

из электронной библиотеки / 887484694831074.pdf
.pdfРисунок 64 - Таблица Клиенты и заказы во второй нормальной форме
Третья нормальная форма
Итак, таблица Клиенты и заказы превратилась у нас в группу связанных таблиц. Благодаря упорядоченности связей в схеме появилась логика: в центре теперь клиент, с которым связаны его заказы и адреса. В свою очередь, с заказами связаны заказанные товары. Но и эта схема все еще не соответствует третьей нормальной форме. Происходит это потому, что в таблице Заказанные товары есть поле Общая стоимость. Это поле получено в результате произведения значений полей Количество штук и Цена за штуку.
База данных находится в третьей нормальной форме, если она находится во второй нормальной форме и все поля ее сущностей не зависят друг от друга1.
Таким образом, чтобы привести полученную группу объектов к третьей нормальной форме,
нужно удалить из таблицы Заказанные товары поле Общая стоимость.
Язык SQL
Математическая реляционная модель данных предполагает, что для манипуляций с данными и сущностями должна использоваться одна из специальных алгебр — реляционная. Для реализации операций реляционной алгебры в СУБД был разработан специальный язык SQL (Structured Query Language — структурированный язык запросов). SQL является декларативным языком программирования. В отличие от процедурных языков программирования, SQL определяет не последовательность процедур, а условия выполнения запроса. При этом запросы могут быть
объемом с простую программу на процедурном языке программирования (от одной строки до нескольких страниц).
Язык SQL содержит несколько групп операторов.
Операторы манипулирования данными
Операторы манипулирования данными позволяют производить извлечение, добавление,
изменение и удаление данных. В группу входят следующие операторы:
□SELECT — оператор извлечения данных.
Пример:
SELECT 'Номер заказа', 'Номер счета', 'Дата заказа' FROM 'Заказы' WHERE 'Номер клиента' - 20
Этот запрос обращается к таблице Заказы, и выбирает из нее все записи, принадлежащие клиенту с номером 20, организуя эти записи в три столбца: Номер заказа, Номер счета, Дата заказа.
□INSERT — оператор добавления данных.
Пример:
INSERT INTO 'Заказы' VALUES (1420, 20, 'Ускоренная доставка', 1221, 15.03.2010)
Этот запрос обращается к таблице Заказы и добавляет к ней запись со значениями полей,
перечисленными в скобках после оператора VALUES.
□UPDATE — оператор изменения данных.
Пример: UPDATE 'Заказы' SET 'Номер счета' = 1432 WHERE 'Номер заказа' - 1220
Этот запрос обращается к таблице Заказы и в записи с номером заказа 1220 изменяет значение поля Номер счета на 1432.
□DELETE — оператор удаления данных.
Пример: DELETE FROM 'Заказы' WHERE 'Номер клиента' - 20
Из таблицы Заказы удаляются строки с номером клиента 20 (то есть все заказы данного клиента).
Операторы определения данных
Операторы определения данных позволяют манипулировать схемой базы данных, то есть создавать объекты базы данных (таблицы, представления, триггеры, хранимые процедуры,
индексы, ключи, ограничения, и т. д.).
□CREATE (TABLE, VIEW, TRIGGER, INDEX, STORED PROC) — создает указанный объект базы
данных.
□DROP (TABLE, VIEW, TRIGGER, INDEX, STORED PROC) — уничтожает указанный объект базы
данных.
□ALTER (TABLE, VIEW, TRIGGER, INDEX, STORED PROC) — изменяет структуру указанного объекта базы данных.
Операторы управления данными
К операторам управления данными относятся операторы назначения прав доступа и управления транзакциями, а также операторы создания баз данных и изменения структуры данных.
□GRANT — предоставляет привилегии пользователям.
Пример: GRANT SELECT ON 'Заказы' ТО NEKT0
Разрешает пользователю NEKT0 выполнять запросы на выборку данных к таблице Заказы. При этом пользователь не получает привилегий, позволяющих ему изменять данные в этой таблице или в структуре таблицы.
