

566_Lazareva_a._JU._Kolichestvennye_metody_sotsiologicheskogo_issledovanija_
.pdfТаблица 3. Статистика связи (Chi-Square Tests)
|
|
df |
Asymp. Sig. (2-sided) |
|
|
Value (зна- |
эмпирический уровень |
||
Статистика |
(степень |
|||
чение) |
значимости (двухсто- |
|||
|
свободы) |
|||
|
|
ронний) |
||
|
|
|
||
|
|
|
|
|
Pearson Chi-Square (Хи-квадрат Пир- |
206,21 |
6 |
0,000 |
|
сона) |
||||
|
|
|
||
|
|
|
|
|
Likelihood Ratio (отношение правдо- |
215,23 |
6 |
0,000 |
|
подобия) |
||||
|
|
|
||
|
|
|
|
В таблице нет ячеек, в которых ожидаемая частота менее 5 объектов. Минимальная ожидаемая частота 28,44
Таблица 4. Симметричные меры связи (Symmetric Measures)
|
|
Value (Ве- |
Asymp. Std. |
Ap- |
Approx. Sig. |
|
|
Статистика |
Error |
prox. |
(Уровень зна- |
||
|
личина) |
(Стандарт- |
||||
|
|
T(b) |
чимости) |
|||
|
|
|
ная ошибка) |
|
|
|
Nominal by |
Phi (фи-коэффициент) |
0,423 |
- |
- |
0,000 |
|
Nominal |
|
|
|
|
|
|
(две номин. |
Cramer's V (V Крамера) |
|
|
|
|
|
|
|
|
|
|
||
перемен- |
|
0,299 |
- |
- |
0,000 |
|
ные) |
|
|||||
|
|
|
|
|
||
|
|
|
|
|
|
|
Ordinal by |
Kendall's tau-b (Тау-в |
0,363 |
0,023 |
15,78 |
0,000 |
|
Ordinal |
Кендалла) |
|||||
|
|
|
|
|||
(две ранго- |
|
|
|
|
|
|
Kendall's tau-c (Тау-с |
0,361 |
0,023 |
15,78 |
0,000 |
||
вые пере- |
Кендалла) |
|||||
|
|
|
|
|||
менные) |
|
|
|
|
|
|
|
Spearman Correlation |
|
|
|
|
|
|
(коэф-т корреляции |
0,407 |
0,025 |
15,14 |
0,000 |
|
|
Спирмена) |
|||||
|
|
|
|
|
||
|
|
|
|
|
|
21
2.5. Исследование данных
(Процедура EXPLORE)
Процедура EXPLORE позволяет получать описательные статистики выборочного распределения количественного признака, часть из них представлена в табл. 1. В табл. 2 представлены результаты теста Колмогорова-Смирнова. Рис. 1 – 4 полезны для «визуального» анализа распределения признака.
Таблица 1.Описательные статистики распределения признака «возраст» (фрагмент)
|
|
|
|
Std. Error (стан- |
Пол |
|
Статистика |
Statistic |
дартная ошибка |
|
|
|
(значение) |
статистики) |
муж- |
Mean (среднее) |
|
43,05 |
0,815 |
ской |
95% Confidence |
Lower Bound (нижняя гра- |
41,45 |
- |
|
Interval for Mean |
ница 95% доверительного |
||
|
|
интервала среднего) |
|
|
|
|
Upper Bound (верхняя гра- |
44,65 |
- |
|
|
ница …) |
||
|
|
|
|
|
|
Median (медиана) |
|
43,00 |
- |
|
Variance (разброс, дисперсия) |
298,255 |
- |
|
|
Std. Deviation (стандартное отклонение) |
17,270 |
- |
|
|
Skewness (скошенность) |
0,209 |
0,115 |
|
|
Kurtosis (пикообразность) |
-1,125 |
0,230 |
|
жен- |
Mean |
|
45,80 |
0,625 |
ский |
95% Confidence |
Lower Bound |
44,57 |
- |
|
Interval for Mean |
|
||
|
|
|
|
|
|
|
Upper Bound |
47,02 |
- |
|
Median |
|
47,00 |
- |
|
Variance |
|
283,307 |
- |
|
Std. Deviation |
|
16,832 |
- |
|
Skewness |
|
0,007 |
0,091 |
|
Kurtosis |
|
-1,144 |
0,181 |
Таблица 2. Тест Колмогорова-Смирнова: проверка нормальности выборочного распределения признака «возраст» (Tests of Normality)
|
Kolmogorov-Smirnov |
|||
|
значение |
степень |
эмпирический уро- |
|
|
статистики |
|||
|
свободы |
вень значимости |
||
Пол |
Statistic |
|||
df |
Sig. |
|||
|
|
|||
|
|
|
|
|
м |
0,096 |
449 |
0,000 |
|
|
|
|
|
|
ж |
0,085 |
726 |
0,000 |
|
|
|
|
|
|
22
2.6. Операции с файлами данных
(Процедура DATA)
Меню DATA содержит различные возможности для преобразования массива данных. На практике часто используется процедура агрегирования данных, заключающаяся в укрупнении объектов анализа. Последовательность шагов этого процесса представлена на рис. 1 – 4.
