

берчун
.pdf29. Форматы команд
Подформатом команды следует понимать длину команды, количество, размер, положение, назначение и способ кодировки ее полей.
Команды, как и любая информация в ЭВМ, кодируются двоичными словами, которые должны содержать в себе следующие виды информации:
тип операции, когорую следует реализовать в данной команде (КОГ1); П место в памяти, откуда следует взять первый операнд (Л 1);
место в памяти, откуда следует взять второй операнд (А2);
место в памяти, куда следует поместить результат (A3).
Каждому из этих видов информации соответствует своя часть двоичного слова — поле, а совокупность полей (их длины, расположение в командном еловс. способ кодирования информации) называется форматомкоманды.В свою очередь, некоторые поля команды могут делиться на подполя.
Команды трехадресного формата занимают много места в памяти, в то же время далеко не всегда поля адресов используются в командах эффективно. Действительно, наряду с двухместными операциями (сложение, деление, конъюнкция и др.) встречаются и одноместные (инверсия, сдвиг, инкремент н др.), для которых третий адрес не нужен. При выполнении цепочки вычислений часто результат предыдущей операции используется в качестве операнда для следующей. Более того, нередко встречаются команды, для которых операнды не определены (СТОП) или подразумеваются самим кодом операций (DAA, десятичная коррекция аккумулятора).
Поэтому в системах команд реальных ЭВМ трсхадресные команды встречаются редко. Чаще используютсядвухадресные команды (рис. 2.1,6), в этом случае в бинарных операциях результат помещается на место одного из операндов.
Для реализации одноадресных форматов (рис. 2.1, в) в процессоре предусматривают специальную ячейку —аккумулятор. Первый операнд и результат всегда размещаются в аккумуляторе, а второй операнд адресуется полем А.
Реальная система команд обычно имеет команды нескольких форматов, причем тип формата определяется в поле КОП.
30. Режимы адресации
Для взаимодействия с различными модулями в ЭВМ должны быть средства идентификации ячеек внешней памяти, ячеек внутренней памяти, регистров МП и регистров устройств ввода/вывода. Поэтому каждой из запоминающих ячеек присваивается адрес, т.е. однозначная комбинация бит. Количество бит определяет число идентифицируемых ячеек. Обычно ЭВМ имеет различные адресные пространства памяти и регистров МП, а иногда - отдельные адресные пространства регистров устройств ввода/вывода и внутренней памяти. Кроме того, память хранит как данные, так и команды. Поэтому для ЭВМ разработано множество способов обращения к памяти, называемых режимами адресации.
Режим адресации памяти - это процедура или схема преобразования адресной информации об операнде в его исполнительный адрес.
Все |
способы |
адресации |
памяти |
можно |
разделить |
на: |
1) прямой, |
когда исполнительный адрес |
берется |
непосредственно из команды |
или |
||
вычисляется с использованием значения, указанного в команде, и содержимого какого-либо регистра (прямая адресация, регистровая, базовая, индексная и т.д.); 2) косвенный, который предполагает, что в команде содержится значение косвенного адреса, т.е. адреса ячейки памяти, в которой находится окончательный исполнительный адрес (косвенная адресация).
В каждой микроЭВМ реализованы только некоторые режимы адресации, использование которых, как правило, определяется архитектурой МП.

31.SIMD
SIMD (single instruction stream / multiple data stream) - одиночный поток команд и множественный поток данных. В архитектурах подобного рода сохраняется один поток команд, включающий, в отличие от предыдущего класса, векторные команды. Это позволяет выполнять одну арифметическую операцию сразу над многими данными - элементами вектора. Способ выполнения векторных операций не оговаривается, поэтому обработка элементов вектора может производится либо процессорной матрицей, как в ILLIAC IV, либо с помощью конвейера, как, например, в машине CRAY-1.
[править]Машины типа SIMD.
Машины типа SIMD состоят из большого числа идентичных процессорных элементов, имеющих собственную память. Все процессорные элементы в такой машине выполняют одну и ту же программу. Очевидно, что такая машина, составленная из большого числа процессоров, может обеспечить очень высокую производительность только на тех задачах, при решении которых все процессоры могут делать одну и ту же работу. Модель вычислений для машины SIMD очень похожа на модель вычислений для векторного процессора: одиночная операция выполняется над большим блоком данных.
В отличие от ограниченного конвейерного функционирования векторного процессора, матричный процессор (синоним для большинства SIMD-машин) может быть значительно более гибким. Обрабатывающие элементы таких процессоров - это универсальные программируемые ЭВМ, так что задача, решаемая параллельно, может быть достаточно сложной и содержать ветвления. Обычное проявление этой вычислительной модели в исходной программе примерно такое же, как и в случае векторных операций: циклы на элементах массива, в которых значения, вырабатываемые на одной итерации цикла, не используются на другой итерации цикла.
