

Концептуальные модели баз данных.
В иерархическойМДлогическая структура хранимой информации может быть представлена упорядоченным графом (деревом, рис. 2) или набором деревьев.
Для такой структуры характерно наличие у каждого потомка только одного родителя.
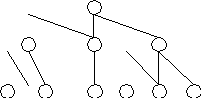
Рис. 2. Граф-дерево
Достоинства ИМД:
Идеально подходит для представления информации с чисто иерархическими связями.
Возможность автоматического контроля целостности связей в рамках дерева (каждый потомок должен иметь только одного родителя).
Наличие развитых программных средств для работы со структурами типа дерева (указатели).
Недостатки ИМД:
Трудность и неочевидность представления информации со сложными логическими связями (как, например, отразить процесс движения предметов между п/о лицами?).
Отсутствие возможности автоматического контроля целостности связей между записями разных деревьев.
Выполнение даже относительно простых запросов требует отслеживания большого количества связей (например, для ответа на запрос: продукция каких поставщиков используется в различных подразделениях, потребуется полный просмотр двух деревьев).
СетеваяМДпредставляет собой обобщение иерархической модели на случай графа с произвольными связями (рис. 4).

Рис. 4. Граф с произвольными связями
Обобщая приведенные рассуждения, можно сказать, что реляционная база данных(РБД) – это совокупность связанных таблиц.
Перечислим достоинства реляционной модели данных:
Простота и интуитивная понятность (мы пришли к РМД без использования каких-то специальных познаний; более того, многие разработчики БД (не СУБД) успешно работают, имея весьма приблизительные понятия о соответствующей математике).
Строгое математическое обоснование (РМД разработана математиком и в своей основе имеет реляционную алгебру и реляционное счисление).
Простота и относительно небольшое количество взаимосвязей, а, соответственно, простота формулирования и выполнения запросов.
Хорошие возможности для автоматического контроля целостности связей (так называемая ссылочная целостность).
В постреляционноймодели данных многозначные атрибуты допустимы. Кроме того, отсутствует требование постоянства числа полей и их размера в записях одной таблицы. Поэтому две последних таблицы могут быть заменены одной:
Счет (№счета, Дата, Покупатель, Товар, Кол-во).
При этом поля «Товар» и «Кол-во» будут многозначными, а часть строк будут содержать только два этих поля.
Таким образом в постреляционной модели достигается повышение производительности и большая наглядность представления данных.
В многомерноймодели данных та же самая информация может быть представлена гораздо более наглядно:
Также важными достоинствами многомерной МД являются: агрегируемость данных, т.е., возможность представления информации с разной степенью обобщения (например, с одной степенью для руководства компании и с другой – для менеджеров начального уровня); историчность – обязательная привязка данных ко времени. Но, с другой стороны, громоздкость многомерной МД делает ее неприемлемой для построения систем оперативной обработки информации.
Для областей, где необходимо отображать большое число сложных связей в последнее время используется объектнаямодель данных, которая основана на известных из ООП понятиях инкапсуляции, наследования и полиморфизма.
Разделение функций БД - СУБД - Приложение.
База данных (в широком смысле)– это компьютерная система упорядоченного хранения информации и обеспечения доступа к ней.
Структурно база данных (БД) представляет собой комплекс хранимой информации (собственно база данных в узком смысле) и средств доступа к ней (система управления базами данных и приложения) (рис. 1).
База данных (в узком смысле)– это упорядоченное множество информации об определенной сфере деятельности человека. В этом смысле БД не предполагает обязательное использование компьютера (например, алфавитный или предметный указатель в библиотеке).
Система управления базами данных (СУБД) – это компьютерная система, которая позволяет определять, создавать и поддерживать базы данных, а также организуетконтролируемыйдоступ к хранимой в них информации.
Приложения– это компьютерные программы, обеспечивающие доступ пользователя к информации, хранимой в БД, через СУБД.
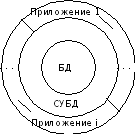
Рис. 1. Структура современной БД
Важнейшей характеристикой любой БД является логическая структура хранимой информации, которая называется моделью представления данныхили просто моделью данных (МД). В зависимости от используемой МД различают: иерархические, сетевые, реляционные, постреляционные, многомерные, объектные, … базы данных.
В любой современной базе данных можно выделить три уровня (рис. 1). Во-первых, это собственно БД, как структура хранения информации. Во-вторых, СУБД – система, выполняющая все необходимые операции с информацией, хранимой в БД. И, наконец, приложения – программы, обеспечивающие взаимодействие пользователя с СУБД.
Суть важным в этой структуре является то обстоятельство, что единственным (монопольным) распорядителем собственно БД выступает СУБД, и никакое приложение, а тем более пользователь, не может получить доступ к БД, минуя СУБД. Такая структура обеспечивает большую гибкость при разработке БД и приложений, а также позволяет корректно реализовать одновременную работу множества пользователей с одной и той же базой данных.
Указанная структура появилась не сразу, а является следствием достаточно большого пути в историческом развитии БД.
Первые БД, так называемые file-based(в русскоязычной литературе используется не очень удачный перевод «файловые системы»), представляли собой единую программу-приложение без явной дифференциации каких-либо функций. То есть, и структуры хранения информации, и способы доступа к ней, и проблемы взаимодействия с пользователем – все задачи решались в рамках единого приложения.
Недостатки такой реализации БД достаточно очевидны. Например, если несколько приложений сильно пересекаются по набору используемой информации (такое пересечение легко заметить, к примеру, в информации о работниках предприятия в отделе кадров и в бухгалтерии), то практически одни и те же структуры и способы доступа должны детально и совершенно одинаково быть прописаны в нескольких приложениях. Изменение структуры хранимой информации в целях одного из приложений требует аналогичных изменений во всех других приложениях, хотя вполне может быть, что эти изменения по сути их и не касаются (например, для нужд службы охраны добавили в базу данных фотографии сотрудников. Ясно, что для бухгалтерских расчетов эти фотографии не имеют никакого значения).
Поскольку структура хранимой информации определяется в рамках приложения, то в разных приложениях для схожих данных могут использоваться различные и не всегда очевидные формы хранения (например, дату можно сохранить самыми разнообразными способами, как в числовой, так и в символьной форме). Соответственно, доступ к информации помимо родительского приложения становится сильно затруднен. И, что много хуже, появляется жесткая зависимость пользователя от разработчика приложений, ведь только разработчик точно знает – какие структуры он использовал и как реализовать доступ к ним.
Наконец, отсутствие унификации приводит к необходимости повторной проработки вопросов хранения информации при разработке каждого нового приложения, требует дополнительных трудозатрат.
Относительным достоинством привязки структур хранения информации к приложению является полная свобода разработчика в плане оптимизации этих структур для хранения конкретной, характерной только для решаемой задачи информации. Первый шаг на этом направлении развития баз данных был продиктован очевидным желанием: один раз тщательно отработать вопросы хранения самой разнообразной информации и прийти к некоторым универсальным, унифицированным решениям, которые и использовать всегда, когда встает проблема хранения накопленной информации. При этом, с одной стороны, отпадает необходимость в повторном решении одной и той же задачи, а с другой – не возникает проблем при необходимости прямого доступа к информации, поскольку правила доступа едины и всем хорошо известны. Ярким примером здесь могут служить, так называемые, dbf-файлы. Они были разработаны в качестве структуры хранения информации в рамках ныне забытой СУБДdBase, но прекрасно используются и по настоящее время (загляните, например, в список форматов, поддерживаемыхMSExcel).
Следствием унификации способов хранения информации стало выделение в базах данных в качестве отдельной составляющей уровня БД, как структуры хранения информации. Соответственно, все вопросы, касающиеся собственно хранения информации, перестали быть составляющей частью приложений.
Дальнейшее развитие БД связано с выделением из приложений функций СУБД. Дело в том, что хранимая в БД информация подчиняется неким общим закономерностям, которые не зависят от конкретного характера и назначения этой информации. Например, в ней, как правило, имеют место вполне определенные взаимосвязи. Поясним, о чем идет речь.
Пусть БД используется для хранения информации о наличии товаров. Очевидно, что в ней должны храниться, с одной стороны, описания этих товаров (наименование, производитель, цена и т.п.), а с другой – данные об их наличии, например, на конкретных складах. Причем информация о наличии должна быть привязана к конкретным товарам, то есть, не может быть в наличии товар, для которого нет описания, хотя может быть описание товара, которого в данный момент в наличии нет.
Такого рода связи встречаются при проектировании баз данных на каждом шагу. Например, работники и их участие в различных проектах, подразделения предприятия и производимая в них продукция, изделия и используемые в них детали, расписание движения транспорта и наличие билетов, и т.д. и т.п. Все эти связи весьма схожи по своему характеру и должны подчиняться одним и тем же правилам (это, так называемые, правила ссылочной целостности) не зависимо от конкретного назначения информации. Соответственно, реализация такого рода связей – это общий момент для всех баз данных.
Другой пример общих задач. Для исключения разного рода ошибок на хранимую в БД информацию накладываются ограничения (бизнес-правила). Например, дата рождения не должна выходить (в большинстве реальных приложений) за пределы с начала XXвека по текущую дату, цена не должна быть отрицательной, номер месяца должен быть в пределах от 1 до 12 и т.п. То есть, ограничения на значения отдельных атрибутов также характерны для большинства баз данных.
Поэтому возникает следующая идея в развитии баз данных – реализовать некоторые характерные, часто используемые механизмы независимо от приложений (вне приложений) и, соответственно, исключить необходимость встраивания этих механизмов в каждое новое приложение. Таким образом в БД начинает выделяться уровень СУБД. Пока что это не полноценная СУБД, а только ее зачатки, но эти шаги задают направление дальнейшего развития. Между БД, как структурой хранения информации, и приложением появляется (пока еще тонкая) прослойка СУБД.
Примером реализации описанных механизмов могут служить структуры хранения информации, унаследованные от СУБД PARADOXи довольно часто применявшиеся в разработке локальных БД в средеDelphi. При использованииPARADOXструктур правила ссылочной целостности, ограничения и т.п. могут быть заданы при создании БД уже вне рамок конкретных приложений, как общий механизм, одинаково работающий для всех приложений, использующих данную конкретную БД.
Превращение СУБД в полноценный элемент архитектуры современных БД обусловлено, прежде всего, необходимостью обеспечения корректного взаимодействия с БД многочисленных одновременно работающих клиентов, то есть необходимостью коллективного доступа к хранимой информации. Проблема заключается в том, что одновременный нерегулируемый доступ к одним и тем же элементам БД со стороны различных пользователей может привести к непредсказуемым последствиям (например, поступление одновременных запросов на пополнение и снятие денег с одного и того же счета в банковской системе). Здесь неизбежно возникает необходимость в едином арбитре, который будет единолично управлять доступом к информации в базе данных и, соответственно, сможет урегулировать последовательность обращений к одним и тем же элементам с целью недопущения конфликтов между различными клиентами и их действиями.
Вот таким арбитром и становится СУБД. Только СУБД имеет непосредственный доступ к собственно БД. Все же приложения могут обращаться к СУБД с запросами на выполнение тех или иных действий в базе, но ни при каких обстоятельствах не могут получить непосредственный доступ к БД. Для взаимодействия приложений с СУБД используется специальный язык запросов SQL, который будет изучаться в настоящем курсе несколько позднее.
Таким образом, трехуровневое построение БД-СУБД-Приложения позволяет обеспечить корректный коллективный доступ к хранимой информации. Отметим, что «продвинутые» пользователи могут взаимодействовать с СУБД и помимо приложений. Для этого используются специальные утилиты. Но с точки зрения СУБД эти утилиты никоим образом не отличаются от всех прочих приложений, и взаимодействие с ними строится аналогично.
В современных базах данных иногда выделяется еще один структурный уровень и обусловлено это следующими причинами. Приложения баз данных могут представлять собой достаточно сложные и ресурсоемкие программы, которые работают в интерактивном режиме. То есть, большую часть времени программа ожидает действий пользователя, а затем должна достаточно быстро на них реагировать и выполнять требуемые вычисления (пользователь, в отличие от программы, не должен долго пребывать в режиме ожидания). Возникает противоречие: нужны значительные ресурсы, но они используются кратковременно.
Для разрешения указанного противоречия приложения могут быть вынесены на специальный достаточно мощный компьютер – «сервер приложений», а на рабочих местах при этом остаются только, так называемые, «тонкие клиенты», которые обеспечивают интерфейс пользователя к приложению и не требуют значительных ресурсов. В результате, пользователь и БД разделяются тремя уровнями: СУБД-Приложения-Клиенты.
Локальные и серверные базы данных.
Линия развития баз данных в применении к персональным компьютерам была направлена от локальных баз данных, работающих в однопользовательском режиме, к серверным базам данных коллективного доступа.
Локальная база данных строится по принципу: один компьютер – одна БД – один пользователь в каждый конкретный момент времени (рис. 7). Но такая связка хороша только для хранения персональной (личной) информации, тогда как информация в большинстве случаев является общей для множества пользователей и требует коллективного доступа. Для реализации такого доступа БД переместили с рабочего места на сервер (файл-сервер) локальной сети (рис. 8), а на рабочих местах пользователей остались только приложения, которые могли обращаться к общей базе данных.
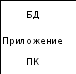
Рис. 7. Локальная база данных

Рис. 8. Файл-серверная база данных
Таким образом был обеспечен коллективный доступ к БД. Но, к сожалению, подобная реализация доступа имеет ряд существенных недостатков. Прежде всего, это большая сложность обеспечения одновременного доступа к одним и тем же элементам БД с разных рабочих мест. В системе нет арбитра, который бы регулировал порядок (очередность) доступа к БД. Этот порядок приходится реализовывать путем синхронизации работы приложений, что крайне сложно и не всегда возможно.
Файл-сервер в такой архитектуре никаких управляющих функций не выполняет, он только лишь хранит файлы БД, но никак не регулирует обращение к ее элементам. Если у пользователя есть права доступа к файлам БД, он может делать с ними все, что угодно. Естественно, что исполнение требований по соблюдению целостности хранимой информации всецело возлагается на приложения.
Наконец, отсутствие «интеллекта» у файл-сервера порождает проблему «тупой телефонистки» (для ответа на запрос о любом конкретном телефонном номере она начинает зачитывать телефонный справочник с буквы «А»), то есть вместо того, чтобы выбрать и передать пользователю только нужную ему информацию, файл-сервер передает всю имеющуюся информацию, оставляя решение задачи выбора за приложением. Как следствие, сильно и неоправданно растет нагрузка на локальную сеть.
Решение перечисленных проблем было найдено в клиент-серверной архитектуре (рис. 9). В такой архитектуре на сервере размещается не только собственно БД, но и СУБД, которая становится монопольным хозяином базы данных. СУБД принимает от приложений запросы на выполнение действий в БД, определяет порядок их выполнения, регулирует доступ к отдельным элементам базы данных, обеспечивает целостность хранимой информации. При этом по сети передается не «сырая», необработанная информация, а только результаты выполнения запросов.

Рис. 9. Клиент-серверная база данных
Кроме того, приложения в клиент-серверных базах данных разделяются на две части: клиентскую и серверную. Серверная часть приложений, как правило, сосредотачивает в себе всю вычислительную нагрузку и выполняется в рамках сервера БД. Для этих целей большинство SQL-серверов БД поддерживает специальные процедурные расширения языкаSQL, предназначенные для реализации процедур обработки информации. В клиентской же части приложений обычно стараются оставить только элементы, обеспечивающие интерфейс пользователя, что уменьшает аппаратные требования к рабочим местам.
Такое разделение обеспечивает также простое масштабирование системы: увеличение сложности обработки информации или необходимость повышения ее производительности требует только наращивания мощности сервера, а рабочие места остаются без изменений. Упрощается сопровождение БД, поскольку изменения по большей части вносятся на серверной стороне и не затрагивают множество рабочих мест. Кроме того, для различных приложений, работающих с одной и той же БД, серверные части могут существенно пересекаться, что упрощает их разработку и решение проблем обеспечения целостности хранимой информации.
Дальнейшее развитие этой линии в истории БД также приводит к трехзвенной архитектуре (рис. 10), когда серверные части приложений выносятся на отдельный компьютер, называемый сервером приложений. При этом обеспечивается большая гибкость при конфигурировании и масштабировании системы.

Рис. 10. Трехзвенная архитектура баз данных
Мы рассмотрели три направления в истории развития баз данных. Их разделение достаточно условно и все они тесно переплетаются и влияют друг на друга. Так, например, выделение СУБД и переход к клиент-серверной модели обусловлены необходимостью реализации корректного многопользовательского доступа, а движение к трехзвенной архитектуре обусловлено как дифференциацией функций в базах данных, так и изменением способов доступа к ним.
Кроме того, переход от одних форм к другим не означает, что предыдущие формы полностью исчезли из употребления. На самом деле происходит смещение акцентов, и каждая форма занимает свою нишу в достаточно большом многообразии БД. Например, концептуально БД начинались с иерархической и сетевой моделей, а затем абсолютное лидерство перешло к реляционной модели данных.
Реляционная модель данных. Отношения и таблицы.
РМД основана на математическом понятии отношения.
Пусть заданы два
множества
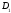 и
и ,
имеющие своими элементами:
,
имеющие своими элементами: ,
, .Декартовым произведениемэтих
множеств называется множество всех
возможных попарных комбинаций элементов
.Декартовым произведениемэтих
множеств называется множество всех
возможных попарных комбинаций элементов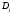 и
и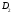 ,
в которых на первом месте стоит элемент
,
в которых на первом месте стоит элемент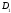 ,
а на втором –
,
а на втором –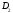 :
:
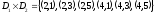 .
.
Любое подмножество этого декартова произведения называется отношением. Например, такое:
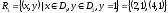 .
.
Физическим аналогом математического отношения является таблица:
|
|
1 |
3 |
5 |
|
2 |
(2,1) |
(2,3) |
(2,5) |
|
4 |
(4,1) |
(4,3) |
(4,5) |
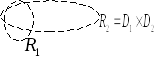
В теории баз данных отношение – это плоская (двумерная) таблица, состоящая из строк и столбцов. Таблицы в БД используются для хранения информации об определенного типа объектах или процессах реального мира. При этом каждому отдельно взятому объекту или процессу соответствует отдельная строка таблицы. А столбцы таблицы соответствуют отдельным свойствам объектов (процессов).
Например, таблица «Предметы» используется для хранения информации о предметах. При этом каждому наименованию предметов (с учетом цены) соответствует отдельная строка, а столбцы соответствуют свойствам предметов: наименование, ед. измерения, цена.
Поименованный столбец отношения называется атрибутом.
Замечание. Здесь имеет место одно из отличий теории БД от чистой математики. Для математики элементы (2,1) и (1,2) различны. А в базах данных порядок следования столбцов не имеет значения, поскольку они поименованы.
Множество допустимых значений атрибута называется доменом атрибута.
Например, для атрибутов типа «Наименование» домен может быть задан, как символьная строка длиной 50 символов. Для атрибутов типа «Условный номер» – как целое положительное число. И т.п.
Каждый атрибут должен быть определен на некотором домене (т.е. для каждого атрибута следует ограничить область допустимых значений с тем, чтобы уменьшить вероятность возникновения ошибок). На одном домене может быть определено несколько атрибутов, но каждый отдельный атрибут может быть определен только на одном домене.
Строка отношения называется кортежем.
Количество атрибутов (столбцов) в отношении (таблице) называется степеньюотношения. Степень отношения обычно величина постоянная и задается в момент создания отношения. Конечно, количество столбцов в таблице может меняться, но это происходит достаточно редко и свидетельствует, как правило, о недоработках допущенных на этапе проектирования БД.
