

g30zAZLYUG
.pdfКак средняя, так и максимальная временная сложность алгоритма древесной сортировки составляет O(n∙log(n)).
Обзор сортировок распределением
Это единственный вид сортировки, при котором не требуется срав-
нивать ключи сортируемых элементов.
Пусть известно, что ключами могут служить только целые неотрицательные числа, максимальное из которых не превосходит некоторое натуральное число m, причём m не слишком велико по сравнению с n.
Одна из разновидностей сортировки распределением – это сортировка вычерпыванием, которая заключается в следующем:
1.организовать m+1 пустых очередей (черпаков) по одной для каждого числа от 0 до m;
2.просмотреть сортируемый массив слева направо, помещая элемент a[j], имеющий ключ a[j].key = i в очередь с номером i;
3.сцепить эти очереди, т.е. содержимое (i+1)-й очереди приписать к
концу i-й очереди (i = 0,1,... m 1).
Так как каждый элемент можно вставить в i-ю очередь за время O(1), то n элементов можно распределить по очередям за время O(n). Конкатенация (сцепление) m очередей требует времени O(m). Таким образом, этот алгоритм сортирует n натуральных чисел за линейное время
T(n, m) = O(n+m),
т.е. является самым быстрым среди всех известных сортировок.
Пусть сортируется последовательность целых неотрицательных чисел, т.е. каждая запись сортируемого массива содержит только одно поле − поле ключа. В этом случае можно существенно облегчить реализацию алгоритма сортировки вычерпыванием, если вместо очередей организовать массив счётчиков: count[0], count[1], …, count[m]. Сначала значение каждого счётчика равно 0. При просмотре массива вместо добавления элемента a[j] = i в очередь с номером i надо увеличить значение i-го счётчика на единицу, а вместо сцепления очередей распечатать элемент i в точности count[i] раз. Такая разновидность сортировки вычерпыванием получила на-
звание цифровой сортировки.
Если вместо массива целых неотрицательных чисел сортируется массив записей с несколькими полями, то цифровую сортировку необходимо модифицировать, т.к. в противном случае не ключевые поля в процессе сортировки будут утеряны.
Познакомимся с модификацией цифровой сортировки, называемой
сортировкой подсчётами.
61

При первом проходе массива выясним, сколько и каких значений ключа имеется, затем заново распределим позиции исходного массива и при втором проходе расставим записи в соответствии с этим распределением. Подробнее:
1.организовать массив счетчиков: count[0], count[1], …, count[m]. Сначала значение каждого счетчика равно 0;
2.скопировать исходный массив А во вспомогательный массив В;
3.осуществить первый просмотр массива В; если b[j].key = i, то увеличить count[i] на единицу;
4.накопить сумму, с тем, чтобы найти будущие границы count[i] групп записей с одинаковым значением ключа:
for (i=1; i<=m; i++) {count[i]+ = count[i-1];};.
Если в массиве несколько записей имеют ключ i, то значение count[i] теперь определяет позицию последней такой записи;
5. при втором просмотре массива В j-ю запись переместить в её новую позицию count[b[j].key] массива А, а значение count[b[j].key] уменьшить на единицу.
Программные коды рассмотренных выше сортировок приведены в Приложении.
п. 1. Сортировка динамического массива записей
Займёмся сортировкой (поочерёдно по каждому из полей) динамического массива записей. В качестве входного файла возьмём известный Вам по лабораторной работе № 1 файл с именем StudPmi.
1.1.Отработав пункты 1.1 – 1.7 лабораторной работы № 2, создайте новый проект с именем, например, lab_04.
1.2.Скопируйте текстовый файл с именем StudPmi в папку вновь созданного проекта (туда же, где размещены cpp-файлы).
1.3.В раздел подключений добавьте библиотеку для работы с файлами и библиотеку для работы с динамическим массивом:
#include <fstream> #include <vector>
1.4.Откройте текст лабораторной работы № 1 и отработайте пункты
7.2– 7.6. Выполнив эти действия, Вы прочитали записи из входного файла и разместили их в динамическом массиве с именем myArray.
1.5.Поле, по которому производится сортировка, будем называть ключевым. Записи в массиве с именем myArray состоят из трёх полей, первые два из которых – строковые, а третье – целочисленное. Начнём сорти-
62

ровку с того, что проще, а именно: с третьего, числового, поля «ball». На данном этапе именно оно и является ключевым.