Модели вычислений на векторных и матричных ЭВМ настолько схожи, что эти ЭВМ часто обсуждаются как эквивалентные.
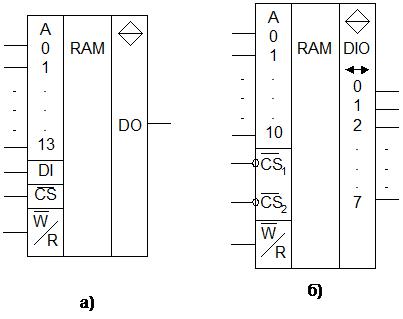
32. Статические БИС ОЗУ
По способу хранения информации ИМС ЗУ подразделяются на статические и динамические.
Встатистических БИС ЗУ элементы памяти реализуются на триггерных схемах, что позволяет использовать потенциальное управление и дает возможность считывать информацию без разрушения.
Вдинамических БИС ЗУ используются для хранения запоминающие конденсаторы, что предполагает обязательное восстановление информации, т.е. регенерацию состояний элементов памяти. В современных БИС режим регенерации либо совмещен с режимом обращения к элементу памяти, либо БИС имеет встроенную систему регенерации.
Отечественная промышленность выпускает ряд серий ИМС статических БИС ОЗУ: 132, 134, 541, 537, 565РУ2
В качестве примера приведено УГО БИС ОЗУ КР132РУ6А (n-МОП) и КР541РУ3 (И2Л) емкостью 16 кбит и организацией 16384Х1 (рис. 152, а)
Рис. 152
Ниже для сравнения приведены основные параметры приведенных БИС ОЗУ.
132 серии |
541 серии |
tв=45 нс |
tв=150 нс |
tу=75 нс |
tу=170 нс |
Рхр=140 мВт |
Рхр=200 мВт |
Рвыр=440 мВт |
Рвыр=565 мВт |
КР537РУ8А(КМОП) - ИМС ОЗУ емкостью 2кбайта, организация 2048 ´8 - 2кбайта
На рис. 152, б приведено УГО БИС ОЗУ КР537РУ8А (КМОП) емкостью 2 кбайта и организацией 2048Х8. Основные параметры ИМС: tв=220 нс, tу=350 нс, Рхр=6 мВт, Рвыр=160 мВт.
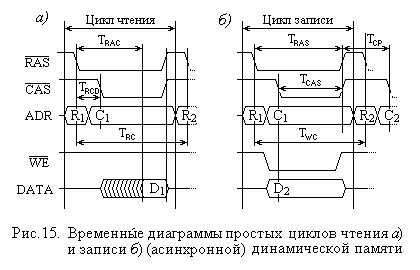
33. как отмечалось выше, в качествеЗУоперативныхнастоящее время чаще использ динамические ЗУ с произвольным доступом (DRAM). Такое положение обусловле связанные с необходимостью регенерации информации в таких ЗУ и относи быстродействием, с лихвойенсируютсякомп другими показателями: малыми размерами элеме следовательно, большим объемом микросхем этих ЗУ, а также низкой их стоимост
Широкое распространение ЗУ этого типа проявилось также и в раз разновидностей: асинхросинхронной,ой, RAMBUS и других. Основные из них рассматри
2.3.1.Асинхронная динамическая память DRAM
Впроцессе совершенствования технологии производства изменялась и ло динамических ОЗУ.
Первые такие ЗУ, которыествиивпоследстали называть асинхронными динамическ выполняли операции чтения и записи, получив лишь запускающий сигнал (обыч независимо от-либокакихвнешних синхронизирующих сигналов. Диаграмма простых (не чтения и записи для таких ЗУ представлена) и 15,бна) соответственнорис.15, . Любой цикл (чте записи) начинается по спаду (фронтуRAS“1”#. →“0”) сигнала

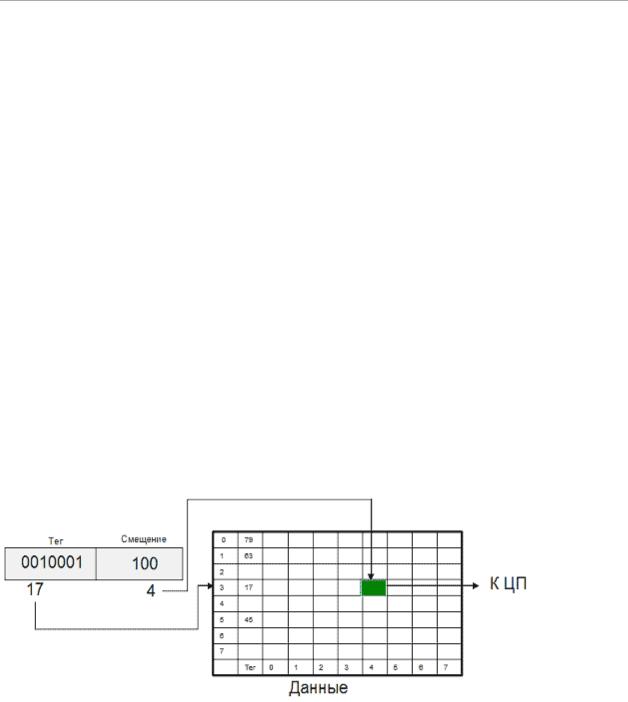
34. Кэш-память с прямым отображением.
