

566_Lazareva_a._JU._Kolichestvennye_metody_sotsiologicheskogo_issledovanija_
.pdf2.9.8. Двухвыборочный знаково-ранговый критерий Вилкоксона для 2-х связанных выборок
(2-related samples/ Wilcoxon)
Таблица 14. Сумма рангов и средние ранги оценок уборки подъездов и дворов
|
|
|
Sum of Ranks |
|
Разница рангов |
|
Mean Rank |
(сумма |
|
|
N |
(средний ранг) |
рангов) |
|
Negative Ranks (количество объек- |
299(a) |
266,24 |
79607,00 |
|
тов с отрицательным рангом) |
||||
|
|
|
||
Positive Ranks (количество объектов |
215(b) |
245,34 |
52748,00 |
|
с положительным рангом) |
||||
|
|
|
||
Ties (количество объектов со свя- |
567(c) |
- |
- |
|
занными рангами) |
||||
|
|
|
||
ВСЕГО |
1081 |
- |
- |
а - уборка подъезда < уборка двора, b - уборка подъезда > уборка двора, c - уборка подъезда = уборка двора
Таблица 15. Статистика теста
Статистика |
Значение |
|
|
|
|
Z |
-4,160(a) |
|
|
|
|
Asymp. Sig. (2-tailed) (двухсторонняя зна- |
0,000 |
|
чимость) |
||
|
||
|
|
aBased on positive ranks. (Основан на положительных рангах.)
2.9.9.Ранговый дисперсионный анализ – критерий Фридмана для k-
связанных выборок
(k-related samples/ Friedman)
Ранговый дисперсионный анализ Фридмана позволяет сравнивать средние ранги в нескольких (3-х и более) связанных выборках. Пример: для людей трудоспособного возраста, имеющих детей младше 18 лет, требуется сравнить их оценки отдельных показателей социальной защищенности: степени уверенности в правовой защищенности, стабильности работы и уверенности в будущем детей. Оценка давалась по 3-х балльной шкале, где 1 – полностью не уверен. В табл. 16 и 17 отражены результаты тестирования (средние ранги и статистика теста).
41
Таблица 16. Средний ранг
Оценка социальной за- |
Mean Rank |
|
(Средний |
||
щищенности |
||
ранг) |
||
|
||
Я уверен, что все мои |
1,74 |
|
права защищены |
||
|
||
У меня стабильная рабо- |
2,29 |
|
та, и мне не грозит ее |
||
потерять |
|
|
Я уверен в будущем сво- |
1,97 |
|
их детей |
||
|
Таблица 17. Статистика теста
N |
502 |
|
Chi-Square (Хи-квадрат) |
146,597 |
|
Df (Число степеней свобо- |
2 |
|
ды) |
||
|
||
Asymp. Sig. (уровень зна- |
0,000 |
|
чимости) |
||
|
2.10. Простая линейная регрессия
(Процедура REGRESSION/ LINEAR)
В программе SPSS есть возможность построения как простой, так и множественной модели линейной регрессии. В предлагаемом примере простой линейной регрессии используются данные агрегированного файла (объекты – районы г. Новосибирска). Зависимый признак – доля людей в районе, негативно оценивающих свое будущее. Независимый признак – доля людей в районе в возрасте от 45 лет и старше. В табл. 1 отражено распределение признаков по районам проживания. Информация табл. 2 полезна для выводов о качестве полученной модели. Для этой же цели полезно изучить распределение остатков. В табл. 3 представлены результаты однофакторного дисперсионного анализа реализуемого для проверки гипотезы о равенстве всех регрессионных коэффициентов нулю (этот тест полезен при построении множественной линейно регрессии). Табл. 4 содержит значения регрессионных коэффициентов и значения t- статистик. На рис. 1 отражено распределение объектов в пространстве зависимого и независимого признаков, а также обозначены границы 95% доверительного интервала для среднего и для модельных значений.