Количество кортежей (строк) в отношении (таблице) называется кардинальностьюотношения. Кардинальность отношения обычно величина переменная и изменяется по мере добавления или удаления строк в таблице. При этом существуют так называемые справочные таблицы, которые изменяются редко или вообще не изменяются после начального заполнения (например, таблица типов лиц).
Реляционная модель данных– это совокупность связанных отношений.
Замечание. Обратите внимание, что термину «отношение» в англоязычной среде соответствует термин «relation», а с другой стороны «связь» по-английски также «relation». Поэтому название «реляционная» как нельзя лучше соответствует этой модели данных.
Как вы уже могли заметить, при работе с базами данных используются различные наименования схожих понятий. Для ясности приведем таблицу соответствия используемых терминов.
Таблица 10. Терминология
|
Реальный мир |
Математика |
Модель данных |
Локальные БД |
Серверные БД |
|
Тип объектов (процессов) |
отношение |
тип сущности |
файл |
таблица |
|
Экземпляр объекта (процесса) |
кортеж |
экземпляр сущности |
запись |
строка |
|
Свойство объекта (процесса) |
атрибут |
атрибут |
поле |
столбец |
Реляционные ключи.
Каждой строке в таблице наличия соответствует единственная строка в таблице лиц и единственная строка в таблице предметов. По этим строкам мы можем судить: о наличии какого предмета и у какого лица идет речь в конкретной строке таблице наличия. Очевидно, что для реализации указанной связи необходим механизм, который позволит найти те самые единственно нужные строки в таблицах лиц и предметов, то есть механизм уникальной идентификации строк в таблицах. Этот механизм получил название реляционных ключей. Попытаемся разобраться – как он устроен.
Любое множество атрибутов отношения, позволяющее однозначно идентифицировать каждый кортеж этого отношения, называется суперключом.
Например, для таблицы предметов суперключом является условный номер предмета. Также суперключом является набор атрибутов «наименование» + «цена». Суперключ, который не содержит подмножества атрибутов, также являющегося суперключом, называется потенциальным ключом.
Потенциальных ключей в отношении может быть несколько, но для уникальной идентификации кортежей необходимо выбрать какой-то один из них.
Потенциальный ключ, который выбран для уникальной идентификации кортежей некоторого отношения, называется первичным ключомэтого отношения (ПК,PrimaryKey,PK). При этом все остальные потенциальные ключи становятсяальтернативными ключами.
Например, если первичный ключ таблицы предметов определить по атрибуту условного номера, то совокупность атрибутов «наименование» + «цена» следует считать альтернативным ключом.
Замечание.Одна и та же таблица в разных своих связях может выступать и как родительская и как дочерняя. Например, таблица лиц в своих связях с таблицами типов лиц и подразделений является дочерней, а в связях с таблицами наличия и проводок – родительской.
Атрибуты первичного ключа родительского отношения, включаемые в дочернее для реализации его связи с родительским отношением, называются внешним ключом(ВК,ForeignKey,FK).
Внешние ключи, в отличие от первичных, свойством уникальности не обладают. Внешних ключей в таблице может быть несколько, тогда как первичный ключ всегда один.
Как отмечалось ранее, отношение может иметь несколько потенциальных ключей и только один из них должен быть выбран в качестве первичного. Сформулируем принципы, которыми следует руководствоваться при этом выборе.
Первичный ключ должен обеспечивать уникальную идентификацию строк не только при текущем состоянии таблицы, но и с учетом всех возможных изменений в будущем.
Первичный ключ должен иметь минимально возможный размер, поскольку он импортируется во все дочерние отношения в качестве внешних ключей. Соответственно, большой размер первичного ключа приведет к неоправданному росту объема дочерних отношений.
Атрибуты первичного ключа должны изменяться как можно реже. Дело в том, что всякое изменение атрибутов первичного ключа влечет за собой соответствующие изменения атрибутов внешних ключей. Например, если условный номер лица изменился с 5 на 25, то во всех соответствующих строках таблиц наличия и проводок значение 5 необходимо заменить значением 25.
Отношение "один ко многим". Родительские и дочерние таблицы.
В каждой паре связанных таблиц можно указать родительскую (главную, Master) и дочернюю (подчиненную,Detail) таблицу. При этомкаждая запись дочерней таблицыдолжнассылаться наединственнуюсоответствующую ей запись родительской таблицы. Алюбаязапись родительской таблицыможетбыть связанас несколькимизаписями дочерней. Например, для связи таблиц предметов и наличия имеем следующую схему:
Предметы Наличие
|
Усл. № |
Наимен. |
Ед. изм. |
Цена |
|
Лицо |
Предмет |
Кол-во |
|
. . . |
|
|
|
|
. . . |
|
|
|
12 |
Стул |
шт |
800.00 |
|
3 |
7 |
2 |
|
23 |
Кресло |
шт |
2000.00 |
|
3 |
12 |
8 |
|
7 |
Стол |
шт |
1600.00 |
|
17 |
12 |
3 |
|
. . . |
|
|
|
|
9 |
7 |
5 |
|
|
|
|
|
|
9 |
12 |
20 |
|
|
|
|
|
|
. . . |
|
|

Такую связь таблиц принято называть один-ко-многим (или многие-к-одному, если посмотреть на связь с другой стороны). То есть, одной строке родительской таблицы может соответствовать множество записей дочерней, но каждой записи дочерней таблицы всегда соответствует только одна запись родительской.
Связи типа один-ко-многим – это основной вид связей в реляционных базах данных. Гораздо реже встречаются связи типа один-к-одному, при которых одной родительской записи соответствует одна дочерняя и наоборот. Такого рода связи возникают, например, в тех случаях, когда отношение делится на две таблицы с тем, чтобы вынести в отдельную таблицу редко используемые атрибуты или атрибуты, к которым необходимо ограничить доступ (фото, пароли и т.п.).
При проектировании БД часто приходится иметь дело со связями типа многие-ко-многим. Например, подотчетные лица отвечают за хранение предметов (у одного п/о лица хранится множество предметов и один и тот же предмет может быть у нескольких лиц). Однако такого рода связи не могут быть реализованы в рамках реляционной модели данных и на этапе логического проектирования заменяются парами связей типа один-ко-многим.
Итак, основной вид связей в РБД это связи типа один-ко-многим. Очевидно, что для их реализации необходимо иметь возможность найти в родительской таблице ту единственную запись, которая соответствует текущей дочерней записи. То есть, в родительском отношении обязательно должен присутствовать механизм уникальной идентификации. Отсюда следует вывод.
Каждое отношение, которое в каких-либо своих связях выступает как родительское, должно иметь первичный ключ.
Первичные и внешние ключи.
Потенциальный ключ, который выбран для уникальной идентификации кортежей некоторого отношения, называется первичным ключомэтого отношения (ПК,PrimaryKey,PK). При этом все остальные потенциальные ключи становятсяальтернативными ключами.
Например, если первичный ключ таблицы предметов определить по атрибуту условного номера, то совокупность атрибутов «наименование» + «цена» следует считать альтернативным ключом.
Замечание.Одна и та же таблица в разных своих связях может выступать и как родительская и как дочерняя. Например, таблица лиц в своих связях с таблицами типов лиц и подразделений является дочерней, а в связях с таблицами наличия и проводок – родительской.
Атрибуты первичного ключа родительского отношения, включаемые в дочернее для реализации его связи с родительским отношением, называются внешним ключом(ВК,ForeignKey,FK).
Внешние ключи, в отличие от первичных, свойством уникальности не обладают. Внешних ключей в таблице может быть несколько, тогда как первичный ключ всегда один.
Как отмечалось ранее, отношение может иметь несколько потенциальных ключей и только один из них должен быть выбран в качестве первичного. Сформулируем принципы, которыми следует руководствоваться при этом выборе.
1. Первичный ключ должен обеспечивать уникальную идентификацию строк не только при текущем состоянии таблицы, но и с учетом всех возможных изменений в будущем.
2. Первичный ключ должен иметь минимально возможный размер, поскольку он импортируется во все дочерние отношения в качестве внешних ключей. Соответственно, большой размер первичного ключа приведет к неоправданному росту объема дочерних отношений.
3. Атрибуты первичного ключа должны изменяться как можно реже. Дело в том, что всякое изменение атрибутов первичного ключа влечет за собой соответствующие изменения атрибутов внешних ключей. Например, если условный номер лица изменился с 5 на 25, то во всех соответствующих строках таблиц наличия и проводок значение 5 необходимо заменить значением 25.
Индексы и ключи.
Такая таблица называется индексомтаблицы «Наличие» по полю «Лицо».
Такой подход позволяет значительно ускорить поиск нужных строк, поскольку:
Таблица индекса имеет меньший объем, чем исходная таблица, т.к. содержит только индексируемые поля.
Записи в индексе упорядочены по значениям полей поиска.
Поиск в таблице индекса ведется не прямым перебором записей, а с использованием специальных алгоритмов, ускоряющих эту процедуру (например, делением пополам области поиска).
Таким образом, индексы позволяют существенно ускорить операции поиска, а также операции сортировки. С другой стороны, реализация связей между дочерними и родительскими таблицами сводится к выполнению операций поиска (поиск нужной родительской записи или всех соответствующих дочерних записей). Здесь возникает очевидная идея использовать для ускорения операций поиска соответствующие индексы. Именно по этой причине во всех СУБД по определениям первичных и внешних ключей всегда строятся индексы. Причем делается это независимо от желания пользователя.
Такая взаимосвязь между ключами и индексами породила некоторую путаницу при использовании этих понятий. Нередко можно встретить использование термина «ключ» в отношении индекса и наоборот. Во избежание проблем следует запомнить:
Ключи – это, по существу, логическая конструкция, определяющая принципы взаимосвязи между родительскими и дочерними отношениями.
Индексы – это физический механизм, позволяющий значительно ускорить выполнение операций поиска и сортировки и используемый, в частности, для реализации ключевых взаимодействий.
Индексы, создаваемые по определениям ключей, принято называть первичными. Помимо них для ускорения поиска и сортировки могут создаваться индексы и по неключевым полям. Их называютвторичными. При создании таких индексов следует иметь в виду, что индексы, с одной стороны, ускоряя поиск и сортировку, с другой стороны, замедляют выполнение операций по изменению содержимого индексируемых таблиц. Дело в том, что всякое изменение значений индексных полей требует соответствующих изменений в таблицах индексов. При этом полная перестройка индексных таблиц невозможна из-за неприемлемых временных затрат. Приходится достраивать индексы по определенным правилам, но накопление такого рода достроек приводит к падению эффективности индексного поиска. Рано или поздно наступает ситуация, при которой прямой перебор содержимого таблицы оказывается более выгодным, чем использование «плохого» индекса.
Таким образом, индексы не являются универсальным средством, которое можно использовать везде и всюду для повышения производительности. Кроме того, они требуют специальных мероприятий по поддержанию своей полезности. Необдуманное применение индексов может не только оказаться неэффективным, но и замедлит работу всей БД.
В заключение рассмотрим некоторые разновидности индексов.
Составнойиндекс – это индекс, построенный по нескольким полям. При этом порядок следования полей в индексе суть важен. Например, индекс таблицы наличия по полям «Лицо» + «Предмет»:может быть использован как для поиска по паре полей «Лицо» + «Предмет», так и для поиска по полю «Лицо», но не может быть использован для поиска по полю «Предмет», поскольку по этому полю он не упорядочен.
Уникальный (Unique)индекс – это индекс, в котором каждому набору значений индексных полей может соответствовать только одна запись. Такого рода индексы строятся, например, по определениям первичных и альтернативных ключей. В нашем примере имеет смысл построить уникальный индекс в таблице предметов по полям «Наименование» + «Цена» с тем, чтобы сделать невозможным добавление одного и того же предмета дважды.
Регистрочувствительный (Case Sensitive)индекс – это индекс, учитывающий регистр букв при сортировке.
Индекс в обратном порядке (Descending)– это индекс, построенный в порядке убывания значений индексных полей (обычный индекс строится в порядке возрастания). Такие индексы часто используются для упорядочения по датам с тем, чтобы вначале располагались более поздние даты. Например, таблицу проводок имеет смысл сортировать в порядке убывания их дат, чтобы в первую очередь видеть более поздние проводки.
Целостность сущностей. NULL. Бизнес-правила.
Целостность БД– это совокупность механизмов, обеспечивающих достоверность хранимой информации.
Прежде, чем рассматривать проблемы целостности, остановимся на одном важном понятии, используемом в серверных БД.
Идентификатор NULLуказывает на то обстоятельство, что некоторому атрибуту конкретного кортежа (полю записи) не присвоено никакого значения.
Замечание.Недопустимо говорить «поле имеет значениеNULL».NULL– это отсутствие какого бы то ни было значения.
Ограничение NOTNULL(отсутствие значения не допустимо) в отношении целочисленного поля не означает, что туда не может быть записано нулевое значение. Это ограничение означает, что полю обязательно должно быть присвоено значение и, в частности, этим значением может быть и ноль. Аналогично, для строковых полей и переменных пустая строка также является значением.
Использование идентификатора NULLхарактерно для серверных баз данных. Дело в том, что в локальных БД при создании новой записи под нее тут же отводится место, которое обычно инициализируется некоторыми значениями (для числовых полей это нулевое значение). То есть, в локальных БД поле всегда имеет некоторое значение, даже если это значение никто ему не присваивал. В серверных же БД полям, не имеющим значения, место не отводится, а в заголовке записи делается отметка, что поле значения не имеет (находится в состоянииNULL).
Особое внимание в отношении возможного отсутствия значения у поля или переменной следует уделять при написании серверных частей приложений. Дело в том, что с учетом возможности NULLимеет место не двузначная логика (да, нет), а трехзначная (да, нет, значение отсутствует). Например, оператор:
if a > 0 then оператор1 else оператор2;
рассматривается следующим образом: если a > 0, тогда выполняетсяоператор1, еслиa <= 0илиaне имеет значения, то выполняетсяоператор2.
Много ошибок и недоразумений возникает при вычислении разного рода выражений. Здесь действует правило: если какой-либо операнд в выражении не имеет значения, то и результатом вычисления всего выражения также будет отсутствие значения. Например, в результате вычисления выражения c = a + b, приb = 1иa, не имеющем значения (a is NULL), вcтакже будет отсутствовать значение (c is NULL). Более того, выражениеa = a + 1не присвоитaникакого значения, еслиaне имела значения исходно.
Первое ограничение целостности относится к первичным ключам и называется целостностью сущностей. Оно гласит, что для атрибутов первичных ключей недопустимо отсутствие значений. То есть, все атрибуты первичных ключей должны задаваться с ограничениемNOTNULL(Requiredв терминологии локальных БД).
Физический смысл такого ограничения очевиден. Первичные ключи предназначены для уникальной идентификации кортежей отношений. Ясно, что при отсутствии значения в атрибуте ПК, ни о какой уникальной идентификации речи быть не может (ситуация не определена, то есть не однозначна).
О целостности сущностей следует помнить не только при определении структуры БД, но и при написании приложений. Приложения должны создаваться таким образом, чтобы у пользователя не было возможности оставить поля первичного ключа не заполненными.
Ссылочная целостность. Механизм каскадных изменений.
Второе ограничение целостности относится к внешним ключам и называется ссылочной целостностью. Заключается оно в следующем: значения атрибутов внешнего ключа в любом кортеже дочернего отношения должно совпадать со значениями атрибутов первичного ключа в каком-либо кортеже родительского отношения. Другими словами: в полях внешнего ключа дочернего отношения могут встречаться только те значения, которые есть в полях первичного ключа родительского отношения. В некоторых случаях допускается отсутствие значений (NULL) в полях внешнего ключа.
Например, в таблице наличия в полях «Лицо» и «Предмет» могут использоваться только те условные номера лиц и предметов, которые есть в таблицах лиц и предметов, соответственно. Здесь отсутствие значений в полях ВК не допустимо, в противном случае это будет наличие у неизвестно какого лица или неизвестно какого предмета. А вот в таблице лиц допустимо отсутствие значения в поле «Подразделение», т.к., поставщики и направления списания не имеют отношения к подразделениям.
Ссылочная целостность накладывает ограничения не только на дочерние, но и на родительские отношения. Действительно, совершенно очевидно, что недопустимо удалять в родительском отношении те строки, на которые есть ссылки из дочерних отношений. Например, если у лица с номером 5 есть какие-то предметы в наличии, то информацию о нем нельзя удалять из таблицы лиц.
При изменении значений в полях первичного ключа родительского отношения, такие же изменения необходимо выполнить в полях внешних ключей дочерних отношений. Например, если условный номер лица изменился с 5 на 25, то и в таблицах наличия и проводок в полях «Лицо», «Расход» и «Приход» значение 5 должно быть изменено на 25.
За поддержание ссылочной целостности в СУБД отвечает специальный механизм, который называется механизмом каскадных изменений. Работает он следующим образом.
При попытке удаления строки из родительской таблицы делается проверка: есть ли в дочерних таблицах строки, ссылающиеся на удаляемую. Если таких строк нет, то операция разрешается. Если есть – то операция или запрещается или перед удалением родительской строки удаляются все ссылающиеся на нее дочерние строки (каскадное удаление).
Аналогичная проверка делается и при попытке изменения значений полей первичного ключа родительского отношения. Если есть ссылающиеся дочерние строки, то операция или запрещается или точно такие же изменения выполняются в полях внешних ключей дочерних отношений (каскадное изменение).
Варианты работы механизма каскадных изменений прописываются отдельно для каждого внешнего ключа. Выбор вариантов зависит от конкретных условий. Чаще всего используется запрет на удаление и каскад на изменение.
Ссылочная целостность должна учитываться и при написании приложений. Обычно пользователю не дают возможности непосредственного ввода значений в поля внешних ключей дочерних отношений. Вместо этого ему предоставляют возможность выбора нужной строки из родительского отношения, а значения его первичного ключа программно копируют в поля внешнего ключа дочернего отношения (механизм Lookup-полей). Например, пользователь не должен знать ни о каких условных номерах лиц и предметов. При добавлении строки в таблицу наличия ему должен быть предоставлен выбор лица и предмета из соответствующих таблиц с показом их реальных наименований, а не условных номеров. Условные номера в строку наличия должны подставляться программным образом.
Семантическая целостность. Механизм транзакций.
Следующее ограничение называется семантической (смысловой) целостностью. Оно подразумевает, что все операции в базе данных должны выполняться таким образом, чтобы не нарушались смысловые связи в хранимой информации.
Вернемся к нашему примеру и рассмотрим процесс передачи предметов от одного лица к другому. Этот процесс порождает в базе данных три операции: уменьшение количества предметов в наличии у передающего лица, увеличение – у принимающего и добавление соответствующей строки в таблицу проводок. Предположим, что после выполнения первой операции произошел сбой (например, выключили питание) и оставшиеся две операции не были выполнены. Тогда достоверность хранимой информации будет нарушена, поскольку предметы от одного лица ушли, а к другому не пришли, то есть, как бы исчезли из БД. Отметим, что ссылочная целостность при этом никак не пострадает, будут нарушены только смысловые связи, то есть, семантическая целостность.
В целях обеспечения семантической целостности в СУБД используется механизм транзакций.Транзакция– это совокупность операций, переводящая базу данных из одного целостного состояния в другое целостное состояние. Если все операции, составляющие транзакцию, выполняются успешно, то транзакция подтверждается и все изменения, выполненные в ее рамках, фиксируются в БД. Если при выполнении любой операции происходит ошибка, то транзакция отменяется и БД откатывается к состоянию, имевшему место на начало транзакции. Таким образом, транзакция выполняется либо полностью, либо не выполняется вовсе.
В нашем примере для обеспечения семантической целостности все три операции следовало бы объединить в рамках одной транзакции.