□REVOKE — аннулирует привилегии.
Пример: REVOKE ALL ON 'Заказы' FROM NEKTO
Лишает пользователя NEKTO всех привилегий в таблице Заказы.
□COMMIT — подтверждает транзакцию.
□ROLLBACK—отменяеттранзакцию.
□CREATE DATABASE — создает базу данных.
□ALTER DATABASE — изменяет базу данных.
□DROP DATABASE — уничтожает базу данных.
В данном разделе перечислены только основные операторы языка SQL. Даже в стандартной реализации их гораздо больше. Однако ограничения, накладываемые декларативным характером языка, вынуждают производителей СУБД создавать расширенные версии SQL. Примерами таких расширенных версий могут служить Transact SQL для MS SQL Server или PL/SQL для ORACLE. В
этих расширениях в язык включены операторы для организации ветвлений, циклов, и т. д.
Преимущества и недостатки реляционной модели
Структурная независимость. Поскольку в реляционной модели баз данных навигационная схема доступа к данным не используется, маршрут доступа к данным не имеет значения для проектировщиков, программистов и конечных пользователей реляционной базы данных. Изменения в структуре реляционной БД не влияют на доступ к данным со стороны СУБД. Поэтому в реляционной модели базы данных достигается структурная независимость, не свойственная сетевым и иерархическим моделям. Структурная независимость имеет место, когда изменения в структуре БД не влияют на возможности доступа к данным со стороны СУБД. В отличие от реляционной базы данных, любые изменения в древовидной структуре иерархической базы данных или во множествах баз сетевой БД влияют на маршруты доступа к данным, что требует изменения всех прикладных программ.
Концептуальная простота. Реляционная модель на концептуальном уровне проста для понимания. Поскольку реляционная модель позволяет полностью избавиться от подробностей физического хранения данных, пользователи могут полностью сосредоточиться на логическом представлении базы данных, то есть уделять большее внимание естественному представлению о хранении.
Простота проектирования, реализации, управления и использования. Поскольку в реляционной модели достигаются и независимость по данным, и структурная независимость,
становится проще проектировать базу и управлять ее содержимым.
Нерегламентированные запросы. Одним из главных факторов, позволивших реляционным базам данных занять доминирующее положение на рынке, была возможность применять гибкий и унифицированный механизм создания запросов. Для большей части программного обеспечения реляционных БД стандартным языком запросов является язык SQL. SQL относится к так называемым языкам четвертого поколения (4GL), которые дают пользователям возможность определить, что делать, не указывая, как именно это делать. В РСУБД язык SQL применяется при трансляции запроса пользователя в специальный код, необходимый для извлечения запрошенной информации. Следовательно, запросы в реляционной базе данных требуют меньшего программирования, чем в любой другой базе или в файловой системе.
Любое SQL-приложение реляционной БД состоит из трех частей: интерфейса пользователя,
набора таблиц внутри БД и SQL-машины (SQL-engine). Интерфейс включает в себя систему меню,
команды запросов и генераторы отчетов. В основном такой интерфейс дает возможность конечному пользователю взаимодействовать с данными. С помощью генераторов приложений, которые сегодня являются стандартными средствами, входящими в состав многих РСУБД, пользователь может разрабатывать собственные интерфейсы.
В значительной степени скрытая от конечного пользователя SQL-машина выполняет большую работу. Внутри РСУБД SQL-машина служит для создания структуры таблиц, обслуживания словаря данных и системного каталога, обеспечения доступа к таблицам БД, а также для трансляции запроса пользователя в формат, пригодный для обработки компьютером.
Мощная система управления базой данных. Хорошая РСУБД является более сложной частью программного обеспечения, нежели СУБД иерархических и сетевых баз данных. Это связано с тем, что она решает гораздо больше (и значительно более сложных) задач как для проектировщиков, так и для пользователей. РСУБД полностью скрывает физический уровень сложности системы от проектировщика и конечного пользователя.