Таблица 1. Доля людей старше 45 лет и доля людей, негативно оценивающих будущее в районах города
Район |
Доля людей 45 лет и |
Доля людей, негативно оцени- |
|
старше |
вающих свое будущее |
||
|
|||
|
|
|
|
Дзержинский |
0,483 |
0,372 |
|
Железнодорожный |
0,521 |
0,309 |
|
Заельцовский |
0,492 |
0,303 |
|
Калининский |
0,453 |
0,214 |
|
Кировский |
0,521 |
0,374 |
|
Ленинский |
0,491 |
0,28 |
|
Октябрьский |
0,444 |
0,241 |
|
Первомайский |
0,606 |
0,365 |
|
Советский |
0,474 |
0,245 |
|
Центральный |
0,569 |
0,327 |
42
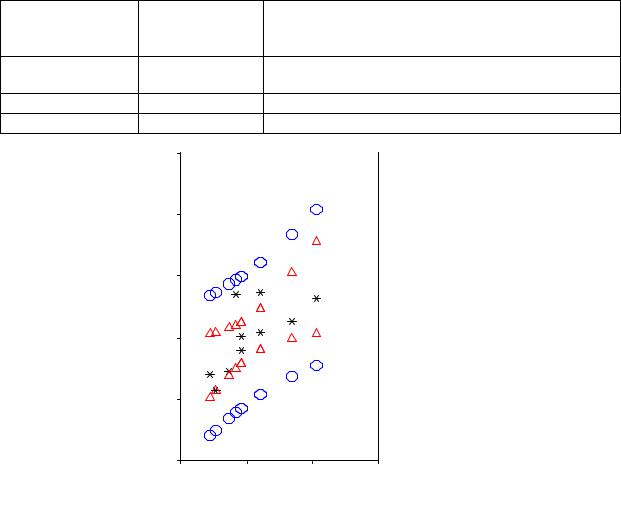
Таблица 2. Коэффициенты корреляции и детерминации
|
R |
R Square |
Adjusted R Square |
Std. Error of |
Durbin- |
|
(коэффици- |
(коэффициент |
(скорректирован- |
the Estimate |
Watson (ко- |
Model |
ент корре- |
детермина- |
ный коэффициент |
(стандартная |
эффициент |
|
ляции) |
ции) |
детерминации) |
ошибка оцен- |
Дурбина- |
|
|
|
|
ки) |
Уотсона) |
1 |
0,689(a) |
0,474 |
0,409 |
0,0441 |
1,847 |
aPredictors (независимая переменная): доля людей старше 45 лет и старше
bDependent Variable (зависимая переменная): доля людей, негативно оценивающих будущее
Таблица 3. Однофакторный дисперсионный анализ
Sum of Squares
Модель (сумма квадратов)
Regression |
0,014 |
|
(модель) |
||
|
||
Residual (остатки) |
0,016 |
|
ВСЕГО |
0,030 |
|
|
,6 |
|
будущее |
,5 |
|
оценивающих |
,4 |
|
|
||
отр. |
,3 |
|
|
||
в районе |
,2 |
|
Доля людей |
||
,1 |
,4 ,5
|
Mean Square |
F- |
Sig. |
|
df |
(средний квад- |
стати- |
||
(Значимость) |
||||
|
рат) |
стика |
||
|
|
|||
1 |
0,014 |
7,221 |
0,028(a) |
|
8 |
0,002 |
- |
- |
|
9 |
- |
- |
- |
 район
район
 95% ВГ ДИ предсказ
95% ВГ ДИ предсказ
 95% НГ ДИ предсказ
95% НГ ДИ предсказ
 95% ВХ ДИ среднего
95% ВХ ДИ среднего
 95% НГ ДИ среднего
95% НГ ДИ среднего
,6 ,7
Доля людей в районе 45 лет и старше
Рис 1. Расположение районов в пространстве исследуемых признаков – «доля жителей 45 лет и старше» и «доля людей, негативно оценивающих свое будущее» (также на рисунке представлены доверительные интервалы предсказания и среднего предсказания)