Замечание. Полноценно механизм транзакций реализован только для серверных БД.
Последнее ограничение целостности называется бизнес-правилами(корпоративными ограничениями целостности). Это ограничения, которые обусловлены конкретной сферой применения базы данных. То есть, ограничения, имеющие отношение только к данной конкретной БД.
В нашем примере можно выделить такие бизнес-правила: поставщики должны передавать предметы только лицам, работающим на центральном складе; поставщики не имеют права списывать предметы; в одном подразделении могут работать несколько подотчетных лиц и т.д.
Невизуальные компоненты Delphi для работы с БД.
Перечислим наиболее часто используемые невизуальные компоненты.
TDatabase – определяет общие параметры связи с БД (имеет большое значение для серверных БД; для локальных может не использоваться, поскольку параметры связи заданы вAliasBDE).
TTable – компонент для работы с набором данных (НД) в виде отдельной таблицы БД.
TQuery – компонент для работы с НД, полученным в результате выполнения SQL запроса к БД (обычно используется в приложениях серверных БД).
TStoredProc – компонент для работы с НД, полученным в результате выполнения хранимой на сервере процедуры (используется в приложениях серверных БД).
TField – компонент для работы с отдельными полями наборов данных. (Непосредственно в приложениях не используется. Используются его потомки TStringField, TIntegerField и т.д.)
TTable, TQuery, TStoredProc имеют общего предка TDataSet, определяющего основные свойства и методы работы с набором данных независимо от его происхождения. Сам TDataSet непосредственно в приложениях не используется.
В этом параграфе рассмотрим более подробно компонент TField, который можетбыть поставлен в соответствие каждому полю набора данных. Если хотя бы для одного поля набора данных определен TField, то в приложении будут доступны только те поля, для которых созданы компоненты TField. Если ни для одного поля набора данных TField не создавался, то по умолчанию доступны все поля. Эту особенность можно, в частности, использовать для ограничения доступа к отдельным полям НД.
При этом в любом варианте доступ к полю можно получить с помощью метода FieldByName. Например:
LicaT.FieldByName(‘Name’)
NalichieT.FieldByName(‘Kolvo’)
Замечание. Здесь подразумевается доступ не к значению поля, а ко всему полю как к объекту, имеющему ряд свойств и методов.
Компонентам TField по умолчанию присваиваются имена вида: имя набора данных + имя поля. Например, LicaTName,NalichieTKolvo. Поэтому следует избегать применения подобных имен в других целях.
Помимо имени, для каждого компонента TField можно задать ряд других свойств: только для чтения (ReadOnly), требование обязательного ввода значения (Required), формат отображения значения (DisplayFormat), минимальное и максимальное значения и т.д.
Компонент TField обеспечивает доступ к полю в целом, а не только к его значению. Для доступа же собственно к значению, хранящемуся в поле, используются свойство Value, а так же AsBoolean, AsCurrency, AsDateTime, AsFloat, AsInteger, AsString, AsVariant. Например:
var s:string;
. . .
s := LicaT.FieldByName(‘Name’).Value;
s := LicaTName.Value;
s := LicaTName.AsString;
Допустимо также:
s := LicaT[‘Name’]; что эквивалентно: s := LicaT.FieldValues[‘Name’];
Свойство Value предполагает неявное преобразование типа значения. Во избежание недоразумений “по умолчанию”, лучше использовать явное преобразование As***.
Lookup поля.
При визуализации дочерних таблиц часто возникает необходимость показа информации из родительских таблиц. Например, при показе таблицы наличия, необходимо показывать не условные номера предметов и лиц, а их реальные наименования.
В этих целях используются так называемые Lookup поля. Например, в таблице наличия таким полем будет поле PredmetName, содержащее реальное наименование предмета, которое извлекается из таблицы предметов по условному номеру предмета.
При создании Lookup поля с помощью редактора полей необходимо определить доступ к родительскому набору данных, указав следующие параметры:
Key Fields – поля внешнего ключа, по которым ищется информация в родительском наборе данных (здесь Predmet);
Dataset – родительский набор данных (PredmetyT);
Lookup Keys – поля первичного ключа родительского набора данных, которые соответствуют полям внешнего ключа дочернего набора данных (NPredm);
Result Field – поле родительского набора данных, значение которого будет подставляться в создаваемое Lookup поле (Name).
Замечание: Lookup поля используются и для ввода значений в дочернюю таблицу путем выбора соответствующих записей из родительской таблицы.
Вычисляемые поля.
Иногда при визуализации информации, хранящейся в БД, возникает необходимость в показе атрибутов, которые физически отсутствуют в БД, но могут быть легко вычислены на основе представленных в БД атрибутов. Например, в таблице наличия показывается количество предметов и их цена (как Lookup поле), а также необходимо показать их общую стоимость (произведение количества на цену). Или, например, в БД о работниках предприятия хранится информация о семейном положении сотрудников в виде логического поля; необходимо визуализировать эту информацию в виде слов: женат, холост, замужем, не замужем в зависимости от пола сотрудника.
В этих целях используются вычисляемые поля. Они создаются с помощью редактора полей, так же как и Lookup поля, но тип поля указывается, как Calculated. Собственно расчет значений вычисляемых полей производится в обработчике события OnCalcFields соответствующего набора данных. Это событие наступает при любом перемещении по набору данных (в том числе и при открытии НД), кроме того, если свойство НД AutoCalcFields установлено в True, то событие наступает и при любом изменении полей НД.
Замечание1. Событие OnCalcFields может наступать очень часто, поэтому следует минимизировать код его обработчика. Иначе перемещения по набору данных могут существенно замедлиться.
Замечание2. В обработчике OnCalcFields значения могут присваиватьсятольковычисляемым полям.
Визуальные компоненты Delphi для работы с БД.
Визуальные компоненты, предназначенные собственно для работы с базами данных, расположены на странице Data Controls. Рассмотрим основные из них, их назначение и наиболее часто используемые свойства.
TDBGrid – предназначен для показа набора данных в табличном виде. Его свойство DataSource должно указывать на компонент TDataSource визуализируемого набора данных.
Набор показываемых на форме столбцов может задаваться двояко.
Если с помощью редактора столбцов (Columns Editor) определен хотя бы один столбец, то в таблице показываются только те столбцы, которые были явно определены в редакторе, и в том виде, в каком они были определены.
Если ни один столбец не определялся с помощью редактора столбцов, то показываются все столбцы набора данных в том виде и в том порядке, в каком они были определены в редакторе полей при создании компонентов TField соответствующего набора данных. Если компоненты TField не создавались, то используется определение полей из самой базы данных.
Как и в случае с редактором полей предпочтительно явное определение показываемых полей в редакторе столбцов, поскольку такой подход обеспечивает большую гибкость.
Для определения столбцов с помощью редактора столбцов в контекстном меню TDBGrid выбирается пункт Columns Editor…, а в контекстном меню появившегося окна пункт Add All Fields. В результате в таблицу будут добавлены все поля. В дальнейшем, поля, не подлежащие показу, удаляются из списка (Delete), а порядок полей в таблице может изменяться перетаскиванием полей в списке редактора столбцов.
Для каждого из столбцов можно указать ряд свойств, в частности:
Alignment – способ выравнивания значений в столбце (влево, вправо, по центру);
ReadOnly – допустимость редактирования значений в столбце;
PickList – список для выбора возможных значений при редактировании (например, это может быть список единиц измерения);
Title – свойства заголовка столбца (текст, шрифт и т.п.).
Сам компонент TDBGrid также имеет ряд свойств, определяющих его поведение. Эти свойства сгруппированы под общим наименованием Options. В частности, наибольший интерес представляют следующие из них:
dgEditing – разрешение на изменение, добавление и удаление записей;
dgAlwaysShowEditor – выбор поля автоматически переводит его в режим редактирования;
dgConfirmDelete – перед удалением записи выдается запрос на подтверждение операции;
dgRowSelect – инверсная полоса показывает всю выбранную запись, а не только выбранное поле (при этом редактирование записи непосредственно в TDBGrid запрещается);
dgAlwaysShowSelection – инверсная полоса показывается всегда (и тогда, когда фокус управления не принадлежит TDBGrid), чтобы пользователю легко было видеть – какая запись является текущей;
dgTabs – клавиша Tab используется для перемещения между столбцами (в обратном направлении – Shift+Tab). Иначе Tab используется для перемещения между компонентами.
Перемещение по таблице возможно с помощью клавиш управления курсором, клавиши Tab и мыши.
Редактирование, добавление и удаление записей непосредственно в DBGrid допускается, если:
свойство ReadOnly соответствующего НД установлено в False;
свойство ReadOnly самой DBGrid – False;
опция dgEditing – True;
свойство ReadOnly соответствующего столбца – False.
Для
редактирования значения некоторого
поля необходимо, находясь в нем, нажать
Enter (или двойной щелчок мыши) или сразу
начать набирать новое значение. При
этом индикатор текущей записи в самой
левой колонке DBGrid изменит вид с на
I .
Для подтверждения изменений, внесенных в поле, следует нажать Enter или перейти к другому полю (Tab). Для отмены изменений следует нажать Esc. Для подтверждения изменений, внесенных во все поля записи, необходимо перейти к другой записи. Для отмены второй раз нажать Esc.
Замечание: все изменения, вносимые в НД, должны соответствовать правилам БД (ссылочная целостность, бизнес-правила и т.п.), зафиксированным при создании базы. В противном случае изменения будут отвергнуты, и последует сообщение об ошибке (например, Key Violation, если нарушена уникальность первичного ключа или уникального индекса).
Для вставки новой записи необходимо нажать Insert или, находясь на последней записи, клавишу ↓. Для удаления записи – Ctrl+Delete.
Визуальные компоненты для работы с отдельными полями текущей записи используются в тех случаях, когда применение DBGrid вообще нецелесообразно (например, когда в записи много полей или они имеют большой размер) или когда нецелесообразно редактирование записей непосредственно в таблице DBGrid. Иногда DBGrid и компоненты для отдельных полей используются одновременно (например, в DBGrid показываются основные поля, а все остальные поля показываются отдельно только для текущей записи). Возможны и другие применения этих компонентов.
В свойствах визуальных компонентов, предназначенных для работы с отдельными полями, помимо указания набора данных в DataSource указывается также имя конкретного поля в свойстве DataField. Перечислим наиболее часто используемые компоненты (их вид приведен на рис. 19).
TDBText предназначен для показа значения поля без возможности его редактирования (подобно Label).
TDBEdit позволяет редактировать значение поля, которое находится в свойстве Text. При вводе автоматически отслеживается соответствие вводимых символов типу поля. Например, в числовое поле нельзя вводить буквы.
TDBCheckBox обычно используется для отображения логических значений. Основное свойство Checked. Когда оно установлено в True в компоненте проставляется «галка» выбора. Собственно значения поля, которым соответствует состояние свойства Checked, указываются в свойствах ValueChecked и ValueUnchecked.
TDBRadioGroup набор переключателей с зависимой фиксацией. Варианты выбора перечисляются в свойстве Items. Номер выбранного варианта содержится в свойстве ItemIndex (нумерация начинается с нуля).
TDBComboBox выпадающий список выбора. Items список вариантов; ItemIndex выбранный вариант.
TDBLookupComboBox (рис. 20) по виду аналогичен TDBComboBox, но вместо фиксированного набора вариантов используется для подстановки значений в поля дочернего НД путем выбора соответствующих значений из родительского НД. Например, в записях таблицы наличия содержится условный номер предмета, но при вводе и показе значений этого поля пользователь должен иметь дело не с условным номером предмета, а с его наименованием. В таких случаях и используется TDBLookupComboBox. Его работа определяется следующими свойствами:
DataSource указывает на TDataSource дочернего НД (в данном примере NalichieDS), с которым ведется работа;
DataField поле дочернего НД (Predmet);
ListSource указывает на TDataSource родительского НД (PredmetyDS);
ListField поле родительского НД, значения которого будут показываться в списке выбора (Name);
KeyField поле родительского НД (NPredm), значение которого будет присвоено полю дочернего НД, указанному в свойстве DataField (Predmet), в результате выбора, сделанного пользователем.
Работа с полями. Компонент TField.
TField – компонент для работы с отдельными полями наборов данных. Непосредственно в приложениях не используется. Используются его потомки TStringField, TIntegerField и т.д.
Каждому полю набора данных (НД) может быть поставлен в соответствие компонент TField. Если хотя бы для одного поля набора данных определен TField, то в приложении будут доступны только те поля, для которых созданы компоненты TField. Если ни для одного поля набора данных TField не создавался, то по умолчанию доступны все поля. Эту особенность можно, в частности, использовать для ограничения доступа к отдельным полям НД.
Замечание: использование компонентов TField при создании приложений обеспечивает гораздо более гибкую работу и предоставляет в распоряжение разработчика массу полезных инструментов. Поэтому использование TField рекомендовано всегда, за исключением самых простых англоязычных приложений.
Компоненты TField создаются с помощью редактора полей (рис. 16). Для этого в контекстном меню набора данных выбирается пункт Fields Editor…, после чего появляется окно редактора. Из его контекстного меню можно создать компоненты TField для всех полей НД (Add all fields) или только для выбранных (Add fields...).
Рис. 16. Редактор полей и его контекстное меню
Компонентам TField по умолчанию (автоматически) присваиваются имена вида: имя набора данных + имя поля. Например, LicaTName, NalichieTKolvo. Соответственно, следует избегать применения подобных имен в других целях.
Помимо имени, для каждого компонента TField можно задать ряд других свойств: только для чтения (ReadOnly), требование обязательного ввода значения (Required), формат показа значения (DisplayFormat), минимальное и максимальное значения и т.д.
Компонент TField обеспечивает доступ к полю в целом, а не только к его значению. Для доступа к значению, хранящемуся в поле, используются свойства Value, а так же AsBoolean, AsCurrency, AsDateTime, AsFloat, AsInteger, AsString, AsVariant.
Общие принципы работы с наборами данных.
Набор данных может находиться в одном из семи состояний:
dsInactive набор данных закрыт: возможны действия только в отношении всего НД (его удаление или создание); доступ к отдельным записям не возможен;
dsBrowse состояние просмотра (в это состояние НД переводится после открытия); возможны любые перемещения по НД;
dsEdit состояние редактирования текущей записи;
dsInsert состояние добавления новой записи;
dsSetKey состояние поиска записи; по окончании поиска НД переходит в состояние dsBrowse;
dsCalcFields состояние расчета вычисляемых полей; по окончании расчета НД переходит в состояние, которое имело место до перехода в dsCalcFields; в этом состоянии могут изменяться только вычисляемые поля;
dsFilter состояние фильтрации: обработчик OnFilterRecord проверяет, удовлетворяет ли текущая запись условиям фильтрации; по окончании НД переходит в состояние dsBrowse.
Основные приемы перехода между состояниями:
dsInactive → dsBrowse
Метод Open (Например: LicaT.Open; - открыть таблицу лиц);
Свойство Active (LicaT.Active := true;- эквивалентно предыдущему)
dsBrowse → dsInactive
Метод Close (LicaT.Close; - закрыть таблицу лиц);
Свойство Active (LicaT.Active := false;).
Замечание: если в момент закрытия набор данных находится в состоянии dsEdit или dsInsert, то внесенные изменения будут утрачены. В частности, если редактирование допускается непосредственно в TDBGrid, то перед закрытием НД следует проверить – не находится ли он в состоянии редактирования, чтобы пользователь не потерял последние исправления.
dsBrowse → dsEdit
Метод Edit (LicaT.Edit; - перейти в режим редактирования текущей записи таблицы лиц).
Замечание: метод Edit может вызываться не явно. Например, при редактировании в TDBGrid.
dsEdit → dsBrowse
Метод Post (LicaT.Post; - подтверждение изменений, внесенных в текущую запись таблицы лиц);
Метод Canсel (LicaT.Cancel; - отмена изменений).
Замечание: эти методы также могут вызываться неявно. Например, при переходе между строками в TDBGrid или при нажатии клавиши Esc.
dsBrowse → dsInsert
Метод Insert (LicaT.Insert; - вставка новой записи после текущей);
Метод Append (LicaT.Append; - вставка новой записи в конец НД).
Замечание: методы могут вызываться неявно.
dsInsert→ dsBrowse
Метод Post (подтверждение изменений в текущей записи);
Метод Cancel (отмена изменений).
Как отмечалось выше, переходы между состояниями НД могут вызываться неявно. Поэтому для выяснения текущего состояния набора данных может понадобиться метод State, который возвращает информацию о состоянии НД в виде констант: dsInactive, dsBrowse, ...
Например, перед началом выполнения каких-либо действий в НД следует проверить, открыт ли он:
if not LicaT.Active then LicaT.Open;
поскольку попытка выполнения действий в закрытом НД повлечет ошибку.
Перед закрытием формы с возможностью редактирования в TDBGrid следует проверить, не находится ли НД в состоянии редактирования:
if LicaT.State in [dsEdit, dsInsert] then LicaT.Post;
Фильтрация в наборах данных.
Фильтрация это отображение в НД только тех записей, которые удовлетворяют определенному условию (фильтру).
Для осуществления фильтрации в TDataSet используются свойства: Filter, FilterOptions, Filtered и событие OnFilterRecord.
В свойстве Filterуказывается условие фильтрации в виде строки SQL-подобного синтаксиса. В этой строке могут использоваться только имена полей, литералы (явно заданные значения), операторы отношения (>, <, <=, =>,<> ), а также логические операторы (OR, AND, NOT). Переменные, объявленные в программе, здесь использоватьнельзя.
Например, для показа только тех проводок, в которых передающим было лицо с условным номером 1, а принимающим – с номером 3, фильтр следует задать следующим образом:
DM.ProvodkiT.Filter := ’([Rashod]=1) AND ([Prihod]=3)’;
Свойство FilterOptionsустанавливает режимы выполнения фильтрации для условия Filter (и только для него). Можно указать два режима:
foCaseInsensitiveигнорирование регистра букв;
foNoPartialCompareпоиск по точному соответствию. Если этот режим выключен (foNoPartialCompare = False), то в фильтре можно использовать символ ‘*’ для указания произвольного числа любых символов. Например, для выбора всех лиц, наименование которых начинается с «Ив», «ИВ», «ив», следует задать фильтр:
DM.LicoTb.Filter:=’[Name]=”ИВ*”’;
с включенной опцией foCaseInsensitive и выключенной foNoPartialCompare.
Значительно большие возможности фильтрации представляет обработчик события OnFilterRecord. Его процедура имеет два параметра: имя фильтруемого НД и параметр Accept. В отфильтрованный НД включаются только те записи, для которых в теле процедуры параметр Accept будет установлен вTrue. Приведенный выше пример можно переписать следующим образом:
procedure DM.ProvodkiT.FilterRecord(DataSet: TDataSet;
var Accept: Boolean);
begin
Accept := (DataSet[‘Rashod’]=1) AND
(DataSet[‘Prihod’]=3);
end;
Следует отметить, что обработчик OnFilterRecord представляет более гибкие возможности для фильтрации НД, чем свойство Filter. В частности, в нем можно использовать и программные переменные.
Свойство Filteredиспользуется для включения/выключения фильтрации. Причем это касается фильтрации, заданной как в свойстве Filter, так и в обработчике OnFilterRecord.
Замечание 1. Фильтры в свойстве Filter и обработчике OnFilterRecord могут использоваться одновременно. Соответственно, в отфильтрованный НД будут включаться записи, удовлетворяющие обоим условиям фильтрации.
Замечание 2. В условия фильтрации могут включаться любые поля, в том числе и те, по которым индексы не строились. Как следствие, фильтрация может потребовать полного перебора всех записей НД. Поэтому использовать в фильтрах неиндексированные поля для больших НД следует с осторожностью, чтобы не замедлить работу с БД.
Замечание 3. Возможно последовательное перемещение по записям, удовлетворяющим условиям фильтрации, и при выключенной фильтрации (Filtered = False). Для этого используются методы:
FindFirst –найти первую запись, удовлетворяющую условиям фильтрации;
FindNext– найти следующую запись, удовлетворяющую условиям фильтрации;
FindPrior– предыдущую запись;
FindLast– последнюю запись.
Эти методы возвращают True, если соответствующая запись найдена.
Несмотря на то, что ищутся записи, удовлетворяющие фильтру, НД отображается полностью в неотфильтрованном виде. По сути, в процессе применения указанных методов НД кратковременно переводится в отфильтрованное состояние. Поэтому использовать эти методы для больших НД также не рекомендуется (см. замечание 2).
Поиск в наборах данных.
Метод Locateищет первую запись, имеющую искомые значения полей. Если такая запись найдена, то делает ее текущей и возвращает True, иначе False. Метод определяется следующим образом:
function Locate(const KeyFields: string;
const KeyValues: Variant;
Options: TLocateOptions): Boolean;
Параметр KeyFields содержит список имен полей, по которым производится поиск. Имена в списке разделяются точкой с запятой.
Параметр KeyValues вариантный массив, который содержит искомые значения. Первое значение для первого поля из списка KeyFields, второе – для второго и т.д.
Параметр Options указывает условия поиска:
loCaseInsensitive игнорирование регистра букв;
loPatrtialKey поиск по частичному соответствию, то есть могут быть заданы только начальные символы значения (здесь символ ‘*’ не используется).
Примеры. Найти в таблице наличия запись, в которой содержится количество предметов с условным номером 25 у лица с условным номером 2:
DM.NalichieT.Locate(‘Lico;Predmet’,
VarArrayOf([2,25]),[]);
Найти в таблице лиц первое лицо, наименование которого начинается с символов, содержащихся в строковой переменной NameLic:
var NameLic: string;
. . .
NameLic := ‘ИВ’;
. . .
DM.LicaT.Locate(‘Name’, NameLic, [loCaseInsensitive,
loPatrtialKey]);
Замечание 1. Поиск возможен по любым полям, в том числе и по неиндексированным. Если индексы есть, то они используются. Если есть несколько индексов по полям поиска, то предсказать какой из них будет использован нельзя. Поэтому, если искомое значение содержится в нескольких записях, то предсказать какая из записей будет найдена первой нельзя. При отсутствии индексов метод работает медленно, поскольку выполняет последовательный перебор записей.
Замечание 2. Иногда после обработки искомой записи возникает необходимость возврата к записи, которая была текущей до начала поиска. Для этого могут использоваться так называемые «закладки» TBookMark, в отношении которых применимы следующие методы:
function GetBookMark: TBookMark; создает закладку для текущей записи;
procedure GotoBookMark (BookMark: TBookMark); перемещает курсор на запись, помеченную закладкой;
procedure FreeBookMark (BookMark: TBookMark); освобождает ресурсы, назначенные закладке;
function BookMarkValid (BookMark: TBookMark): Boolean;возвращаетTrue, если закладка указывает на некоторую запись.
Метод Lookupтакже как и методLocateищет первую запись, удовлетворяющую критериям поиска, но не делает ее текущей, а возвращает значения некоторых ее полей. Поиск производится только на точное совпадение (режимовOptionsздесь нет).
Метод определяется следующим образом:
function Lookup (const KeyFields: string;
const KeyValues: Variant;
const ResultFields: string): Variant;
Назначение параметров KeyFields и KeyValuesто же, что и дляLocate. Параметр ResultFields содержат список имен полей, значения которых должны быть возвращены.
Вид результата зависит от количества возвращаемых полей. Если поле одно, то возвращается его значение или NULL (если полю не присвоено никакого значения). Если полей несколько, то результатом будет вариантный массив, содержащий значения (или NULL для полей, значения которым не присвоены). Если запись не будет найдена, то тип результата (varType) будет varNULL; если поиск по каким-либо причинам не был произведен, то тип результата будет varEmpty.
Замечание. Использованная в примере функцияVarIsArray возвращаетTrue, если переменная типа Variant является массивом.
Построение отчетов в базах данных.
Важнейшим требованием к любому приложению баз данных является возможность формирования разнообразных отчетов и представления сводной информации по имеющимся данным.
С этими целями используются различные генераторы отчетов. В частности, при написании приложений баз данных в Delphi можно использовать генератор отчетов QuickReport, входящий в дистрибутив Delphi. Его компоненты расположены на страничке QReport.
TQuickRep определяет поведение и характеристики отчета в целом.
Его свойство DataSet указывает на набор данных, по которому создается отчет. Обычно для отчета используется один НД. Если же необходимо вывести информацию из нескольких связанных наборов данных, то можно использовать компонент TQuery для задания соответствующего SQL-запроса, или использовать наборы данных, которые находятся в отношении Master-Detail.
Свойство Page задает параметры страницы;
PrinterSetting настройки принтера;
Frame рамки страницы.
В свойстве Options можно указать – следует ли печатать шапку на первой странице и подвал на последней.
В свойстве PrintIfEmpty печатать ли отчет, если соответ-ствующий НД пуст.
Основным методом TQuickRep является метод Preview, который обеспечивает вывод окна предварительного просмотра отчета при выполнении программы (не следует путать с Preview в процессе проектирования отчета). В этом окне есть инструменты для установки параметров принтера и печати отчета или вывода его в файл. Обычно этим методом в программе инициируется генерация отчета. Например, если подготовка отчета должна происходить по нажатию некоторой кнопки, то в обработчике OnClick этой кнопки следует записать:
QuickRep1.Preview; // где QuickRep1 – имя компонента TQuickRep
Среди событий, связанных с TQuickRep, наибольший интерес представляют следующие:
BeforPrint наступает при подготовке отчета до вывода окна предварительного просмотра;
AfterPrint после печати;
OnStartPage при генерации первой страницы;
OnEndPage при генерации последней страницы.
Назначение, расположение и поведение этого компонента определяется свойством BandType:
rbTitle заголовок всего отчета: выводится на первой странице после ее шапки;
rbSummary подвал всего отчета: выводится на последней странице после всего отчета, но до подвала последней страницы;
rbGroupHeader шапка группы: используется при группировке информации в отчете и выводится в начале каждой группы;
rbGroupFooter подвал группы: выводится в конце группы;
rbPageHeader – шапка страницы: выводится вверху каждой страницы;
rbPageFooter – подвал страницы: выводится внизу каждой страницы;
rbColumnHeader заголовок столбцов: выводится на каждой странице после ее шапки;
rbDetail основной элемент, в котором печатается детальная информация по каждой записи НД;
Для вывода вспомогательной и системной информации используется компонент TQRSysData. Вид выводимой информации определяется значением его свойства Data:
qrsDate текущая дата;
qrsTime текущее время;
qrsDateTime текущая дата и время;
qrsPageNumber номер страницы;
qrsDetailNo номер текущей записи НД;
qrsDetailCount число записей в НД.
DDL Firebird/InterBase.
Для создания БД используется оператор CREATE DATABASE, который имеет следующий формат:
CREATE DATABASE "имя файла"
[USER "имя пользователя" [PASSWORD "пароль"]]
[PAGE_SIZE [=] целое]
[DEFAULT CHARACTER SET набор символов];
Может быть опущена любая составляющая оператора, за исключением имени файла.
СУБД размещает всю базу данных (таблицы, индексы, системную информацию и т.д.) в едином файле, разбитом на страницы. Возможно использование нескольких файлов, в том числе и на разных носителях, но все равно они будут рассматриваться как единый файл. В качестве расширения для имени файла БД InterBaseобычно используются символыgdb, а дляFireBird–fdb.
Имя пользователя и пароль определяют лишь пользователя, создавшего БД, но не назначают права доступа к ней. В дальнейшем БД может быть удалена только её создателем или администратором.
Параметр PAGE_SIZEопределяет размер страницы БД в байтах: 1024, 2048, 4096, 8192 или 16384 байт. Все операции записи и чтения производятся постранично. Обычно рекомендуется делать размер страницы равным размеру кластера. Увеличение страницы может ускорять доступ к данным за счет уменьшения глубины индексов. Но с другой стороны, страница всегда читается и записывается целиком, и при малых размерах записей будет перемещаться много лишней информации.
Параметр DEFAULTCHARACTERSETуказывает национальную кодировку символов для символьных данных. Для русскоязычных данных подWindowsследует использоватьWIN1251. Национальный набор символов может быть изменен при определении конкретных столбцов.
Замечание. Здесь определяется кодировка символов, но нельзя определить порядок сортировки символьной
Типы данных и таблицы в Firebird/InterBase.
В InterBase/FireBirdопределены следующие основные типы данных:
Типы NUMERIC и DECIMALочень похожи и отличаются небольшими деталями реализации и хранения. Они, в известной степени, виртуальны, поскольку реально для хранения их значений в базе данных используются столбцы типовSMALLINT, INTEGER, BIGINTиDOUBLE PRECISION, в зависимости от количества значащих цифр.
Отличие CHARотVARCHARсостоит в том, что при записиCHARудаляются хвостовые пробелы, а при чтении строка дополняется пробелами до своей длины.VARCHARпишется и читается как есть, без удаления и добавления пробелов. Обычно рекомендуется использоватьVARCHAR.
Тип TIMESTAMPполностью совместим с типомTDataTimeвDelphi.
Если присвоение значения даты производится с помощью операторов SQL, можно использовать стандартный формат даты: DD-MMM-YYYY (например, ’25-OCT-2002’ ). В операторахSQLдопустимо присвоение значения типа DATE символьной переменной. При этом дата будет преобразована в стандартный формат.
В SQLмогут быть также использованы литералы‘NOW’(возвращает текущую дату и время сервера) и‘TODAY’(возвращает текущую дату без времени).
Столбцы типа BLOB(BinaryLargeObject) рассматривается, как последовательность байтов, интерпретация которой возлагается на приложение. Например, в них можно хранить графическую или звуковую информацию.
Замечание1.В процессе присвоения значений переменных одного типа переменным другого типа в SQL-операторах допускается неявное преобразование типов (например, 2 + ‘1’ даст 3). Однако если преобразование окажется невозможным, то будет возвращена ошибка.
Замечание2.ВInterBase/FireBirdнет логического типа данных. Его можно реализовать, например, с помощьюCHAR(1) со значениями "T" и "F" или INTEGER со значениями 1 и 0.
3.2.2.Создание таблиц
Если при определении столбцов предполагается использовать домены, то они должны быть заданы заранее.
Таблицы создаются оператором CREATE TABLEследующего формата:
CREATE TABLE имя_таблицы
(<определение столбца>[,<определение столбца>|,<ограничение таблицы>...]);
где:
<определение столбца> = имя_столбца {тип данных| COMPUTED BY | домен}
DEFAULT {литерал | NULL | USER}]
[NOT NULL]
[CHECK (<ограничение столбца>)]
[COLLATE порядок_сортировки]
<ограничение таблицы>- список ограничений уровня таблицы. Чаще всего здесь задаютсяограничения ссылочной целостности.
Тип столбца может быть определен через тип данных, домен или как вычисляемый (COMPUTEDBY). Тип вычисляемого столбца определяется типом результирующего выражения.
Предложения DEFAULT,NOTNULL,COLLATEимеют тот же смысл, что и при определении домена.
Ограничения уровня столбца, задаваемые в предложении CHEK, имеют гораздо более широкие возможности, чем при определении домена. В них можно ссылаться на другие столбцы, использовать операторы выбора из других таблиц, использовать функцииSUM,MIN,MAX, … и многое другое.
Замечание. Допустимо объявление столбцов, как массивов, однако возможности работы с этими массивами весьма ограничены.
Способы реализации ограничений в Firebird/InterBase.
Ограничения ссылочной целостности обычно задаются при создании таблиц, но могут быть добавлены или изменены позднее.
Для задания первичного ключа используется предложение:
PRIMARY KEY (столбец1[,столбец2...])
Все столбцы, входящие в первичный ключ, должны быть объявлены как NOT NULL. Естественно, что в таблице может быть только одно ограничение первичного ключа. Если же необходимо обеспечить уникальность какой-либо другой комбинации полей (альтернативных ключей), то используется предложение UNIQUE аналогичного формата.
Внешний ключ задается предложением следующего вида:
FOREIGN KEY (список столбцов ВК)
REFERENCES имя_родит.табл. [(список столбцов ПК)]
[ON UPDATE действие] [ON DELETE действие]
Столбцы, входящие во внешний ключ по своим характеристикам должны полностью совпадать со столбцами первичного ключа. Возможна ссылка не только на первичный ключ, но и на альтернативный (UNIQUE; в этом случае список столбцов рекомендуется указывать).
Предложения ONUPDATEи ONDELETEопределяют действия СУБД в случае попытки изменения или удаления записи в родительской таблице. Возможные варианты действий:
NOACTION– при наличии в дочерней таблице записей, ссылающихся на запись родительской таблицы, операция запрещается (по умолчанию);
CASCADE– выполняется каскадное изменение или удаление записей дочерней таблицы;
SETDEFAULT– полям внешнего ключа присваиваются значения по умолчанию. В родительской таблице должны присутствовать записи с соответствующими значениями;
SETNULL– поля внешнего ключа устанавливаются в NULL.
Если в таблице объявлен внешний ключ, то в нее нельзя будет добавить запись в полях внешнего ключа которой будут значения, отсутствующие в полях первичного ключа родительской таблицы.
Замечание. Рекомендуется присваивать ограничениям имена, которые будут использоваться СУБД в своих сообщениях о нарушении ограничений. Эти имена удобно использовать и при необходимости удаления ограничений. Имя ограничения задается с помощью предложения CONSTRAINT:
CONSTRAINT FK_Nalichie_Lica
FOREIGN KEY (Lico) REFERENCES Lica(NLic)
ON UPDATE CASCADE ON DELETE NO ACTION
здесь FK_Nalichie_Lica– имя ограничения.
Если ограничению не было присвоено имя в явной форме, то оно будет сгенерировано системой автоматически. Имена всех ограничений хранятся в системной таблице RDB$RELATION_CONSTRAINTS.
Ключи и индексы в Firebird/InterBase.
Индексы в БД используются в двух целях:
обеспечение поддержания ссылочной целостности (индексы по первичным, внешним и альтернативным ключам);
повышение скорости поиска и сортировки данных.
Построение индексов для реализации первой цели происходит практически не зависимо от воли разработчика; СУБД просто создает индексы по определениям всех ключей. А вот реализация второй цели полностью зависит от разработчика БД и здесь имеется одна проблема, требующая компромиссных решений.
Дело в том, что повышение скорости поиска и сортировки с использованием индексов приводит, с другой стороны, к увеличению объема БД и снижению скорости изменения информации, хранящейся в ней, поскольку изменение содержимого индексируемых столбцов требует изменения индексов. Поэтому при создании индексов обычно исходят из следующих компромиссных соображений:
Индексы рекомендуется создавать по столбцам, для которых:
часто производится поиск в БД (столбцы часто перечисляются в предложении WHEREоператораSELECT);
часто строится объединение таблиц в операторе SELECT;
часто производится сортировка (предложение ORDERBYоператораSELECT).
Не рекомендуется создавать индексы по столбцам, которые:
редко используются для поиска, объединения и сортировки;
часто меняют значение, что приводит к необходимости часто изменять индекс;
содержат небольшое число вариантов значений (например, ‘T’ и ‘F’).
Замечание 1.Если часто используется поиск или сортировка по нескольким столбцам таблицы, то целесообразно создать общий индекс по этим столбцам (например,R1,R2,R3,R4). Этот же индекс будет использоваться и для поиска по любому подмножеству столбцов следующих подряд, начиная с ведущего (например,R1,R2 илиR1,R2,R3; но неR2,R3 илиR1,R3). Однако этот индекс не будет использоваться для поиска по столбцам, следующим в обратном порядке (R2,R1).
Замечание 2.При частом использовании в предложенииWHEREпоиска по нескольким столбцам, объединенным операторомOR, например:
WHERE R1=значение_1 OR R2= значение_2 OR R3= значение_3
лучше создать отдельные индексы по столбцам R1,R2 иR3, поскольку составной индекс по этим столбцам будет в данном случае использоваться только для поиска по столбцуR1.
Индексы создаются с помощью оператора вида:
CREATE [UNIQUE] [ASC|DESC] INDEX имя_индекса
ON имя_таблицы (столбец1[,столбец2...]);
где слово UNIQUEозначает уникальный индекс;
ASC– индекс в порядке возрастания значений (по умолчанию);
DESC– индекс в порядке убывания значений.
Удаление индекса выполняется оператором вида:
DROP INDEX имя_индекса;
Нельзя удалить индекс, который используется в данный момент времени другими пользователями для выполнения запросов. Нельзя удалить индекс, созданный по определению ключей. В этом случае следует использовать оператор ALTERTABLEдля удаления соответствующего ограничения.
Всякое изменение в таблице (удаление или добавление записи, изменение значений индексных полей) должно, по идее, влечь за собой перестроение индекса. Однако этот процесс может потребовать значительного времени, и поэтому в СУБД используются другие приемы, которые позволяют отражать изменения в индексе без его полной перестройки. Но эти приемы по мере накопления изменений приводят к изменению структуры индекса, увеличению его глубины (максимальное число обращений к индексу для поиска нужной записи). Если изменений в таблице очень много, то глубина индекса может стать неприемлемо большой и его использование для поиска и сортировки станет нецелесообразным. Поэтому иногда, по мере накопления изменений, необходимо полностью перестраивать индекс. Для этого используется пара операторов:
ALTERINDEXимя_индексаINACTIVE; - деактивирует индекс;
ALTERINDEXимя_индексаACTIVE; - перестраивает индекс и активирует его.
Нельзя деактивировать используемый в данный момент времени индекс, а так же индекс, построенный по определению ключей.
Замечание 1.С теми же целями можно использовать пару операторовDROPINDEXиCREATEINDEX.
Замечание 2.Полное перестроение индексов выполняется и при восстановлении БД из резервной копии.
Замечание 3.Рекомендуется отключать индексы на время внесения массовых изменений в таблицы, например при добавлении множества новых записей.
Оптимизатор запросов при поступлении каждого нового запроса принимает решение о том, какие индексы следует использовать для их быстрейшего выполнения. Решение принимается на основе так называемого показателя полезности индекса. При частом внесении изменений в таблицы показатель полезности может перестать соответствовать действительному положению дел в БД и поэтому его следует периодически пересчитывать с помощью оператора:
SET STATISTICS INDEX имя_индекса;
Замечание.SETSTATISTICSне перестраивает индекс, а лишь пересчитывает показатель его полезности, тем самым облегчая оптимизатору запросов правильный выбор индексов.
Оператор SELECT.
Оператор SELECTявляется самым важным и самым используемым оператором языкаSQL. Утверждение «языкSQL– это операторSELECT» недалеко от истины, посколькуSQL– это язык запросов, а операторSELECTи является средством формулирования запросов.
Именно этот оператор демонстрирует отличия локальных и серверных БД. В локальной БД извлечение любой информации требует детального знания структуры БД и подробного описания алгоритма получения необходимой информации. В серверных же БД с помощью оператора SELECTформулируется запрос кSQL-серверу о том, какая информация должна быть получена. А каким образом эта информация будет получена, какие алгоритмы ее извлечения будут использованы и как они связаны со структурой БД – все это заботаSQL-сервера, его внутренняя работа, скрытая от клиента.
Вообще, локальные базы данных ориентированы на работу с отдельными записями и имеют соответствующие средства навигации (перемещения) по наборам данных для перехода к конкретной записи. Серверные БД ориентированы на работу с множествами записей, удовлетворяющих некоторым требованиям выборки, и имеют средства для указания (выбора) этого множества.
Одним из следствий такого подхода является отсутствие в серверных БД возможности свободной навигации по наборам данных. Так, например, нет другой возможности перейти на произвольную запись НД, как только перебором всех предыдущих записей (имеется ввиду именно перемещение по НД, хотя выбрать нужную запись не составит труда, если указать ее уникальные идентифицирующие признаки). Более того, обычно возможно движение по НД только от начала к концу, но не наоборот. Для реализации возможности произвольного двунаправленного движения необходимо обеспечить буферизацию данных на локальном рабочем месте.
Итак, вся работа в серверных БД ориентирована на действия с некоторыми множествами записей, а средством указания этих множеств является оператор SELECT.
Простейшая форма оператора SELECT
SELECT {* | <значение 1>[,<значение 2>,...]}
FROM <таблица 1>[,<таблица 2>,...];
где <значение 1>, <значение 2>, ... – обычно имена столбцов;
<таблица 1>, <таблица 2>, ... – имена таблиц.
Приведенный оператор извлекает значения указанных столбцов из всех строк указанных таблиц. Если из таблицы необходимо извлечь значения всех столбцов, то вместо перечисления их имен можно использовать символ ‘*’.
Например, для извлечения всего содержимого таблицы лиц:
SELECT * FROM Lica;
что эквивалентно:
SELECT Nlic, Name, Tip, Podr FROM Lica;
Предложение WHERE
Обычно из таблиц извлекают не все строки, а только те из них, которые удовлетворяют определенному условию поиска. С этой целью в оператор SELECTдобавляется предложение вида:
WHERE <условие поиска>
где в наиболее простом случае условие поиска имеет вид:
<условие поиска> = <имя столбца><оператор>константа
где <оператор>={<|>|<+|>+|!<|!>|=|<>|!=}, а константа может быть строковым или числовым значением.
Например: извлечь из таблицы наличия все строки, касающиеся предмета с условным номером 3:
SELECT * FROM Nalichie WHERE Predmet=3;
Для задания более сложных условий поиска можно использовать логические операторы: AND,OR,NOT.
Замечание. Всегда следует помнить о важном отличии использования логических операторов вSQLот использования их в других языках программирования:в SQL наивысший приоритет имеют операции сравнения. Поэтому сначала выполняются операторы сравнения, а потом уже логические. Такая особенностьSQLизбавляет от необходимости использования множества скобок.
Например: извлечь из таблицы наличия строку, касающуюся наличия у лица с условным номером 5 предмета с условным номером 12:
SELECT * FROM Nalichie WHERE Lico=5 AND Predmet=12;
Как видите, здесь нет необходимости в скобках.
Если необходимо проверить наличие значения (NOTNULL) для некоторого столбца, то используется конструкция вида:
<имя столбца> IS [NOT] NULL
Например, дать список всех подотчетных лиц (для них указывается подразделение):
SELECT * FROM Lica WHERE Podr IS NOT NULL;
Внутренние и внешние соединения таблиц.
Внутреннее соединение таблиц
В условии поиска может сравниваться значение столбца из одной таблицы со значением столбца из другой таблицы:
<имя столбца таблицы1> <оператор> <имя столбца таблицы2>
Такие условия часто используются для реализации механизма, аналогичного Lookup-полям локальных БД.
Например, извлечь информацию из таблицы лиц, с указанием реальных наименований типов лиц и подразделений, а не их условных номеров:
SELECT Lica.Name, Tipy.Name, Podrazd.Name
FROM Lica, Tipy, Podrazd
WHERE Tipy.NTip=Lica.Tip AND Lica.Podr=Podrazd.NPodr;
В соответствии с этим оператором, для каждой строки из таблицы лиц будет найдена строка с таким же условным номером типа лица в таблице типов лиц и строка с таким же условным номером подразделения в таблице подразделений. В результирующий НД будут включены не условные номера типов и подразделений, а их реальные наименования (при необходимости можно включить и условные номера).
Обратите внимание, что в предложении WHEREперечисляются все таблицы, участвующие в выборке, а ссылка на столбцы разных таблиц осуществляется путем включения в имя столбца префикса в виде имени его таблицы.
Такой способ объединения информации из разных таблиц получил название внутреннего соединения таблиц.
Замечание:Для внутреннего соединения порядок перечисления таблиц в условии поиска не имеет значения (не важно, столбец какой из таблиц упоминается слева, а какой – справа от знака равенства).
Логически внутреннее соединение таблиц выполняется следующим образом. Вначале строится полное декартово произведение перечисленных таблиц, то есть перебираются все возможные комбинации строк этих таблиц:
строка1 таблицы1, строка1 таблицы2, строка1 таблицы3
строка1 таблицы1, строка1 таблицы2, строка2 таблицы3
строка1 таблицы1, строка1 таблицы2, строка3 таблицы3
. . .
строка1 таблицы1, строка2 таблицы2, строка1 таблицы3
строка1 таблицы1, строка2 таблицы2, строка2 таблицы3
. . .
строка2 таблицы1, строка1 таблицы2, строка1 таблицы3
строка2 таблицы1, строка1 таблицы2, строка2 таблицы3
строка2 таблицы1, строка1 таблицы2, строка3 таблицы3
. . .
Затем из полученного (вероятно очень большого) НД выбираются строки, удовлетворяющие условиям поиска. (Фактически, в целях минимизации работы, SQL-сервер работает несколько иначе, но логически – процесс выглядит именно так.)
Например, пусть таблицы T1 иT2 имеют столбцыC1,C2,C3 иC1,C2, соответственно. И пустьT2 является родительской по отношению кT1, причем связаны они по значению столбцовT2.C1 иT1.C2:
Таблица T2
|
C1 |
C2 |
|
1 |
x |
|
2 |
y |
|
3 |
z |
Тогда выполнение оператора:
SELECT T1.C1, T2.C2, T1.C3 FROM T1, T2 WHERE T1.C2=T2.C1;
приведет к построению следующего декартова произведения:
Замечание 1.При внутреннем соединении таблиц, в результирующий НД не включаются записи, для которых нет соответствия в парной таблице (в рассмотренном выше примере выборки из таблицы лиц с реальными наименованиями подразделений и типов в результирующий НД не включены поставщики и направления списания, так как для них нет соответствия в таблице подразделений). Если такие записи необходимо включить (например, для включения в выборку лиц поставщиков и направлений списания), следует использовать внешнее соединение таблиц (оно будет рассмотрено ниже).
Замечание 2.Рассмотренную в этом пункте форму записи внутреннего соединения таблиц называют неявной формой внутреннего соединения. Альтернативная явная форма предполагает использование предложенияJOIN…ONдля каждой присоединяемой таблицы. В этом случае приведенный выше пример будет выглядеть следующим образом:
SELECT Lica.Name, Tipy.Name, Podrazd.Name
FROM Lica
JOIN Tipy ON Tipy.NTip=Lica.Tip
JOIN Podrazd ON Lica.Podr=Podrazd.NPodr;
Рекомендуется использовать такую форму записи, поскольку она более информативна и позволяет четко разграничивать условия соединения таблиц (в предложениях JOINпосле ключевого словаON) от условий выбора строк (в предложенииWHERE).
Внешние соединения таблиц
Выше было рассмотрено внутреннее соединение таблиц, при котором строится полное декартово произведение этих таблиц, из него отбираются записи, удовлетворяющие условию соединения, и в результирующий набор данных не включаются строки, не имеющие соответствия в парной таблице. Поэтому, например, если попытаться построить список всех лиц с указанием подразделений для подотчетных лиц:
SELECT L.Name, D.Name
FROM Lica L
JOIN Podrazd D ON D.NPodr=L.Podr;
то в результирующий набор не будут включены поставщики и направления списания, так как для них не указываются подразделения.
В таких случаях следует использовать внешние соединения таблиц, при которых в результирующий набор данных включаются и те записи ведущей таблицы, которым нет соответствия в ведомой таблице. Какая таблица является ведущей, определяется видом соединения:
SELECT <список столбцов>
FROM <таблица_1>
<вид_соединения> JOIN <таблица_2> ON <условие_поиска>;
где в качестве вида соединения может быть указано:
LEFT левое внешнее соединение (ведущей является таблица_1);
RIGHT правое внешнее соединение (ведущей является таблица_2).
Предложение ON используется, так же как и предложение WHERE для внутреннего соединения.
Приведенный выше пример может быть реализован с помощью следующего внешнего соединения:
SELECT L.Name, D.Name
FROM Lico L
LEFT JOIN Podrazd D ON D.NPodr=L.Podr;
Вложенные запросы.
При необходимости операторы SELECT могут быть вложенными. Например, дать информацию о наиболее дорогостоящем предмете:
SELECT Name, Cena FROM Predmety
WHERE Cena=(SELECT MAX(Cena) FROM Predmety);
Здесь необходим вложенный SELECT, так как в предложении WHERE нельзя использовать агрегатную функцию.
Замечание. Если вложенный запрос используется в сравнении со знаком равенства, то необходимо следить, чтобы он возвращал единственное значение (в противном случае будет сгенерирована ошибка). Если же нет уверенности в том, что будет возвращено единственное значение, то вместо знака равенства следует использовать ключевое слово включения в множество IN. Например, список проводок в отношении самого дорогостоящего предмета (следует учесть, что несколько различных предметов могут иметь одну и ту же максимальную цену):
SELECT * FROM Provodki WHERE Predmet IN (
SELECT NPredm FROM Predmety WHERE Cena=(
SELECT MAX(Cena) FROM Predmety));
Иногда для вложенного запроса важно знать, что существует хотя бы одна соответствующая запись, а количество этих записей не важно. В этом случае используется выражение:
[NOT] EXISTS (<запрос>)
Например, выбрать подотчетных лиц, у которых нет ни одной записи в таблице наличия (пусть условный номер типа лица для подотчетных лиц равен 2):
SELECT Name FROM Lica L WHERE Tip=2 AND NOT EXISTS(
SELECT * FROM Nalichie N WHERE N.Lico=L.NLic);
Если необходимо отобрать записи, для которых вложенный запрос возвращает одну и только одну строку, то используется выражение:
SINGULAR(<запрос>)
Например, выбрать подотчетные лица, у которых имеется единственная запись в таблице наличия:
SELECT Name FROM Lica L WHERE Tip=2 AND SINGULAR(
SELECT * FROM Nalichie N WHERE N.Lico=L.NLic);
В операторе SELECT имеется возможность сравнить значение некоторого выражения со всеми значениями, возвращаемыми вложенным запросом:
<выражение> <оператор> {ALL|SOME|ANY} (<запрос>)
В случае ALL сравнение дает истину, если значение выражения находится в отношении, указываемом оператором, со всеми значениями, возвращенными вложенным запросом. Для SOME (ANY – синоним) достаточно выполнения отношения хотя бы для одного значения, возвращенного вложенным запросом.
Например, выбрать подотчетные лица, у которых нет предметов, с ценой свыше тысячи рублей:
SELECT Name FROM Lica L WHERE 1000 > ALL(
SELECT P.Cena FROM Predmety P, Nalichie N
WHERE N.Lico=L.NLic AND P.NPredm=N.Predmet);
или выбрать лиц, у которых есть предметы с ценой выше 10 000 рублей:
SELECT Name FROM Lica L WHERE 10000 < SOME(
SELECT P.Cena FROM Predmety P, Nalichie N
WHERE N.Lico=L.NLic AND P.NPredm=N.Predmet);
Агрегатные функции и группировка записей.
Предназначены для расчета итоговых значений по набору данных:
COUNT(<выражение>) – подсчитывает количество вхождений значения выражения во все строки результирующего НД;
SUM(<выражение>) – суммирует значения выражения для всех строк;
AVG(<выражение>) – находит среднее значение выражения для всех строк;
MIN(<выражение>) – находит минимальное значение выражения;
MAX(<выражение>) – находит максимальное значение выражения.
Например, число записей в таблице предметов:
SELECT COUNT(*) FROM Predmety;
Число различных предметов, имеющихся на предприятии:
SELECT COUNT(DISTINCT Predmet) FROM Nalichie
WHERE Kolvo>0;
Суммарное наличие у лица с условным номером 3:
SELECT SUM(P.Cena*N.Kolvo) AS Vsego
FROM Nalichie N, Predmety P
WHERE P.NPredm=N.Predmet AND N.Lico=3;
Средняя сумма проводки за Январь месяц:
SELECT AVG(P.Cena*V.Kolvo) AS SrSumma
FROM Provodki V, Predmety P
WHERE P.NPredm=V.Predmet AND
V.Date>=”1-JAN-2012” AND V.Date<=”31-JAN-2012”;
Самая крупная передача предметов от лица с условным номером 1 к лицу с номером 3 за Январь месяц:
SELECT P.Name, V.Date, MAX(P.Cena*V.Kolvo) AS MaxProvodka
FROM Provodki V, Predmety P
WHERE P.NPredm=V.Predmet AND V.Rashod=1 AND V.Prihod=3
AND V.Date>=”1-JAN-2012” AND V.Date<=”31-JAN-2012”;
Иногда возникает необходимость подсчета агрегированных значений (сумма, среднее, минимум …) не по всему набору данных, а по некоторым его группам, характеризуемым одинаковыми значениями определенных полей. Например, суммарное наличие по подотчетным лицам или по подразделениям.
С этой целью в операторе SELECT используется предложение:
GROUP BY столбец_1[, столбец_2...]
Замечание.При использовании предложения GROUP BY один из столбцов результирующего набора данныхобязательнодолжен быть представлен агрегатной функцией.
Например, суммарное наличие по подотчетным лицам:
SELECT L.Name, SUM(N.Kolvo*P.Cena)
FROM Nalichie N, Lica L, Predmety P
WHERE L.NLic=N.Lico AND P.NPredm=N.Predmet
GROUP BY L.Name;
или количество проводок, сгруппированных по предметам и датам:
SELECT P.Name, V.Data, COUNT(V.*)
FROM Provodki V, Predmety P
WHERE P.NPredm=V.Predmet
GROUP BY P.Name, V.Data;
Замечание.В предложенииSELECTмогут присутствовать в чистом виде (т.е. не в качестве аргументов агрегатных функций) только те столбцы, которые присутствуют в предложенииGROUPBY.
Если в результирующий набор данных необходимо включать агрегированное значение не по всем группам, а только по тем из них, которые удовлетворяют некоторому условию, то предложение GROUP BY дополняется предложением:
HAVING <условие_поиска>
где условие_поискаформируется по тем же правилам, что и предложение WHERE, за одним исключением: здесь, в отличие от WHERE, можно использовать агрегатные функции.
Например, список подотчетных лиц, имеющих наличие общей стоимостью менее 1000 руб., с указанием количества наименований, значащихся за ними предметов:
SELECT L.Name, COUNT(N.*)
FROM Nalichie N, Lica L, Predmety P
WHERE L.NLic=N.Lico AND P.NPredm=N.Predmet
AND N.Kolvo>0
GROUP BY L.Name HAVING SUM(N.Kolvo*P.Cena)<1000;
Замечание. В предложении HAVING, также как и в предложенииSELECTмогут использоваться непосредственно только столбцы, перечисленные в GROUP BY, а все остальные столбцы могут упоминаться только в качестве аргументов агрегатных функций.
Модификация наборов данных в SQL.
Операторы добавления, изменения и удаления строк в SQL, как и все другие операторыSQL, ориентированы на работус группами строк, а не с отдельными строками. Поэтому всегда следует уделять особое внимание таким операторам в части ограничения выборки (предложениеWHERE) с тем, чтобы не получить неожиданный результат.
Добавление строк в таблицу осуществляется оператором INSERTследующего формата:
INSERT INTO имя_таблицы[(столбец_1[, столбец_2 ...])]
{VALUES(<значение_1>[, <значение_2> ...]) |
<оператор SELECT>};
Список столбцов указывает столбцы, которым будут присваиваться значения. Если список опущен, то значения будут присваиваться всем столбцам таблицы, причем в том порядке, в котором они создавались.
Замечание.Во избежание недоразумений, список столбцов рекомендуется всегда указывать, поскольку их порядок может изменяться при изменении структуры таблицы.
Значения, присваиваемые столбцам, могут указываться двояко. Они или указываются явно, после ключевого слова VALUES, или формируются с помощью оператораSELECT.
При явном задании значений оператор INSERTимеет вид:
INSERT INTO имя_таблицы[(столбец_1[, столбец_2, ...])]
VALUES(<значение_1>[, <значение_2> ...]);
Этот оператор добавит в таблицу одну строку, в которой значение_1 будет присвоено столбцу_1, значение_2 – столбцу_2 и т.д. Значения должны соответствовать типу столбцов (с учетом возможностей автоматического преобразования).
Например, добавить в таблицу наличия строку для предмета с условным номером 12 у лица с номером 5 и количеством в 100 единиц:
INSERT INTO Nalichie(Lico, Predmet, Kolvo)
VALUES(5, 12, 100);
Если какой-либо столбец отсутствует в списке присвоения, то ему не будет присвоено никакого значения (NULL).
Во второй своей форме (с оператором SELECT)INSERTдобавляет в таблицу столько строк, сколько их будет в НД, возвращенном операторомSELECT. При этом значения присваиваются столбцам в том порядке, в каком они перечислены в оператореINSERTи вSELECT. Например, для копирования всех строк из таблицы проводок в таблицу архива (с той же структурой, что и таблица проводок) можно использовать оператор вида:
INSERT INTO Archive SELECT * FROM Provodki;
Здесь списки столбцов опущены, так как подразумевается полная идентичность структур таблиц. В общем же случае следует указать список столбцов и в INSERTи вSELECT.
Изменение значений столбцов в строках таблицы осуществляется с помощью оператора UPDATEследующего формата:
UPDATE имя_таблицы
SET столбец_1=<значение 1>[, столбец_2=<значение 2> ...]
[WHERE <условие поиска>];
Изменению подвергаются все строки таблицы, удовлетворяющие условию поиска. Будьте внимательны, используя этот оператор! Если опустить предложение WHERE, то будут измененывсе строки таблицы ! Условие поиска вUPDATEзадается так же, как и в оператореSELECT.
Например, деноминация цен в таблице предметов путем деления цены на 1000:
UPDATE Predmety SET Cena=Cena/1000;
Изменить в таблице проводок все даты проводок за 1.01.2012 на 11.01.2012:
UPDATE Provodki SET Data=”11-JAN-2012”
WHERE Data=”1-JAN-2012”;
Удаление строк из таблицы выполняется оператором:
DELETE FROM имя_таблицы [WHERE <условие поиска>];
Обратите внимание, удаляются все строки, удовлетворяющие условию поиска. Если опустить условие поиска, то таблица будет полностью очищена!
Процедурное расширение SQL.
Хранимые процедуры.
Хранимая процедура – это программный модуль, написанный на специальном языке хранимых процедур, и хранящийся в БД как её элемент.
Хранимые процедуры могут использоваться при подготовке данных для отчетов, внесении массовых изменений в БД, для выполнении периодических действий в БД и множества других операций. Вообще, можно сформулировать такое правило: если какое-либо действие может быть выполнено без участия клиента, то его следует реализовать на сервере с помощью хранимой процедуры или триггера.
С некоторой долей условности хранимые процедуры можно разделить на две категории:
процедуры выборатак же, как и операторSELECT, могут возвращать многострочные наборы данных (то есть несколько наборов значений своих выходных параметров);
процедуры действиявозвращают один набор значений своих выходных параметров или вообще ничего не возвращают, а только выполняют некоторые действия в БД.
Создание хранимой процедуры
Выполняется оператором вида:
CREATE PROCEDURE имя_процедуры
[(вх.параметр1 тип_данных[,вх.параметр2 тип_данных...])]