Несмотря на существенные преимущества реляционной модели перед иерархической или сетевой, она имеет некоторые недостатки. Один из них — это существенные требования к оборудованию и системному программному обеспечению. На самом деле это не столько
недостаток, сколько вполне справедливая плата за те преимущества, которые получают пользователи, программисты и администраторы.
5.2.3. Постреляционные модели
По мере того как практические задачи приобретают все более сложный и комплексный характер, а информационные системы все больше склонны проявлять интеллектуальное поведение при взаимодействии с окружающим миром, необходимы более совершенные модели данных. Такие модели должны точнее описывать окружающий мир: уже не в терминах наборов данных, а в терминах объектов, обладающих свойствами, состояниями и поведением.
Первой из таких моделей стала семантическая модель данных (Semantic Data Model, SDM),
разработанная M. Хаммером и Д. Маклеодом в 1981 г. SDM позволяет моделировать как данные, так и их отношения в единой структуре, называемой объектом. Поскольку основной структурой модели является объект, модель SDM получила название объектно-ориентированной модели данных
(Object-Oriented Data Model, OODM). В свою очередь, OODM стала основой для создания объектно-ориентированной модели базы данных (OODBM), управление которой осуществляется с помощь системы управления объектно-ориентированной базой данных (ООСУБДИЛИ OODBMS).
Объект может включать в себя все данные о себе, связи с другими объектами и операции,
которые могут выполняться с объектом (или выполняться объектом). Таким образом, объекты в усовершенствованной модели SDM стали похожи на объекты, создаваемые объектно-
ориентированными языками. Это, в свою очередь, обеспечило возможность сближения и тесной интеграции различных групп разработчиков, как проектировщиков и архитекторов базы данных, так и программистов, разрабатывающих пользовательские программы.
Рисунок 65 иллюстрирует такую методологию работы, когда различные группы разработчиков, вовлеченные в процесс обеспечения работы ООСУБД, используют общий репозиторий (хранилище) классов для решения различных задач на различных этапах работы над проектом.
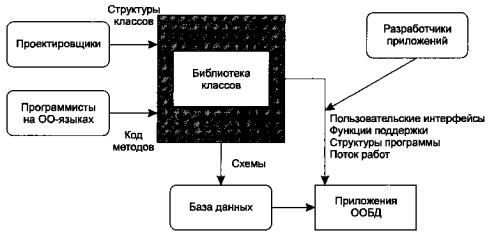
Рисунок 65 - Методология совместной разработки в парадигме ООБД
Основные понятия OODM
Объекты модели данных являются абстракцией сущностей и событий реального мира. В
общих чертах любой объект может рассматриваться как эквивалент сущности ER-модели. Точнее,
любой объект представляет собой только один экземпляр сущности.
Атрибуты описывают свойства объекта. Например, в объект PERSON (персона) включены атрибуты Name (имя), Social Security Number (номер социального страхования) и Date of Birth (дата рождения).
Объекты, которые совместно используют одни и те же характеристики, группируются в классы. Класс представляет собой абстрактное представление схожих объектов со структурой совместного доступа (атрибутами) и поведением (методами). В общем случае класс напоминает набор сущностей ER-модели. Однако класс отличается от набора сущностей тем, что содержит набор процедур, называемых методами. Метод класса представляет собой некоторое действие, например,
поиск, изменение данных или распечатку данных. Иначе говоря, методы эквивалентны процедурам
втрадиционных языках программирования. В терминах объектно-ориентированного подхода методы определяют поведение объекта.
Классы организованы в иерархию классов. Иерархия классов похожа на перевернутое дерево,
вней каждый класс имеет только одного предка (явное сходство с иерархической моделью).
Наследование — это возможность объекта внутри иерархии классов наследовать атрибуты и
методы классов, структурно расположенных выше него.
Преимущества OODM
Объектно-ориентированная модель имеет несколько важнейших преимуществ перед ER-
моделью.
Добавление семантического наполнения делает модель более значимой и информационно-
насыщенной.
Семантическое наполнение включено во внешнее представление. Как и ER-диаграммы,
объектно-ориентированная модель представляет отношения в наглядной форме. Однако в наглядное представление объектно-ориентированной модели включается семантическое наполнение, что упрощает визуализацию сложных отношений между объектами.
Целостность базы данных. Так же как и иерархическая, объектно-ориентированная модель использует наследование для защиты целостности базы данных. Однако объекты OODM содержат большее количество типов связей, а сами связи являются более сложными.
Структурная независимость и независимость по данным. Автономия объекта объектно-
ориентированной модели гарантирует структурную независимость и независимость по данным.
Недостатки OODM
Несмотря на то что OODM является безусловным шагом вперед по сравнению с реляционной моделью, подавляющее число СУБД на сегодняшний день продолжают оставаться реляционными.
Причин этому множество, и не последнюю роль сыграли недостатки, свойственные OODM.
Отсутствие должного уровня стандартизации. Для OODM пока не существует стандартов объектно-ориентированной модели. Различные стандарты, связанные с OODM, находятся в активной разработке, работа над ними продолжается, однако они не являются столь распространенными, как стандарты для РСУБД. Происходит сближение стандартов для РСУБД с ООСУБД, например, в стандарте SQL3 и более поздних. Особенно проблематичным является отсутствие стандартного метода доступа к данным. Этот недочет создает проблемы при доступе к данным из различных источников (различные поставщики поддерживают различные методы доступа к данным, как правило, несовместимые).
Сложная навигация доступа к данным. Метод доступа к данным напоминает стиль навигации в иерархической и сетевой моделях.
Трудность изучения. Недостаток стандартизации и трудности, вызванные навигационным стилем доступа к данным, приводят к затруднениям в изучении объектно-ориентированной модели, даже большим, чем при изучении сетевой модели. Несмотря на то что мы с легкостью используем объекты — перетаскиваем объекты на экране дисплея, не заботясь и не задумываясь о тех процессах, которые обеспечивают это действие, — моделирование данных и реализация объектно-
ориентированных баз данных — это совершенно иные действия.
Объекты сложны, и тот факт, что они могут иметь большое семантическое наполнение,
делает их трудными для проектирования и реализации. Работа с OODM больше похожа на объектно-ориентированное программирование, чем на проектирование данных. Это приводит к тому, что конечные пользователи считают объектно-ориентированные системы трудными для понимания и применения.
Ресурсоемкость. Объектно-ориентированные системы сложнее, чем реляционные модели.
Реализация такой модели требует солидных затрат на приобретение оборудования и операционной системы. Сложность конфигурации и повышенные системные требования приводят к замедлению выполнения запросов и транзакций.
5.3Проектирование баз данных
Проектирование баз данных, как и проектирование информационных систем, состоит из нескольких этапов. Одним из важных этапов проектирования является создание диаграмм
«сущность-связь». Для этого необходимо обозначить сущности, добавить к ним атрибуты, установить ключи и объединить сущности при помощи связей. Все это можно проделывать вручную, просто рисуя соответствующие диаграммы на бумаге. В те времена, когда была предложена концепция
«сущность-связь», так и делали, однако при наличии компьютера с развитым графическим интерфейсом рисунки на бумаге отошли в прошлое. Довольно быстро был создан целый класс программных продуктов, позволяющий не только выполнять моделирование в парадигме
«сущность-связь», но и генерировать на основе созданных моделей схему базы данных для практически любых распространенных серверов баз данных. Одной из таких программ является
ErWin Data Modeler (рисунок 66).
Рисунок 66 - Окно программы ErWin Data Modeler
При помощи этой программы можно быстро и легко создавать сущности, присваивать им атрибуты, ключи, создавать между ними связи. После того как схема создана, можно выбрать конкретный сервер баз данных и построить схему базы данных. При этом ErWin Data Modeler
переводит созданную логическую модель на физический уровень представления и генерирует схему в соответствии с набором типов данных на конкретном выбранном сервере. Этот процесс носит название прямого проектирования (forward engineering).
