

берчун
.pdf12. Управляющий автомат Мили
Автомат Мили имеет структуру, на 100% совпадающую с рис. 2. И поведение его описывается теми же общими формулами
– Y=ƒ1(X,T), D=ƒ2(X,T). Поэтому иногда говорят, что этот автомат генерирует (в смысле изменяет) выходные сигналы при переходах из одного состояния в другое. Здесь подчёркивается тот факт, что Y непосредственно зависит от X.
Рассмотрим синтез автомата Мили на примере.
Допустим, нам необходимо построить автомат, имеющий 2 входных сигнала (x1, x2) и 4 выходных (y1-y4):
x1 |
x2 |
y1 |
y2 |
y3 |
y4 |
0 |
1 |
1 |
0 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
0 |
1 |
0 |
1 |
1 |
1 |
Т.к. мы имеем 6 состояний, то нам понадобится 3 триггера. Используем для простоты D-триггеры. Построим теперь полную таблицу истинности автомата:
Сост. |
T1 |
T2 |
T3 |
x1 |
x2 |
y1 |
y2 |
y3 |
y4 |
D1 |
D2 |
D3 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
1 |
1 |
0 |
0 |
1 |
1 |
0 |
0 |
1 |
1 |
1 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
2 |
1 |
0 |
0 |
1 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
1 |
3 |
1 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
4 |
1 |
1 |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
0 |
1 |
1 |
5 |
0 |
1 |
1 |
0 |
1 |
0 |
1 |
1 |
1 |
0 |
0 |
0 |
Здесь мы:
1.Пронумеровали все состояния автомата.
2.Закодировали все 6 состояний автомата сигналами текущего состояния триггеров Tx. Кодировать можно как угодно, единственное требование – все коды состояний д.б. уникальны. Т.е. не должно быть 2-х и более состояний с одинаковыми кодами.
3.Дополнили исходную таблицу сигналами Tx и сигналами Dx управления триггерами для того, чтобы автомат мог переходить из одного состояния в другое.
Также подразумевается, что состояния меняются по кругу. В разделе 1.2 показано, как реализовывается переход их одного состояния в 2 других в зависимости от разных входных сигналов.
По этой таблице уже можно синтезировать КС автомата. Но перед тем, как перейти непосредственно к синтезу, отметим небольшую особенность использованного кодирования состояний: сигнал T1 повторяет x1 со сдвигом на один такт. Это позволяет не строить какие-то формулы и схемы для сигнала D1, а сразу пустить x1 на D1. Подобные «уловки» в ряде случаев позволяют упростить схему и ускорить её быстродействие.
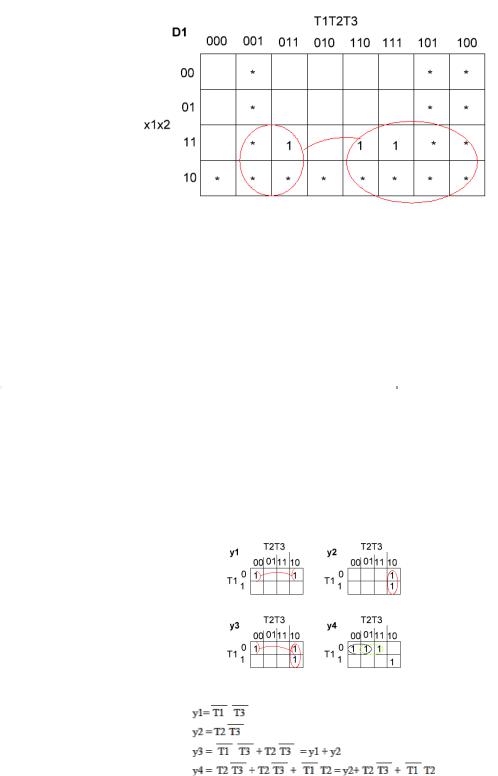
КС должна формировать 7 сигналов: y1-y4 и D1-D3. Составим формулы для каждого сигнала:
По формулам можно нарисовать схему автомата. Мы этого делать не будем, здесь и так всё понятно.
Следует отметить, что у автомата Мили теоретически возможна ситуация, при которой окажется, что какой-то yi зависит только от xj и не зависит от Tn. Т.е. автомат изменяет выходные сигналы, не изменяя своего состояния. Учесть это при синтезе сложно, гораздо проще после него ввести какие-то «ненужные» зависимости yi от каких-то Tn.
12. Управляющий автомат Мура
Автомат Мура отличается от Мили тем, что он описывается формулами Y=ƒ1(T), D=ƒ2(X,T). Т.е. его выходные сигналы зависят только от состояния триггеров. Поэтому его КС фактически распадается на 2 независимые КС – рис. 3.
Рис. 3 Структура автомата Мура
КС1 реализует функцию D=ƒ2(X,T), а КС2 - Y=ƒ1(T).
Построим автомат Мура для того же примера:
Сост. |
x1 |
x2 |
y1 |
y2 |
y3 |
y4 |
0 |
0 |
1 |
1 |
0 |
1 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
1 |
2 |
1 |
0 |
0 |
1 |
1 |
1 |
3 |
1 |
1 |
0 |
0 |
0 |
0 |
4 |
0 |
0 |
1 |
1 |
1 |
1 |
5 |
0 |
1 |
0 |
1 |
1 |
1 |
Сразу отметим, что состояния 2 и 5 для Мура полностью эквивалентны, т.к. они генерируют идентичные наборы выходных сигналов. Поэтому состояние 5 можно выбросить и добавить дополнительный переход из состояния 2 по сигналам x1x2=01 в состояние 0. Это действие заменит выброшенное 5-е состояние в плане переходов.
Исключение эквивалентных состояний в общем случае может сократить число триггеров автомата.
ТИ для КС1 (таблица переходов автомата):
Сост. |
T1 |
T2 |
T3 |
X1 |
x2 |
D1 |
D2 |
D3 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
1 |
1 |
0 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
2a |
1 |
1 |
0 |
1 |
1 |
1 |
1 |
1 |
2b (5) |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
3 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
4 |
0 |
1 |
0 |
0 |
0 |
0 |
1 |
1 |
Правила кодирования состояний те же, что и автомате Мили.
Коды состояний 001, 100, 101 и сочетание входных сигналов x1x2=10 не используются, это можно учитывать при минимизации.
Обратите внимание, что в таблице 2 строки, соответствующие состоянию 2. Строка 2b соответствует выброшенному состоянию 5. Видно, что из неё автомат переходит в состояние 0.
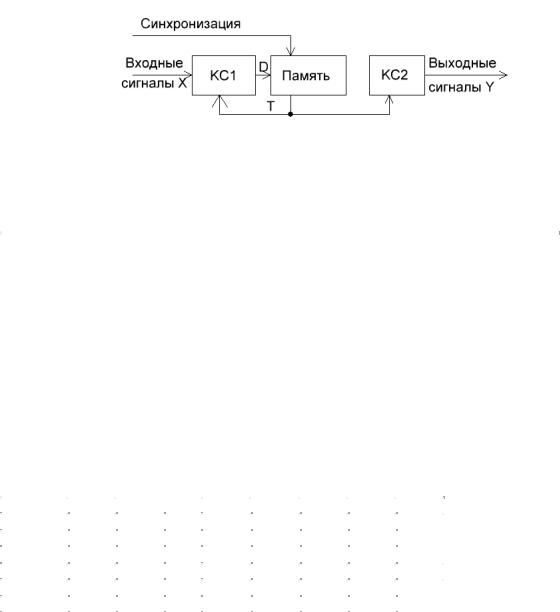
Получим минимальные формулы сигналов D1, D2 и D3 КС1:
Карта Карно для сигнала X1 – рис 4.
Рис 4. Карта Карно для сигнала X1.
Из карты следует, что D1 = x1. Это же видно из ТИ.
Аналогично:
D2 = x1 + T2 + T1 T2 T3 x2
D3 = T1 T2 T3 x2 + T2 + T1 T2 T3 x1
ТИ для КС2 автомата:
Сост. |
T1 |
T2 |
T3 |
y1 |
y2 |
y3 |
y4 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
1 |
1 |
0 |
1 |
1 |
0 |
0 |
0 |
1 |
2 |
1 |
1 |
0 |
0 |
1 |
1 |
1 |
3 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
4 |
0 |
1 |
0 |
1 |
1 |
1 |
1 |
Сигналы:
Рис.5 Карты Карно для сигналов y1-y4
Из анализа формул видно, что y3 и y4 можно формировать, используя уже готовые y1 и y2. Это может дополнительно упростить КС2, но на практике такое решение снижает нагрузочную способность схемы на выходах y1 и y2.
Также, можно упростить реальную схему, если в каком-то смысле объединять схемы КС1 и КС2, формируя общие для них внутренние сигналы (например, T1 T3) и использовать их одновременно в обоих схемах. Конечно, обращая внимание на длину получаемых цепочек элементов и на их быстродействие (при увеличении длины цепочки падает её быстродействие).
Даже несмотря на то, что при рассмотрении автомата Мили мы не минимизировали его формулы, можно заметить, что автомат Мура проще уже потому, что для формирования Y не нужны сигналы X.
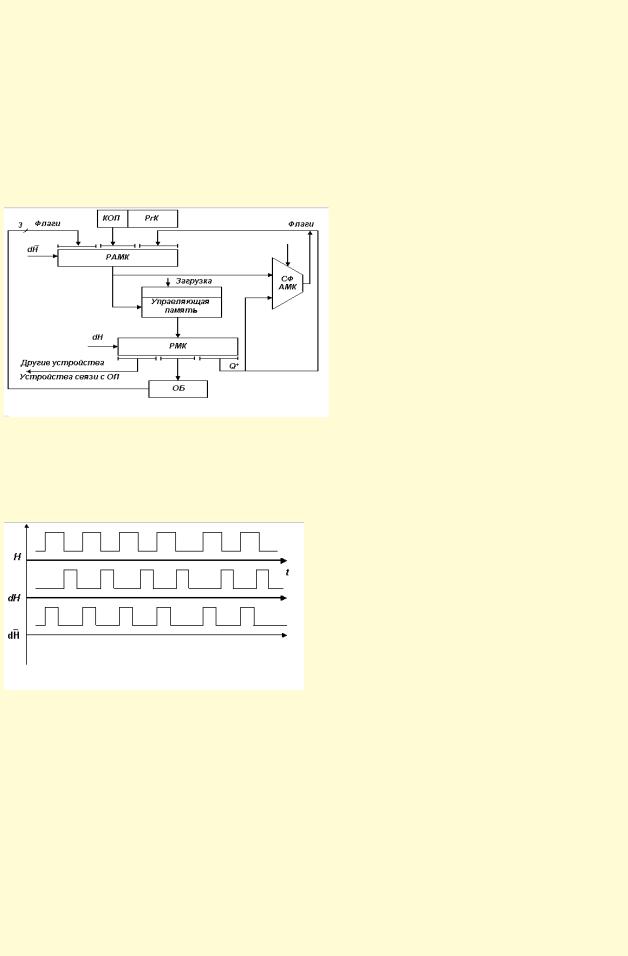
13. Управляющий автомат с хранимой в памяти логикой – это последовательностное устройство,
вырабатывающее распределенные во времени управляющие функциональные сигналы, задавае мые содержимым микропрограммной памяти.
Во всех случаях, перед тем как выполнить некую команду, надо считать ее из запоминающего устройства. А значит, что надо иметь некоторый регистр, где эта команда будет храниться во время исполнения.
Регистр адреса мик рокоманд (РАМК) является синхронным, и мы будем тактировать его некоторым
сигналом 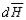 . Необходимо так же учитывать состояние операционного блока, то есть его флаги. По адресу микрокоманды из памяти микропрограмм извлекается микрокоманда.
. Необходимо так же учитывать состояние операционного блока, то есть его флаги. По адресу микрокоманды из памяти микропрограмм извлекается микрокоманда.
Рис. 2.10. Структура УБ, позволяющего нам изменять микропрограммы, используемые при функционировании процессора
Нарисуем временную диаграмму работы управляющего блока.
Рис. 2.11. Временная диаграмма УБ
1)КОП совместно с флагом из ОБ и с состоянием управляющего авт омата Q+ задает адрес ячейки управляющей памяти, где хранится микрокоманда и следующее состояние управляющего блока.
2)С приходом 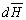 адрес в управляющей памяти фиксируется в РАМК, который определяет новое содержимое регистра микрокоманды (РМК).
адрес в управляющей памяти фиксируется в РАМК, который определяет новое содержимое регистра микрокоманды (РМК).
3)С приходо м сигнала 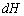 в РМК переписывается микрокоманда и новое состояние управляющего автомата.
в РМК переписывается микрокоманда и новое состояние управляющего автомата.
4)Микрокоманда состоит из микроопераций, которые подаются в управляемые устройства (ОБ,
устройство связи с внешней памятью) и до прихода следующего сигнала 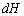 выполняется извлеченная микрокоманда.
выполняется извлеченная микрокоманда.

5)По окончании выполнения микрокоманды формируется состояние управляемых блоков, которые поступают на вход РАМК.
6)С приходом следующего сигнала 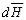 фиксируется новый адрес микрокоманды и процесс повторяется.
фиксируется новый адрес микрокоманды и процесс повторяется.
Замечание 1 . Управляющ ая память может допускать загрузку содержимого до начала работы процессора или в процессе его работы. Это позволяет изменять логику работы управляющего автомата (например систему команд ).
Замечание 2 . Число состояний управляющего автомата Q + невелико и фор мирование следующей микрокоманды можно выполнять с помощью комбинационной схемы – СФАМК (схема формирования адреса микрокоманды). Это позволяет реализовать последовательное выполнение микрокоманд с изменением этой последовательности в случае использования микрокоманды перехода.
14. Микрокоманда, как и команда, имеет две части :
Операционная часть содержит информацию о том, какие микрооперации должны быть выполнены в операционной части процессора в данном такте. Адресная часть указывает на то, каким должен быть адрес следующей микрокоманды. Это отличает от адресной части команды, которая обычно указывает на адреса операндов.
Существуют разные способы кодирования операционной части микрокоманды: горизонтальное, вертикальное, смешанное и нанокодирование (микропрограммирование).
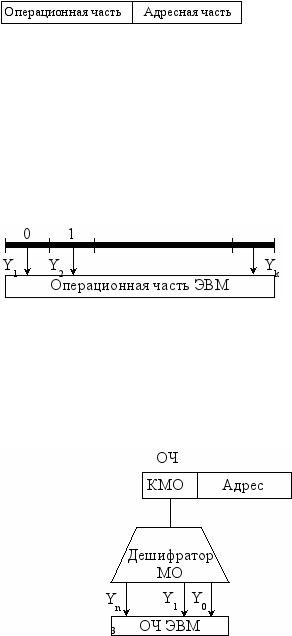
^ 1. Горизонтальное микропрограммирование
Этот способ микропрограммирования представлен на рисунке.
Здесь сигнал каждого разряда микрокоманды без изменения используется в качестве управляющего, т.е. блок
формирования управляющих сигналов отсутствует. В этом состоит преимущество этого способа (схема проще). Недостатки: избыточность кодирования, неэффективное использование памяти микрокоманд (в реальных ЭВМ число микроопераций может достигать нескольких сотен; одновременно в каждом такте обычно выполняется несколько микроопераций; это приводит к тому, что в ячейках памяти микрокоманд будут находиться практически одни нули).
^ 2. Вертикальное микропрограммирование
На рисунке видно, что в этом случае в операционной части микрокоманды указывается код одной микрооперации
(КМО).
Как известно из теории кодирования, если число кодируемых объектов ( данном случае - микроопераций) равно N, то число разрядов в коде может быть равно LogN, то есть существенно меньше. Для формирования управляющих сигналов необходим один дешифратор. Таким образом, при этом способе кодирования активным всегда будет только один из сигналов Yi.
Достоинства этого способа: уменьшается длина микрокоманд, уменьшается объем памяти микрокоманд. Недостаток этого способа заключается в том, что длина микропрограмм, реализующих тот же самый алгоритм, возрастает, а следовательно, возрастает число тактов необходимых для его выполнения .
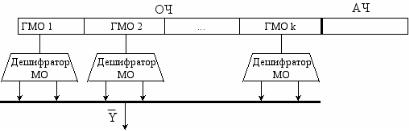
^ 3. Смешанное микропрограммирование
Смешанное микропрограммирование является одним из самых распространенных. В этом методе все множество микроопераций разбивается на группы независимых микроопераций, т.е. на такие группы, что любая микрооперация из одной группы может выполняться одновременно с любой микрооперацией из другой группы. Этот способ микропрограммирования объединяет достоинства горизонтального и вертикального способов. В нем все микрооперации выполняются за один такт.
15. Рассмотрение «классической» микроархитектуры процессора
Чтобы понимать, как функционирует процессор, нужно рассмотреть его классическую микроархитектуру и базовые принципы функционирования. В данной статье мы этим и займёмся.
Итак, поехали…
В любом процессоре присутствует несколько элементов: кэш команд и данных, предпроцессор и постпроцессор.
Процесс обработки данных в классическом упрощённом виде, состоит из нескольких этапов:
1. Происходит процедура выборки. Во время этой процедуры данные и инструкции вытягиваются с кэшпамяти первого уровня (L1)
2.Выбранные данные декодируются (превращаются в понятные для процессора команды)
3.Потом декодированные данные доходят до исполнительных блоков и выполняются
4.После всего этого обработанные результаты записываются в оперативную память.
Данные стадии называют конвейером обработки команд. Так как у нас четыре стадии (ступени) обработки, то логично, что конвейер в данном случае будет четырёхступенчатым. Стоит подчеркнуть тот факт, что каждую из стадий (ступеней) команда проходит ровно за один такт, поэтому для данного четырёхступенчатого конвейера, на выполнение одной команды уходит четыре такта. В реальных процессорах, число ступеней конвейера будет на порядок больше и может различаться. Само же увеличение количества ступеней в конвейере процессора, было вызвано необходимостью выполнить более сложные команды, которые не удается выполнить при такой структуре, поэтому каждая ступень «классического» конвейера, может иметь массу «подступеней» и могут быть добавлены новые ступени.
А сейчас давайте рассмотрим процесс исполнения кода в «классическом» процессоре. Первым делом, при исполнении кода, происходит выборка инструкций и данных из кэша L1. Затем эти инструкции блоками определённой длинны, загружаются из кэша L1, среди которых потом выделяются те, которые подвергнутся декодированию.
Главная задача процессора – за минимальное время выполнить максимальное количество инструкций. Именно этим и определяется производительность процессора.
Для увеличения производительности процессора, помимо наращивания тактовой частоты, применяется несколько интересных подходов. Можно повысить производительность процессора, за счёт уменьшения длинны конвейера и увеличения количества исполнительных блоков. Такой подход реализует параллелизм на уровне инструкций (ILP), когда несколько инструкций выполняются одновременно в различных исполнительных блоках процессора.
Как короткий, так и длинный конвейер, имеют свои плюсы и минусы. В длинном конвейере, где имеется множество коротких ступеней, время прохождение командой каждой из ступеней - будет совсем небольшим. В таком конвейере ступень выполняется за один такт, что даёт обширные возможности, для наращивания тактовой частоты.
Ситуация обстоит совершенно по-другому, в случае применения короткого конвейра (соответственно с длинными ступенями, но с их меньшим количеством). В таком варианте, время на прохождения команды одной ступени увеличивается, что даёт серьёзные ограничения, при наращивании тактовой частоты.
Если подвести небольшой итог, то мы вкратце рассмотрели структуру и принцип работы «классического» процессора, по модели которого построены реальные процессоры.
16. Трехшинная Гарвардская архитектура
Ее особенность состоит прежде всего в том, что в отличии от привычных нам двух шин: шины адреса и шины данных, а также одного банка памяти, DSP имеет как минимум 6-7 различных шин и 2-3 банка памяти. Эта особенность имеет своей целью максимально ускорить выполнение операции умножения с сохранением результата, которая, несомненно, является наиболее употребляемой и ресурсоемкой при цифровой обработке сигналов. Архитектура DSP позволяет за один машинный цикл произвести:
1.выборку команды посредством шины адреса программ и шины данных программ;
2.выборку двух операндов для операции умножения посредством двух шин адреса данных;
3.занесение операндов в аккумуляторы посредством двух шин данных;
4.операцию умножения;
5.сохранить результат в аккумуляторе.
Таким образом, трехшинная Гарвардская архитектура позволяет выполнить практически любую операцию за
один машинный цикл.
B качестве примера эффективности использования DSP при реализации алгоритмов цифровой обработки сигналов можно привести следующий факт: время выполнения комплексного 1024-точечного преобразования Фурье составляет 20 мс для 486DX2 66 МГц (32-разрядный) и 3.23 mc для 24-разрядного 33 МГц DSP56001 фирмы Motorola или 3.1 мс для 32разрядного 33 МГц DSP TMS320C30 с плавающей арифметикой фирмы Texas Instruments.
Однако, как уже упоминалось, процессоры цифровой обработки сигнала имеют отличием не только высокую производительность, измеряемую в быстроте выполнения операций умножения/аккумуляции (MIPS - миллионы команд в секунду), но и такие характеристики, как последовательность выполнения программ, арифметических операций и адресации памяти, позволяющие сократить до минимума непроизводительные затраты времени. В целом DSP отличается от других типов микропроцессоров и микроконтроллеров по следующим пяти основным признакам:
1.Быстрая арифметика.
DSP - процессор должен осуществлять выполнение за один цикл операций умножения, умножения с
аккумуляцией, циклический сдвиг, а также стандартные арифметические и логические операции.
2.Расширенный динамический объем для операции умножения/аккумуляции.
Операция вычисления суммы некой последовательности значений является фундаментальной для алгоритмов,
реализуемых на DSP. Защита от переполнения необходима для избежания потери данных.
3.Выборка двух операндов за один цикл.
Очевидно, что для большинства операций, выполняемых DSP, необходимы два операнда. Таким образом, для
достижения максимального быстродействия процессор должен быть способен производить одновременную выборку двух операндов, что требует также наличия гибкой системы адресации.
4.Наличие аппаратно реализованных циклических буферов(встроенных и внешних).
Широкий класс алгоритмов, реализуемых на DSP требует использования циклических буферов. Аппаратная поддержка циклического возврата указателя адреса или модульная адресация уменьшает непроизводительные затраты процессорного времени и упрощает реализацию алгоритмов.
5.Организация циклов и ветвлений без потери в производительности.
Алгоритмы DSP включают очень много повторяющихся операций, которые могут быть реализованы в виде циклов. Возможность организации последовательности выполнения программы кодов в цикле без потери производительности отличают DSP от других процессоров. Аналогично, потеря времени при выполнении операции ветвления по условию также недопустима при цифровой обработке сигналов.
Не следует, однако, думать, что DSP могут полностью заменить процессоры общего назначения. Как правило, процессоры цифровых сигналов имеют упрощенную систему команд, не позволяющие выполнить операции, не связанные с математическими вычислениями с такой же эффективностью, как и процессоры общего назначения. Попытка же сочетания в одном процессоре мощность при математических вычислениях и гибкость при операциях другого рода приводит к неоправданному повышению себестоимости. Поэтому DSP используют чаще в виде сопроцессоров (математических, графических, акселераторов и т.д.) при главном процессоре либо в качестве самостоятельного процессора, если этого достаточно.

19. Суть конвейерного способа производства состоит в разбиении технологической цепочки изготовления некоего продукта на простейшие последовательные операции. Производительность конвейера определяется лишь длительностью самой сложной операции. Поэтому совершенно неважно, какой длины конвейер. Если ни одна операция не занимает больше минуты, то новенькое изделие будет появляться на выходе конвейера каждую минуту.
Конвейерный подход в принципе применим в процессорах: хотя машинные инструкции содержат довольно сложный код, они успешно раскладываются на отдельные этапы. Чем более простые операции выполняются на каждой стадии конвейера, тем быстрее работает процессор. Практически любая инструкция разделяется, как минимум, на пять этапов:
выборка инструкции из памяти;
декодирование инструкции;
подготовка исходных данных для выполнения;
собственно выполнение инструкции;
сохранение полученных результатов.
В1992 году корпорация Intel совершила революцию в процессорной архитектуре, предложив процессор 80486 с конвейером длиной пять стадий. В результате рабочая частота выросла по сравнению с предшествующей моделью 80386 в три раза, среднее время выполнения инструкций снизилось вдвое.
Идея конвейерной обработки инструкций оказалась плодотворной, однако трудно реализуемой на практике. Расплатой за внедрение конвейера стала чудовищная сложность ядра. Тем не менее, сегодня процессоры семейства Intel Pentium 4 способны выполнять семь инструкций за такт, а семейства AMD Athlon 64 — девять.