Непосредственно перед процедурой main (после объявления глобальных переменных) вставьте процедуру сортировки массива по третьему полю методом Шелла.
void Sort_Shell_3() // Сортировка Шелла h-серий по полю "ball"
{
int h,i,j,k,key;
// Запись buf используется в качестве буфера для i-й записи
MyRecord buf;
if (myArray.size()>1) // Если есть, что сортировать
{ // Начальное значение h зависит от количества записей for (h=1; h<(myArray.size()/9); h=3*h+1);
while (h>0)
{
for (k=0; k<h; k++)
{
for (i=k+h; i<myArray.size(); i+=h)
{
buf=myArray[i]; key=myArray[i].ball; // Ищем место для вставки
for (j=i-h; j>=0 && key<myArray[j].ball; j-=h)
{
// Сдвигаем элементы вправо myArray[j+h]=myArray[j];
};
// Устанавливаем i-й элемент на своё место относительно предыдущих myArray[j+h]=buf;
}
}
h/=3;
}
}
}
Для хранения значения в ключевом поле i-й записи, перемещаемой на i-м шаге на своё место среди предыдущих элементов, в процедуре используется локальная переменная key. Просмотрите текст процедуры, чтобы убедиться, что
переменная key объявлена как целочисленная, т.к. сортировка производится по целочисленному полю «ball»:
int h,i,j,k,key;
63

в неё перегружается значение ключевого поля i-й записи: key=myArray[i].ball;
она задействована в условии внутреннего цикла: key<myArray[j].ball;
Именно эти фрагменты придётся редактировать, когда мы перейдём
ксортировке массива по другим полям.
1.6.В текст процедуры main добавьте вызов сортировки Шелла и вывод на экран массива, отсортированного по третьему полю:
Sort_Shell_3();
cout << "Массив, отсортированный по третьему полю:\n"; for (i=0; i<myArray.size(); i++)
{
cout << myArray[i].surname << "\t" << myArray[i].name << "\t" << myArray[i].ball << "\n";
};
Запустите программу на выполнение, чтобы убедиться, что она работает правильно.
1.7. Приступим к сортировке массива по первому, строковому полю. Соответственно, на этом этапе ключевым является поле «surname». Начните с того, что просто скопируйте текст процедуры Sort_Shell_3, разместив копию выше (или ниже – не принципиально) оригинала. А теперь внесём во вновь созданную копию необходимые изменения.
1.7.1.Переименуйте Sort_Shell_3 в Sort_Shell_1.
1.7.2.Все остальные изменения касаются упомянутой выше локальной переменной key. Ключевое поле теперь строковое; поэтому убираем объявление переменной key из строки int и объявляем эту переменную, как строковую, причём её длина определяется длиной того поля, по которому производится сортировка. Замените строку
int h,i,j,k,key;
следующими строками:
int h,i,j,k; char key[24];
1.7.3. Теперь надо изменить строку key=myArray[i].ball;
64

Если в этом операторе просто заменить myArray[i].ball на myArray[i].surname, то ничего хорошего из этого не выйдет, т.к. в С++ прямое присваивание для строковых переменных не работает.
Напомню, что здесь надо воспользоваться функцией strcpy(s1, s2), которая копирует содержимое строки s2 в строку s1:
strcpy(key,myArray[i].surname);
1.7.4. Отсталость поменять одно из условий продолжения внутреннего цикла. Для сравнения строковых переменных воспользуемся функцией strcmp(s1,s2). Замените фрагмент
key<myArray[j].ball;
следующим кодом:
strcmp(key,myArray[j].surname)==-1;
1.8.В текст процедуры main добавьте вызов процедуры Sort_Shell_1
ивывод на экран массива, отсортированного по первому полю.
Запустите программу на выполнение, чтобы убедиться, что она работает правильно.
1.9.Аналогичным образом самостоятельно организуйте сортировку массива по второму полю. Результат (код и выведенный на консоль отсортированный по второму полю массив) покажите преподавателю.
1.10.Прежде чем переходить к выполнению задания № 1, сохраните проект под другим именем, например, lab_05_part1, т.к. он понадобится Вам в процессе выполнения следующей лабораторной работы.
Закройте проект lab_05_part1, снова откройте проект lab_04 и можете переходить к выполнению задания № 1, соответствующего номеру Вашего варианта.
ЗАДАНИЕ № 1. Сортировка динамического массива записей
Разработайте консольное приложение, в котором необходимо выполнить следующие действия:
прочитать набор записей, соответствующих номеру Вашего варианта (см. задание № 1 лабораторной работы № 1) из входного текстового файла и разместить их в динамическом массиве;
отсортировать (поочерёдно) массив по каждому из четырёх полей
методом, указанным в Вашем варианте (см. ниже);
результат каждой сортировки записать в выходной текстовый файл. Работающую версию программы, а также программный код, предъя-
вите преподавателю.