В табл. 1 отражены результаты «ремонта выборки» с помощью весовых коэффициентов.
2.6.1. Агрегирование данных
(Aggregate)
Рис. 1. Исходный массив (объекты – респонденты)
Рис. 2. Процедура Aggregate 23
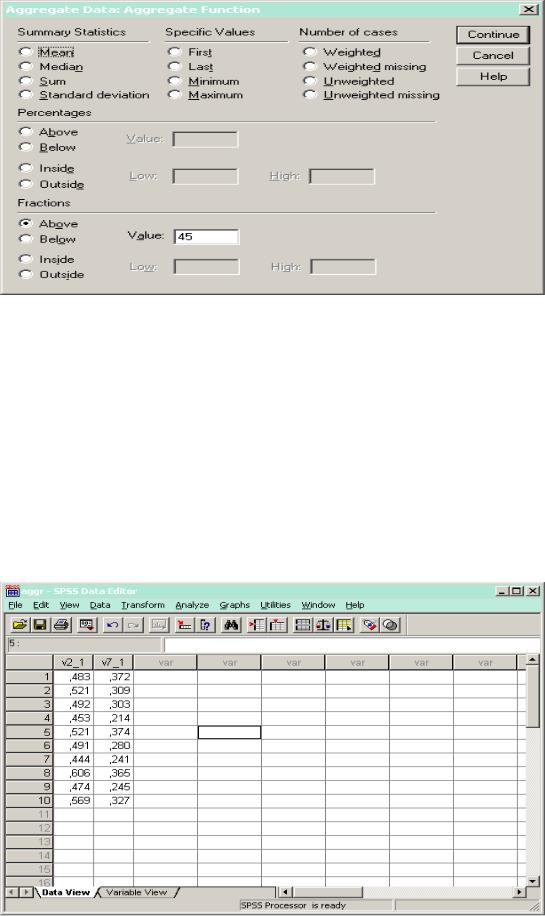
Рис. 3. Создание новых (агрегированных) переменных
Per. above – процент объектов, у которых переменная принимает значения большие указанного (включительно).
Per. below – процент объектов, у которых переменная принимает значения меньшие указанного (включительно).
Frac. above – доля объектов, у которых переменная принимает значения большие указанного (включительно).
Frac. below – доля объектов, у которых переменная принимает значения меньшие указанного (включительно).
Per. inside – процент объектов, у которых значение переменной находится в указанном интервале (интервал закрытый).