[RETURNS(вых.параметр1 тип_данных[,вых.параметр2
тип_данных...])]
AS <тело процедуры>;
Входные параметры предназначены для передачи в процедуру некоторых значений из точки вызова. Выходные параметры предназначены для возврата результирующих значений.
Обратите внимание на четкое разграничение входных и выходных параметров. В принципе, входные параметры можно изменять в теле процедуры, но это никак не скажется на точке ее вызова.
Тип данных для параметров может быть любым, кроме массивов. И входные и выходные параметры могут отсутствовать.
Тело процедуры имеет формат:
[<объявление локальных переменных>]
BEGIN
<оператор>
[<оператор>...]
END
Операторы в теле процедуры разграничиваются точкой с запятой.
Для написания процедур используется специальный внутренний язык InterBase/FireBird, который называетсяPSQL. Он является процедурным языком и, соответственно, в нем есть операторы управления ходом вычислительного процесса. Этот же язык используется для написания триггеров.
Оператор приостановки SUSPEND
Используется в процедурах выбора для указания момента передачи в вызывающее приложение очередного набора значений выходных параметров.
Когда в процедуре выбора достигается оператор SUSPEND, в вызывающее приложение возвращается набор значений параметров, перечисленных в предложенииRETURNS, и выполнение процедуры приостанавливается до прихода запроса на следующий набор значений.
Замечание: ОператорSUSPEND– характерный признак процедуры выбора.
Пример. Изменим процедуру, приведенную в предыдущем примере, таким образом, чтобы она выдавала количество предметов одного и того же наименования для каждой из возможных цен:
CREATE PROCEDURE KolvoPredmPoCene(Name VARCHAR(30))
RETURNS(Cena DOUBLE PRECISION, Kolvo DOUBLE PRECISION) AS
DECLARE VARIABLE N INTEGER;
BEGIN
FOR SELECT NPredm, Cena FROM Predmety
WHERE UPPER(Name)=:Name INTO :N, :Cena DO
BEGIN
SELECT SUM(Kolvo) FROM Nalichie WHERE Predmet=:N
INTO :Kolvo;
SUSPEND;
END
END
Оператор выхода EXIT
Немедленно прекращает выполнение процедуры и передает управление на последний оператор ENDв процедуре.EXITможет находиться в любом месте, в том числе, и внутри цикла.
Вызов других процедур
Хранимые процедуры в процессе выполнения могут вызывать другие хранимые процедуры.
Допустимы рекурсивные вызовы, при этом для каждого вызова создается отдельный экземпляр процедуры. Максимально допустимая глубина рекурсии – 1000 (ограничена во избежание бесконечной рекурсии), хотя физически ограничение может наступить раньше, ввиду превышения допустимого размера стека.
Формат вызова другой процедуры:
EXECUTE PROCEDURE имя_процедуры
[входной_параметр_1[,входной_параметр_2...]]
[RETURNING_VALUES выходной_параметр_1
[, выходной_параметр_2...]];
Список входных параметров указывает на переменные и/или содержит константы, значения которых будут использованы для передачи в вызывающую процедуру. Список выходных параметров указывает на переменные, которым будут присвоены возвращённые процедурой значения.
Удаление хранимой процедуры осуществляется оператором:
DROP PROCEDURE имя_процедуры;
Изменение процедуры возможно либо с помощью пары операторов: DROP–CREATE, либо с помощью оператораALTERPROCEDURE, имеющего такой же формат, как и операторCREATEPROCEDURE.
Замечание. ОператорALTERPROCEDUREудобно использовать в тех случаях, когда процедуру нельзя удалить из-за взаимосвязи с другими процедурами или триггерами.
Вызов хранимых процедур
Выполнение хранимой процедуры действия инициируется оператором:
EXECUTE PROCEDURE имя_процедуры
[(входной_параметр_1[, входной_параметр_2...])];
Например, рассчитать с помощью приведенной в предыдущих примерах процедуры среднюю стоимость проводок по предмету с условным номером 15:
EXECUTE PROCEDURE AvgProvodka(15);
Триггеры.
Триггер – это процедура, автоматически выполняемая сервером при добавлении, изменении или удалении строки в таблице, с которой триггер связан.
В отличие от хранимых процедур, триггеры не имеют ни входных, ни выходных параметров и их нельзя вызывать непосредственно. Вызов триггера порождается только соответствующим действием в таблице, с которой триггер связан.
Триггеры, так же как и все хранимые процедуры работают в контексте конкретной транзакции. Поэтому откат транзакции, в рамках которой сработал триггер, приведет к отмене и всех изменений, выполненных триггером.
В зависимости от события, к которому привязан триггер, различаются триггеры, вызываемые при:
добавлении строки;
удалении строки;
изменении строки.
В зависимости от времени срабатывания триггеры делятся на:
выполняемые до наступления события;
выполняемые после наступления события
Создание триггера
Выполняется оператором:
CREATE TRIGGER имя_триггера FOR имя_таблицы
[{ACTIVE | INACTIVE}] {BEFORE | AFTER}
{DELETE | INSERT | UPDATE} [POSITION номер]
AS <тело_триггера>;
где имя_таблицыуказывает на таблицу, действия в которой триггер должен отслеживать;
ACTIVE|INACTIVE– определяет активность триггера (триггер можно включать и отключать). По умолчанию считаетсяACTIVE;
DELETE|INSERT|UPDATE– указывает при каком действии в таблице должен срабатывать триггер;
BEFORE|AFTER– указывает: до или после действия должен срабатывать триггер;
POSITION– определяет порядок срабатывания триггеров, если к одному и тому же событию привязано несколько триггеров (номер – целое число в интервале от 0 до 32767). Триггер с меньшим номером срабатывает раньше.
Тело триггера определяется точно также, как и тело хранимой процедуры. Единственным отличием является возможность обращения к значениям столбцов, которые имели место до изменения строки и после её изменения. С этой целью к именам столбцов добавляются префиксы OLDиNEW.
Префикс OLDуказывает на предыдущее или текущее значение столбца в строке, которая изменяется или удаляется. Для добавляемых строк префиксOLDне используется.
Префикс NEWуказывает на новое значение столбца в изменяемой или добавляемой строке. Для удаляемых строк он не используется.
Замечание 1.Префиксы столбцов могут использоваться в любых операторах тела триггера, в том числе и в SELECT.
Замечание 2.Новые значения, присваиваемые столбцам, могут быть изменены только до выполнения операции. То есть, например, если триггер AFTER INSERT попытается изменить значение NEW.имя_столбца, то это действие не будет иметь результата. Кроме того, фактические значения столбцов не изменяются до тех пор, пока не будет закончена операция вставки или изменения строки. Поэтому триггеры, привязанные к одному и тому же событию, не могут видеть изменения вносимые друг другом.
Замечание 3.Если триггер выполняет действие, которое приводит к тому, что он срабатывает снова, то образуется бесконечный цикл. Поэтому необходимо обеспечить, чтобы действия триггера не приводили к его срабатыванию вновь, даже неявным образом. Например, бесконечный цикл будет иметь место, если триггер, срабатывающий по INSERT в некоторой таблице, будет пытаться добавить запись в ту же таблицу.
Замечание 4.В триггерах допускается вызов хранимых процедур, генерация исключительных ситуаций и их обработка.
Изменение и удаление триггера
Для изменения триггера используется оператор ALTERTRIGGER. Этот оператор может изменять:
только заголовок триггера, включая событие, к которому он привязан, и его активность;
только тело триггера;
и тело и заголовок.
По своему формату оператор ALTERTRIGGERполностью совпадает с оператором CREATETRIGGERза одним исключением: в нем отсутствует предложение FOR (то есть триггер, созданный для одной таблицы, нельзя затем перепривязать к другой таблице).
Если оператор ALTERTRIGGERиспользуется для изменения заголовка, то в нем перечисляются только те параметры, которые должны быть изменены. Например, для временного отключения некоторого триггераTr1 следует использовать такой оператор:
ALTER TRIGGER Tr1 INACTIVE;
Если изменяется момент срабатывания триггера (BEFORE,AFTER), то должно быть указано и действие (DELETE,INSERT,UPDATE).
Для изменения только тела триггера в операторе ALTERTRIGGERничего не должно быть между именем триггера и словомAS.
Для удаления триггера используется оператор:
DROP TRIGGER имя_триггера;
Не может быть удален триггер, используемый в текущий момент времени.
Генераторы. Исключительные ситуации. Примеры использования.
В InterBase/FireBirdнет автоинкрементных полей. Вместо них применяются генераторы, которые возвращают уникальные значение целого типа. Для создания генератора используется оператор вида:
CREATE GENERATOR имя_генератора;
Этот оператор создает генератор и устанавливает его начальное значение в ноль. Если необходимо изменить начальное значение для созданного генератора, то используется оператор:
SET GENERATOR имя_генератора TO целое_число;
Для получения уникального значения к генератору обращаются с помощью функции:
GEN_ID (имя_генератора, шаг);
Эта функция возвращает увеличенное на шаг предыдущее значение, выданное генератором. При необходимости можно также использовать отрицательные значения для шага.
Замечание.Не рекомендуется для одного и того же генератора переустанавливать начальное значение или при разных обращениях использовать разный шаг, чтобы исключить вероятность получения неуникальных значений.
Например, для присвоения условных номеров предметам можно использовать следующий генератор:
CREATE GENERATOR PredmetN;
. . .
INSERT INTO Predmety(NPredm, Name, EdIzm, Cena)
VALUES(GEN_ID(PredmetN), ”Бензин АИ-92”, ”л”, 19.50);
Замечание 1. Не существует оператораDROPGENERATOR. Если необходимо удалить генератор из БД, то это следует сделать в системной таблицеRDB$GENERATORS. Там же можно посмотреть всю информацию о созданных генераторах.
Замечание 2. Чаще всего присвоение уникальных значений полям производится в триггерах, вызываемых перед добавлением новой строки. Например, для таблицы предметов можно использовать такой триггер:
CREATE TRIGGER BI_Predmety FOR Predmety
ACTIVE BEFORE INSERT AS
BEGIN
NEW.NPredm=GEN_ID(PredmetN,1);
END
Соответственно, в операторе добавления новой записи значение полю условного номера предмета присваивать не надо, поскольку такое присвоение будет автоматически выполнено в созданном триггере.
Замечание 3. Если присвоение уникальных значений полям желательно выполнять в клиентской части приложения, то для получения этих уникальных значений с сервера можно создать хранимую процедуру вида:
CREATE PROCEDURE Get_PredmetN RETURNS(N Integer) AS
BEGIN
N=GEN_ID(PredmetN,1);
END
и вызывать ее перед добавлением новой строки в таблицу предметов.
Исключительные ситуации (ИС)
Если при выполнении хранимой процедуры происходит ошибка, то генерируется исключительная ситуация.
Исключительные ситуации бывают трех видов:
ошибки SQL– возвращают номер ошибкиSQLCODE;
ошибки InterBase/FireBird– возвращают номер ошибкиGDSCODE;
исключительные ситуации, определенные пользователем.
Исключительные ситуации, определенные пользователем, являются таким же элементом БД, как и сами хранимые процедуры. Поэтому перед использованием они должны быть определены в БД с помощью оператора:
CREATE EXCEPTION имя_исключит_ситуации ’<сообщение>’;
Сообщение возвращается в приложение в случае наступления исключительной ситуации.
После того, как исключительная ситуация определена, она может быть инициирована в процедуре или триггере с помощью оператора:
EXCEPTION имя_исключит_ситуации;
Например:
. . .
CREATE EXCEPTION KolvoLessZero ’Количество меньше нуля’;
. . .
IF (Kolvo < 0) THEN EXCEPTION KolvoLessZero;
. . .
Удаление исключительной ситуации из БД выполняется оператором:
DROP EXCEPTION имя_исключит_ситуации;
изменение:
ALTER EXCEPTION имя_исключит_ситуации ’<сообщение>’;
Если исключительная ситуация не обрабатывается в процедуре (для такой обработки используется специальный оператор WHEN), то при её наступлении выполнение процедуры прекращается, все выполненные в ней действия отменяются и в вызывающее приложение передается сообщение об ошибке.
Транзакции. Основные свойства и проблемы.
Транзакцией называется группа операций, переводящая базу данных из одного целостного состояния в другое целостное состояние. В случае успешного завершения всех операций, составляющих транзакцию, следует команда подтверждения, в результате которой все изменения, произведенные в ходе транзакции, фиксируются в БД на постоянной основе. Если при выполнении любой операции происходит ошибка или наступает нештатная ситуация, то следует команда отмены и БД откатывается к состоянию, которое имело место на момент старта транзакции.
Поскольку у СУБД отсутствует внутренняя возможность определить – какие операции должны быть объединены в рамках одной транзакции, то эта обязанность возлагается на пользователя. С этой целью в его распоряжение представляются команды вида: STARTTRANSACTION– определяет точку начала транзакции;COMMIT– завершает транзакцию и подтверждает сделанные в ее ходе изменения;ROLLBACK– откатывает транзакцию.
Механизм транзакций столь важен для целостности баз данных, что практически ни одно действие в серверных БД не может быть выполнено иначе, как в рамках какой-либо транзакции. Иногда у пользователя может складываться ложное впечатление, что некоторые действия он выполняет вне контекста транзакций. Оно обусловлено некоторой «самостоятельностью» используемых приложений, которые запускают (а иногда и подтверждают) транзакции без соответствующих запросов к пользователю. Часто, например, автоматическое подтверждение транзакций используется для операторов DDL. Однако на самом деле все действия в БД всегда выполняются в контексте транзакций. Редким исключением здесь является механизм генераторов вInterBase/FireBird, который работает вне контекста транзакций по понятным причинам (подумайте, к каким проблемам привел бы возврат генераторов к предыдущим значениям при откате транзакций).
Для успешной реализации своих функций транзакции должны удовлетворять четырем основным требованиям. В англоязычной литературе для них используется аббревиатура ACID, образованная начальными буквами названий соответствующих свойств.
Атомарность – транзакция представляет собой неделимую единицу работы, которая либо выполняется вся целиком, либо не выполняется вовсе.
Согласованность – транзакция должна переводить БД из одного целостного состояния в другое целостное состояние (имеется ввиду семантическая целостность информации).
Изолированность – транзакции должны выполняться независимо друг от друга, не влияя на результаты друг друга.
Постоянство – результаты успешно завершенной транзакции должны сохраняться в БД на постоянной основе с тем, чтобы никакие последующие сбои и исключительные ситуации не могли повлечь за собой их утрату.
Среди перечисленных требований наиболее сложным, в плане реализации, является обеспечение изолированности, то есть независимости, множества одновременно работающих транзакций. Здесь возникает ряд существенных проблем. Перечислим некоторые из них.
1.Проблема потерянного обновления.Пусть транзакция Т1выполняет снятие 100 руб. со счета, на котором имеется 2000 руб. А транзакция Т2пополняет этот же счет на 500 руб. Предположим, что обе транзакции стартовали практически одновременно и прочитали исходное состояние счета в 2000 руб. Далее транзакция Т2рассчитала новое значение остатка 2000 + 500 = 2500 (руб.) и записала его значение на счет. Тем временем Т1рассчитала свой результат 2000 – 100 = 1900 (руб.) и записала его поверх результата Т2. Таким образом, остаток по счету имеет значение 1900 вместо 2400.
2. Проблема зависимости от нефиксированных результатов.Возникает, когда одна транзакция получает доступ к промежуточным результатам выполнения другой транзакции до того момента, как они были зафиксированы на постоянной основе.
Пусть в тех же условиях, что и в предыдущем примере, Т1начала выполняться раньше Т2и к моменту старта Т2уже записала на счет свой результат 1900, но еще не подтвердила его. Т2считает состояние счета 1900, рассчитает остаток 1900 + 500 = 2400, а тем временем по каким-либо причинам Т1будет отменена и вернет прежнее состояние счета в 1000 руб. Но Т2запишет поверх уже неверный результат 2400.
3. Проблема несогласованной обработки (имеет и другие названия: неповторяемость чтения, чтение мусора, грязное чтение).Пусть транзакция Т1выполняет суммирование остатков на счетах с №1 по №100, а Т2переносит сумму в 1000 руб. со счета №90 на счет №10. Предположим, что Т2стартовала после того, как Т1просчитала сумму остатков на первых 20-ти счетах, и к тому моменту, когда Т1дошла до счета №90 успела забрать с него 1000 руб. и прибавить их к остатку на счете №10. В результате, полученная Т1сумма будет меньше реальной на 1000 руб. Отметим, что здесь в отличие от предыдущего примера проблема имеет место и при нормальном завершении Т2.
Для решения этих и других проблем в СУБД используются механизмы блокировок и уровней изоляции транзакций.
Механизм блокировок
Механизм блокировок позволяет транзакции получить монопольный доступ к используемым ею элементам базы данных. При этом любая другая транзакция сможет получить доступ к тем же элементам только по завершении (успешном или неуспешном) первой транзакции.
Очевидно, что во всех приведенных примерах для решения возникших проблем достаточно было бы Т1установить блокировку на используемые ею счета. Соответственно, Т2получила бы к ним доступ только после завершения Т1. Однако при кажущейся простоте решения проблем возникает ряд существенных вопросов.
Например, если бы Т1выполняла суммирование остатков по всем открытым счетам, то заблокировав их, она бы остановила работу всех остальных транзакций. Допустимо ли это? И нужно ли полностью блокировать доступ ко всем счетам, учитывая тот факт, что Т1не изменяет их остатки? Может быть и другим транзакциям можно позволить считывать текущее состояние счетов?
Другой вопрос: когда надо блокировать используемый транзакцией элемент БД – в момент старта транзакции или в момент обращения к элементу? И т.д.
Поэтому конкретная реализация механизма блокировок может отличаться многими деталями, но основной принцип его работы всегда один: транзакция прежде, чем получить доступ к какому-либо элементу БД, должна запросить его блокировку по чтению или по записи. После того, как блокировка элемента разрешена для текущей транзакции, никакая другая транзакция не сможет изменить этот элемент и даже не сможет его прочитать (если установлена блокировка по записи) до завершения текущей транзакции.
Если транзакция установила блокировку элемента по чтению, то она имеет право только читать его, но не имеет права изменять. Если блокировку по записи – то может и читать элемент, и изменять его. Блокировка может выполняться в отношении элементов разного размера: отдельного атрибута строки, всей строки, таблицы и даже всей БД.
Поскольку при таких условиях операция чтения не может порождать конфликты, то допускается одновременная блокировка одного и того же элемента по чтению несколькими транзакциями. Поэтому блокировку по чтению называют разделяемой блокировкой. В отличие от нее блокировка по записи является эксклюзивной, то есть дает транзакции монопольное право доступа к заблокированному элементу. До тех пор, пока транзакция удерживает блокировку элемента по записи, никакая другая транзакция не сможет даже прочитать этот элемент.
Порядок работы механизма блокировок обычно бывает следующим:
транзакция для получения доступа к элементу данных должна запросить его блокировку. Блокировка может запрашиваться по чтению (допускает только чтение элемента) или по записи (допускает чтение и изменение элемента);
если элемент еще не заблокирован другими транзакциями, то блокировка разрешается;
если элемент уже заблокирован, то тип запрашиваемого блока сравнивается с типом уже установленного. Если запрашивается доступ по чтению к элементу, который заблокирован по чтению, то доступ разрешается. Во всех остальных случаях транзакция переводится в режим ожидания снятия предыдущих блокировок;
блокировка удерживается транзакцией до своего завершения или до тех пор, пока не снимет ее явным образом в ходе своего выполнения.
Механизм блокировок, решая вышеперечисленные проблемы, создает другую, так называемую, проблему взаимной блокировки (deadlock, смертельные объятия). Пусть транзакции Т1и Т2для своей работы должны заблокировать по записи элементы Э1и Э2. И пусть, вследствие сложившихся временных соотношений, Т1успела заблокировать Э1, а Т2– Э2. Тогда Т1будет переведена в состояние ожидания при попытке заблокировать Э2, а Т2– при попытке заблокировать Э1. В результате образуется бесконечный цикл взаимного ожидания.

Такие ситуации обычно отслеживаются СУБД путем анализа взаимозависимости транзакций или просто по таймеру. В случае их возникновения возможны два решения. Либо какая-нибудь из транзакций выбирается случайным образом жертвой и принудительно откатывается. Либо приложению возвращается сообщение об ошибке взаимной блокировки.
Изоляция транзакций.
Помимо механизма блокировок для обеспечения одновременной работы множества транзакций большое значение имеют уровни их изоляции. Эти уровни определяют видимость для текущей транзакции результатов других, работающих одновременно с ней транзакций. Обычно различают три уровня изоляции транзакций:
1. Dirty Read (грязное чтение). Текущей транзакции видны все изменения, внесенные другими транзакциями, в том числе и неподтвержденные ими. Этот уровень характерен для локальных БД и, по сути, означает отсутствие изоляции транзакций. В серверных БД практически не используется, поскольку может послужить причиной большого числа проблем.
2. Read Committed (чтение подтвержденного). Текущая транзакция видит только те изменения других транзакций, которые ими подтверждены. Это наиболее часто используемый уровень изоляции транзакций. Следует иметь ввиду, что при неоднократном чтении одного и того же элемента результаты могут быть разными, поскольку в промежутке времени между чтениями элемент мог быть изменен и его изменения подтверждены.
3. Repeatable Read (повторяемое чтение). Текущая транзакция видит все данные в том виде, в каком они были подтверждены на момент ее старта. То есть, транзакция как бы работает с моментальным снимком базы данных и ей не доступны никакие последующие изменения. При многократном чтении одного и того же элемента результат всегда будет одним. Такой уровень изоляции транзакций удобно использовать для фиксации состояния базы данных при составлении отчетов. Однако он может быть причиной многочисленных конфликтов блокировок.
Механизм транзакций в InterBase.
Осуществляется с помощью трех операторов:
SET TRANSACTION – запускает транзакцию и определяет режимы ее работы;
COMMIT – подтверждает изменения, выполненные в рамках транзакции, и завершает транзакцию;
ROLLBACK - отменяет изменения, выполненные в рамках транзакции, и завершает транзакцию.
Оператор SET TRANSACTION имеет следующий формат:
SET TRANSACTION
[READ WRITE | READ ONLY]
[WAIT | NO WAIT]
[[ISOLATING LEVEL] {SNAPSHOT [TABLE STABILITY] |
READ COMMITTED [[NO] RECORD_VERSION]}]
[RESERVING <список_таблиц_1> [FOR [{SHARED | PROTECTED}]
{READ | WRITE}] [, <список таблиц 2>...]];
Параметр READWRITE|READONLY– определяет тип доступа (AccessMode), который транзакция имеет к используемым ею таблицам. По умолчанию предполагаетсяREADWRITE. В случаеREADONLYдопускается только чтение данных.
Замечание 1.Если предполагается, что транзакция будет только читать данные, то следует указатьREADONLY, чтобы уменьшить вероятность конфликтов блокировок.
Замечание 2. Несмотря на то, что данный параметр может быть опущен, делать это не рекомендуется. Указание режима доступа в явной форме является хорошей программной практикой. Это касается и всех последующих параметров.
Параметр WAIT|NOWAIT– определяет режим разрешения конфликтов блокировок (LockResolution). По умолчанию WAIT – если данная транзакция во время операции обновления или удаления встретит заблокированную строку, то она будет ждать снятия блокировки, чтобы попытаться выполнить свои действия. В случаеNOWAIT – немедленно возвращается сообщение об ошибке конфликта блокировок.
Параметр SNAPSHOT|READCOMMITTED– определяет уровень изоляции транзакций (IsolationLevel). По умолчаниюSNAPSHOT(аналогREPEATABLEREAD) – обеспечивает стабильное представление БД на момент старта транзакции (моментальный снимок БД). Другие одновременно работающие транзакции могут обновлять и вставлять строки, однако, данная транзакция не будет видеть эти изменения. Она будет видеть те версии строк, которые имели место на момент её старта. Если данная транзакция попытается обновить или удалить строки, измененные другими транзакциями, то наступит конфликт обновления.
SNAPSHOT TABLESTABILITY– обеспечивает транзакции монопольное право на внесение изменений в используемые ею таблицы. Другие, одновременно работающие транзакции, могут только читать данные из этих таблиц. Транзакции такого уровня следует использовать с осторожностью, так как они могут породить большое количество конфликтов блокировок.
READ COMMITTED – дает возможность транзакции видеть все завершенные (подтвержденные COMMIT) изменения, выполненные другими транзакциями. Такая транзакция может обновлять строки, измененные и подтвержденные другими транзакциями, работающими одновременно, без возникновения проблем потерянных обновлений.
Уровень READ COMMITTED дает также возможность указать, какие версии строк следует считывать (дело в том, что при одновременной работе нескольких транзакций в БД может иметься несколько версий одной и той же строки). Если указан параметр RECORD_VERSION, то транзакция считывает последний завершенный (подтвержденный COMMIT) вариант строки, даже если существует более поздний и еще не подтвержденный вариант. По умолчанию действует параметр NO RECORD_VERSION, при котором транзакция может считывать только последнюю версию строки. Если эта версия еще не подтверждена, возникает конфликт блокировок, разрешение которого зависит от параметра [NO] WAIT. Если указан WAIT, то транзакция будет ждать подтверждения или отмены последнего варианта, после чего выполнит повторное чтение. Если NO WAIT – то сообщит об ошибке.
Обычно используются уровни SNAPSHOTиREADCOMMITTED, которые дают одновременно работающим транзакциям возможность считывать и изменять строки в совместно используемых таблицах. Эти уровни минимизируют вероятность конфликтов. Они возникают только в двух случаях:
когда транзакция пытается обновить строку уже обновленную или удаленную другой транзакцией. Строка, обновленная некоторой транзакцией, не может быть изменена другими транзакциями до тех пор, пока изменившая строку транзакция не будет завершена или отменена;
когда транзакция пытается вставить, изменить или удалить строку в таблицу, которая заблокирована другой транзакцией с уровнем SNAPSHOTTABLESTABILITY. Транзакция с уровнемSNAPSHOTTABLESTABILITYполностью блокирует таблицу по записи. УровеньSNAPSHOTTABLESTABILITYгарантирует, что только одна транзакция может изменять таблицу, но при этом растет вероятность конфликтов.
Транзакции уровня SNAPSHOTне могут изменять или удалять строки, которые были изменены и подтверждены другими одновременно работающими транзакциями. ТранзакцияREADCOMMITTEDможет считывать изменения, завершенные другими транзакциями, и после этого обновлять измененные строки. Случайные конфликты обновления могут происходить, если одновременно работающие транзакции уровняSNAPSHOTилиREADCOMMITTEDделают попытку изменить одну и ту же строку.
Замечание. Если операторUPDATEизменяет несколько строк в таблице, то при возникновении конфликта обновления хотя бы одной строки все изменения отменяются.
Необязательное предложение RESERVINGдает транзакции возможность гарантировать для себя определенные права доступа к некоторому подмножеству таблиц. Резервирование производится при запуске транзакции, а не тогда, когда операторы манипуляции данными требуют определенного режима доступа. ОбычноRESERVINGиспользуется в трех случаях:
для предотвращения возможных взаимных блокировок;
с целью обеспечения блокировок для зависимых таблиц, которые изменяются триггерами или ограничениями ссылочной целостности;
чтобы изменить уровень доступа только для части используемых таблиц. Например, для транзакции уровня SNAPSHOTможно обеспечить исключительный доступ (уровняSNAPSHOTTABLESTABILITY) только для отдельных таблиц.
Оператор COMMITиспользуется для фиксации изменений, выполненных транзакцией. Этот оператор закрывает потоки записей, связанные с транзакцией, и освобождает системные ресурсы, выделенные транзакции.
Оператор ROLLBACKиспользуется для возврата БД в то состояние, которое имело место на момент старта транзакции. Обычно применяется в случае возникновения ошибок. Он также закрывает потоки записей, связанные с транзакцией, и освобождает системные ресурсы, выделенные транзакции.
Замечание.Даже транзакции с режимом доступаREADONLY, которые не вносят изменения, рекомендуется заканчивать операторомCOMMIT, а неROLLBACK. При этом для запуска следующей транзакции требуется меньше ресурсов.
Компоненты Delphi для работы с InterBase.
В Delphi имеется два набора компонентов, предназначенных для создания клиентских приложений InterBase / Firebird. Во-первых, это универсальные компоненты доступа к БД через механизмы BDE (они расположены на странице BDE). Их основное достоинство заключается в универсальности, что позволяет относительно просто переориентировать приложение на использование различных СУБД. Однако универсальность имеет и оборотную сторону, заключающуюся в игнорировании множества индивидуальных возможностей разных СУБД (в универсальном механизме невозможно учесть все детали конкретных СУБД). Кроме того, BDE выступает в качестве еще одного передаточного звена между приложением и СУБД, которое может вносить свои искажения в смысл передаваемых команд и данных (ситуация эквивалентна переводу с русского языка на английский через, например, немецкий язык).
Поэтому при создании сколько-нибудь значительных клиент-серверных приложений обычно используется альтернативный набор компонентов, непосредственно взаимодействующих с SQL сервером InterBase (Firebird) без посредничества BDE. Они расположены на странице InterBase и имеют общее название InterBaseExpess (IBX). Если приложение написано только с использованием компонентов IBX, то на клиентском компьютере можно не устанавливать BDE, достаточно наличия InterBase Client (gds32.dll).
Замечание. Компоненты IBX не являются «родными» компонентами Delphi. Это сторонняя разработка, включенная в Delphi. Помимо них, существуют и другие наборы компонентов, предназначенные для создания клиентских приложений InterBase / Firebird, которые по многим параметрам превосходят IBX. Наиболее признанными и широко применяемыми среди них являются компоненты FIBPlus (к сожалению, это коммерческая разработка и предполагает соответствующую плату за использование). Мы остановимся на InterBaseExpress, только потому, что они непосредственно включены в дистрибутив Delphi.
Компонент TIBDatabase обеспечивает соединение с БД, создает ее локальный псевдоним и указывает параметры соединения. В рамках приложения обычно используется одно соединение с базой данных (один компонент TIBDatabase).
В отличие от соединения через BDE компонент TDatabase, соединение через TIBDatabase может обеспечивать одновременную работу нескольких транзакций. В IBX транзакции отделены от соединения и задаются отдельными компонентами TIBTransaction.
Компонент TIBTransaction используется для определения транзакций, которых может быть несколько для каждого из соединений с БД.
В свойстве Name указывается имя транзакции для ссылок на нее из других компонентов. Параметры транзакции задаются с помощью редактора Transaction Editor, вызываемого из контекстного меню . Наиболее часто используемый уровень изоляции транзакций – Read Committed.
Замечание. Завершение транзакции (ее подтверждение или откат) автоматически закрывает все компоненты, которые работали в ее контексте. Если работа с компонентами должна продолжаться, то они должны быть активизированы вновь в явной форме. По этой причине, в частности, не стоит привязывать большое число компонентов к одной и той же транзакции, т.к. при подтверждении или откате транзакции в целях одного из компонентов придется вновь активировать все другие компоненты, работающие в рамках данной транзакции.
Компонент TIBTable по своим свойствам и методам этот компонент во многом совпадает с компонентом TTable, но имеет особенности, обусловленные ориентацией на работу с серверными БД.
Вообще, рекомендуется весьма ограниченное использование табличных компонентов для серверных БД и только для таблиц небольшого объема. Эта рекомендация обусловлена ориентацией табличных компонентов на навигационный способ доступа к данным. Так, например, если использовать TIBTable для доступа к таблице большого объема, то переход в ней к последней записи потребует значительного времени и создаст большую нагрузку на сеть, поскольку при этом вся таблица будет последовательно, от начала до конца передана на локальное место. Аналогично, включение фильтра в табличном компоненте предполагает полное копирование таблицы с сервера на локальное место, и т.д.
Поэтому при работе с серверными БД настоятельно рекомендуется использовать компоненты типа TIBQuery, которые обеспечивают отбор необходимой информации непосредственно на сервере и по сети передают только результаты выполнения запросов, а не полное содержимое таблиц.
Для работы TIBTable необходимо в свойстве Database выбрать имя компонента TIBDatabase, а в свойстве Transaction – имя транзакции, в рамках которой будут выполняться запросы этого компонента к БД. В свойстве TableName должно быть указано имя таблицы, работа с которой предполагается через компонент TIBTable.
Свойство UniDirectional определяется возможность двунаправленного движения по таблице. Если UniDirectional установлено в False, то обеспечивается возможность перемещения по набору данных как от начала к концу, так и в обратном направлении. Однако это требует больше ресурсов для работы компонента, поскольку предполагает кэширование (буферизацию) набора данных на локальном месте (серверные БД предполагают возможность перемещения только в прямом направлении путем последовательной загрузки очередного набора строк).
Активизировать созданные компоненты можно, например, при показе главной формы приложения:
procedure TMainForm.FormShow(Sender: TObject);
begin
DM.TipyLicT.Open;
DM.PodrT.Open;
end;
Компонент TIBQuery используется для реализации запросов к БД, как возвращающих набор данных (оператор SELECT), так и не возвращающих (INSERT, UPDATE, DELETE). Возвращаемый набор данных может быть визуализирован точно так же, как и в случае TTable при посредничестве TDataSource.
Компонент TIBQuery используется для реализации запросов к БД, как возвращающих набор данных (оператор SELECT), так и не возвращающих (INSERT, UPDATE, DELETE). Возвращаемый набор данных может быть визуализирован точно так же, как и в случае TTable при посредничестве TDataSource.
Компонент TIBStoredProc предназначен для работы с хранимыми процедурами действия, которые возвращают не более одного набора значений выходных параметров. В принципе этот компонент можно использовать и для процедур выбора, но более естественным для них будет использование компонента TIBQuery с соответствующим оператором SELECT.
В свойстве StoredProcName указывается имя хранимой на сервере процедуры. В свойстве Transaction указывается имя транзакции, в рамках которой должна выполняться процедура.
Доступ к входным и выходным параметрам процедуры осуществляется через свойства Params и ParamByName аналогично динамическим запросам. Если хранимая процедура вызывается многократно с различными значениями параметров, то имеет смысл выполнить ее подготовку с помощью метода Prepare.
Выполнение хранимой процедуры действия инициируется вызовом метода ExecProc.
Трехуровневая архитектура ANSI-SPARC.
Рассматриваемая далее методика проектирования баз данных основана на архитектуре ANSI-SPARC, которая выделяет три уровня описания данных (требований к структуре БД): внешний, концептуальный и внутренний (рис. 1).
Внешний уровень состоит из представлений отдельных пользователей о том, какая информация должна храниться в базе данных; каким обработкам она будет подвергаться; какие результаты и в какой форме должны получаться. Т.е., этот уровень представляет собой постановку задачи с точки зрения будущих пользователей БД.
На концептуальном уровне представления пользователей преобразуются в единую логическую структуру, называемую концептуальной моделью данных. Эта модель должна с максимально возможной точностью отображать объекты и процессы реального мира и взаимосвязи между ними. На концептуальном уровне принимается решение о типе базы данных (реляционная, сетевая, объектная и т.д.); определяется набор отношений, связей между ними, атрибутов, множество выполняемых в базе данных операций (транзакций). Таким образом, получается постановка задачи с точки зрения разработчика базы данных.
Далее, на внутреннем уровне выбирается конкретная СУБД и концептуальная модель преобразуется во внутреннюю с учётом возможностей и ограничений выбранной СУБД. Здесь определяется набор таблиц, первичные и внешние ключи, набор индексов, требования к аппаратной части и т.п. Т.е., на внутреннем уровне разрабатывается детальный рабочий проект базы данных, на основе которого в дальнейшем выполняется физическая реализация базы данных.
Помимо структуризации процесса проектирования трехуровневая модель способствует решению важных проблем независимости от логической и физической структуры данных.
Независимость от логической структуры данных подразумевает защищённость внешних схем от изменений, вносимых в концептуальную схему. Это значит, что изменения, вносимые в концептуальную схему по требованию одного из пользователей (добавление или изменение сущностей, связей, атрибутов и т.п.), не должны сказываться на остальных пользователях. Соответственно, изменения коснутся только приложения, обслуживающего нужды конкретного пользователя, а все остальные приложения смогут продолжать свою работу без модификации.
Независимость от физической структуры данных предполагает защищённость концептуальной схемы от изменений, вносимых во внутреннюю схему. Т.е., изменения, например, файловой системы, операционного окружения, набора индексов и т.п. никоим образом не должны сказываться на концептуальной и, тем более, внешних схемах. Единственным видимым для пользователей следствием внесенных во внутреннюю схему изменений должно стать повышение производительности работы системы.
Концептуальное проектирование баз данных.
Концептуальное проектирование – это создание концептуального представления объектов и процессов реального мира в виде совокупности некоторого множества типов сущности и связи без учета каких-либо аспектов последующей реализации базы данных.
В процессе концептуального проектирования при постоянном контакте с будущими пользователями базы данных строится концептуальная схема объектов/процессов реального мира и их взаимосвязей. Эта схема не привязывается не только к конкретной СУБД, но даже к типу БД. Основное назначение концептуальной схемы – адекватное отражение объектов и процессов, имеющих место в реальном мире. Отображение схемы в область баз данных происходит на следующем этапе логического проектирования.
Результатом концептуального проектирования является обобщенная модель данных предметной области без привязки не только к конкретной СУБД, но даже и к ее типу. Для этого этапа проектирования, как и, в известной степени, для следующего этапа – логического проектирования, характерна необходимость постоянного взаимодействия с будущими пользователями БД, поскольку именно они являются основными носителями всей нужной информации. Какой бы полной не казалась исходная постановка задачи, у проектировщика неизбежно возникают вопросы, требующие выяснения или согласования с пользователями.
И еще одно замечание. Концептуальное проектирование – процесс неоднозначный и во многом субъективный. Одна и та же предметная область может быть представлена различными наборами типов сущности и связи. При этом качество модели в существенной степени определяется опытом и искусством разработчика.
Логическое проектирование баз данных.
Логическое проектирование – это процесс преобразования концептуальной модели в логическую, отвечающую требованиям конкретной модели данных, и далее в набор отношений и связей между ними.
Логическое проектирование начинается с выбора наиболее подходящего типа (модели) базы данных, но пока без привязки к конкретной СУБД. Далее концептуальная схема преобразуется в логическую, отвечающую требованиям и ограничениям выбранного типа БД. Полученная схема проверяется на соответствие требованиям нормализации и пригодность для выполнения всего набора предполагаемых транзакций. В процессе логического проектирования схема неоднократно уточняется на основе информации, получаемой от пользователей.
В начале логического проектирования на основе информации, полученной на предыдущих этапах, делается выбор модели данных (реляционная, сетевая, объектная, …), которая позволит наиболее адекватно отразить реальные объекты и процессы предметной области средствами проектируемой БД. Поскольку каждая модель имеет известные особенности и ограничения, то исходная концептуальная модель должна быть преобразована с тем, чтобы исключить из нее все элементы, которые не могут быть реализованы в рамках выбранной модели данных.
Затем на основе скорректированной модели строится набор отношений и связей между ними и проверяется на соответствие требованиям нормализации и возможность выполнения всех предполагаемых транзакций. Здесь же определяются требования и способы поддержки целостности данных в будущей БД.