65
Программные коды всех упоминаемых ниже сортировок см. в Приложении.
Вариант № 1. Использовать сортировку подсчётами.
Замечание. Сортировать только по целочисленным полям.
Вариант № 2. Использовать сортировку слиянием. Вариант № 3. Использовать быструю сортировку. Вариант № 4. Использовать древесную сортировку.
Вариант № 5. Использовать сортировку простыми вставками.
Вариант № 6. Использовать сортировку Шелла. В качестве h-последовательности взять последовательность Кнута.
Вариант № 7. Использовать сортировку слиянием. Вариант № 8. Использовать быструю сортировку. Вариант № 9. Использовать древесную сортировку.
Вариант № 10. Использовать сортировку посредством простого выбора
Вариант № 11. Использовать сортировку подсчётами
Замечание. Сортировать только по целочисленным полям.
Вариант № 12. Использовать быструю сортировку.
Вариант № 13. Использовать сортировку Шелла. В качестве h-последовательности взять последовательность Седгевика.
Вариант № 14. Использовать древесную сортировку. Вариант № 15. Использовать пузырьковую сортировку.
Контрольные вопросы
1.Что понимается под сортировкой последовательности?
2.Сформулируйте принцип, реализуемый в сортировках включением.
3.В чём суть метода сортировки простыми вставками?
4.Какова временная сложность метода простых вставок?
5.Опишите процедуру сортировки методом Шелла.
6.Запишите формулы, которые задают h-последовательность Шелла, h-последовательность Кнута и h-последовательность Седгевика.
7.Какова временная сложность метода Шелла в зависимости от выбранной h-последовательности?
8.Какую структуру данных использует в своей работе процедура слияния двух упорядоченных последовательностей в одну упорядоченную?
9.В чём заключается сортировка слиянием?
10.Какова временная сложность сортировки слиянием?
11.Сформулируйте принцип, реализуемый в сортировках обменами.
12.Какие элементы массива сравниваются в процессе работы пузырьковой сортировки?
13.Какова временная сложность пузырьковой сортировки?
14.В чём заключается быстрая сортировка?
66
15.Каким образом осуществляется выбор главного элемента в алгоритме быстрой сортировки?
16.Как работает процедура реорганизации массива относительно главного элемента в алгоритме быстрой сортировки?
17.Назовите среднюю и максимальную сложность быстрой сортировки.
18.Сформулируйте принцип, реализуемый в сортировках извлечением.
19.В чём суть метода сортировки простым выбором?
20.Какова временная сложность сортировки простым выбором?
21.Сформулируйте определение сортирующего дерева.
22.Перечислите свойства сортирующего дерева.
23.Каков принцип работы древесной сортировки?
24.Как работает процедура «пересыпки», используемая для построения сортирующего дерева в алгоритме древесной сортировки?
25.Какова временная сложность древесной сортировки?
26.Какое ограничение на ключи накладывают сортировки распределени-
ем?
27.В чём заключается сортировка вычерпыванием?
28.Какова временная сложность сортировки вычерпыванием?
29.Для упорядочения каких массивов служит цифровая сортировка?
30.Как работает сортировка подсчётами?
31.Назовите те сортировки, в процессе работы которых не сравниваются ключи сортируемых элементов.
67
Лабораторная работа № 5. Быстрый поиск
Дихотомический (логарифмический) поиск в отсортированном массиве
Пусть в отсортированном массиве записей требуется отыскать элемент, у которого значение в ключевом поле совпадает с данным значением «k», и вернуть индекс «i» этого элемента.
Дихотомический поиск в отсортированном массиве состоит в следующем: сравнивая значение «k» с ключом записи в середине массива, определяем, в какой половине (левой или правой) следует продолжить поиск. После этого алгоритм рекурсивно применяем к выбранной части массива до получения массива, содержащего один элемент.
Временная сложность дихотомического поиска составляет
T(n) = O(log2n),
где n – количество элементов в массиве. Такая оценка сложности обусловила другое название этого алгоритма – логарифмический поиск.
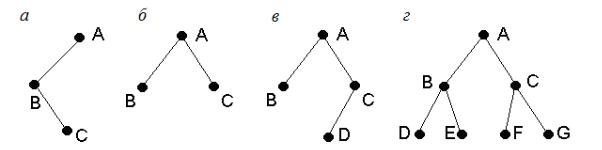
Двоичное (бинарное) дерево
Двоичное (бинарное) дерево − это структура данных, которая либо пуста, либо состоит из корня и двух непересекающихся бинарных деревьев, называемых левым (ЛПД) и правым (ППД) поддеревьями данного дерева.