Рис. 4. Агрегированный массив данных
24
2.6.2. Процедура взвешивания данных
(Weight cases)
Таблица 1. Структура выборки до и после взвешивания
|
Структура до |
Структура |
Весовой |
Структура |
|
Район |
генеральной |
после взвеши- |
|||
взвешивания |
коэффициент |
||||
|
совокупности |
вания |
|||
Дзержинский |
10,2 |
11,0 |
1,1 |
11,3 |
|
|
|
|
|
|
|
Железнодорожный |
8,0 |
4,4 |
0,6 |
4,8 |
|
|
|
|
|
|
|
Заельцовский |
10,4 |
9,7 |
0,9 |
9,4 |
|
|
|
|
|
|
|
Калининский |
10,0 |
12,2 |
1,2 |
12,0 |
|
|
|
|
|
|
|
Кировский |
10,0 |
11,9 |
1,2 |
12,0 |
|
|
|
|
|
|
|
Ленинский |
14,7 |
19,2 |
1,3 |
19,3 |
|
|
|
|
|
|
|
Октябрьский |
10,0 |
12,4 |
1,2 |
12,0 |
|
|
|
|
|
|
|
Первомайский |
8,4 |
5,0 |
0,6 |
5,1 |
|
|
|
|
|
|
|
Советский |
9,7 |
9,2 |
0,9 |
8,8 |
|
|
|
|
|
|
|
Центральный |
8,7 |
5,1 |
0,6 |
5,2 |
|
|
|
|
|
|
|
ВСЕГО |
100,0 |
100,0 |
- |
100,0 |
|
|
|
|
|
|
2.7. Коэффициенты корреляции
(Процедура CORRELATE)
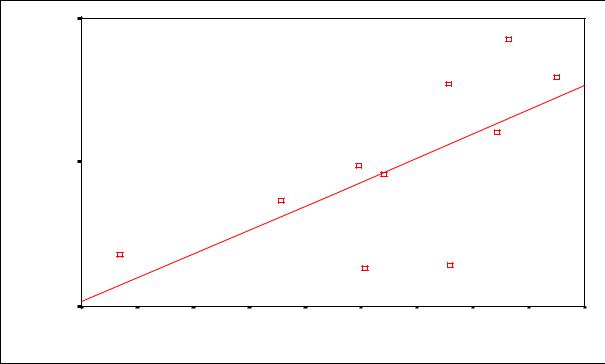
Коэффициенты ранговой корреляции, а также коэффициенты корреляции Пирсона можно получить с помощью процедуры Correlate. В табл. 1 представлены результаты расчета коэффициента парной корреляции для интервальных признаков, полученных в процессе агрегирования исходного массива данных (объект – район проживания). На рис. 1 отражено расположение объектов (районов) в пространстве исследуемых признаков с наложением линии регрессии, построенной методом наименьших квадратов. Процедура дает возможность расчета частной корреляции (табл. 2).
25
2.7.1. Парная корреляция
(Bivariate)
Таблица 1. Коэффициент корреляции Пирсона
|
|
|
Доля людей, нега- |
Доля людей |
|
Статистика |
старше 45 лет |
||
|
|
|
тивно оцениваю- |
(45 лет – сред- |
|
|
|
щих свое будущее |
|
|
|
|
|
нее) |
Доля людей, нега- |
|
Pearson Correlation (коэф- |
1 |
0,662(*) |
тивно оцениваю- |
|
фициент корреляции Пир- |
||
щих свое будущее |
|
сона) |
|
|
|
Sig. (2-tailed) (двухсторон- |
- |
0,037 |
|
|
|
|||
|
|
ний уровень значимости) |
||
|
|
|
|
|
|
|
N (количество объектов) |
10 |
10 |
Доля людей стар- |
|
Pearson Correlation |
0,662(*) |
1 |
ше 45 лет |
|
Sig. (2-tailed) |
0,037 |
- |
|
|
N |
10 |
10 |
Correlation is significant at the 0.05 level (2-tailed) [Корреляция значима на 5% уровне (2- |
||||||||||
сторонний ДИ)] |
|
|
|
|
|
|
|
|
|
|
|
,8 |
|
|
|
|
|
|
Калининский |
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
Советский |
Октябрьский |
||
|
|
|
|
|
|
|
|
|
||
будущее |
|
|
|
|
|
|
|
Ленинский |
|
|
,7 |
|
|
|
|
Заельцовский |
|
|
|
|
|
оценивающих |
|
|
|
|
Железнодорожный |
|
|
|
||
|
|
|
Центральный |
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
долянегативно |
Первомайский |
|
|
|
|
Дзержинский |
|
|
||
|
|
|
|
|
Кировский |
|
|
|||
|
|
|
|
|
|
|
|
|
||
,6 |
|
|
|
|
|
|
|
|
|
|
|
,36 |
,38 |
,40 |
,42 |
,44 |
,46 |
,48 |
,50 |
,52 |
,54 |
|
доля людей в возрасте старше 45 лет |
|
|
|
|
|
||||
Рис. 1. Расположением районов в пространстве исследуемых признаков с наложением |
||||||||||
|
|
|
|
регрессионной прямой |
|
|
|
|
||
26
2.7.2. Частная корреляция
(Partial)
Таблица 2. Коэффициенты частной корреляции (контролирующая переменная – доля людей в районе, имеющих среднее образование и ниже)
|
Доля людей в районе |
Доля людей в районе, |
|
|
негативно оценивающих |
||
|
в возрасте 45 лет и старше |
||
|
будущее |
||
|
|
||
Доля людей в районе |
1,000 |
0,7220 |
|
(7) |
|||
в возрасте 45 лет и старше |
(0) |
||
р = 0,028 |
|||
|
|
||
Доля людей в районе, |
0,7220 |
1,000 |
|
негативно оценивающих |
(7) |
||
(0) |
|||
будущее |
р = 0,028 |
||
|
2.8. Параметрические методы – сравнение средних
(Процедура COMPARE MEANS)
Параметрические тесты для несвязанных, связанных выборок, а также одновыборочные тесты в программе SPSS реализованы в процедуре Compare means. Кроме того, в этом блоке предусмотрена возможность получения описательных статистик распределения исследуемого признака (например, признака «количество полных лет», как представлено в табл. 1 и 2) и тест КолмогороваСмирнова для проверки совпадения выборочного распределения с нормальным
(табл. 3).
Процедура MEANS
Таблица 1. Описательные статистики
|
Mean |
N |
Std. Deviation |
Std. Error of |
|
|
Mean (стан- |
||||
Район |
(сред- |
(количество |
(стандартное от- |
||
дартная ошибка |
|||||
|
нее) |
объектов) |
клонение) |
среднего) |
|
|
|
|
|
||
Дзержинский |
44,76 |
120 |
17,950 |
1,639 |
|
Железнодорожный |
45,30 |
94 |
17,546 |
1,810 |
|
Заельцовский |
45,09 |
122 |
17,416 |
1,577 |
|
Калининский |
43,96 |
117 |
16,992 |
1,571 |
|
Кировский |
45,81 |
117 |
16,403 |
1,516 |
|
Ленинский |
43,50 |
173 |
16,643 |
1,265 |
|
Октябрьский |
42,29 |
117 |
17,384 |
1,607 |
|
Первомайский |
46,63 |
99 |
16,608 |
1,669 |
|
Советский |
44,41 |
114 |
16,630 |
1,558 |
|
Центральный |
46,97 |
102 |
17,139 |
1,697 |
|
Всего |
44,75 |
1175 |
17,046 |
0,497 |
27

Таблица 2. Статистики распределения признака «возраст»
|
Statistic (Зна- |
Std. Error |
|
Статистка |
(Стандартная |
||
|
чение) |
ошибка) |
|
|
|
||
Mean (Средняя) |
44,75 |
0,497 |
|
Variance (Дисперсия) |
290,557 |
- |
|
Std. Deviation |
17,046 |
- |
|
(Стандартное отклонение) |
|||
|
|
||
Skewness (Скошенность) |
0,081 |
0,071 |
|
Kurtosis (Пикообразность) |
-1,153 |
0,143 |
Таблица 3. Тест Колмогорова-Смирнова (Оne-Sample Kolmogorov-Smirnov Test)
Статистика |
Значение |
|
N |
1175 |
|
Kolmogorov-Smirnov Z (Z-статистика Колмогорова-Смирнова) |
2,965 |
|
Asymp. Sig. (2-tailed) (2-сторонняя асимптотическая значи- |
0,000 |
|
мость) |
||
|
2.8.1. Одновыборочный T-тест
(One-sample t-test)
Одновыборочный T-тест позволяет осуществлять проверку статистических гипотез о равенстве выборочного среднего среднему по генеральной совокупности. Например, отличается ли статистически значимо средний возраст опрошенных от среднего возраста жителей г. Новосибирска (по данным Госкомстата он составляет 44 года). В табл. 4 представлены описательные статистики. В табл. 5 и 6 статистики теста для 0,05 и 0,4 уровня значимости.