Альтернативный способ отображения оперативной памяти в кэш - это кэш прямого отображения (или одновходовый ассоциативный кэш). В этом случае адрес памяти (номер блока) однозначно определяет строку кэша, в которую будет помещен данный блок. Физический адрес разбивается на три части: смещение в блоке (строке кэша), номер строки кэша и тег. Тот или иной блок будет всегда помещаться в строго определенную строку кэша, при необходимости заменяя собой хранящийся там другой блок. Когда ЦП обращается к кэшу за необходимым блоком, для определения удачного обращения или кэш-промаха достаточно проверить тег лишь одной строки.
Очевидными преимуществами данного алгоритма являются простота и дешевизна реализации. К недостаткам следует отнести низкую эффективность такого кэша из-за вероятных частых перезагрузок строк. Например, при обращении к каждой 64-й ячейке памяти в системе на кэш-контроллер будет вынужден постоянно перегружать одну и ту же строку кэш-памяти, совершенно не задействовав остальные.
Пример: Если объем ОЗУ – 4 Гбайт, тогда полный адрес - 32 бита можно представить в виде полей: 20 рр. – тэг (T), 7 рр – номер строки таблиц кэша (S), 5 рр – номер байта в строке (N). Поиск запрошенного байта (T-S-
N)в кэше с прямым распределением производится так:
1.Из памяти данных и памяти тэгов кэша одновременно считываются S-ные строки.
2.Если содержимое считанной строки памяти тэгов равно Т – кэш попадание, это значит, что считанная S строка памяти данных кэша содержит запрашиваемый байт и его номер в строке есть N.
3.Если содержимое считанной строки памяти тэгов не равно Т – кэш промах, и тогда T-S строка ОЗУ переписывается в S строку памяти данных кэша, а Т записывается в S строку памяти тэгов. Затем, см по п. 1.
35. Полностью ассоциативная кэшпамять.
Кэш-память
Для полностью ассоциативного кэша характерно, что кэш-контроллер может поместить любой блок оперативной памяти в любую строку кэш-памяти. В этом случае физический адрес разбивается на две части: смещение в блоке (строке кэша) и номер блока. При помещении блока в кэш номер блока сохраняется в теге соответствующей строки. Когда ЦП обращается к кэшу за необходимым блоком, кэш-промах будет обнаружен только после сравнения тегов всех строк с номером блока.
Одно из основных достоинств данного способа отображения - хорошая утилизация оперативной памяти, т.к. нет ограничений на то, какой блок может быть отображен на ту или иную строку кэш-памяти. К недостаткам следует отнести сложную аппаратную реализацию этого способа, требующую большого количества схемотехники (в основном компараторов), что приводит к увеличению времени доступа к такому кэшу и увеличению его стоимости. Intractable при размерах кэша порядка мегабайта (нужно перебирать десятки/сотни тысяч строк).
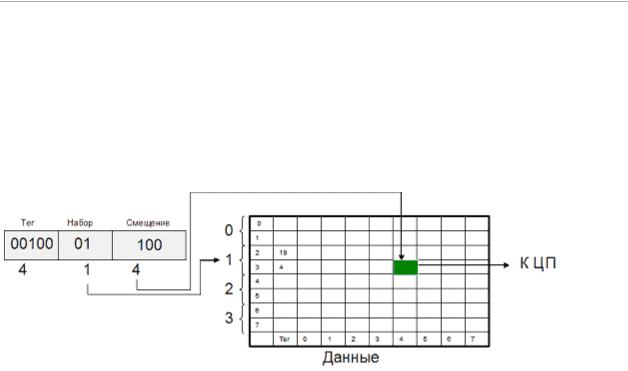
36. Частично-асссоциативная кэш-память.