Отметим, что логическое проектирование выполняется с учетом выбранного типа базы данных, но не привязывается к какой-то конкретной СУБД.
\
Физическое проектирование баз данных.
Физическое проектирование – это процесс создания базы данных средствами выбранной СУБД и разработки приложений.
На этапе физического проектирования выбирается конкретная СУБД, и в ее рамках определяются таблицы, первичные и внешние ключи, способы поддержания целостности хранимой информации, набор индексов, требования к аппаратной части и т.п. Схема оптимизируется под выбранную СУБД и приводится в соответствие с ее возможностями. Физическое проектирование, как правило, выполняется специалистами иного профиля, чем исполнители первых двух этапов, и не предполагает непосредственных контактов с пользователями. Все возникающие здесь вопросы решаются с исполнителями концептуального/логического проектирования и свидетельствуют о недоработках предыдущих этапов.
Вначале физического проектирования на основе всей информации, собранной в процессе концептуального и логического проектирования, с учетом предполагаемого объема хранимой информации, количества одновременно работающих приложений-клиентов, имеющегося бюджета и др. факторов делается выбор конкретной СУБД, в рамках которой будет выполняться физическая реализация базы данных.
Далее средствами выбранной СУБД создаются таблицы и реализуются ограничения, определяется набор вторичных индексов, задаются правила и права доступа к базе данных, разрабатываются серверные и клиентские части приложений. Большое внимание при этом уделяется скорости выполнения наиболее часто используемых запросов.
В целях повышения скорости выполнения запросов и общей производительности системы достаточно часто приходится использовать приемы, предполагающие отклонение от требований нормализации. При этом следует помнить, что всякий отход от требований нормальных форм до НФБК включительно создает почву для проблем обновления. Поэтому одновременно должны предприниматься адекватные меры по исключению возможности появления такого рода проблем, то есть процесс денормализации (введения избыточности) должен быть контролируемым.
Типы сущностей. Атрибуты.
Типом сущностиназывается некоторое множество объектов или процессов реального мира, обладающих одинаковым набором свойств (характеристик, атрибутов). Каждый элемент этого множества называетсяэкземпляром сущностиили простосущностью.
Замечание.Часто термин «сущность» используется для обозначения не только отдельного экземпляра сущности, но и для типа сущности. О чем идет речь, как правило, следует из контекста.
Например, в рассматриваемой учебной задаче можно выделить тип сущности «Отделение» со свойствами: номер, адрес, телефон. Экземплярами сущности здесь будут Отделение №1, Отделение №2, … Другой пример: тип сущности «Склад» с экземплярами Склад №1 Отделения №1, Склад №3 Отделения №2 и т.д.
В качестве типа сущности могут выступать не только объекты, но и процессы. Например, тип сущности «Наличие товара на складе» с атрибутами: товар, склад, количество, отражает процесс хранения товаров на складе.
Обычно различают сильные и слабые типы сущности.
Сильнымназывается тип сущности, существование которого не зависит от каких-либо других типов сущности. Соответственно,слабым– существование, которого зависит от других типов сущности.
Например, тип сущности «Отделение» является сильным. Когда мы говорим: Отделение №2, сразу ясно, о каком отделении идет речь, и при этом не надо выяснять его взаимосвязи с другими типами сущности. Напротив, если сказать: Склад №2, то однозначно указать на конкретный склад будет невозможно, поскольку склад №2 есть и в первом отделении и во втором и т.д. То есть, здесь для указания конкретного объекта придется дать еще ссылку на отделение. Таким образом, в рассматриваемой постановке задачитип сущности «Склад» является слабым.
Замечание. Если ввести сквозную нумерацию складов на предприятии (а не в рамках отделения), то тип сущности «Склад» будет сильным. Поэтому приведенное выше определение сильного типа сущности не является строгим и допускает различные толкования в зависимости от конкретной постановки задачи. Более строгая формулировка понятия сильного типа сущности будет дана позднее.
На диаграммах типы сущности обозначаются прямоугольниками, причём слабые типы сущности отличаются двойным контуром .
Отдельное свойство (характеристика) сущности (типа сущности) называется её атрибутом. Например, тип сущности «Отделение» имеет атрибуты: номер, адрес, телефон; тип сущности «Товар»: наименование, единица измерения, цена.
Различают несколько разновидностей атрибутов.
Составнымназывается атрибут, состоящий из нескольких компонентов.
Например, атрибут «адрес» может включать в себя компоненты: город, улица, строение (вопрос о целесообразности разделения атрибута на несколько компонент будет рассмотрен позднее).
Многозначнымназывается атрибут, который может принимать несколько значений для одного и того же экземпляра сущности.
В нашем примере таким атрибутом является телефон отделения, поскольку по постановке задачи в каждом отделении может быть несколько телефонов.
Производнымназывается атрибут, значение которого рассчитывается на основе значений других атрибутов.
Примеры: общая сумма в накладной, стаж работы на предприятии, количество работников в отделении и т.п.
Множество допустимых значений атрибута называется доменом атрибута. Каждый атрибут должен быть определен на некотором домене. Причем на одном домене может быть определено несколько атрибутов, но каждый атрибут может быть определен только на одном домене.
Например, атрибут «Пол работника» может быть определен на домене, который представляет собой множество из двух символов: «м» и «ж». Для номеров отделений и складов доменом может служить множество натуральных чисел. И т.д.
Большое значение для проектирования баз данных имеют рассмотренные выше понятия потенциальных и первичных ключей. В отношении типов сущности и их атрибутов эти понятия формулируются следующим образом.
Потенциальным ключомназывается атрибут или набор атрибутов, позволяющий однозначно идентифицировать каждый экземпляр типа сущности.
Первичным ключомназывается потенциальный ключ, выбранный для уникальной идентификации экземпляров типа сущности.
Если ключ состоит из нескольких атрибутов, то он называется составным ключом.
На диаграммах атрибуты изображаются эллипсами, которые связаны со своими типами сущности линиями, при этом многозначные атрибуты выделяются двойным контуром; производные атрибуты – штриховым; для составных атрибутов указываются их компоненты. Наименования атрибутов входящих в первичный ключ подчёркиваются.
Для того чтобы не загромождать большие диаграммы детальной информацией, на них обычно прорисовывают только атрибуты, входящие в состав первичных ключей.
Типы связей.
Типом связи называется осмысленная взаимосвязь между типами сущностей. Взаимосвязи между отдельными экземплярами сущностей называются экземплярами связейили простосвязями.
Например: работник состоит в штатеотделения – тип связи, а работник Ивановсостоит в штатеотделения №1 – экземпляр связи.
На диаграммах типы связи обозначаются ромбами. Если в связи участвует слабая сущность, то контур ромба должен быть двойным. Например, связи «отделение состоит изскладов» соответствует такая диаграмма.
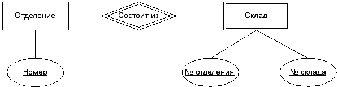
Для детального изучения свойств связей часто используют семантические диаграммы, на которых прорисовывают отдельные экземпляры связей (рис. 7). На них экземпляры сущностей обозначаются точками, а экземпляры связей – ромбиками.

Естественно, что семантические диаграммы прорисовывают только для отдельных частей полной диаграммы для выяснения характера конкретных типов связи.
Степенью связи называется количество охватываемых ею типов сущности.
Наиболее распространены бинарные (степени 2) связи, которые соединяют два типа сущности. Например, рассмотренная выше связь «состоит из» имеет степень 2. Реже встречаются связи больших степеней. Например, кватернарная (степени 4) связь «покупатель покупаеттовар»
Иногда встречаются рекурсивные (унарные) связи, в которых один и тот же тип сущности выступает в разных ролях. Например, руководитель отделения, являясь работником отделения, руководит всеми остальными работниками этого отделения (рис. 9).
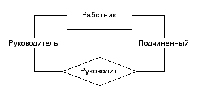
Рис. 9. Унарная связь
Важной характеристикой связи является ее показатель кардинальности. Различают следующие показатели кардинальности:один-к-одному (1:1), один-ко-многим (1:M), многие-ко-многим (M:N). Для определения кардинальности связи обычно используют семантические диаграммы.
Рассмотрим, например, связь «работник заведуетскладом» (рис. 12).
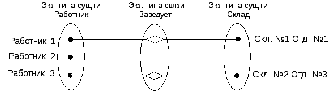
Еще одной важной характеристикой связи является степень участияв ней связываемых сущностей. Если все экземпляры некоторой сущности должны участвовать в рассматриваемой связи, то степень участия этой сущности будетполной. Если некоторые экземпляры сущности могут не участвовать в связи, то –частичной. Например, в связи «работникзаведуетскладом» сущность «Работник» имеет частичное участие, т.к. не все работники являются заведующими складами. А сущность «Склад» в этой связи имеет полное участие, т.к. каждый склад должен иметь заведующего.
Ловушки соединений. Специализация / генерализация.
Неправильная интерпретация связей на этапе создания ER-модели может послужить причиной появления ряда проблем при физической реализации базы данных. Эти проблемы получили названиеловушек соединения. Различают ловушки разветвления и ловушки разрыва. Рассмотрим их на примерах.
Возьмем следующий фрагмент модели (рис. 18). На первый взгляд такая схема обеспечивает взаимосвязь сущностей «Работник» и «Склад» через сущность «Отделение». Проверим это заключение с помощью семантической диаграммы (рис. 19).
Рис. 18. Фрагмент ER-модели (вариант 1)
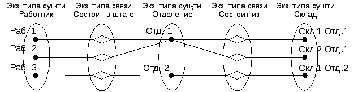
Рис. 19. Семантическая диаграмма (вариант 1)
Из семантической диаграммы видно, что такой вариант модели не позволит ответить на запрос: какие работники работают на первом складе первого отделения, поскольку Работник1 и Работник2 могут в этой модели быть приписаны как к первому, так и ко второму складам. Это и есть ловушка разветвления.
Ловушка разветвленияимеет место в тех случаях, когда на схеме есть цепь связей между двумя типами сущности, но связи между отдельными экземплярами этих сущностей определяются неоднозначно.
Для устранения обнаруженной проблемы перестроим модель следующим образом (рис. 20). Соответствующая семантическая диаграмма будет иметь вид (рис. 21).

Рис. 20. Фрагмент ER-модели (вариант 2)
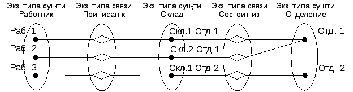
Рис. 21. Семантическая диаграмма (вариант 2)
В некоторых случаях для повышения информативности модели, уточнения функций отдельных подтипов имеет смысл выделить их на ER-модели. При этом категорию, соответствующую общему понятию (в данном случае «Работник»), называютсуперклассом, а категории, соответствующие частным понятиям (руководитель отделения, заведующий складом) –подклассами. Сам процесс выделения подклассов из суперкласса называютспециализацией.
Возможен и обратный процесс объединения нескольких подклассов в единый суперкласс, называемый генерализацией. В рассматриваемой постановке задачи может оказаться целесообразным объединение типов сущности «Поставщик» и «Покупатель» в суперкласс «Контрагент».
На схемах специализацию/генерализацию изображают следующим образом (рис. 25).
Буква “d” в кружке означает, что подклассы являются непересекающимися, то есть участник одного подкласса не может одновременно быть участником и другого подкласса. В противном случае, для пересекающихся подклассов, в кружке ставится буква “o”. Кроме того, на схемах отражают степень участия суперкласса в специализации. Если все члены суперкласса должны входить в какой-либо подкласс, то это полное участие (отмечается двойной линией связи для суперкласса), если такое требование отсутствует (например, не все работники являются руководителями отделений или заведующими складами) – то участие частичное. На рис. 26 изображена генерализация типов сущности «Поставщик» и «Покупатель» для случая, когда один и тот же контрагент может быть как поставщиком, так и покупателем.
ER-модели.
Одним из важных инструментов, используемых на этапах концептуального и логического проектирования, являются модели «сущность - связь» («Entity–Relationship»,ER-модели). В основеER-моделирования лежат три понятия: тип сущности, атрибут, тип связи.
Пример:
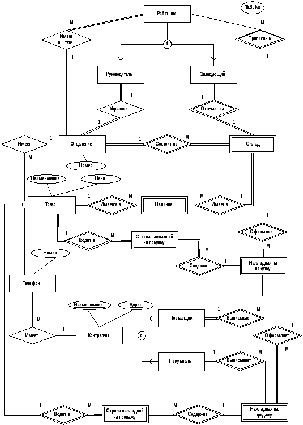
Нормализация и проблемы обновления.
1. Избыточность хранимой информации. Например, информация о некотором товаре (наименование, единица измерения, цена) будет повторяться для каждого склада, где этот товар хранится.
2. Проблема вставки кортежей. При добавлении на некоторый склад товара, который уже имеется на других складах, необходимо повторить ввод всех атрибутов товара точно в таком виде, в котором они уже записывались ранее для других складов. Здесь появляется потенциальная возможность ввода разных значений атрибутов одного и того же товара в строках, относящихся к различным складам. Кроме того, для рассматриваемого отношения первичный ключ определяется по атрибутам: номер отделения, номер склада, наименование и цена товара. Поэтому, если возникнет необходимость добавить информацию о новом складе, на котором еще нет товаров, то сделать это будет невозможно, так как нельзя добавить строку с незаполненными полями наименования и цены товара (нарушение требования целостности сущностей).
3. Проблема удаления кортежей. Если на каком-либо складе не останется товаров, то при удалении строки с последним товаром будет удалена и информация о самом складе.
4. Проблема изменения кортежей. При необходимости, например, изменить наименование какого-либо товара, соответствующие изменения должны быть сделаны в нескольких строках, относящихся к различным складам, на которых этот товар имеется в наличии. Соответственно, появляется возможность рассогласования информации в записях об одном и том же товаре на различных складах.
Замечание. Последние три из перечисленных выше проблем получили наименование проблем обновления.
Для исключения перечисленных проблем при проектировании баз данных используется набор приемов, получивший общее название: нормализация отношений.
Нормализациейназывается метод проектирования отношений в реляционных базах данных, который позволяет минимизировать избыточность хранимой информации и исключить возможность появления проблем обновления.
Замечание. Существуют методики проектирования баз данных, полностью основанные на процессе нормализации. Рассматриваемая далее методика проектирования использует нормализацию в качестве вспомогательного средства проверки отношений, полученных иными способами.
Процесс нормализации заключается в последовательном приведении отношений в соответствие с требованиями первой нормальной формы (1НФ), второй нормальной формы (2НФ), третьей нормальной формы (3НФ), нормальной формы Бойса-Кодда (НФБК) и, в некоторых случаях, 4НФ и 5НФ.
Исходным материалом для нормализации обычно служат отношения, получаемые из существующих печатных форм и документов путем представления их в табличном виде.
Функциональные зависимости атрибутов.
Атрибут
 называется функционально зависимым от
атрибута
называется функционально зависимым от
атрибута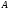 (
(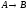 ),
если каждому конкретному значению
атрибута
),
если каждому конкретному значению
атрибута всегда соответствует одно и то же
значение атрибута
всегда соответствует одно и то же
значение атрибута .
При этом конкретному значению атрибута
.
При этом конкретному значению атрибута может соответствовать несколько значений
атрибута
может соответствовать несколько значений
атрибута .
.
Замечание. Под
атрибутами и
и могут пониматься как отдельные атрибуты,
так и группы атрибутов.
могут пониматься как отдельные атрибуты,
так и группы атрибутов.
Атрибут
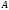 в функциональной зависимости
в функциональной зависимости называется детерминантом.
называется детерминантом.
Приведем примеры функциональных зависимостей:
№ отд.
 Адрес, телефон;
Адрес, телефон;
№ отд., № скл.
 ФИО зав. скл., Таб. № зав. скл.;
ФИО зав. скл., Таб. № зав. скл.;
Таб. № зав. скл.
 № отд., № скл.;
№ отд., № скл.;
№ отд., № скл.,
Наименование товара, Цена
 все остальные атрибуты.
все остальные атрибуты.
Легко заметить,
что понятие функциональной зависимости
атрибутов практически совпадает с
аналогичным понятием однозначной
функции в функциональном анализе. При
этом атрибут
 выступает, как аргумент функции
выступает, как аргумент функции (см. рис. 1)
(см. рис. 1)
Для случая, когда
 представляет собой группу атрибутов,
можно сформулировать понятие полной
функциональной зависимости.
представляет собой группу атрибутов,
можно сформулировать понятие полной
функциональной зависимости.
Атрибут
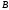 называетсяполностьюфункционально
зависимымот набора атрибутов
называетсяполностьюфункционально
зависимымот набора атрибутов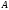 ,
если он функционально зависит только
от полного набора атрибутов
,
если он функционально зависит только
от полного набора атрибутов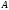 и не зависит от любого его подмножества.
и не зависит от любого его подмножества.
Или то же самое
другими словами: функциональная
зависимость
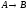 называется полной, если она утрачивается
при исключении любого атрибута из набора
называется полной, если она утрачивается
при исключении любого атрибута из набора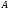 .
.
Примеры:
№ отд., № скл.,
Наименование товара, Цена
 Количество – полная;
Количество – полная;
№ отд., № скл.,
Наименование товара, Цена
 Адрес, Телефон – частичная (№ скл.,
Наименование товара и Цена могут быть
исключены из набора
Адрес, Телефон – частичная (№ скл.,
Наименование товара и Цена могут быть
исключены из набора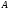 );
);
№ отд., № скл.
 ФИО зав. скл., Таб. № зав. скл. – полная.
ФИО зав. скл., Таб. № зав. скл. – полная.
Атрибут
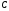 называетсятранзитивно зависимымот атрибута
называетсятранзитивно зависимымот атрибута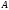 через атрибут
через атрибут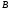 ,
если имеют место зависимости
,
если имеют место зависимости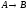 и
и ,
но атрибут
,
но атрибут не зависит ни от
не зависит ни от ,
ни от
,
ни от .
.
1НФ и 2НФ.
Отношение находится в первой нормальной форме, если в нем на пересечении каждого столбца с каждой строкой (т.е. в каждой ячейке) имеется значение и притом единственное.
Переход к 1НФ осуществляется простым дублированием значений в пустых ячейках (табл. 2). Очевидно, что при этом быстро растет избыточность представленной в таблице информации.
Отношение находится во второй нормальной форме, если оно отвечает требованиям 1НФ и все его атрибуты (не входящие в первичный ключ) полностью функционально зависят от атрибутов первичного ключа.
Переход от 1НФ к 2НФ осуществляется путем декомпозиции исходного отношения на несколько более мелких отношений. При этом в отдельные отношения выносятся атрибуты, частично зависимые от первичного ключа, с копией той части ПК, от которой они зависят полностью.
Выполним переход к 2НФ в нашем примере. Для этого выпишем полные функциональные зависимости для всех атрибутов, не входящих в ПК:
№ отд.
 Адрес, Телефон;
Адрес, Телефон;
№ отд., № скл.
 ФИО зав. скл., Таб. № зав. скл.;
ФИО зав. скл., Таб. № зав. скл.;
Наименование
товара, Цена
 Ед.изм.;
Ед.изм.;
№ отд., № скл.,
Наименование товара, Цена
 Количество.
Количество.
Из анализа этих зависимостей видно, что из исходного отношения следует выделить следующие три отношения с копиями частей первичного ключа:
Отделение(№ отд., Адрес, Телефон);
Склад(№ отд.,№ скл., ФИО зав. скл., Таб. № зав. скл.);
Товар(Наименование товара,Цена, Ед.изм.)
после чего исходное отношение примет вид:
Наличие(№ отд.,№ скл.,Наименование товара,Цена, Количество).