса самостоятельного получения знаний интеллектуальной системой в процессе её работы. Второе связано с созданием экспертных систем — программ, использующих специализированные базы знаний для получения достоверных заключений по какой-либо проблеме. К области машинного обучения относится большой класс задач на распознавание образов. Например, это распознавание символов, рукописного текста, речи, анализ текстов. Многие задачи успешно решаются с помощью биологического моделирования (см. след. пункт). Особо стоит упомянуть компьютерное зрение, которое связано ещё и с робототехникой. Биологическое моделирование искусственного интеллекта Отличается от понимания искусственного интеллекта по Джону Маккарти, когда исходят из положения о том, что искусственные системы не обязаны повторять в своей структуре и функционировании структуру и протекающие в ней процессы, присущие биологическим системам, сторонники данного подхода считают, что феномены человеческого поведения, его способность к обучению и адаптации, есть следствие именно биологической структуры и особенностей ее функционирования. Сюда можно отнести несколько направлений. Нейронные сети используются для решения нечётких и сложных проблем, таких как распознавание геометрических фигур или кластеризация объектов. Генетический подход основан на идее, что некий алгоритм может стать более эффективным, если позаимствует лучшие характеристики у других алгоритмов («родителей»). Относительно новый подход, где ставится задача создания автономной программы — агента, взаимодействующего с внешней средой, называется агентным подходом. Робототехника Вообще, робототехника и искусственный интеллект часто ассоциируется друг с другом. Интегрирование этих двух наук, создание интеллектуальных роботов, можно считать ещё одним направлением ИИ. Примером интеллектуальной робототехники могут служить игрушки-роботы Pleo, AIBO, QRIO. Машинное творчество Природа человеческого творчества ещё менее изучена, чем природа интеллекта. Тем не менее, эта область существует, и здесь поставлены проблемы написания компьютером музыки, литературных произведений (часто — стихов или сказок), художественное творчество. Создание реалистичных образов широко используется в кино и индустрии игр. Добавление данной возможности к любой интеллектуальной системе позволяет весьма наглядно продемонстрировать что именно система воспринимает и как это понимает. Добавлением шума вместо недостающей информации или фильтрация шума имеющимися в системе знаниями производит из абстрактных знаний конкретные образы, легко воспринимаемые человеком, особенно это полезно для интуитивных и малоценных знаний, проверка которых в формальном виде требует значительных умственных усилий.
Знания связаны с данными, основываются на них, но представляют результат мыслительной деятельности человека, обобщают его опыт, полученный в ходе выполнения какой-либо практической деятельности. Они получаются эмпирическим путем. Знания — это выявленные закономерности предметной области (принципы, связи, законы), позволяющие решать задачи в этой области. При обработке на ЭВМ знания трансформируются аналогично данным:
---------------------------------------------------------------------------------- ----------------------------------------------------------------------------------
Перечисленные пять особенностей информационных единиц определяют ту грань, за которой данные превращаются в знания, а базы данных перерастают в базы знаний (БЗ). Совокупность средств, обеспечивающих работу с знаниями, образует систему управления базой знаний (СУБЗ). В настоящее время не существует баз знаний, в которых в полной мере были бы реализованы внутренняя интерпретируемость, структуризация, связность, введена семантическая мера и обеспечена активность знаний.
------------------------------------------------------------------------------------
9. Формальные системы представления знаний. Исчисление предикатов. Во - первых, наличие алфавита (словаря), отображающего в символьной форме весь набор базовых понятий (элементов), с которыми придется иметь дело и, во - вторых, набор синтаксических правил, на основе которых, пользуясь алфавитом, можно построить определенные выражения. Логические выражения, построенные в данном языке, могут быть истинными или ложными. Некоторые из этих выражений, являющиеся всегда истинными объявляются аксиомами (или постулатами). Они составляют ту базовую систему посылок, исходя из которой и пользуясь определенными правилами вывода, можно получить заключения в виде новых выражений, также являющихся истинными. Если перечисленные условия выполняются, то говорят, что система удовлетворяет требованиям формальной теории. Ее так и называют формальной системой(ФС). Система, построенная на основе формальной теории, называется также аксиоматической системой. Всякая формальная теория F = (A, V, W, R), определяющая некоторую аксиоматическую систему, характеризуется: наличием алфавита (словаря), A; множеством синтаксических правил, V, множеством аксиом, лежащих в основе теории, W; множеством правил вывода, R. Исчисление высказываний (ИВ) и исчисление предикатов (ИП) являются классическими примерами аксиоматических систем. Эти ФС хорошо исследованы и имеют прекрасно разработанные модели логического вывода - главной метапроцедуры в интеллектуальных системах. Поэтому все, что может и гарантирует каждая из этих систем, гарантируется и для прикладных ФС как моделей конкретных предметных областей. В частности, это гарантии непротиворечивости вывода, алгоритмической разрешимости (для исчисления высказываний) и полуразрешимости (для исчислений предикатов первого порядка). ФС имеют и недостатки, которые заставляют искать иные формы представления. Главный недостаток - это "закрытость" ФС, их негибкость. Модификация и расширение здесь всегда связаны с перестройкой всей ФС, что для практических систем сложно и трудоемко. В них очень сложно учитывать происходящие изменения. Поэтому ФС как модели представления знаний используются в тех предметных областях, которые хорошо локализуются и мало зависят от внешних факторов. Под исчислением предикатов понимается формальный язык для представления отношений в некоторой предметной области. Основное преимущество исчисления предикатов - хорошо понятный мощный механизм математического вывода, который может быть непосредственно запрограммирован. Дальнейшее изложение ведется с учетом того, что читатель знаком с основами булевой алгебры.
Предикатом
называют предложение, принимающее
только два значения: "истина" или
"ложь". Для обозначения предикатов
применяются логические связки между
высказываниями: ¬
- не,
Приведем пример простого доказательства на языке исчисления предикатов. Даны следующие факты: 1. "Иван является отцом Михаила" - отец(a,b) 2. "Петр является отцом Василия" - отец(c,d)
3.
"Иван и Петр являются братьями"
-
Даны следующие определения:
4.
"Брат отца является дядей" -
5. "Сын дяди является двоюродным братом"-
Требуется доказать, что "Михаил и Василий являются двоюродными братьями":
6.
Делаем подстановки y = Иван, b = Михаил и x = Петр, d = Василий, видим, что предикаты 1, 2, 3 дают правильное предложение 6.
13. Решение задач методом поиска в пространстве состояний.
Представление задач в пространстве состояний предполагает задание ряда описаний: состояний, множества операторов и их воздействий на переходы между состояниями, целевых состояний. Описания состояний могут представлять собой строки символов, векторы, двухмерные массивы, деревья, списки и т. п. Операторы переводят одно состояние в другое. Иногда они представляются в виде продукций A=>B, означающих, что состояние А преобразуется в состояние В. Пространство состояний можно представить как граф, вершины которого помечены состояниями, а дуги - операторами. Таким образом, проблема поиска решения задачи <А,В> при планировании по состояниям представляется как проблема поиска на графе пути из А в В. Обычно графы не задаются, а генерируются по мере надобности. Различаются слепые и направленные методы поиска пути. Слепой метод имеет два вида: поиск вглубь и поиск вширь. При поиске вглубь каждая альтернатива исследуется до конца, без учета остальных альтернатив. Метод плох для "высоких" деревьев, так как легко можно проскользнуть мимо нужной ветви и затратить много усилий на исследование "пустых" альтернатив. При поиске вширь на фиксированном уровне исследуются все альтернативы и только после этого осуществляется переход на следующий уровень. Метод может оказаться хуже метода поиска вглубь, если в графе все пути, ведущие к целевой вершине, расположены примерно на одной и той же глубине. Оба слепых метода требуют большой затраты времени и поэтому необходимы направленные методы поиска. Метод ветвей и границ. Из формирующихся в процессе поиска неоконченных путей выбирается самый короткий и продлевается на один шаг. Полученные новые неоконченные пути (их столько, сколько ветвей в данной вершине) рассматриваются наряду со старыми, и вновь продлевается на один шаг кратчайший из них. Процесс повторяется до первого достижения целевой вершины, решение запоминается. Затем из оставшихся неоконченных путей исключаются более длинные, чем законченный путь, или равные ему, а оставшиеся продлеваются по такому же алгоритму до тех пор, пока их длина меньше законченного пути. В итоге либо все неоконченные пути исключаются, либо среди них формируется законченный путь, более короткий, чем ранее полученный. Последний путь начинает играть роль эталона и т. д. Алгоритм кратчайших путей Мура. Исходная вершина X0 помечается числом 0. Пусть в ходе работы алгоритма на текущем шаге получено множество дочерних вершин X(xi) вершины xi. Тогда из него вычеркиваются все ранее полученные вершины, оставшиеся помечаются меткой, увеличенной на единицу по сравнению с меткой вершины xi, и от них проводятся указатели к Xi. Далее на множестве помеченных вершин, еще не фигурирующих в качестве адресов указателей, выбирается вершина с наименьшей меткой и для нее строятся дочерние вершины. Разметка вершин повторяется до тех пор, пока не будет получена целевая вершина. Алгоритм Дейкстры определения путей с минимальной стоимостью является обобщением алгоритма Мура за счет введения дуг переменной длины. Алгоритм Дорана и Мичи поиска с низкой стоимостью. Используется, когда стоимость поиска велика по сравнению со стоимостью оптимального решения. В этом случае вместо выбора вершин, наименее удаленных от начала, как в алгоритмах Мура и Дийкстры, выбирается вершина, для которой эвристическая оценка расстояния до цели наименьшая. При хорошей оценке можно быстро получить решение, но нет гарантии, что путь будем минимальным. Алгоритм Харта, Нильсона и Рафаэля. В алгоритме объединены оба критерия: стоимость пути до вершины g[x) и стоимость пути от вершины h(x) - в аддитивной оценочной функции f{x) =g(x}-h(x). При условии h(x)<hp(x), где hp(x)-действительное расстояние до цели, алгоритм гарантирует нахождение оптимального пути. Алгоритмы поиска пути на графе различаются также направлением поиска. Существуют прямые, обратные и двунаправленные методы поиска. Прямой поиск идет от исходного состояния и, как правило, используется тогда, когда целевое состояние задано неявно. Обратный поиск идет от целевого состояния и используется тогда, когда исходное состояние задано неявно, а целевое явно. Двунаправленный поиск требует удовлетворительного решения двух проблем: смены направления поиска и оптимизации "точки встречи". Одним из критериев для решения первой проблемы является сравнение "ширины" поиска в обоих направлениях - выбирается то направление, которое сужает поиск. Вторая проблема вызвана тем, что прямой и обратный пути могут разойтись и чем уже поиск, тем это более вероятно.