43
Таблица 4. Коэффициенты регрессионной модели
|
|
|
Стандартизованные |
t |
Sig. |
|
|
Нестандартизованные |
коэффициенты |
||||
Коэффици- |
коэффициенты |
Standardized |
стати- |
(Значи- |
||
енты модели |
Unstandardized Coefficients |
Coefficients |
стика |
мость) |
||
|
B |
Std. Error |
Beta |
|
|
|
|
|
|
|
|
|
|
Константа |
-0,093 |
0,148 |
- |
-0,628 |
0,547 |
|
доля людей |
0,783 |
0,291 |
0,689 |
2,987 |
0,028 |
|
старше 45 |
||||||
|
|
|
|
|
||
|
|
|
|
|
|
|
2.11. Факторный анализ/ Метод главных компонент
(Процедура DATA REDUCTION/ FACTOR/ PRINCIPAL COMPONENTS)
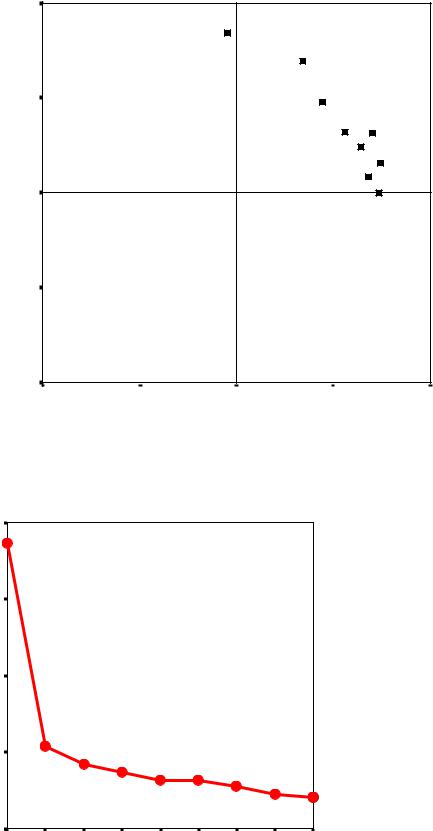
Одним из методов свертывания признакового пространства является метод главных компонент. Пример: исходные признаки – характеристики восприятия Новосибирска, полученные с помощью метода семантического дифференциала (1 – «отрицательный» полюс, 5 – «положительный»). Табл. 1 содержит коэффициенты корреляции для каждой пары исходных признаков. Некоторую информацию о качестве модели Вы можете получить, проанализировав статистики КМО и Бартлетта (табл. 2). Значения начальных и модельных общностей дают представление о доли дисперсии исходных признаков, объясненной моделью (табл. 3). Табл. 4 содержит данные об общей дисперсии, собственных значениях факторов и о количестве выделенных главных компонент. Табл. 6 является основанием для интерпретации полученных факторов (новых признаков). В табл. 5 приведены факторные нагрузки до вращения, что объясняет их меньшую контрастность. На рис. 1 представлено размещение исходных признаков в пространстве главных компонент. Рис. 2 является дополнительным основанием для принятия решения о количестве главных компонент (критерий «каменистой осыпи»). Значения новых признаков могут быть рассчитаны с помощью коэффициентов значений факторов (табл. 7). Однако процедура дает возможность автоматического сохранения новых признаков и их значений.
Таблица 1. Корреляционная матрица исходных признаков (Correlation Matrix)
Характеристики города |
проблемный благополучный |
невзрачный красивый |
холодный гостеприимный |
отсталый развитый |
старомодный современный |
неухоженный благоустроенный |
заурядный уникальный |
дорогой доступный |
бескультурный культурный |
|
|||||||||
|
|
|
|
|
|
|
|
|
|
проблемный/ |
1,00 |
0,41 |
0,38 |
0,36 |
0,25 |
0,32 |
0,36 |
0,36 |
0,28 |
благополучный |
|||||||||
невзрачный/красивый |
0,41 |
1,00 |
0,48 |
0,44 |
0,42 |
0,48 |
0,44 |
0,17 |
0,39 |
холодный/гостеприимный |
0,38 |
0,48 |
1,00 |
0,39 |
0,35 |
0,31 |
0,33 |
0,15 |
0,41 |
отсталый/развитый |
0,36 |
0,44 |
0,39 |
1,00 |
0,57 |
0,37 |
0,32 |
0,20 |
0,42 |
44
Характеристики города |
проблемный благополучный |
невзрачный красивый |
холодныйгостеприимный |
отсталыйразвитый |
старомодный современный |
неухоженныйблагоустроенный |
заурядный уникальный |
дорогой доступный |
бескультурный культурный |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
старомодный/современный |
0,25 |
0,42 |
0,35 |
0,57 |
1,00 |
0,32 |
0,25 |
0,13 |
0,33 |
неухоженный/ |
0,32 |
0,48 |
0,31 |
0,37 |
0,32 |
1,00 |
0,36 |
0,19 |
0,34 |
благоустроенный |
|||||||||
заурядный/ уникальный |
0,36 |
0,44 |
0,33 |
0,32 |
0,25 |
0,36 |
1,00 |
0,22 |
0,31 |
дорогой/ доступный |
0,36 |
0,17 |
0,15 |
0,20 |
0,13 |
0,19 |
0,22 |
1,00 |
0,11 |
бескультурный/ культурный |
0,28 |
0,39 |
0,41 |
0,42 |
0,33 |
0,34 |
0,31 |
0,11 |
1,00 |
Таблица 2. Статистика KMO и статистика Бартлетта
KMO |
|
0,865 |
|
Критерий адекватности выборки Кайзера-Мейера-Олкина |
|||
|
|||
Bartlett's Test of Sphericity |
Approx. Chi-Square (Хи-квадрат) |
1866,375 |
|
(Тест сферичности Бартлетта) |
df (Число степеней свободы) |
36 |
|
Sig. (уровень значимости) |
0,000 |
||
|
|||
|
|
|
|
Таблица 3. Общности (Communalities)
Исходные признаки |
Начальные общности |
Модельные общности |
|
Initial |
Extraction |
||
|
|||
|
|
|
|
проблемный/благополучный |
1,000 |
0,598 |
|
невзрачный/красивый |
1,000 |
0,584 |
|
холодный/гостеприимный |
1,000 |
0,466 |
|
отсталый/развитый |
1,000 |
0,574 |
|
старомодный/современный |
1,000 |
0,542 |
|
неухоженный/ благоустроенный |
1,000 |
0,417 |
|
заурядный/ уникальный |
1,000 |
0,421 |
|
дорогой/ доступный |
1,000 |
0,715 |
|
бескультурный/ культурный |
1,000 |
0,474 |
45
Таблица 4. Общая объясненная дисперсия (Total Variance Explained)
компоненты |
|
|
|
|
|
Сумма квадратов нагрузок |
Сумма квадратов нагрузок |
||||
Собственные значения |
для выделенных факторов |
для выделенных факторов |
|||||||||
|
|
|
|
|
|
(до вращения) |
(после вращения) |
||||
|
Initial Eigenvalues |
|
Extraction Sums of Squared |
Rotation Sums of Squared |
|||||||
|
|
|
|
|
|
Loadings |
|
Loadings |
|||
|
|
|
|
|
|
|
|
||||
|
|
|
% of |
Cumulative |
|
% of |
Cumulative |
|
% of |
Cumulative |
|
|
Total |
|
Variance |
|
% |
Total |
Variance |
% |
Total |
Variance |
% |
1 |
3,72 |
|
41,33 |
|
41,33 |
3,72 |
41,33 |
41,33 |
3,08 |
34,22 |
34,22 |
2 |
1,07 |
|
11,91 |
|
53,24 |
1,07 |
11,91 |
53,24 |
1,71 |
19,02 |
53,24 |
3 |
0,83 |
|
9,27 |
|
62,50 |
|
|
|
|
|
|
4 |
0,73 |
|
8,07 |
|
70,57 |
|
|
|
|
|
|
5 |
0,63 |
|
7,04 |
|
77,61 |
|
|
|
|
|
|
6 |
0,62 |
|
6,94 |
|
84,56 |
|
|
|
|
|
|
7 |
0,54 |
|
6,04 |
|
90,60 |
|
|
|
|
|
|
8 |
0,44 |
|
4,93 |
|
95,53 |
|
|
|
|
|
|
9 |
0,40 |
|
4,47 |
|
100,00 |
|
|
|
|
|
|
Extraction Method: Principal Component Analysis. (Метод извлечения факторов: метод главных компонент.)
Таблица 5. Факторные нагрузки (Component Matrix)
Исходные признаки |
Component (главные компоненты) |
||
1 |
|
2 |
|
|
|
||
невзрачный/ красивый |
|
0,761 |
-0,072 |
отсталый/ развитый |
|
0,723 |
-0,226 |
холодный/ гостеприимный |
|
0,675 |
-0,103 |
неухоженный/ благоустроенный |
|
0,646 |
0,003 |
старомодный/ современный |
|
0,642 |
-0,360 |
проблемный/ благополучный |
|
0,638 |
0,438 |
бескультурный/ культурный |
|
0,636 |
-0,264 |
заурядный/ уникальный |
|
0,619 |
0,197 |
дорогой/ доступный |
|
0,374 |
0,759 |
Extraction Method: Principal Component Analysis. (Метод извлечения факторов: метод главных компонент.)
Таблица 6. Факторные нагрузки после вращения (Rotated Component Matrix)
Исходные признаки |
Component (главные компоненты) |
||
1 |
|
2 |
|
|
|
||
отсталый/ развитый |
|
0,741 |
0,159 |
старомодный/ современный |
|
0,736 |
0,002 |
невзрачный/ красивый |
|
0,698 |
0,311 |
бескультурный/ культурный |
|
0,683 |
0,083 |
холодный/ гостеприимный |
|
0,638 |
0,242 |
неухоженный/ благоустроенный |
|
0,561 |
0,320 |
дорогой/ доступный |
|
-0,048 |
0,844 |
проблемный/ благополучный |
|
0,340 |
0,695 |
заурядный/ уникальный |
|
0,442 |
0,476 |
Метод вращения – Варимакс. |
|
|
|
46
Главная компонента 2
1,0
дорогой доступный проблемный благополу
заурядный уникальный
,5
неухоженный благоукрасивыйт невзрачный
холодный гостеприимн
отсталый развитый бескультурный культу
старомодный современ
0,0
-,5
-1,0
-1,0 |
-,5 |
0,0 |
,5 |
1,0 |
Главная компонента 1 |
|
|
|
|
Рис.1. Исходные признаки в пространстве главных компонент (после вращения)
|
4 |
|
|
|
|
|
|
|
|
|
3 |
|
|
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
|
|
значения |
1 |
|
|
|
|
|
|
|
|
Собственные |
0 |
|
|
|
|
|
|
|
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
Номер компоненты |
|
|
|
|
|
|
||
Рис. 2. График «осыпь»
47

Таблица7. Коэффициенты значенийфактора(ComponentScoreCoefficientMatrix)
Исходные признаки |
Главные компоненты (Component) |
||
1 |
|
2 |
|
|
|
||
проблемный благополучный |
|
-0,052 |
0,440 |
|
|
|
|
невзрачный красивый |
|
0,211 |
0,042 |
|
|
|
|
холодный гостеприимный |
|
0,205 |
0,006 |
|
|
|
|
отсталый развитый |
|
0,273 |
-0,088 |
|
|
|
|
старомодный современный |
|
0,315 |
-0,207 |
|
|
|
|
неухоженный благоустроенный |
|
0,150 |
0,088 |
|
|
|
|
заурядный уникальный |
|
0,054 |
0,242 |
|
|
|
|
дорогой доступный |
|
-0,260 |
0,666 |
|
|
|
|
бескультурный культурный |
|
0,270 |
-0,130 |
|
|
|
|
2.12. Иерархический кластерный анализ
(Процедура CLASSIFY/ HIERARCHICAL CLUSTER)
Иерархический кластерный анализ позволяет осуществлять классификацию объектов количеством меньшим 100 (табл. 1). Преимуществом метода является возможность задания диапазона кластерных решений, что позволяет выбрать наиболее предпочтительный вариант. В пакете предусмотрено получение таблицы объединения (табл. 2), которая дает основания для выбора оптимального количества кластеров на основе анализа коэффициентов на разных шагах объединения. Визуальное представление процедуры можно получить, построив дендрограмму классификации (рис.1).
Пример: группирующие признаки получены на основе факторизации переменных, отражающих степень неудовлетворенности отдельными аспектами жизнедеятельности в районе: неудовлетворенность состоянием социальной сферы и неудовлетворенность развитием инфраструктуры.
Таблица 1. Общая информация об объектах (Case Processing Summary)
Cases
Valid |
Missing |
|
Total |
|||
|
|
|
|
|
|
|
N |
Percent |
N |
Percent |
N |
|
Percent |
|
|
|
|
|
|
|
41 |
35,3 |
75 |
64,7 |
116 |
|
100,0 |
|
|
|
|
|
|
|
aSquared Euclidean Distance used (Мера расстояния – квадрат евклидова расстояния)
bAverage Linkage (Between Groups) (Метод объединения – среднее межгрупповое значение расстояния)
48
Таблица 2. Таблица объединения (Agglomeration Schedule), фрагмент
|
|
|
|
|
|
|
Coefficients |
Stage Cluster First |
Next Stage |
|||
Stage |
Cluster Combined |
|
Коэффици- |
Appears |
Следую- |
|||||||
Шаг |
|
|
|
|
|
|
енты |
Шаг первого появ- |
щий шаг |
|||
|
|
|
|
|
|
|
|
|
|
ления кластера |
|
|
|
Cluster 1 |
Cluster 2 |
|
|
|
|
Cluster 1 |
Cluster 2 |
|
|||
|
Кластер |
|
Кластер |
|
|
|
|
Кластер |
Кластер |
|
||
|
1 |
|
|
|
2 |
|
|
|
|
1 |
2 |
|
1 |
|
885 |
|
|
974 |
|
|
|
,000 |
0 |
0 |
2 |
2 |
|
513 |
|
|
885 |
|
|
|
,000 |
0 |
1 |
11 |
3 |
|
259 |
|
|
770 |
|
|
|
,000 |
0 |
0 |
11 |
… |
|
… |
|
|
… |
|
|
|
… |
… |
… |
… |
38 |
|
9 |
|
|
264 |
|
|
|
3,395 |
31 |
36 |
39 |
39 |
|
9 |
|
|
13 |
|
|
|
4,157 |
38 |
37 |
40 |
40 |
|
9 |
|
|
586 |
|
|
|
9,716 |
39 |
35 |
0 |
C A S E |
0 |
|
|
5 |
|
10 |
|
15 |
20 |
25 |
|
|
Label Num +---------+---------+---------+---------+---------+ |
|
|||||||||||
|
885 |
|
|
|
|
|
|
|
|
|
|
|
|
974 |
|
|
|
|
|
|
|
|
|
|
|
|
513 |
|
|
|
|
|
|
|
|
|
|
|
|
259 |
|
|
|
|
|
|
|
|
|
||
|
770 |
|
|
|
|
|
|
|
|
|
||
|
256 |
|
|
|
|
|
|
|
|
|
||
|
9 |
|
|
|
|
|
|
|
|
|
||
|
68 |
|
|
|
|
|
|
|
||||
|
37 |
|
|
|
|
|
|
|
|
|
|
|
|
550 |
|
|
|
|
|
|
|
|
|
|
|
|
652 |
|
|
|
|
|
|
|
|
|
||
|
77 |
|
|
|
|
|
|
|
|
|
|
|
|
510 |
|
|
|
|
|
|
|
|
|
|
|
|
545 |
|
|
|
|
|
|
|||||
|
589 |
|
|
|
|
|
|
|
||||
|
365 |
|
|
|
|
|
|
|
|
|
||
|
495 |
|
|
|
|
|
|
|
||||
|
297 |
|
|
|
|
|
|
|
|
|
||
|
264 |
|
|
|
|
|
|
|
|
|
|
|
|
452 |
|
|
|
|
|
|
|
|
|
||
|
272 |
|
|
|
|
|
|
|||||
|
291 |
|
|
|
|
|
|
|
|
|
|
|
|
441 |
|
|
|
|
|
|
|
|
|
|
|
|
893 |
|
|
|
|
|
|
|
|
|
|
|
|
816 |
|
|
|
|
|
|
|
|
|
||
|
880 |
|
|
|
|
|
|
|
|
|
||
|
79 |
|
|
|
|
|
|
|
|
|||
|
620 |
|
|
|
|
|
|
|
|
|||
|
129 |
|
|
|
|
|
|
|
|
|
||
|
273 |
|
|
|
|
|
||||||
|
619 |
|
|
|
|
|
|
|
|
|
|
|
|
383 |
|
|
|
|
|
|
|
|
|
||
|
792 |
|
|
|
|
|
|
|
|
|||
|
607 |
|
|
|
|
|
|
|
|
|||
|
1059 |
|
|
|
|
|
|
|
||||
|
796 |
|
|
|
|
|
|
|
|
|
|
|
|
13 |
|
|
|
|
|
|
|
|
|
||
|
598 |
|
|
|
|
|
|
|
|
|
|
|
|
727 |
|
|
|
|
|
|
|
||||
|
726 |
|
|
|
|
|||||||
|
586 |
|
|
|
|
|
|
|
||||
Рис. 1. Дендрограмма классификации
49
2.13. Быстрый кластерный анализ
(Процедура CLASSIFY/ K-means)
В отличие от иерархического кластерного анализа, с помощью метода К- средних можно осуществлять группировку большого количества объектов. Однако процедура требует задания желаемого количества таксономий. Поэтому исследователи часто используют эти два метода кластеризации в паре. Первые пять таблиц получены для двухкластерной модели, таблицы с 6 по 8 – для трехкластерного решения. Данные таблицы 9 позволяют оценить устойчивость первого решения. В табл. 1 выделены значения признаков, ставших начальными кластерными центрами. В табл. 2 отражены изменения координат. Итоговые значения центров представлены в табл. 3 и для трехкластерного решения в табл. 6. Дисперсионный анализ дает «условные» основания для проверки гипотезы о различии полученных кластеров по выделенным критериям (табл. 4 и 7). В табл. 5 содержится информация о наполненности полученных групп (в табл. 8 для трехкластерного решения). На рис. 1 и 2 представлено пространственное распределение объектов в случае двухкластерного и трехкластерного решения.
Двухкластерное решение
Таблица 1. Начальные кластерные центры (Initial Cluster Centers)
Основания классификации (группирующие признаки) |
Cluster (Кластер) |
|||
1 |
2 |
|||
|
|
|||
REGR factor score 1 for analysis |
2 |
1,37133 |
-1,76275 |
|
(неудовлетворенность состоянием социальной сфе- |
||||
ры) |
|
|
|
|
REGR factor score 2 for analysis |
2 |
2,41893 |
-0,99960 |
|
(неудовлетворенность развитием инфраструктуры) |
||||
|
|
|||
Таблица 2. История изменения кластерных центров (Iteration History)
Iteration |
Change in Cluster Centers |
|
|||
(Изменения в кластерных центрах) |
|||||
Итерация |
|||||
|
1 |
|
2 |
|
|
|
|
|
|
|
|
1 |
|
1,704 |
|
1,519 |
|
|
|
|
|
|
|
2 |
|
0,085 |
|
0,066 |
|
|
|
|
|
|
|
3 |
|
0,042 |
|
0,029 |
|
|
|
|
|
|
|
4 |
|
0,000 |
|
0,000 |
|
|
|
|
|
|
|
50