Компромиссным вариантом между первыми двумя алгоритмами является множественный ассоциативный кэш или частично-ассоциативный кэш (рис.). При этом способе организации кэш-памяти строки объединяются в группы, в которые могут входить 2, 4, 8, и т.д. строк. В соответствии с количеством строк в таких группах различают 2-входовый, 4-входовый и т.п. ассоциативный кэш. При обращении к памяти физический адрес разбивается на три части: смещение в блоке (строке кэша), номер группы (набора) и тег. Блок памяти, адрес которого соответствует определенной группе, может быть размещен в любой строке этой группы, и в теге строки размещается соответствующее значение. Очевидно, что в рамках выбранной группы соблюдается принцип ассоциативности. С другой стороны, тот или иной блок может попасть только в строго определенную группу, что перекликается с принципом организации кэша прямого отображения. Для того чтобы процессор смог идентифицировать кэш-промах, ему надо будет проверить теги лишь одной группы (2/4/8/… строк).
39. Структуры данных
В современных компьютерах многоуровневая структура кэша, которая позволяет очень быстро выполнять обход массива. Попадание кэша настолько быстрая операция, что можно учитывать только промахи. Если строка кэша имеет размер B, то колличество промахов в массиве равно n/B. Если рассматривать связный список, то в худшем случае на доступ к каждому узлу будет приходится промах. Но даже в лучшем случае, когда узлы списка расположенны последовательно, из-за того, что узел у списка больше, может потребоваться в несколько раз больше кэша для прохода по списку.
Пусть у нас есть массив из 60 миллионов элементов и мы хотим вставить элементы в середину. Несмотря на преимущества, которые дает кэш, эта операция займет недели (Какого размера должны быть элементы чтобы копирование 30 миллионов элементов заняло недели? Секунды, ну максимум минуты...). Поэтому в программах, где вставка и удаление элементов является частой операцией, массивы неприменимы. Также недостатком массивов явлеется то, что они медленно увеличиваются и фрагментируют память.
Поэтому нужна структура, которая сочетает в себе преимущества кэша, которые дает массив, но при этом позволяет быстро вставлять элементы и увеличивать размер, как это свойственно спискам.
Такой структурой будет связный список маленьких массивов. А, чтобы эту структуру сделать cache-aware, нужно, чтобы каждый узел такого связного списка был размером B (т.е. размером со строку кэша).
[править]Оптимизация сортировки слиянием
Особенность Cache-aware версий алгоритма сортировки слиянием -- его операции были специально выбраны для сведения к минимуму перемещения страниц в и из кэш-памяти машины. Например, tiled алгоритм сортировки слиянием останавливает разбиение на подмассивы, когда размер подмассива становится равным S, где S -- это колличествр элементов данных, которые можно разместить на одной странице в памяти. Каждый из этих подмассивов сортируется сортировкой для которой не требуется дополнительной памяти, чтобы избежать подкачки, отсортированние подмассивы сортируются обычным слиянием.
40. Введение
В лекции рассмотрена сегментная организация памяти – альтернативастраничной организации. Дано обоснование сегментной организации и ее связи с логической структурой программы. Рассмотрена смешанная – сегментностраничная – организация памяти, применяемая во многих системах.
Принципы сегментной организации памяти
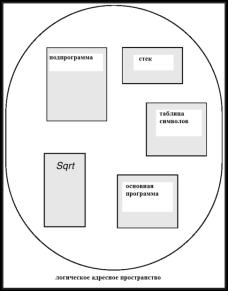
Сегментная организация памяти (segmentation) - схема распределения памяти в виде сегментов переменной длины, соответствующая пользовательской трактовке распределения памяти, т.е. логической структуре программ и данных. С точки зрения пользователя (разработчика программы), программа – это набор модулей кода и данных, каждому из которых должен соответствовать свой сегмент в памяти. Сегмент – логическая единица распределения памяти, предназначенная для размещения в памяти одного модуля программного кода или данных. Например, в виде сегментов памяти могут быть представлены:
основная программа;
процедура;
функция;
метод;
объект;
набор локальных переменных;
набор глобальных переменных;
общий блок данных (например, COMMON-блок в языке FORTRAN);
стек;
таблица символов;
массив.
рис. 17.1 иллюстрирует данную точку зрения на программу как на набор сегментов в памяти.
увеличить изображение Рис. 17.1. Программа как набор сегментов.
Архитектура сегментной организации памяти
Многие принципы архитектуры сегментной организации схожи с принципами страничной организации (см. "Страничная организация памяти"), однако во всех случаях приходится учитывать, что длина сегмента переменна, и хранить ее в явном виде в таблицах.
Логический адрес при сегментной организации памяти - пара:
<segment-number, offset>,
где segment-number – номер сегмента, offset – смещение в сегменте.
Таблица сегментов – служит для отображения логических адресов в физические при сегментной организации памяти. Каждый ее элемент содержит следующую информацию: