

681_Trofimov_V.K._Teoremy_kodirovanija_neravnoznachnymi_
.pdfФедеральное агентство связи
Федеральное государственное бюджетное образовательное учреждение высшего образования
«Сибирский государственный университет телекоммуникаций и информатики» (СибГУТИ)
В. К. Трофимов
Т. В. Храмова
ТЕОРЕМЫ КОДИРОВАНИЯ
НЕРАВНОЗНАЧНЫМИ СИМВОЛАМИ
ДЛЯ ДИСКРЕТНЫХ КАНАЛОВ БЕЗ ШУМА
МОНОГРАФИЯ
Новосибирск
2016
УДК 621.391
Трофимов В. К., Храмова Т. В.
Теоремы кодирования неравнозначными символами для дискретных каналов без шума. Монография. – Изд-во СибГУТИ, Новосибирск, 2016. – 80с., илл.
Рецензенты: д.т.н. А.Л. Резник, д.ф.м.н. Г.Г. Черных.
Утверждено редакционно-издательским советом СибГУТИ
©«Сибирский государственный университет телекоммуникаций и информатики»
©Трофимов В.К., Храмова Т.В., 2016 г.
2
Оглавление |
|
Предисловие |
5 |
Введение |
6 |
Предварительные сведения |
8 |
1. Канал передачи информации |
10 |
1.1. Общая схема канала без шума |
10 |
1.2. Понятие источника информации |
11 |
1.3. Энтропия источника информации |
13 |
1.4. Кодирование источника сообщений |
16 |
1.5. Пропускная способность канала и избыточность кодирования |
|
информации |
18 |
2.Некоторые методы кодирования известного источника равнозначными
символами |
19 |
2.1. Код Хаффмана |
19 |
2.2. Арифметическое кодирование |
23 |
2.3. Код Лемпела-Зива |
26 |
3. Кодирование известного источника неравнозначными символами |
29 |
3.1. Предварительные построения |
29 |
3.2. Схема кодирования неравнозначными символами |
34 |
3.3. Оценка стоимости кодирования известного источника неравнозначными |
|
символами |
41 |
4.Универсальное кодирование бернуллиевских источников буквами
кодового алфавита с неравными длительностями |
42 |
4.1. Схема кодирования множества бернуллиевских источников буквами |
|
кодового алфавита с неравными длительностями |
43 |
4.2. Верхняя оценка избыточности универсального кодирования множества |
|
бернуллиевских источников |
49 |
4.3. Нижняя оценка избыточности универсального кодирования множества |
|
бернуллиевских источников |
50 |
3
4.4. Асимптотика избыточности универсального кодирования множества
бернуллиевских источников |
51 |
5.Универсальное кодирование марковских источников буквами кодового
алфавита с неравными длительностями |
58 |
5.1. Кодирование неравнозначными символами информации, порожденной |
|
неизвестным марковским источником |
58 |
5.2. Верхняя оценка избыточности универсального кодирования марковских |
|
источников символами неравнозначных длительностей |
64 |
5.3. Нижняя оценка избыточности универсального кодирования марковских |
|
источников неравнозначными символами |
65 |
5.4. Асимптотика избыточности универсального кодирования марковских |
|
источников неравнозначными символам |
66 |
6.Слабо универсальное кодирование стационарных источников
символами с неравнозначными длительностями |
68 |
7.Оптимальное универсальное кодирование объединения различных
множеств источников символами неравной длительности |
69 |
7.1. Адаптивное кодирование объединения различных множеств |
|
источников |
69 |
7.2. Универсальное кодирование для объединения множеств марковских |
|
источников |
71 |
Литература |
74 |
4
Предисловие
Вопросы сжатия информации возникают при решении многих задач.
Например, сжатие информации позволяет в несколько раз уменьшить ее объем при передаче. Так, хорошо известные факсимильные аппараты при работе при-
мерно в 3,5 – 4 раза уменьшают объем передаваемой информации. При факси-
мильной передаче больших текстов (таких, например, как газетные) удается уменьшить объем передаваемых данных до 10 раз. Отметим также широкое ис-
пользование методов сжатия информации в криптографии. Можно считать, что первым алгоритмом, позволяющим сжать сообщение, явился известный код Морзе. В дальнейшем появились новые возможности передачи сообщений, та-
кие как телефон, радио, телевидение, интернет. С их помощью передаются ограниченные потоки информации. Задача сжатия приобрела огромное значе-
ние, и для её решения в различных случаях была создана наука, названная тео-
рией информации.
Теория информации излагается во многих книгах. В них нашли отраже-
ние универсальные коды, которые позволяют сжимать тексты различной при-
роды, не требуя знания их точной закономерности.
Проведем анализ между степенью сжатия и сложностью реализации этих алгоритмов. Все методы сжатия информации, описанные в литературе, как пра-
вило излагаются для случая, когда символы, используемые при передаче по ка-
налам связи равнозначны. Если же эти символы не равнозначны, то в моногра-
фиях описаны методы сжатия информации, когда структура этой информации известна. К последним относятся работы К. Шеннона, И. Чиссара, Г. Катоны
(G. Katona).
Изучению вопросов сжатия информации символами различной стоимости и посвящена настоящая монография. Книга может быть полезна для специали-
стов по теории информации, информатике, программированию, базам данных.
5
Введение
В условиях современной реальности мы постоянно сталкиваемся с лави-
нообразным потоком информации, которую необходимо обрабатывать, хранить
и передавать. Передача информации по каналам связи сопровождается ее
предварительной обработкой с целью уменьшения объема информации, подле-
жащей передаче, защиты ее от искажения в процессе передачи, и т.д. Уменьше-
ние объема передаваемой информации напрямую связано с увеличением скоро-
сти передачи, а также экономией процессорного времени, затрачиваемого на дальнейшую обработку. Задача уменьшения объема памяти, занимаемого ин-
формацией, частично решается за счет использования методов сжатия данных и кодирования дискретных источников. Следует отметить, что решение задач ко-
дирования источников используется также в теории управления, при выявлении скрытой информации, при создании большемасштабных вычислительных си-
стем, в криптографии.
Теория информации, основанная в 1948 г. К. Шенноном, служит для по-
лучения различных методов сжатия данных. Разработанные К. Шенноном
[61, 28], Р. Фано [22], Д. А. Хаффманом [27], И. Чисаром [25], Г. Катоной [46]
алгоритмы кодирования дискретных источников существенно использовали статистику сообщений, что частично препятствовало их практическому приме-
нению.
Вопросы кодирования источников с неизвестной статистикой впервые рассматривались в работах А.Н. Колмогорова [2] и Б.М. Фитингофа [23]. В слу-
чае неизвестной статистики источника кодирование называется универсаль-
ным. Точная постановка задачи универсального кодирования принадлежит Р.Е. Кричевскому [3].
Исследованию свойств универсального кодирования также посвящены
работы Л.Д. Дэвиссона [37, 38], Т.Д. Линча [51, 52], Т. Ковера [36], Н. Фаллера
[41], Р.Г. Галлагера [45], Д. Кнута [47], |
Й.С. Виттера [64], |
Б.Я. Рябко, |
А. Н. Фионова [13-17, 58, 59], М. Борроуза |
и Д. Виллера [35], |
А. Лемпела, |
6 |
|
|
Я. Зива [67, 68], Й. Риссайнена [55-57], Ф. Уиллемса, Ю.М. Штарькова и Ч. Чокенса [31, 32, 65], В. Ф. Бабкина [62], В. К. Трофимова [19-21, 49, 50],
С. Савари [60], С. Верду [63], В.Н. Потапова [9-12]. Последним двум авторам принадлежат подробные обзорные работы.
7

Предварительные сведения
Ниже приведены основные понятия, используемые в данной работе.
Рассмотрим источник сообщений , генерирующий последовательность из букв некоторого конечного алфавита X {x1, x2,..., xk }. Последовательность должна быть закодирована и передана по каналу связи. Для решения нашей за-
дачи оптимального кодирования разобьем исходящую последовательность букв
источника на блоки (слова) фиксированной длины N .
Процедура кодирования источника заключается в том, что каждому блоку w X N ставится в соответствие некоторое кодовое слово (w) Y из букв ко-
дового алфавита Y {y1, y2,..., ym} (здесь Y обозначает множество всевозмож-
ных последовательностей из элементов множества Y ). Кодирование, при кото-
ром блокам источника ставится в соответствие кодовое слов нефиксированной длины, называется равномерным по входу.
Разные буквы кодового алфавита имеют разную длительность или, дру-
гими словами, стоимость передачи: t j t( y j ) , j 1, m . Таким образом, каждому кодовому алфавиту можно поставить в соответствие вектор длительностей букв t t1,t2 , ,tm , ( t j t( y j ) , j 1, m ). В частности, длительности кодовых
символов могут быть одинаковы, в этом случае соответствующий алфавиту
вектор обозначим через |
|
1,1, |
,1 . |
t |
|||
1 |
|
||
m
Самым популярным примером кода с неравными длительностями являет-
ся код Морзе, актуальность которого не теряется и в наше время: на основе ко-
да Морзе созданы широко используемые штрихкоды.
Длительностью кодового слова будем считать величину, равную сумме длительностей входящих в слово букв:
l w , |
|
|
t y . |
t |
|||
|
|
|
y w |
8

Стоимость кодирования определяется как отношение средней длитель-
ности кодового слова к средней длительности слова источника и в рассматри-
ваемом случае принимает следующий вид:
L N, , , t 1 p w l w , t .
N w X N
Эффективность метода кодирования : X N Y определяется избыточно-
стью:
R N, , , t L N, , , t H  C t ,
C t ,
где H – энтропия источника, определяемая законом распределения веро-
ятностей появления букв алфавита X на выходе источника , C t – про-
пускная способность канала передачи информации, зависящая только от кодо-
вого алфавита Y .
В классической работе К. Шеннона [28] были заложены основы теории кодирования, сформулированы основные понятия и получены многие базовые результаты, явившиеся опорной точкой для дальнейшего развития. Фундамен-
тальными трудами в изучаемой области являются работы А. Н. Колмогорова
[2], Р. Фано [22], Б. Фитингофа [24], Н. Абрамсона [33], Р. Г. Галлагера [1],
А. А. Маркова [8], Р. Е. Кричевского [7] и др.
9
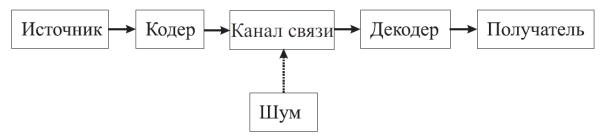
1.Канал передачи информации
1.1.Общая схема канала без шума
Дискретным каналом передачи информации называют совокупность средств, предназначенных для передачи дискретных сигналов: источник сооб-
щений – кодер – передающее устройство – декодер – получатель (рис. 1).
Рис. 1. Схема канала передачи информации.
Дискретные последовательности, состоящие из букв алфавита источника сообщений – информационных сигналов, преобразуются в кодирующем устройстве в последовательности символов кодового алфавита.
Цель кодирования информации может быть различна: шифрование с це-
лью защиты от утечки информации, сжатие с целью уменьшения объема, пре-
образование с целью защиты от помех. Точное определение кодирования будет приведено ниже. Полученные кодовые слова передаются посредством некото-
рого устройства получателю. Переданный сигнал подвергается декодированию из кодового алфавита в исходный алфавит. Рассматривается только дешифруе-
мое кодирование.
При передаче сигналов возможны помехи (шумы), сигнал при этом может подвергаться искажению. В случае отсутствия помех при передаче канал назы-
вается каналом без шума. В данной работе рассматривается задача кодирования информации с целью сжатия. В этом случае целесообразно предположить, что канал является бесшумным (рис. 2).
10