На рисунке 5.1 представлены примеры бинарных деревьев.
Рис. 5.1. Примеры бинарных деревьев
Над двоичным деревом определены следующие операции:
создать пустое дерево;
построение – составление дерева из данных корня, ЛПД и ППД;
добавить вершину;
удалить вершину;
получить корень непустого дерева;
слева (справа) – доступ к ЛПД (ППД) непустого дерева;
проверка: является ли дерево пустым?
Пусть над каждым элементом бинарного дерева необходимо выполнить некоторое действие Р. Это действие можно рассматривать как пара-
68
метр более общей задачи – посещения всех вершин или, другими словами,
обхода дерева.
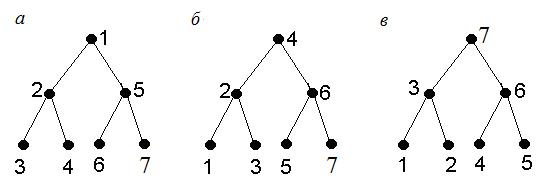
Существуют три способа упорядочения вершин, естественно вытекающих из структуры бинарного дерева. Выразим эти способы в терминах рекурсии.
I способ. Обход сверху вниз (в прямом порядке): посетить корень, посетить ЛПД, посетить ППД.
II способ. Обход слева направо (во внутреннем порядке): посетить ЛПД, посетить корень, посетить ППД.
III способ. Обход снизу вверх (в обратном порядке): посетить ЛПД, посетить ППД, посетить корень.
Пример. На рисунке 5.2, а вершины бинарного дерева пронумерованы в порядке его обхода сверху вниз, на рисунке 5.2, б – в порядке его обхода слева направо, на рисунке 5.2, в – в порядке его обхода снизу вверх.
Количество рёбер в самой длинной ветке дерева определяет его вы-
соту H.
Бинарное дерево с максимальным количеством вершин на каждом уровне называется полным.
Рис. 5.2. Обход бинарного дерева: а) в прямом порядке; б) во внутреннем порядке; в) в обратном порядке
Примеры. На рисунке 5.1, б, изображено полное бинарное дерево высотой H=1, на рисунке 5.1, г, – полное бинарное дерево высотой H=2.
Установим связь между количеством вершин n полного бинарного дерева и его высотой H:
n = 20 + 21 + 22 +…+ 2H = (2H +1 –1) / (2–1) = 2H +1 –1.
Устремляя n к бесконечности, получим следующую оценку высоты полного дерева: H = O(log2(n)).
Дерево поиска
Существуют специальные структуры, которые организованы таким образом, чтобы в них быстро выполнялся поиск элемента по данному ключу «k». Одной из таких структур является дерево поиска.
69
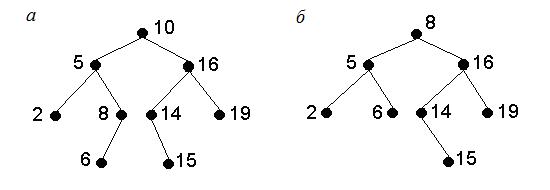
Деревом поиска называется бинарное дерево, для каждой вершины которого справедливо утверждение: ключ элемента, соответствующего этой вершине, не меньше ключей элементов, соответствующих её левому поддереву, и не больше ключей элементов, соответствующих её правому поддереву.
Примеры деревьев поиска приведены на рисунке 5.3, а, б.
Поиск элемента
В дереве поиска запись с данным ключом «k» можно обнаружить, начав с корня и двигаясь к левому или правому поддереву на основании сравнения ключа «k» с ключом текущей вершины V. Продолжаем поиск
в левом поддереве вершины V, если «k» меньше ключа вершины V;
в правом поддереве вершины V, если «k» больше ключа вершины V.
Включение элемента в дерево поиска
Прочитав очередное число − ключ «k», ищем его в дереве поиска. Если элемент с ключом «k» в дереве не существует, то, спустившись по пути поиска до вершины V с нулевым указателем, создаём новую вершину с начальным единичным значением счётчика, цепляя её
слева от вершины V, если «k» меньше ключа вершины V;
справа от вершины V, если «k» больше ключа вершины V.
Этот процесс называется поиском по дереву с включением.
Рис. 5.3. Примеры деревьев поиска
Исключение элемента
В случае исключения элемента из дерева поиска возможны три ситуации, а именно: удаляется
концевая вершина, т.е. вершина, не имеющая потомков;
вершина с одним потомком;
вершина с двумя потомками.
Первые две ситуации не вызывают трудностей и обрабатываются одинаково. Пусть удаляется вершина V, имеющая предка U и не более од-
70