18. Мягкие вычисления. Основные свойства мягких систем.
Мягкие вычисления — термин, введенный Лотфи Заде в 1994 году, обозначающий совокупность неточных, приближенных методов решения задач, зачастую не имеющих решение за полиномиальное время. Такие задачи возникают в области биологии, медицины, гуманитарных наук. Это понятие объединяет такие области как: нечеткая логика, нейронные сети, вероятностные рассуждения, сети доверия и эволюционные алгоритмы; которые дополняют друг друга и используются в различных комбинациях или самостоятельно для создания гибридных интеллектуальных систем. Поэтому создание систем работающих с неопределенностью, надо понимать как составную часть "мягких" вычислений. По существу в 1970 году Л.Заде был создан новый метод вычислительной математики, который был поддержан аппаратными средствами (нечеткими процессорами) который в ряде проблемных областей стал более эффективным, чем классические методы. Первоначально эти области входили в проблематику искусственного интеллекта. Постепенно круг этих областей существенно расширился и сформировалось направление "вычислительного интеллекта". В это направление в настоящее время входят:
Нейман первый сформулировал постулат: «стремление получить точную, исчерпывающую модель системы не имеет смысла, т.к. сложность модели (описания) становится соизмеримой со сложностью самого объекта». Лотфи Заде сформулировал эту мысль в виде принципа несовместимости, согласно которому для систем, сложность которых превосходит некоторый пороговый уровень, точность и практический смысл становятся почти исключающими друг друга характеристиками. Глубоко укоренившийся подход решения интеллектуальных задач так, будто это механические системы, описываемые дифференциальными уравнениями, эффекта не дает, поскольку вступает в действие принцип несовместимости: с ростом сложности систем человеческая способность делать точные утверждения о них падает. Основные свойства мягких систем Рассмотрим различные аспекты неполноты информации.
Различие между случайностью и нечеткостью определяют следующим образом: Случайность – неопределенность, касающаяся принадлежности или непринадлежности некоторого объекта к какому-либо множеству. Нечеткость – понятие относящееся к таким множествам, в которых возможны градация степени принадлежности к ним, от полной принадлежности до полной не принадлежности, т.е. такой класс объектов в котором нет резкой границы между объектами с полной принадлежностью к нему и его окружением.
21. Процедура нечеткого логического вывода.
Определение: Нечеткие алгоритмы - это упорядоченное множество нечетких инструкций (правил) в формулировке которых содержатся нечеткие указания (термы). Пример: 1) прибыль = высокая – нечеткое указание (терм, факт) 2) Если Эластичность_Цены = низкая, то Цена = увеличить. Обобщенная схема процедуры нечеткого логического вывода.
Фаззификация (переход к нечеткости) Точные значения входных переменных преобразуются в значения лингвистических переменных посредством применения некоторых положений теории нечетких множеств, а именно - при помощи определенных функций принадлежности. Определение операции фаззификации (fuzzification) Определение: Процесс перехода от четкого представления к нечеткому называется фаззификацией.
Дадим некое подобие алгоритма по формализации задачи в терминах нечеткой логики. Шаг 1. Для каждого терма взятой лингвистической переменной найти числовое значение или диапазон значений, наилучшим образом характеризующих данный терм. Так как это значение или значения являются «прототипом» нашего терма, то для них выбирается единичное значение функции принадлежности. Шаг 2. После определения значений с единичной принадлежностью необходимо определить значение параметра с принадлежностью «0» к данному терму. Это значение может быть выбрано как значение с принадлежностью «1» к другому терму из числа определенных ранее. Шаг 3. После определения экстремальных значений нужно определить промежуточные значения. Для них выбираются П- или Л-функции из числа стандартных функций принадлежности. Шаг 4. Для значений, соответствующих экстремальным значениям параметра, выбираются S- или Z-функции принадлежности. Разработка нечетких правил На этом этапе определяются продукционные правила, связывающие лингвистические переменные. Совокупность таких правил описывает стратегию управления, применяемую в данной задаче. Большинство нечетких систем используют продукционные правила для описания зависимостей между лингвистическими переменными. Типичное продукционное правило состоит из антецедента (часть ЕСЛИ …) и консеквента (часть ТО …). Антецедент может содержать более одной посылки. В этом случае они объединяются посредством логических связок И или ИЛИ.
23. Назначение экспертных систем. Структура экспертных систем.
Под экспертной системой (ЭС) будем понимать программу, которая использует знания специалистов (экспертов) о некоторой конкретной узко специализированной предметной области и в пределах этой области способна принимать решения на уровне эксперта-профессионала. Осознание полезности систем, которые могут копировать дорогостоящие или редко встречающиеся человеческие знания, привело к широкому внедрению и расцвету этой технологии в 80-е, 90-е годы прошлого века. Основу успеха ЭС составили два важных свойства, отмечаемые рядом исследователей:
Основными категориями решаемых ЭС задач являются: диагностика, управление (в том числе технологическими процессами), интерпретация, прогнозирование, проектирование, отладка и ремонт, планирование, наблюдение (мониторинг), обучение. Обобщенная схема ЭС приведена на рис. 6.1. Основу ЭС составляет подсистема логического вывода, которая использует информацию из базы знаний (БЗ), генерирует рекомендации по решению искомой задачи. Чаще всего для представления знаний в ЭС используются системы продукций и семантические сети. Допустим, БЗ состоит из фактов и правил (если <посылка> то <заключение>). Если ЭС определяет, что посылка верна, то правило признается подходящим для данной консультации и оно запускается в действие. Запуск правила означает принятие заключения данного правила в качестве составной части процесса консультации. Обязательными частями любой ЭС являются также модуль приобретения знаний и модуль отображения и объяснения решений. В большинстве случаев, реальные ЭС в промышленной эксплуатации работают также на основе баз данных (БД). Только одновременная работа со знаниями и большими объемами информации из БД позволяет ЭС получить неординарные результаты, например, поставить сложный диагноз (медицинский или технический), открыть месторождение полезных ископаемых, управлять ядерным реактором в реальном времени.
Важную роль при создании ЭС играют инструментальные средства. Среди инструментальных средств для создания ЭС наиболее популярны такие языки программирования, как LISP и PROLOG, а также экспертные системы-оболочки (ЭСО): KEE, CENTAUR, G2 и GDA, CLIPS, АТ_ТЕХНОЛОГИЯ.
------------------------------------------------------------------------------------------- Математическая модель нейрона, её как раз и предложили Маккаллок и Питтс, имеет вид:
Где
Для простоты обычно рассматривают только три типа функции выхода:
сигмоидная функция:
Необходимо
учитывать, что при
----------------------------------------------------------------------------------
Области применения. Экономика и бизнес: прогнозирование курсов валют, объемов продаж, автоматический трейдинг, предсказание банкротств, оценка стоимости недвижимости, выявление переоцененных и недооцененных компаний, считывание и распознавание чеков и документов, безопасность транзакций по пластиковым картам. Медицина: постановка диагноза, обработка медицинских изображений, мониторинг состояния пациента, анализ эффективности лечения, очистка показаний приборов от шумов. Связь: сжатие видеоинформации, быстрое кодирование-декодирование, оптимизация сотовых сетей и схем маршрутизации пакетов. Интернет: ассоциативный поиск информации, электронные секретари и автономные агенты в интернете, фильтрация информации, блокировка спама. Автоматизация производства: оптимизация режимов производственного процесса, контроль качества продукции, мониторинг и визуализация многомерной диспетчерской информации, предупреждение аварийных ситуаций, робототехника. Политологические и социологические технологии: предсказание результатов выборов, анализ опросов, предсказание динамики рейтингов. Безопасность и охранные системы: распознавание лиц; идентификация личности по отпечаткам пальцев, голосу, подписи, лицу; распознавание автомобильных номеров, анализ аэрокосмических снимков, обнаружение вторжений, обнаружение подделок. Ввод и обработка информации: распознавание рукописных текстов, почтовых, платежных, финансовых и бухгалтерских документов. Геологоразведка: анализ сейсмических данных, ассоциативные методики поиска полезных ископаемых, оценка ресурсов месторождений. --------------------------------------------------------------------------------------
|
33. Предпосылки возникновения систем понимания естественного языка. Понимание в диалоге.
Предпосылки возникновения систем понимания естественного языка Мало кто знает, как человек общался с первыми вычислительными машинами. Можно сказать, программирование тогда осуществлялось даже не в машинных командах, а на аппаратном уровне. Потом задача упростилась: последовательность нужных команд стали записывать непосредственно в память машины. Для ввода информации стали применяться более производительные устройства. Затем появились перфокарты. Следом - перфоленты. Скорость общения с машиной возросла, число ошибок, возникающих при вводе, резко уменьшилось. Но сущность этого общения, его характер - не изменились. Возможность впервые пообщаться напрямую появилась на так называемых малых машинах. Неизгладимы впечатления от знакомства с диалоговым интерфейсом. Любой потребитель компьютерных услуг мог, не вдаваясь в технические трудности и выучив всего пару десятков команд операционной системы, общаться с компьютером без посредников. Тогда, впервые возникло такое понятие, как "юзер", и именно появлению диалогового режима история приписывает взлет и расцвет многих компьютерных компаний, таких, например, как DEC. А потом появился его величество интерфейс графический: отпала нужда в знании вообще каких-либо команд, и юзер стал общаться со своим железным другом на интуитивно понятном языке жестов. На горизонте замаячил призрак звукового интерфейса. Понимание в диалоге Как бы то ни было, продолжатся поиски такого интерфейса, который устроил бы всех. На эту роль сейчас претендует интерфейс речевой. Собственно говоря, это как раз то, к чему человечество всегда стремилось в общении с компьютером. Еще в эпоху перфокарт в научно-фантастических романах человек с компьютером именно разговаривал, как с равным себе. Тогда же, в эпоху перфокарт, или даже ранее, были предприняты первые шаги по реализации речевого интерфейса. Работы в этом направлении велись еще в то время, когда о графическом интерфейсе никто даже и не помышлял. За сравнительно короткий период был выработан исчерпывающий теоретический базис, и практические достижения обуславливались только производительностью компьютерной техники. Исследователи недалеко продвинулись за прошедшие десятки лет, что заставляет некоторых специалистов крайне скептически относиться к самой возможности реализации речевого интерфейса в ближайшем будущем. Другие считают, что задача уже практически решена. Впрочем, все зависит от того, что следует считать решением этой задачи. Построение речевого интерфейса распадается на три составляющие. Первая задача состоит в том, чтобы компьютер мог "понять" то, что ему говорит человек, то есть он доложен уметь извлекать из речи человека полезную информацию. Пока что, на нынешнем этапе, эта задача сводится к тому, чтобы извлечь из речи смысловую ее часть, текст (понимание таких составляющих, как скажем, интонация, пока вообще не рассматривается). То есть эта задача сводится к замене клавиатуры микрофоном. Вторая задача состоит в том, чтобы компьютер воспринял смысл сказанного. Пока речевое сообщение состоит из некоего стандартного набора понятных компьютеру команд (скажем, дублирующих пункты меню), ничего сложного в ее реализации нет. Однако вряд ли такой подход будет удобнее, чем ввод этих же команд с клавиатуры или при помощи мыши. Пожалуй, даже удобнее просто щелкнуть мышкой по иконке приложения, чем четко выговаривать (к тому же мешая окружающим): "Старт! Главное меню! Ворд!". В идеале компьютер должен четко "осмысливать" естественную речь человека и понимать, что, к примеру, слова "Хватит!" и "Кончай работу!" означают в одной ситуации разные понятия, а в другой - одно и то же. Третья задача состоит в том, чтобы компьютер мог преобразовать информацию, с которой он оперирует, в речевое сообщение, понятное человеку. Пока окончательное решение существует только для третьей. По сути, синтез речи - это чисто математическая задача, которая в настоящее время решена на довольно хорошем уровне.
37. Основы теории анализа и распознавания изображений.
Пусть
дано множество M
объектов; на этом множестве существует
разбиение на конечное число подмножеств
(классов) Ω,
i
= {1,m},M
=
Пусть задана таблица обучения (таблица 4.1). Задача распознавания состоит в том, чтобы для заданного объекта ω и набора классов Ω1, ..., Ωm по обучающей информации в таблице обучения I0(Ω1...Ωm) о классах и описанию I(ω) вычислить предикаты:
Pi(ω
Рассмотрим алгоритмы распознавания, основанные на вычислении оценок. В их основе лежит принцип прецедентности (в аналогичных ситуациях следует действовать аналогично). Пусть задан полный набор признаков x1, ..., xN. Выделим систему подмножеств множества признаков S1, ..., Sk. Удалим произвольный набор признаков из строк ω1, ω2, ..., ωrm и обозначим полученные строки через Sω1, Sω2, ..., Sωrm, Sω' .
Правило
близости, позволяющее оценить похожесть
строк Sω'
и Sωr
состоит в следующем. Пусть "усеченные"
строки содержат q
первых символов, то есть Sωr=(a1,
..., aq)
и Sω'=(b1,
..., bq)
. Заданы пороги
ε1...εq,
Величины
ε1...εq,
Пусть Гi(ω') - оценка объекта ω' по классу Ωi. Описания объектов {ω'}, предъявленные для распознавания, переводятся в числовую матрицу оценок. Решение о том, к какому классу отнести объект, выносится на основе вычисления степени сходства распознавания объекта (строки) со строками, принадлежность которых к заданным классам известна. Проиллюстрируем описанный алгоритм распознавания на примере. Задано 10 классов объектов (рис. 4.2а). Требуется определить признаки таблицы обучения, пороги и построить оценки близости для классов объектов, показанных на рис. 4.2б. Предлагаются следующие признаки таблицы обучения:
40. Состояние и тенденции развития искусственного интеллекта. Успехи систем искусственного интеллекта и их причины.
По мнению специалистов [1], в недалекой перспективе экспертные системы будут играть ведущую роль во всех фазах проектирования, разработки, производства, распределения, продажи, поддержки и оказания услуг. Их технология, получив коммерческое распространение, обеспечит революционный прорыв в интеграции приложений из готовых интеллектуально-взаимодействующих модулей. Коммерческий рынок продуктов искусственного интеллекта в мире в 1993 году оценивался примерно в 0,9 млрд. долларов; из них 600 млн. приходится на долю США [2]. Выделяют несколько основных направлений этого рынка: 1) экспертные системы; теперь их часто обозначают еще одним термином - "системы, основанные на знаниях"; 2) нейронные сети и "размытые" (fuzzy) логики; 3) естественно-языковые системы. Одно из наиболее популярных направлений последних пяти лет связано с понятием автономных агентов. Их нельзя рассматривать как "подпрограммы", - это скорее прислуга, даже компаньон, поскольку одной из важнейших их отличительных черт является автономность, независимость от пользователя. Идея агентов опирается на понятие делегирования своих функций. Другими словами, пользователь должен довериться агенту в выполнении определенной задачи или класса задач. Всегда существует риск, что агент может что-то перепутать, сделать что-то не так. Следовательно, доверие и риск должны быть сбалансированными. Автономные агенты позволяют существенно повысить производительность работы при решении тех задач, в которых на человека возлагается основная нагрузка по координации различных действий. Следующее направление в области искусственной жизни - генетическое программирование (genetic programming) - является попыткой использовать метафору генной инженерии для описания различных алгоритмов. Строки (string) искусственной "генетической" системы аналогичны хромосомам в биологических системах. Законченный набор строк называется структурой (structure). Структуры декодируются в набор параметров, альтернативы решений или точку в пространстве решений. Строки состоят из характеристик, или детекторов, которые могут принимать различные значения. Детекторы могут размещаться на разных позициях в строке. Все это сделано по аналогии с реальным миром. В природных системах полный генетический пакет называется генотипом. Организм, который образуется при взаимодействии генотипа с окружающей средой, носит название фенотипа. Хромосомы состоят из генов, которые могут принимать разные значения. (Например, ген цвета для глаза животного может иметь значение "зеленый" и позицию 10). Причины, приведшие системы искусственного интеллекта к коммерческому успеху, следующие: 1. Специализация. Переход от разработки инструментальных средств общего назначения к проблемно/предметно специализированным средствам [4], что обеспечивает сокращение сроков разработки приложений, увеличивает эффективность использования инструментария, упрощает и ускоряет работу эксперта, позволяет повторно использовать информационное и программное обеспечение (объекты, классы, правила, процедуры). 2. Использование языков традиционного программирования и рабочих станций. Переход от систем, основанных на языках искусственного интеллекта (Lisp, Prolog и т.п.), к языкам традиционного программирования (С, С++ и т.п.) упростил "интегрированность" и снизил требования приложений к быстродействию и емкости памяти. Использование рабочих станций вместо ПК резко увеличило круг возможных приложений методов искусственного интеллекта. 3. Интегрированность. Разработаны инструментальные средства искусственного интеллекта, легко интегрирующиеся с другими информационными технологиями и средствами (с CASE, СУБД, контроллерами, концентраторами данных и т.п.). 4. Открытость и переносимость. Разработки ведутся с соблюдением стандартов, обеспечивающих данные характеристики [5]. 5. Архитектура клиент/сервер. Разработка распределенной информационной системы в данной архитектуре позволяет снизить стоимость оборудования, используемого в приложении, децентрализовать приложения, повысить надежность и общую производительность, поскольку сокращается объем информации, пересылаемой между ЭВМ, и каждый модуль приложения выполняется на адекватном оборудовании.
41. Язык программирования Turbo Prolog. Основные понятия. Область применения.
Имена отношений и тип переменных, которые ими связываются, задаются в секции программы predicates. Описание фактов и правил задается в секции программы clauses. Кроме отношений факты могут выражать также свойства отдельных объектов. Это кажется естественным, поскольку ощущаемые нами свойства объекта – это ни что иное, как отношение между нами и объектом. Просто в этом случае, мы как созерцатели и способные чувствовать опускаемся в факте, уступая место основному объекту. Например, тот факт, что «Роза(rose) красная(red)» можно записать так: red (rose). Иногда свойства объекта могут выражаться числом. Например, «Ивану 29 лет». Обозначив отношение, как age – возраст, можно записать его так: age (ivan,29). Еще одной особенность Пролога является наличие анонимных переменных, которые используются для игнорирования ненужных вам значений, и обозначаются одиночными символами подчеркивания ("_"). Анонимная переменная может быть использована вместо любой другой переменной. Разница заключается в том, что анонимные переменные никогда не примут какого-либо значения. Анонимные переменные сопоставляются с чем угодно. В большинстве случаев поименованные переменные смогут работать абсолютно равнозначно, однако, их значения не будут служить какой-либо полезной цели. Кроме этого, анонимные переменные могут быть использованы в фактах. Например, факт eats(_). соответствует следующему предложению естественного языка: Все едят (eats). Для обеспечения более компактной записи программ на Турбо Прологе следующие символы и слова в нем являются попарно заменяемыми: "if" и ":-", "and" и ",", "or" и ";". Обычно, программа на Турбо Прологе состоит из трех или четырех основных программных секций. К ним относятся: секция clauses (предложений), секция predicates (предикатов), секция domains (доменов) и, иногда, секция goal (используемая для задания внутренних целей при создании автономных исполняемых программных модулей). Структура программы при этом выглядит следующим образом: domains /* … объявление доменов … */ predicates /* … объявление предикатов … */ clauses /* … предложения (факты и правила) … */ goal /* … подцель №1, подцель №2, и т.д. … */
Менее используемыми секциями программ на Турбо Прологе являются секции database и constants, а также различные глобальные (global) секции. Кроме этого, Пролог позволяет задавать компилятору особые инструкции в форме директив. Секция domains служит для объявления доменов (типов), не являющихся стандартными доменами Турбо Пролога. Основная форма объявления доменов имеет следующий вид: domains аргумент №1, …, аргумент №N = домен №1; аргумент №N+1, …, аргумент №M = домен №2;
Домены в Прологе сходны с типами в Паскале. Они позволяют задавать различные имена различным видам данных. В Турбо Прологе есть несколько встроенных стандартных доменов, основные из которых показаны в Таблице 3.1. Использовать стандартные домены можно при декларации типов аргументов предикатов. Т.к. стандартные домены уже известны Турбо Прологу, их описание в секции domains не требуется.
3. Функциональная структура использования СИИ.
Практически все интеллектуальные системы имеют достаточно простое строение: база знаний о предметной области и механизм интерпретации этих знаний к условиям конкретной задачи. Наиболее интеллектуально сложным и трудоемким считается создание базы знаний. Данные должны иметь определенную структуру, удобную как для кодирования, так и для дальнейшей поисковой работы. Вопросами извлечения знаний и их формализации занимается "инженерия знаний".
Эта структура состоит из трех комплексов вычислительных средств (см. рисунок). Первый комплекс представляет собой совокупность средств, выполняющих программы (исполнительную систему), спроектированных с позиций эффективного решения задач, имеет в ряде случаев проблемную ориентацию. Второй комплекс - совокупность средств интеллектуального интерфейса, имеющих гибкую структуру, которая обеспечивает возможность адаптации в широком спектре интересов конечных пользователей. Третьим комплексом средств, с помощью которых организуется взаимодействие первых двух, является база знаний, обеспечивающая использование вычислительными средствами первых двух комплексов целостной и независимой от обрабатывающих программ системы знаний о проблемной среде. Исполнительная система (ИС) объединяет всю совокупность средств, обеспечивающих выполнение сформированной программы. Интеллектуальный интерфейс - система программных и аппаратных средств, обеспечивающих для конечного пользователя использование компьютера для решения задач, которые возникают в среде его профессиональной деятельности либо без посредников либо с незначительной их помощью. База знаний (БЗ) - занимает центральное положение по отношению к остальным компонентам вычислительной системы в целом, через БЗ осуществляется интеграция средств ВС, участвующих в решении задач.
-------------------------------------------------------------------------------------- И этот процесс носит открытый характер. Понимание в полном объеме - некоторая, по-видимому, недостижимая мечта. Но понимание на уровне "бытового понимания" людей в ИС вполне достижимо. Существуют и другие интерпретации феномена понимания. Можно, например, оценивать уровень понимания по способности системы к объяснению полученного результата. Здесь возможен не только уровень объяснения, когда система объясняет, что она сделала, например, на основе введенного в нее текста, но и уровень обоснования (аргументации), когда система обосновывает свой результат, показывая, что он не противоречит той системе знаний и данных, которыми она располагает. В отличие от объяснения обоснование всегда связано с суммой фактов и знаний, которые определяются текущим моментом существования системы. И вводимый для понимания текст в одних состояниях может быть воспринят системой как истинный, а в других - как ложный. Кроме объяснения и обоснования возможна еще одна функция, связанная с пониманием текстов,- оправдание. Оправдать нечто означает, что выводимые утверждения не противоречат той системе норм и ценностей, которые заложены в ИС. Существующие ИС типа экспертных систем, как правило, способны давать объяснения и лишь частично обоснования. В полном объеме процедуры обоснования и оправдания еще не реализованы.
---------------------------------------------------------------------------------------------
7. Особенности знаний. Переход от базы данных к базе знаний.
В ЭВМ знания так же, как и данные, отображаются в знаковой форме - в виде формул, текста, файлов, информационных массивов и т.п. Поэтому можно сказать, что знания - это особым образом организованные данные. Но это было бы слишком узкое понимание. А между тем, в системах ИИ знания являются основным объектом формирования, обработки и исследования. База знаний, наравне с базой данных, - необходимая составляющая программного комплекса ИИ. Машины, реализующие алгоритмы ИИ, называются машинами, основанными на знаниях, а подраздел теории ИИ, связанный с построением экспертных систем, - инженерией знаний. Особенности знаний:
Между информационными единицами могут устанавливаться и иные связи, например, определяющие порядок выбора информационных единиц из памяти или указывающие на то, что две информационные единицы несовместимы друг с другом в одном описании. Перечисленные три особенности знаний позволяют ввести общую модель представления знаний, которую можно назвать семантической сетью, представляющей собой иерархическую сеть, в вершинах которой находятся информационные единицы. Эти единицы снабжены индивидуальными именами. Дуги семантической сети соответствуют различным связям между информационными единицами. При этом иерархические связи определяются отношениями структуризации, а неиерархические связи - отношениями иных типов.
10. Фреймовые системы представления знаний.
Предложены в 1975 году Марвином Минским. Фрейм (рамка в переводе с англ.) - это единица представления знаний, запомненная в прошлом, детали которой могут быть изменены согласно текущей ситуации. Фрейм представляет собой структуру данных, с помощью которых можно, например, описать обстановку в комнате или место встречи для проведения совещания. М.Минский предлагал эту модель для описания пространственных сцен. Однако с помощью фреймов можно описать ситуацию, сценарий, роль, структуру и т.д. В отличие от моделей других типов во фреймовых моделях фиксируется жесткая структура информационных единиц, которая называется протофреймом. В общем виде она выглядит следующим образом: (Имя фрейма: Имя слота 1(значение слота 1) . . . . . . . . . . . . . . . . . . . . . . Имя слота К (значение слота К)). Значением слота может быть практически что угодно (числа или математические соотношения, тексты на естественном языке или программы, правила вывода или ссылки на другие слоты данного фрейма или других фреймов). В качестве значения слота может выступать набор слотов более низкого уровня, что позволяет во фреймовых представлениях реализовать "принцип матрешки". При конкретизации фрейма ему и слотам присваиваются конкретные имена и происходит заполнение слотов. Таким образом, из протофреймов получаются фреймы - экземпляры. Переход от исходного протофрейма к фрейму - экземпляру может быть многошаговым, за счет постепенного уточнения значений слотов. Например, структура табл. 1.1, записанная в виде протофрейма, имеет вид (Список работников: Фамилия (значение слота 1); Год рождения (значение слота 2); Специальность (значение слота 3); Стаж (значение слота 4)). Если в качестве значений слотов использовать данные табл. 1.1, то получится фрейм - экземпляр (Список работников: Фамилия (Попов - Сидоров - Иванов - Петров); Год рождения (1965 - 1946 - 1925 - 1937); Специальность (слесарь - токарь - токарь - сантехник); Стаж (5 - 20 - 30 - 25)). Связи между фреймами задаются значениями специального слота с именем "Связь". Часть специалистов по ИС считает, что нет необходимости специально выделять фреймовые модели в представлении знаний, т.к. в них объединены все основные особенности моделей остальных типов. Фрейм отражает основные свойства объекта или явления. Рассмотрим запись фрейма на языке FRL (Frame Representation Language) - языке, похожем на LISP, но только внешне из-за наличия скобок. Например, фрейм СТОЛ может быть записан в виде 3 слотов: слот НАЗНАЧЕНИЕ (purpose), слот ТИП (type) и слот ЦВЕТ (colour) следующим образом: (frame СТОЛ (purpose (value(размещение предметов для деятельности рук))) (type (value(письменный))) (colour (value (коричневый)))) Во фрейме СТОЛ представлены только ДЕКЛАРАТИВНЫЕ средства для описания объекта, и такой фрейм носит название фрейм-образец. Однако существуют также фреймы-экземпляры, которые создаются для отображения фактических ситуаций на основе поступающих данных и ПРОЦЕДУРАЛЬНЫХ средств (демонов), например, следующих: IF-DEFAULT - по умолчанию IF-NEEDED - если необходимо IF-ADDED - если добавлено IF-REMOVED - если удалено Слот IS-A или AKO (A Kind Of) определяет иерархию фреймов в сети фреймов. Такая связь обеспечивает наследование свойств. Слот isa указывает на фрейм более высокого уровня, откуда неявно наследуются свойства аналогичных слотов.
14. Решение задач методом редукции.
Этот метод приводит к хорошим результатам потому, что часто решение задач имеет иерархическую структуру. Однако не обязательно требовать, чтобы основная задача и все ее подзадачи решались одинаковыми методами. Редукция полезна для представления глобальных аспектов задачи, а при решении более специфичных задач предпочтителен метод планирования по состояниям. Метод планирования по состояниям можно рассматривать как частный случай метода планирования с помощью редукций, ибо каждое применение оператора в пространстве состояний означает сведение исходной задачи к двум более простым, из которых одна является элементарной. В общем случае редукция исходной задачи не сводится к формированию таких двух подзадач, из которых хотя бы одна была элементарной. Поиск планирования в пространстве задач заключается в последовательном сведении исходной задачи к все более простым до тех пор, пока не будут получены только элементарные задачи. Частично упорядоченная совокупность таких задач составит решение исходной задачи. Расчленение задачи на альтернативные множества подзадач удобно представлять в виде И/ИЛИ-графа. В таком графе всякая вершина, кроме концевой, имеет либо конъюнктивно связанные дочерние вершины (И-вершина), либо дизъюнктивно связанные (ИЛИ-вершина). В частном случае, при отсутствии И-вершин, имеет место граф пространства состояний. Концевые вершины являются либо заключительными (им соответствуют элементарные задачи), либо тупиковыми. Начальная вершина (корень И/ИЛИ-графа) представляет исходную задачу. Цель поиска на И/ИЛИ-графе-показать, что начальная вершина разрешима. Разрешимыми являются заключительные вершины (И-вершины), у которых разрешимы все дочерние вершины, и ИЛИ-вершины, у которых разрешима хотя бы одна дочерняя вершина. Разрешающий граф состоит из разрешимых вершин и указывает способ разрешимости начальной вершины. Наличие тупиковых вершин приводит к неразрешимым вершинам. Неразрешимыми являются тупиковые вершины, И-вершины, у которых неразрешима хотя бы одна дочерняя вершина, и ИЛИ-вершины, у которых неразрешима каждая дочерняя вершина. Алгоритм Ченга и Слейгла. Основан на преобразовании произвольного И/ИЛИ-графа в специальный ИЛИ-граф, каждая ИЛИ-ветвь которого имеет И-вершины только в конце. Преобразование использует представление произвольного И/ИЛИ-графа как произвольной формулы логики высказываний с дальнейшим преобразованием этой произвольной формулы в дизъюнктивную нормальную форму. Подобное преобразование позволяет далее использовать алгоритм Харта, Нильсона и Рафаэля. Метод ключевых операторов. Пусть задана задача <A, B> и известно, что оператор f обязательно должен входить в решение этой задачи. Такой оператор называется ключевым. Пусть для применения f необходимо состояние C, а результат его применения есть I(c). Тогда И-вершина <A,В> порождает три дочерние вершины: <A, C>, <C, f{c)> и <f(c), B>, из которых средняя является элементарной задачей. К задачам <A, С> и <f(c), B> также подбираются ключевые операторы, и указанная процедура редуцирования повторяется до тех пор, пока это возможно. В итоге исходная задача <A, B> разбивается на упорядоченную совокупность подзадач, каждая из которых решается методом планирования в пространстве состояний. Возможны альтернативы по выбору ключевых операторов, так что в общем случае будет иметь место И/ИЛИ-граф. В большинстве задач удается не выделить ключевой оператор, а только указать множество, его содержащее. В этом случае для задачи <A, B> вычисляется различие между A и B, которому ставится в соответствие оператор, устраняющий это различие. Последний и является ключевым. Метод планирования общего решателя задач (ОРЗ). ОРЗ явился первой наиболее известной моделью планировщика. Он использовался для решения задач интегрального исчисления, логического вывода, грамматического разбора и др. ОРЗ объединяет два основных принципа поиска: анализ целей и средств и рекурсивное решение задач. В каждом цикле поиска ОРЗ решает в жесткой последовательности три типа стандартных задач: преобразовать объект А в объект В, уменьшить различие D между А и В, применить оператор f к объекту А. Решение первой задачи определяет различие D второй - подходящий оператор f, третьей - требуемое условие применения С. Если С не отличается от A, то оператор f применяется, иначе С представляется как очередная цель и цикл повторяется, начиная с задачи "преобразовать A в С". В целом стратегия ОРЗ осуществляет обратный поиск-от заданной цели В к требуемому средству ее достижения С, используя редукцию исходной задачи <A, В> к задачам <A, C> и <С, В>. Заметим, что в ОРЗ молчаливо предполагается независимость различий Друг от друга, откуда следует гарантия, что уменьшение одних различий не приведет к увеличению других. 3. Планирование с помощью логического вывода. Такое планирование предполагает: описание состояний в виде правильно построенных формул (ППФ) некоторого логического исчисления, описание операторов в виде либо ППФ, либо правил перевода одних ППФ в другие. Представление операторов в виде ППФ позволяет создавать дедуктивные методы планирования, представление операторов в виде правил перевода - методы планирования с элементами дедуктивного вывода. Дедуктивный метод планирования системы QA3, ОРЗ не оправдал возлагавшихся на него надежд в основном из-за неудовлетворительного представления задач. Попытка исправить положение привела к созданию вопросно-ответной системы QA3. Система рассчитана на произвольную предметную область и способна путем логического вывода ответить на вопрос: возможно ли достижение состояния В из A? В качестве метода автоматического вывода используется принцип резолюций. Для направления логического вывода QA3 применяет различные стратегии, в основном синтаксического характера, учитывающие особенности формализма принципа резолюций. Эксплуатация QA3 показала, что вывод в такой системе получается медленным, детальным, что несвойственно рассуждениям человека. Метод продукций системы STRIPS. В этом методе оператор представляет продукцию Р, А=>В, где Р, А и В - множества ППФ исчисления предикатов первого порядка, Р выражает условия применения ядра продукции А=>В, где В содержит список добавляемых ППФ и список исключаемых ППФ, т. е. постусловия. Метод повторяет метод ОРЗ с тем отличием, что стандартные задачи определения различий и применения подходящих операторов решаются на основе принципа резолюций. Подходящий оператор выбирается так же, как в ОРЗ, на основе принципа "анализ средств и целей". Наличие комбинированного метода планирования позволило ограничить процесс логического вывода описанием состояния мира, а процесс порождения новых таких описаний оставить за эвристикой "от цели к средству ее достижения". Метод продукций, использующий макрооператоры [Файкс и др., 1973]. Макрооператоры-это обобщенные решения задач, получаемые методом STRIPS. Применение макрооператоров позволяет сократить поиск решения, однако при этом возникает проблема упрощения применяемого макрооператора, суть которой заключается в выделении по заданному различию его требуемой части и исключении из последней ненужных операторов.
Процесс вычисления нечеткого правила называется нечетким логическим выводом и подразделяется на два этапа: обобщение и заключение. Пусть мы имеем следующее правило: ЕСЛИ ДИСТАНЦИЯ=средняя И УГОЛ=малый, ТО МОЩНОСТЬ=средняя. Обратимся к примеру с контейнерным краном и рассмотрим ситуацию, когда расстояние до платформы равно 20 метрам, а угол отклонения контейнера на тросе крана равен четырем градусам. После фаззификации исходных данных получим, что степень принадлежности расстояния в 20 метров к терму СРЕДНЯЯ лингвистической переменной ДИСТАНЦИЯ равна 0,9, а степень принадлежности угла в 4 градуса к терму МАЛЫЙ лингвистической переменной УГОЛ равна 0,8. На первом шаге логического вывода необходимо определить степень принадлежности всего антецедента правила. Для этого в нечеткой логике существуют два оператора: MIN(…) и MAX(…). Первый вычисляет минимальное значение степени принадлежности, а второй - максимальное значение. Когда применять тот или иной оператор, зависит от того, какой связкой соединены посылки в правиле. Если использована связка И, применяется оператор MIN(…). Если же посылки объединены связкой ИЛИ, необходимо применить оператор MAX(…). Ну а если в правиле всего одна посылка, операторы вовсе не нужны. Для нашего примера применим оператор MIN(…), так как использована связка И. Получим следующее: MIN(0,9;0,8)=0,8. Следовательно, степень принадлежности антецедента такого правила равна 0,8. Операция, описанная выше, отрабатывается для каждого правила в базе нечетких правил. Следующим шагом является собственно вывод или заключение. Подобным же образом посредством операторов MIN/MAX вычисляется значение консеквента. Исходными данными служат вычисленные на предыдущем шаге значения степеней принадлежности антецедентов правил. После выполнения всех шагов нечеткого вывода мы находим нечеткое значение управляющей переменной. Чтобы исполнительное устройство смогло отработать полученную команду, необходим этап управления, на котором мы избавляемся от нечеткости и который называется дефаззификацией. Методы нечеткого логического вывода. 1. Метод максимума-минимума (Мамдани) а) для одного простого правила П1: Если Т=низкая, то Вентиль=полуоткрыт.
Математическое представление: Если х1=Ai, то y=Bj µBj(y) | x1=x1зад=min {µAi(x1зад); µВj(у)} б1) для одного фокусирующего правила (для логической связки «И») П2: Если Т=низкая И Влажность=средняя, то Вентиль=полуоткрыт.
Математическое представление: Если х1=Ai И х2=Сj, то y=Bk
µBk(y)
|
б2) для логической связки «ИЛИ»
µBk(y)
|
в) для нескольких простых правил П1: Если Т=низкая, то Вентиль=полуоткрыт. П3: Если Т=средняя, то Вентиль=почти открыт.
24. Этапы разработки экспертных систем.
Использовать ЭС следует только тогда, когда разработка ЭС возможна, оправдана и методы инженерии знаний соответствуют решаемой задаче. Чтобы разработка ЭС была возможной для данного приложения, необходимо одновременное выполнение по крайней мере следующих требований: 1) существуют эксперты в данной области, которые решают задачу значительно лучше, чем начинающие специалисты; 2) эксперты сходятся в оценке предлагаемого решения, иначе нельзя будет оценить качество разработанной ЭС; 3) эксперты способны вербализовать (выразить на естественном языке) и объяснить используемые ими методы, в противном случае трудно рассчитывать на то, что знания экспертов будут "извлечены" и вложены в ЭС; 4) решение задачи требует только рассуждений, а не действий; 5) задача не должна быть слишком трудной (т.е. ее решение должно занимать у эксперта несколько часов или дней, а не недель); 6) задача хотя и не должна быть выражена в формальном виде, но все же должна относиться к достаточно "понятной" и структурированной области, т.е. должны быть выделены основные понятия, отношения и известные (хотя бы эксперту) способы получения решения задачи; 7) решение задачи не должно в значительной степени использовать "здравый смысл" (т.е. широкий спектр общих сведений о мире и о способе его функционирования, которые знает и умеет использовать любой нормальный человек), так как подобные знания пока не удается (в достаточном количестве) вложить в системы искусственного интеллекта. При разработке ЭС, как правило, используется концепция "быстрого прототипа". Суть этой концепции состоит в том, что разработчики не пытаются сразу построить конечный продукт. На начальном этапе они создают прототип (прототипы) ЭС. Прототипы должны удовлетворять двум противоречивым требованиям: с одной стороны, они должны решать типичные задачи конкретного приложения, а с другой - время и трудоемкость их разработки должны быть весьма незначительны, чтобы можно было максимально запараллелить процесс накопления и отладки знаний (осуществляемый экспертом) с процессом выбора (разработки) программных средств (осуществляемым инженером по знаниям и программистом). Для удовлетворения указанным требованиям, как правило, при создании прототипа используются разнообразные средства, ускоряющие процесс проектирования. Прототип должен продемонстрировать пригодность методов инженерии знаний для данного приложения. В случае успеха эксперт с помощью инженера по знаниям расширяет знания прототипа о проблемной области. При неудаче может потребоваться разработка нового прототипа или разработчики могут прийти к выводу о непригодности методов ЭС для данного приложения. По мере увеличения знаний прототип может достигнуть такого состояния, когда он успешно решает все задачи данного приложения. Преобразование прототипа ЭС в конечный продукт обычно приводит к перепрограммированию ЭС на языках низкого уровня, обеспечивающих как увеличение быстродействия ЭС, так и уменьшение требуемой памяти. Трудоемкость и время создания ЭС в значительной степени зависят от типа используемого инструментария. В ходе работ по созданию ЭС сложилась определенная технология их разработки, включающая шесть следующих этапов (рис. 1.4): идентификацию, концептуализацию, формализацию, выполнение, тестирование, опытную эксплуатацию. На этапе идентификации определяются задачи, которые подлежат решению, выявляются цели разработки, определяются эксперты и типы пользователей. На этапе концептуализации проводится содержательный анализ проблемной области, выявляются используемые понятия и их взаимосвязи, определяются методы решения задач. На этапе формализации выбираются ИС и определяются способы представления всех видов знаний, формализуются основные понятия, определяются способы интерпретации знаний, моделируется работа системы, оценивается адекватность целям системы зафиксированных понятий, методов решений, средств представления и манипулирования знаниями. На этапе выполнения осуществляется наполнение экспертом базы знаний. В связи с тем, что основой ЭС являются знания, данный этап является наиболее важным и наиболее трудоемким этапом разработки ЭС. Процесс приобретения знаний разделяют на извлечение знаний из эксперта, организацию знаний, обеспечивающую эффективную работу системы, и представление знаний в виде, понятном ЭС. Процесс приобретения знаний осуществляется инженером по знаниям на основе анализа деятельности эксперта по решению реальных задач.
28. Нейронные сети. Типы нейронных сетей. Области применения.
Искусственная нейронная сеть (ИНС, нейросеть) - это набор нейронов, соединенных между собой. Как правило, передаточные функции всех нейронов в сети фиксированы, а веса являются параметрами сети и могут изменяться. Некоторые входы нейронов помечены как внешние входы сети, а некоторые выходы - как внешние выходы сети. Подавая любые числа на входы сети, мы получаем какой-то набор чисел на выходах сети. Таким образом, работа нейросети состоит в преобразовании входного вектора в выходной вектор, причем это преобразование задается весами сети.
Нейронные сети классифицируются следующим образом: I. С точки зрения топологии
б) частично полносвязные 2. С обратными связями(рекурентные) Пример: сеть Элмана
Сеть Жордана(обратные связи через слой)
3. Слабосвязные Пример: сеть Кохонена – самоорганизующиеся карты
II. По типам структур нейронов: 1. Гомогенные – функции активации всех нейронов одинаковые 2. Гетерогенные – функции активации всех нейронов разные
III. По видам сигналов, которыми оперируют нейронные сети
IV. По методу обучения
Собственно обучение сети В процессе обучения сеть в определенном порядке просматривает обучающую выборку. Порядок просмотра может быть последовательным, случайным и т. д. Некоторые сети, обучающиеся без учителя, например, а также сети, обучающиеся с учителем, просматривают выборку множество раз, при этом один полный проход по выборке называется эпохой обучения. При обучении с учителем набор исходных данных делят на две части — собственно обучающую выборку и тестовые данные. Если ошибка на обучающих данных продолжает уменьшаться, а ошибка на тестовых данных увеличивается, значит, сеть перестала выполнять обобщение и просто «запоминает» обучающие данные. Это явление называется переобучением сети или оверфиттингом. В таких случаях обучение обычно прекращают. В процессе обучения могут проявиться другие проблемы, такие как паралич или попадание сети в локальный минимум поверхности ошибок. Проверка адекватности обучения Даже в случае успешного, на первый взгляд, обучения сеть не всегда обучается именно тому, чего от неё хотел создатель.
30. Процесс построения нейронной сети.
Вопрос "как строить НС сеть" решается в два этапа:
На первом этапе следует выбрать следующее:
Эта задача на первый взгляд кажется необозримой, но, к счастью, нам необязательно придумывать нейросеть "с нуля" - существует несколько десятков различных нейросетевых архитектур, причем эффективность многих из них доказана математически. Наиболее популярные и изученные архитектуры - это многослойный перцептрон, нейросеть с общей регрессией, сети Кохонена и другие. На втором этапе нам следует "обучить" выбранную сеть, то есть подобрать такие значения ее весов, чтобы сеть работала нужным образом. Необученная сеть подобна ребенку - ее можно научить чему угодно. В используемых на практике нейросетях количество весов может составлять несколько десятков тысяч, поэтому обучение - действительно сложный процесс. Для многих архитектур разработаны специальные алгоритмы обучения, которые позволяют настроить веса сети определенным образом. Наиболее популярный из этих алгоритмов - метод обратного распространения ошибки (Error Back Propagation), используемый, например, для обучения перцептрона. И еще что-то интересное
Следует рассмотреть подробнее некоторые из этих этапов. Сбор данных для обучения Выбор данных для обучения сети и их обработка является самым сложным этапом решения задачи. Набор данных для обучения должен удовлетворять нескольким критериям:
Исходные данные преобразуются к виду, в котором их можно подать на входы сети. Каждая запись в файле данных называется обучающей парой или обучающим вектором. Кроме того, большую роль играет само представление как входных, так и выходных данных. Используют топологию сети с большим числом выходов, когда каждый выход имеет свой смысл. Чем больше выходов в сети, тем большее расстояние между классами и тем сложнее их спутать. Выбор топологии сети Выбирать тип сети следует исходя из постановки задачи и имеющихся данных для обучения. Для обучения с учителем требуется наличие для каждого элемента выборки «экспертной» оценки. Иногда получение такой оценки для большого массива данных просто невозможно. В этих случаях естественным выбором является сеть, обучающаяся без учителя, например, самоорганизующаяся карта Кохонена или нейронная сеть Хопфилда. При решении других задач, таких как прогнозирование временных рядов, экспертная оценка уже содержится в исходных данных и может быть выделена при их обработке. В этом случае можно использовать многослойный перцептрон или сеть Ворда. Экспериментальный подбор характеристик сети После выбора общей структуры нужно экспериментально подобрать параметры сети. Для сетей, подобных перцептрону, это будет число слоев, число блоков в скрытых слоях (для сетей Ворда), наличие или отсутствие обходных соединений, передаточные функции нейронов. При выборе количества слоев и нейронов в них следует исходить из того, что способности сети к обобщению тем выше, чем больше суммарное число связей между нейронами. Экспериментальный подбор параметров обучения После выбора конкретной топологии, необходимо выбрать параметры обучения нейронной сети. Этот этап особенно важен для сетей, обучающихся с учителем. Например, выбор низкой скорости обучения увеличит время схождения, однако иногда позволяет избежать паралича сети. Увеличение момента обучения может привести как к увеличению, так и к уменьшению времени сходимости.
|
34. Системы речевого общения. Функциональная структура анализатора и синтезатора.
В системах ЕЯ-общения обычно предполагается, что в качестве средства общения используется текст или письменная речь. Поэтому в системах ЕЯ-общения под текстом понимается орфографический текст (как пишется), а в системах речевого общения (СРО) используется фонемный текст (как слышится). В СРО решаются задачи преобразования «текст - речевой сигнал» (синтезатор речи) и «речевой сигнал - текст» (анализатор речи). Синтез речи - это возможность обработки текстовой или числовой информации, согласно установленным правилам произношения для конкретного языка, и преобразование ее в синтезированный голос, по восприятию близкий к человеческому. Анализ речи - это распознавание отдельных слов или слитной человеческой речи, с последующим ее преобразованием в текст либо последовательность команд.
Первые СРО стали появляться в конце 70-х годов. Это было связано со следующими преимуществами СРО:
Обучающие системы, синхронный перевод с одного языка на другой, говорящие книжки, говорящие компьютеры для слепых, управление голосом инвалидными колясками, приборы для генерации и восприятия речи глухонемыми - вот лишь неполный перечень применения СРО. В основе СРО лежит работа с фонемами. Фонема - это минимальная смысловая единица речи. В русском языке 42 фонемы: 6 гласных и 36 согласных. В английском языке 20 гласных (из них 5 дифтонгов) и 24 согласных, во французском - 16 гласных и 20 согласных.
x1- количество вертикальных линий минимального размера; x2- количество горизонтальных линий; x3- количество наклонных линий; x4- количество горизонтальных линий снизу объекта.
На
рис.
4.3 приведена
таблица
обучения
и пороги
ε1=1,
ε2=1,
ε3=1,
ε4=1,
Из этой таблицы видно, что неразличимость символов 6 и 9 привела к необходимости ввода еще одного признака x4.
Теперь
может быть построена таблица
распознавания
для объектов на рис.
4.2б.
Читателю
предлагается самостоятельно ответить
на вопрос: что будет, если увеличить
пороги
ε1,
ε2,
ε3,
ε4,
Заключая данный раздел лекции, отметим важную мысль, высказанную А. Шамисом в работе [55]: качество распознавания во многом зависит от того, насколько удачно создан алфавит признаков, придуманный разработчиками системы. Поэтому признаки должны быть инвариантны к ориентации, размеру и вариациям формы объектов.
Современный искусственный интеллект Некоторые из самых известных ИИ-систем:
Банки применяют системы искусственного интеллекта (СИИ) в страховой деятельности (актуарная математика) при игре на бирже и управлении собственностью. Методы распознавания образов (включая, как более сложные и специализированные, так и нейронные сети) широко используют при оптическом и акустическом распознавании (в том числе текста и речи), медицинской диагностике, спам-фильтрах, в системах ПВО (определение целей), а также для обеспечения ряда других задач национальной безопасности. Разработчики компьютерных игр применяют ИИ в той или иной степени проработанности. Это образует понятие «Игровой искусственный интеллект». Стандартными задачами ИИ в играх являются нахождение пути в двумерном или трёхмерном пространстве, имитация поведения боевой единицы, расчёт верной экономической стратегии и так далее. Перспективы Можно выделить два направления развития ИИ:
В секции predicates объявлются свои предикаты и домены их аргументов. (При этом нет необходимости декларировать предикаты, встроенные в Турбо Пролог.) В этой секции программы просто перечисляются все предикаты с указанием типов (доменов) их аргументов. Объявление предиката начинается с имени этого предиката, за которым следует открывающая (левая) круглая скобка, после чего следует ноль или больше типов аргументов предиката: predicates Имя(аргумент_типа1,аргумент_типа2,..., аргумент_типаN). После каждого типа аргумента следует запятая, а после последнего типа аргумента – закрывающая (правая) скобка. Типами аргументов предиката могут быть либо стандартные домены, либо домены, объявленные в секции domains. Имя предиката должно начинаться с буквы, за которой может следовать последовательность букв, цифр и символов подчеркивания. Регистр букв не имеет значения, однако, использование заглавной буквы в качестве первой буквы имени предиката не является нормой языка. Имя предиката может содержать до 250 символов. В именах предикатов вы не можете использовать буквы русского алфавита, пробел, символ минус, звездочку, прямую (и обратную) черту. Аргументы предикатов должны принадлежать доменам, известным Турбо Прологу. Эти домены могут либо быть стандартными доменами, либо – некоторыми из тех, что вы объявили в секции доменов. Приведем пример, показывающий, как объявление доменов помогает документировать ваши предикаты. Пусть необходимо объявить предикат, раскрывающий следующее предложение естественного языка: Франк – мужчина, которому 45 лет. Используя стандартные домены, можно объявить соответствующий предикат следующим образом: person (symbol,symbol,integer)
Подобное описание является рабочим с точки зрения программы, но не удобным с точки зрения программиста. Напротив, декларация этого же предиката, представленная ниже, поможет программисту разобраться в том, что же представляют собой аргументы данного предиката: domains name,sex=symbol /* name - имя, sex - пол */ age =integer /* age - возраст */
predicates person (name,sex,age)
Одним из главных преимуществ объявления собственных доменов является то, что Турбо Пролог может отслеживать ошибки типов, как, например, при следующей очевидной ошибке: same_sex (X,Y):- person (X,Sex,_), person (Sex,Y,_).
Несмотря на то, что и «name» и «sex» описываются как symbol, они не эквивалентны друг другу. Это и позволяет Турбо Прологу определить ошибку в вышеописанном случае. Данная особенность очень полезна, особенно в случаях, когда программы очень велики и сложны.
4. Интеллектуальный интерфейс. Основные понятия и определения. 5. Интеллектуальный интерфейс. Уровни понимания.
Интеллектуальный интерфейс – система программных и аппаратных средств, обеспечивающих для конечного пользователя использование компьютера для решения задач, возникших в среде профессиональной деятельности, либо без посредников, либо с незначительной их помощью. Интеллектуальный интерфейс - интерфейс непосредственного взаимодействия ресурсов информационного комплекса и пользователя посредством программ обработки текстовых запросов пользователя. Предположим, что на вход ИС поступает текст. Будем говорить, то ИС понимает текст, если она дает ответы, правильные с точки зрения человека, на любые вопросы, относящиеся к тому, о чем говорится в тексте. Под "человеком" понимается конкретный человек-эксперт, которому поручено оценить способности системы к пониманию. Это вносит долю субъективизма, ибо разные люди могут по-разному понимать одни и те же тексты. Классификация уровней понимания В существующих ИС можно выделить пять основных уровней понимания и два уровня метапонимания. Первый уровень характеризуется схемой, показывающей, что любые ответы на вопросы система формирует только на основе прямого содержания, введенного из текста. Если, например, в систему введен текст: "В восемь утра, после завтрака, Петя ушел в школу. В два часа он вернулся домой. После обеда он ушел гулять", то на первом уровне понимания система обязана уметь отвечать правильно на вопросы типа: "Когда Петя ушел в школу?" или "Что сделал Петя после обеда?". В лингвистическом процессоре происходит морфологический, синтаксический и семантический анализ текста и вопросов, относящихся к нему. На выходе лингвистического процессора получается внутреннее представление текста и вопросов, с которыми может работать блок вывода. Используя специальные процедуры, этот блок формирует ответы. Другими словами, уже понимание на первом уровне требует от ИС определенных средств представления данных и вывода на этих данных. Второй уровень: На втором уровне добавляются средства логического вывода, основанные на информации, содержащейся в тексте. Это разнообразные логики текста (временная, пространственная, каузальная и т. п., которые способны породить информацию, явно отсутствующую в тексте. Для нашего примера на втором уровне возможно формирование правильных ответов на вопросы типа: "Что было раньше: уход Пети в школу или его обед?" или "Гулял Петя после возвращения из школы?" Только построив временную структуру текста, ИС сможет ответить на подобные вопросы. Схема ИС, с помощью которой может быть реализован второй уровень понимания, имеет еще одну базу знаний. В ней хранятся закономерности, относящиеся к временной структуре событий, возможной их пространственной организации, каузальной зависимости и т. п., а логический блок обладает всеми необходимыми средствами для работы с псевдофизическими логиками. Третий уровень: К средствам второго уровня добавляются правила пополнения текста знаниями системы о среде. Эти знания в ИС, как правило, носят логический характер и фиксируются в виде сценариев или процедур иного типа. На третьем уровне понимания ИС должна дать правильные ответы на вопросы типа: "Где был Петя в десять утра?" или "Откуда Петя вернулся в два часа дня?" Для этого надо знать, что означает процесс "пребывание в школе" и, в частности, что этот процесс является непрерывным и что субъект, участвующий в нем, все время находится "в школе". Схема ИС, в которой реализуется понимание третьего уровня, внешне не отличается от схемы второго уровня. Однако в логическом блоке должны быть предусмотрены средства не только для чисто дедуктивного вывода, но и для вывода по сценариям. Три перечисленных уровня понимания реализованы во всех практически работающих ИС. Первый уровень и частично второй входят в разнообразные системы общения на естественном языке. Следующие два уровня понимания реализованы в существующих ИС лишь частично. Четвертый уровень: Вместо текста в ней используется расширенный текст, который порождается лишь при наличии двух каналов получения информации. По одному в систему передается текст, по другому - дополнительная информация, отсутствующая в тексте. При человеческой коммуникации роль второго канала, как правило, играет зрение. Более одного канала коммуникации имеют интеллектуальные роботы, обладающие зрением. Зрительный канал коммуникации позволяет фиксировать состояние среды "здесь и сейчас" и вводить в текст наблюдаемую информацию. Система становится способной к пониманию текстов, в которые введены слова, прямо связанные с той ситуацией, в которой порождается текст. На более низких уровнях понимания нельзя понять, например, текст: "Посмотрите, что сделал Петя! Он не должен был брать это!" При наличии зрительного канала процесс понимания становится возможным. При наличии четвертого уровня понимания ИС способна отвечать на вопросы типа: "Почему Петя не должен был брать это?" или "Что сделал Петя?" Если вопрос, поступивший в систему, соответствует третьему уровню, то система выдает нужный ответ. Если для ответа необходимо привлечь дополнительную ("экзегетическую") информацию, то внутреннее представление текста и вопроса передается в блок, который осуществляет соотнесение текста с той реальной ситуацией его порождения, которая доступна ИС по зрительному или какому-нибудь иному каналу фиксации ситуации внешнего мира. Пятый уровень: Для ответа на этом уровне ИС кроме текста использует информацию о конкретном субъекте, являющемся источником текста, и хранящуюся в памяти системы общую информацию, относящуюся к коммуникации (знания об организации общения, о целях участников общения, о нормах участия в общении). Теория, соответствующая пятому уровню – это, так называемая, теория речевых актов. Было обращено внимание на то, что любая фраза не только обозначает некое явление действительности, но и объединяет в себе три действия: локуцию, иллокуцию и перлокуцию. Локуция - это говорение как таковое, т. е. те действия, которые говорящий произвел, чтобы высказать свою мысль. Иллокуция - это действие при помощи говорения: вопрос, побуждение (приказ или просьба) и утверждение. Перлокуция - это действие, которым говорящий пытается осуществить некоторое воздействие на слушающего: "льстить", "удивлять", "уговаривать" и т. д. Речевой акт можно определить как минимальную осмысленную (или целесообразную) единицу речевого поведения. Каждый речевой акт состоит из локутивного, иллокутивного и перлокутивного акта. Для четвертого и пятого уровней понимания интересны результаты по невербальным (несловесным) компонентам общения и психологическим принципам, лежащим в основе общения. Кроме того, в правила пополнения текста входят правила вывода, опирающиеся на знания о данном конкретном субъекте общения, если такие знания у системы есть. Например, система может доверять данному субъекту, считая, что порождаемый им текст истинен. Но может не доверять ему и понимать текст, корректируя его в соответствии со своими знаниями о субъекте, породившем текст. Знания такого типа должны опираться на психологические теории общения, которые пока развиты недостаточно. Первый метауровень: На этом уровне происходит изменение содержимого базы знаний. Она пополняется фактами, известными системе и содержащимися в тех текстах, которые в систему введены. Разные ИС отличаются друг от друга характером правил порождения фактов из знаний. Например, в системах, предназначенных для экспертизы в области фармакологии, эти правила опираются на методы индуктивного вывода и распознавания образов. Правила могут быть основаны на принципах вероятностей, размытых выводов и т. п. Но во всех случаях база знаний оказывается априорно неполной и в таких ИС возникают трудности с поиском ответов на запросы. В частности, в базах знаний становится необходимым немонотонный вывод. Второй метауровень: На этом уровне происходит порождение метафорического знания. Правила порождения знаний метафорического уровня, используемые для этих целей, представляют собой специальные процедуры, опирающиеся на вывод по аналогии и ассоциации. Известные в настоящее время схемы вывода по аналогии используют, как правило, диаграмму Лейбница, которая отражает лишь частный случай рассуждений по аналогии. Еще более бедны схемы ассоциативных рассуждений. Если рассматривать уровни и метауровни понимания с точки зрения архитектуры ИС, то можно наблюдать последовательное наращивание новых блоков и усложнение реализуемых ими процедур. На первом уровне достаточно лингвистического процессора с базой знаний, относящихся только к самому тексту. На втором уровне в этом процессоре возникает процедура логического вывода. На третьем уровне необходима база знаний. Появление нового канала информации, который работает независимо от исходного, характеризует четвертый уровень. Кроме процедур, связанных с работой этого канала, появляются процедуры, увязывающие между собой результаты работы двух каналов, интегрирующие информацию, получаемую по каждому из них. На пятом уровне развитие получают разнообразные способы вывода на знаниях и данных. На этом уровне становятся важными модели индивидуального и группового поведения. На метауровнях возникают новые процедуры для манипулирования знаниями, которых не было на более низких уровнях понимания. 11. Продукционные системы представления знаний.
Под продукцией будем понимать выражение: Если <X1, X2 ... Xn> то <{Y1, D1}, ... {Ym,Dm}>, где: Xi,Yi - логические выражения, Di - фактор достоверности (0,1) или фактор уверенности (0,100). Системы продукций - это набор правил, используемый как база знаний, поэтому его еще называют базой правил. В Стэндфордской теории фактор уверенности CF (certainty factor) принимает значения от +1 (максимум доверия к гипотезе) до -1 (минимум доверия). А.Ньюэлл и Г.Саймон отмечали в GPS, что продукции соответствуют навыкам решения задач человеком в долгосрочной памяти человека. Подобно навыкам в долгосрочной памяти эти продукции не изменяются при работе системы. Они вызываются по "образцу" для решения данной специфической проблемы. Рабочая память продукционной системы соответствует краткосрочной памяти, или текущей области внимания человека. Содержание рабочей области после решения задачи не сохраняется. Работа продукционной системы инициируется начальным описанием (состоянием) задачи. Из продукционного множества правил выбираются правила, пригодные для применения на очередном шаге. Эти правила создают так называемое конфликтное множество. Для выбора правил из конфликтного множества существуют стратегии разрешения конфликтов, которые могут быть и достаточно простыми, например, выбор первого правила, а могут быть и сложными эвристическими правилами. Продукционная модель в чистом виде не имеет механизма выхода из тупиковых состояний в процессе поиска. Она продолжает работать, пока не будут исчерпаны все допустимые продукции. Практические реализации продукционных систем содержат механизмы возврата в предыдущее состояние для управления алгоритмом поиска. Рассмотрим пример использования продукционных систем для решения шахматной задачи хода конем в упрощенном варианте на доске размером 3 x 3. Требуется найти такую последовательность ходов конем, при которой он ставится на каждую клетку только один раз (рис. 2.2). Записанные на рисунке предикаты move(x,y) составляют базу знаний (базу фактов) для задачи хода конем. Продукционные правила - это факты перемещений move, первый параметр которых определяет условие, а второй параметр определяет действие (сделать ход в поле, в которое конь может перейти). Продукционное множество правил для такой задачи приведено ниже. P1: If (конь в поле 1) then (ход конем в поле 8) P2: If (конь в поле 1) then (ход конем в поле 6) P3: If (конь в поле 2) then (ход конем в поле 9)
Рис. 2.2. Шахматная доска 3х3 для задачи хода конем с допустимыми ходами Продукционные системы могут порождать бесконечные циклы при поиске решения. В продукционной системе эти циклы особенно трудно определить, потому что правила могут активизироваться в любом порядке. Например, если в 4-й итерации выбирается правило 8, мы попадаем в поле 3 и зацикливаемся. Самая простая стратегия разрешения конфликтов сводится к тому, чтобы выбирать первое соответствующее перемещение, которое ведет в еще не посещаемое состояние. Следует также отметить, что конфликтное множество это простейшая база целей. В следующей лекции мы рассмотрим различные стратегии поиска в продукционных системах и пути разрешения конфликтов. В заключение данного раздела лекции перечислим основные преимущества продукционных систем:
15.
Методы поиска решений в пространстве
состояний. Алгоритмы эвристического
поиска.
В
рассмотренных примерах поиска решений
число состояний невелико, поэтому
перебор всех возможных состояний не
вызвал затруднений. Однако при
значительном числе состояний время
поиска возрастает экспоненциально,
и в этом случае могут помочь алгоритмы
эвристического поиска,
которые обладают высокой вероятностью
правильного выбора решения. Рассмотрим
некоторые из этих алгоритмов.