Интересной особенностью ErWin Data Modeler является также возможность осуществить обратную операцию: извлечь схему из выбранного сервера баз данных и отобразить ее в качестве своей модели. Извлеченную схему можно затем изменить и снова осуществить прямую генерацию.
Надо отметить, что современные серверы баз данных часто оснащаются средствами моделирования модели «сущность-связь» или другими средствами создания схем баз данных.
6Глобальная компьютерная сеть Интернет
Вдословном переводе на русский язык интернет — это межсеть, то есть в узком смысле слова интернет — это объединение сетей. Однако в последние годы у этого слова появился и более широкий смысл: Всемирная компьютерная сеть. Интернет можно рассматривать в физическом смысле как несколько миллионов компьютеров, связанных друг с другом всевозможными линиями связи, однако такой «физический» взгляд на Интернет слишком узок. Лучше рассматривать Интернет как некое информационное пространство.
Рисунок 67 - Простейшая модель службы передачи сообщений
Интернет — это не совокупность прямых соединений между компьютерами. Так,
например, если два компьютера, находящиеся на разных континентах, обмениваются данными в Интернете, это совсем не значит, что между ними действует одно прямое или виртуальное соединение. Данные, которые они посылают друг другу, разбиваются на пакеты, и даже в
одном сеансе связи разные пакеты одного сообщения могут пройти разными маршрутами.
Какими бы маршрутами ни двигались пакеты данных, они все равно достигнут пункта назначения и будут собраны вместе в цельный документ. При этом данные, отправленные позже, могут приходить раньше, но это не помешает правильно собрать документ, поскольку каждый пакет имеет свою маркировку.
Таким образом, Интернет представляет собой как бы «пространство», внутри которого осуществляется непрерывная циркуляция данных. В этом смысле его можно сравнить с теле- и
радиоэфиром, хотя есть очевидная разница хотя бы в том, что в эфире никакая информация храниться не может, а в Интернете она перемещается между компьютерами, составляющими
узлы сети, и какое-то время хранится на их жестких дисках.
Теоретические основы интернета
Ранние эксперименты по передаче и приему информации с помощью компьютеров начались еще в 50-х годах и имели лабораторный характер. Лишь в конце 60-х годов на средства Агентства Перспективных Разработок министерства обороны США (DARPA — Defense Advanced Research Project Agency) была создана первая сеть национального масштаба.
По имени агентства она получила название ARPANET. Эта сеть связала несколько крупных научных, исследовательских и образовательных центров. Ее основной задачей стала координация групп коллективов, работающих над едиными научно-техническими проектами, а
основным назначением стал обмен электронной почтой и файлами с научной и проектно-
конструк-торской документацией.
Сеть ARPANET заработала в 1969 году. Немногочисленные узлы, входившие в нее в то время, были связаны выделенными линиями. Прием и передача информации обеспечивались программами, работающими на узловых компьютерах. Сеть постепенно расширялась за счет подключения новых узлов, а к началу 80-х годов на базе наиболее крупных узлов были созданы свои региональные сети, воссоздающие общую архитектуру ARPANET па более низком уровне
(в региональном или локальном масштабе).
Всякий раз, когда мы говорим о вычислительной технике, нам надо иметь в виду принцип единства аппаратного и программного обеспечения. Пока глобальное расширение
ARPANET происходило за счет механического подключения все новых и новых аппаратных средств (узлов и сетей), до Интернета в современном понимании этого слова было еще очень далеко. По-настоящему рождением Интернета принято считать 1983 год. В этом году произошли революционные изменения в программном обеспечении компьютерной связи. Днем рождения Интернета в современном понимании этого слова стала дата стандартизация протокола связи TCP/IP, лежащего в основе Всемирной сети по нынешний день.
Здесь требуется уточнить, что в современном понимании TCP/IP — это не один сетевой