Таблица 4. Описательные статистики выборочного распределения признака «возраст»
N |
Mean (Сред- |
Std. Deviation |
Std. Error Mean |
|
нее) |
(Станд. отклонение) |
(Станд. ошибка среднего) |
||
|
||||
1175 |
44,75 |
17,046 |
0,497 |
Таблица 5. Статистика теста (доверительная вероятность 95%)
Test Value (тестируемое значение) = 44
|
|
Sig. (2- |
|
95% Confidence Interval of the |
||
|
Df (сте- |
tailed) (2- |
Mean Dif- |
Difference (95% доверитель- |
||
|
пени |
сторонняя |
ference |
ный интервал разницы сред- |
||
|
свобо- |
значимость |
(Разница |
них) |
|
|
t |
ды) |
) |
средних) |
Lower |
|
Upper |
|
|
|
|
|
||
1,501 |
1174 |
0,134 |
0,75 |
-0,23 |
|
1,72 |
*Принимаем нулевую гипотезу (интервал [-0,23; 1,72] с 95% доверительной вероятностью накрывает 0)
28

Таблица 6. Статистика теста (доверительная вероятность 60%)
Test Value (тестируемое значение) = 44
|
|
|
Mean Dif- |
66% Confidence Interval of the |
||
|
Df |
Sig. (2-tailed) |
ference |
Difference (66% доверитель- |
||
|
ный интервал разницы сред- |
|||||
|
(степени |
(2-сторонняя |
(Разница |
|||
t |
свободы) |
значимость) |
средних) |
них) |
|
|
Lower |
|
Upper |
||||
|
|
|
|
|
||
|
|
|
|
|
|
|
1,501 |
1174 |
0,134 |
0,75 |
0,33 |
|
1,17 |
* Принимает альтернативную гипотезу (60% доверительный интервал «не накрывает» 0); заданная вероятность ошибки I рода (вероятность отвергнуть нулевую гипотезу, тогда как она истинна) – 0,4.
2.8.2. Двухвыборочный T-тест
(Independent-samples t-test)
Двухвыборочный параметрический тест для несвязанных выборок позволяет проверять статистические гипотезы о равенстве средних в двух группах. В табл. 7 отражены описательные статистики. В табл. 8 – статистики теста, рассчитанные для двух случаев: если в группах наблюдается или не наблюдается равенство дисперсий. Пример: исследуемый признак – возраст (количество полных лет); группирующий признак – пол.
Таблица 7. Описательные статистики
|
|
Mean |
Std. Deviation |
Std. Error Mean |
пол |
N |
(сред- |
(стандартное от- |
(стандартная ошибка |
|
|
нее) |
клонение) |
среднего) |
|
|
|
|
|
мужской |
449 |
43,05 |
17,270 |
0,815 |
женский |
726 |
45,80 |
16,832 |
0,625 |
29
Таблица 8. Статистики теста
Levene's Test for Equality of Variances |
|
t-test for Equality of Means (Т-тест на равенство средних в группах) |
|
|||||||
(Тест Ливиня на равенство дисперсий в группах) |
|
|
||||||||
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
95% Confidence Interval |
||
|
|
|
|
|
|
|
Std. Error Differ- |
of the Difference (95% |
||
Условия теста Ливиня |
|
|
|
|
Sig. (2- |
Mean Differ- |
ence (стандарт- |
ДИ разницы) |
||
|
|
|
|
tailed) (эпр. |
ence (разница |
ная ошибка раз- |
Lower |
|
Upper |
|
|
|
|
|
|
|
|||||
|
F |
Sig. |
t |
df |
ур. знач.) |
средних) |
ницы) |
(нижняя |
|
(верхняя |
|
|
|
|
|
|
|
|
граница) |
|
граница) |
Equal variances assumed |
1,446 |
0,229 |
-2,695 |
1173 |
0,007 |
-2,75 |
1,021 |
-4,753 |
|
-0,748 |
(предполагается равенство |
|
|||||||||
дисперсий) |
|
|
|
|
|
|
|
|
|
|
Equal variances not assumed |
- |
- |
-2,679 |
930,534 |
0,008 |
-2,75 |
1,027 |
-4,766 |
|
-0,735 |
(равенство дисперсий |
|
|||||||||
не предполагается) |
|
|
|
|
|
|
|
|
|
|