Алгоритм
наискорейшего спуска по дереву решений Пример построения более узкого дерева рассмотрим на примере задачи о коммивояжере. Торговец должен побывать в каждом из 5 городов, обозначенных на карте . Задача состоит в том, чтобы, начиная с города А, найти минимальный путь, проходящий через все остальные города только один раз и приводящий обратно в А. Идея метода исключительно проста - из каждого города идем в ближайший, где мы еще не были. Решение задачи показано на рис.
Алгоритм
оценочных (штрафных) функций Умело подобранные оценочные функции (в некоторых источниках - штрафные функции) могут значительно сократить полный перебор и привести к решению достаточно быстро в сложных задачах. В нашей задаче о людоедах и миссионерах в качестве самой простой целевой функции при выборе очередного состояния можно взять число людоедов и миссионеров, находящихся "не на месте" по сравнению с их расположением в описании целевого состояния. Например, значение этой функции f=x+y для исходного состоянияf0=6, а значение для целевого состояния f1=0. Эвристические процедуры поиска на графе стремятся к тому, чтобы минимизировать некоторую комбинацию стоимости пути к цели и стоимости поиска. Основу алгоритма поиска составляет выбор пути с минимальной оценочной функцией.
Алгоритм минимакса В 1945 году Оскар Моргенштерн и Джон фон Нейман предложили метод минимакса, нашедший широкое применение в теории игр. Предположим, что противник использует оценочную функцию (ОФ), совпадающую с нашей ОФ. Выбор хода с нашей стороны определяется максимальным значением ОФ для текущей позиции. Противник стремится сделать ход, который минимизирует ОФ. Поэтому этот метод и получил название минимакса. На рис. 3.5 приведен пример анализа дерева ходов с помощью метода минимакса (выбранный путь решения отмечен жирной линией).
Теоретически,
это эквивалентная минимаксу процедура,
с помощью которой всегда получается
такой же результат, но заметно быстрее,
так как целые части дерева исключаются
без проведения анализа. В основе этой
процедуры лежит идея Дж. Маккарти об
использовании двух переменных,
обозначенных
Основная идея метода состоит в сравнении наилучших оценок, полученных для полностью изученных ветвей, с наилучшими предполагаемыми оценками для оставшихся. Можно показать, что при определенных условиях некоторые вычисления являются лишними
19. Нечеткие множества. Основные определения. Функции принадлежности.
Нечёткое
(или размытое, расплывчатое, туманное,
пушистое) множество
— понятие, введённое Лотфи
Заде в 1965
г. в статье «Fuzzy Sets» (нечёткие множества)
в журнале Information and Control [1]. Л. Заде
расширил классическое канторовское
понятие множества,
допустив, что характеристическая
функция (функция принадлежности
элемента множеству) может принимать
любые значения в интервале [0,1],
а не только значения 0
или 1
Виды функций принадлежности:
По умолчанию считается, что все правила в базе нечетких правил соединены по логической связке «ИЛИ»
Математическое представление: П1: Если х1=Ai, то y=Bj П2: Если х1=Ai+1, то y=Bj+1 µBjВj+1(y) | x1=x1зад=max {µBj(y)| x1=x1зад ; µВj+1(у)| x1=x1зад }
2. Метод максимума произведения а) µBj(y)| x=xзад=µAi(xзад)• µBj(y) б1) и б2) аналогично
Дефаззификация (устранение нечеткости) На этом этапе осуществляется переход от нечетких значений величин к определенным физическим параметрам, которые могут служить командами исполнительному устройству. Результат нечеткого вывода, конечно же, будет нечетким. В примере с краном команда для электромотора крана будет представлена термом СРЕДНЯЯ (мощность), но для исполнительного устройства это ровно ничего не значит. Методы дефаззификации 1. Метод максимума. Выбирается тот элемент нечеткого множества, который имеет максимальную степень принадлежности. 2. Метод левого (правого) максимума. Выбирается наименьший (наибольший) элемент нечеткого множества среди всех элементов имеющих максимальную степень принадлежности.
3. Метод центра тяжести.
4. Модифицированный метод центра тяжести. Уровень (0,05…1) Выполняется -срез (своего рода отсечение шумов). 5. Метод среднего из максимумов.
25. Классификация экспертных систем.
Рассмотрим различные способы классификации ЭС. По назначению ЭС делятся на:
По степени зависимости от внешней среды выделяют:
По типу использования различают:
По сложности решаемых задач различают:
По стадии создания выделяют:
26. Трудности при разработке экспертных систем.
29. Алгоритм обучения НС с обратным распространением ошибки.
Алгоритм обратного распространения — backpropagation algorithm — основывается на многослойной нейронной сети. В нём используется не менее трёх слоёв нейронов. Для простоты мы трёхслойные сети и будем рассматривать. Три слоя: входной, скрытый и выходной.
Таким образом на выходном слое:
на скрытом слое:
где
Процедура
обучения включает представление
набора пар входных и выходных образов.
Т.е. мы должны показать нашей нейросети,
что должно быть на выходе, когда на
входе какая-то комбинация сигналов.
Сначала нейронная сеть на основе
входного образа создаёт собственный
выходной образ, а затем сравнивает
его с целевым выходным образом. Если
различий между фактическим и целевым
образами нет, то обучения не происходит.
В противном случае веса связей
изменяются таким образом, чтобы
различие уменьшилось. Мерой различия
при этом является функция квадрата
ошибки
где
Таким
образом,
Задача алгоритма — добиться минимума этой ошибки, управляя весовыми коэффициентами. Можно воспользоваться градиентным методом наискорейшего спуска. {рисунок}
Я не буду здесь подробно расписывать правила для входных и выходных слоёв, чтобы не загружать вас лишней математикой. А сразу перейду к порядку реализации алгоритма обратного распространения. Алгоритм этот может быть представлен в виде следующих шагов:
Шаг
1.
Присвоить начальные значения величинам
Шаг
2.
Подать на нейронную сеть входной
сигнал. Задать соответствующий ему
желаемый выход
Шаг 3. Изменить веса связей на величину:
Шаг
4.
Вычислить
Шаг 5. Изменить веса связей на величину:
Шаг
6.
Положить
Недостатки алгоритма Паралич сети В процессе обучения сети значения весов могут в результате коррекции стать очень большими величинами. Это может привести к тому, что все или большинство нейронов будут функционировать при очень больших значениях OUT, в области, где производная сжимающей функции очень мала. Локальные минимумы Алгоритм обратного распространения получен на основе градиентного метода наискорейшего спуска и предназначен для поиска минимума ошибки. Это приводит, однако, к поиску локального минимума или точки перегиба. В идеальном же случае должен отыскиваться глобальный минимум, представляющий собой нижнюю точку всей области определения. Размер шага Размер шага должен браться конечным. Если размер шага фиксирован и очень мал, то сходимость слишком медленная, если же он фиксирован и слишком велик, то может возникнуть паралич или постоянная неустойчивость.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||


 Рис.
1.1.
Процесс логического вывода в ИС
Рис.
1.1.
Процесс логического вывода в ИС



 — входные
сигналы (как бы с дендритов);
— входные
сигналы (как бы с дендритов); — весовые
коэффициенты;
— весовые
коэффициенты;
 Рис.
4.1.
Структура системы распознавания
Рис.
4.1.
Структура системы распознавания


 Рис.
6.1.
Структура экспертной системы
Рис.
6.1.
Структура экспертной системы
 ,
, — входной сигнал сети для
— входной сигнал сети для
 -го
нейрона,
-го
нейрона, — вес
смещения,
— вес
смещения, — сила
синаптической связи
— сила
синаптической связи
 -го
нейрона с
-го
нейрона с
 -ым,
-ым, — выходной
сигнал
— выходной
сигнал
 -го
нейрона,
-го
нейрона, — функция
выхода.
— функция
выхода.
 ;
;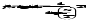 .
.
 сигмоидная функция переходит в
линейную, а при
сигмоидная функция переходит в
линейную, а при
 — в функцию знака.
— в функцию знака.



 =min{min {µAi(x1зад);
µcj(x2зад)};
µBk(y)}
=min{min {µAi(x1зад);
µcj(x2зад)};
µBk(y)} =min{max {µAi(x1зад);
µcj(x2зад)};
µBk(y)}
=min{max {µAi(x1зад);
µcj(x2зад)};
µBk(y)}


 Рис.
5.3.
Анализатор и синтезатор речевых
сообщений в потоке информации
Рис.
5.3.
Анализатор и синтезатор речевых
сообщений в потоке информации Рис.
4.2. Пример
задачи по распознаванию
Рис.
4.2. Пример
задачи по распознаванию Рис.
4.3.
Таблица обучения для задачи по
распознаванию
Рис.
4.3.
Таблица обучения для задачи по
распознаванию



 Альфа-бета-процедура
Альфа-бета-процедура




 ,
где m
–
количество локальных максимумов.
,
где m
–
количество локальных максимумов.



 ,
задаваемая следующим образом:
,
задаваемая следующим образом:

 — желаемый
вход для
— желаемый
вход для
 -й
компоненты
-й
компоненты
 -го
выходного образа,
-го
выходного образа, — соответствующий
фактический выход.
— соответствующий
фактический выход. — мера ошибки вход-выход для
— мера ошибки вход-выход для
 -го
образа, а
-го
образа, а
 — общая мера ошибки.
— общая мера ошибки. ,
,
 ,
,
 ,
,
 ,
,
 и
и
 .
. — это
скорость обучения,
— это
скорость обучения,
 ;
Это константа, представляющая собой
коэффициент пропорциональности между
изменением веса связи и градиентом
ошибки E
относительно веса. Чем больше эта
константа, тем больше изменения в
весах связей.
;
Это константа, представляющая собой
коэффициент пропорциональности между
изменением веса связи и градиентом
ошибки E
относительно веса. Чем больше эта
константа, тем больше изменения в
весах связей. — константа,
определяющая влияние предыдущего
изменения весов на текущее направление
движения в пространстве весов связей.
Учёный с мировым именем Румельхарт
рекомендует использовать величину
альфа, приблизительно равную 0,9.
— константа,
определяющая влияние предыдущего
изменения весов на текущее направление
движения в пространстве весов связей.
Учёный с мировым именем Румельхарт
рекомендует использовать величину
альфа, приблизительно равную 0,9. ,
вычислить
,
вычислить
 ,
,
 и
и
 по формуле:
по формуле: .
. — это
величина обобщённого сигнала ошибки,
задаваемая выражением:
— это
величина обобщённого сигнала ошибки,
задаваемая выражением: .
. .
. по формуле:
по формуле: .
. .
. равным
равным
 и перейти к шагу 2.
и перейти к шагу 2.