

566_Lazareva_a._JU._Kolichestvennye_metody_sotsiologicheskogo_issledovanija_
.pdfпоэтому если для анализа отпала необходимость в репрезентации по районам, не забудьте отключить «веса» (в том же меню, где и включали взвешивание).
Семинар 7. Коэффициенты корреляции (2 часа)
Возможности и ограничения корреляционной модели. Ранговая корреляция и коэффициент корреляции Пирсона. Реализация этих моделей в SPSS. Подготовка переменных для включения в модель. Интерпретация и презентация результатов, в том числе их визуализация.
Задание
1.Откройте агрегированный файл (задание 6), используя данные этого файла, ответьте на вопрос: имеется ли «линейная» зависимость между долей людей с высшим образованием, проживающих в том или ином районе города, и тем, чувствуют ли жители района защищенность своего правового и трудового положения?
2.А также можно ли утверждать, что с увеличением среднего возраста в районе возрастает доля людей, чувствующих себя защищенными.
3.Аналогично и в отношении связи с долей людей, хорошо оценивающих свой уровень жизни. Для получения ответов на данные вопросы воспользуйтесь процедурой CORRELATE/BIVARIATE/Pearson, в итоге вы получите значение и эмпирический уровень значимости коэффициента корреляции Пирсона. Для обоснованного ответа на поставленные вопросы воспользуйтесь также графическим представлением «поля рассеяния» признаков с наложением регрессионной прямой GRAPHS/SCATTER/SIMPLE, обратите внимание на расположение признаков по осям. В окно Laber cases by вставьте признак V02 (район), тогда точки на диаграмме будут маркированы. Если в окне этого не произойдет, то перейдите в режим редактирования диаграммы, выберите из меню Chart/Options/ case label ON. Для наложения регрессионной прямой в том же окне поставьте галочку около Fit line TOTAL.
4.Проанализируйте все случаи, даже если в них не фиксируется наличие линейной связи. С чем это может быть связано?
Семинар 8. Обобщающий семинар по анализу взаимосвязи неколичественных переменных (2 часа)
Обсуждение изученных методов изучения взаимосвязи неколичественных переменных. Сравнение их возможностей и ограничений. Дополнительность по отношению друг к другу. Комплексное решение социологической задачи.
Задание
1.Выберите из массива GOROD два ранговых признака, подготовьте их к дальнейшему анализу. Постройте таблицу сопряженности, в клетках которой отразите либо процент по строке, либо процент по столбцу в
11
зависимости от своих исследовательских задач. Кроме того, в клетках таблицы должны присутствовать значения стандартизированных остатков (Z-статистики). Опишите полученную таблицу.
2.Осуществите проверку гипотез о связи двух ранговых признаков с использованием критерия «Хи-квадрат». Соотнесите его значение и значения Z-статистик в разных клетках. Связи между какими именно значениями признаков формируют общую связь между признаками? Если статистика Хи-квадрат указывает на отсутствие связи между признаками, «поработайте» с исходными признаками. Например, укрупните или уменьшите группы. В крайнем случае, используйте для построения таблицы сопряженности другие признаки.
3.С помощью коэффициента ранговой корреляции, проверьте гипотезу о наличии линейной связи между выбранными ранговыми признаками. Опишите полученный результат: можно ли действительно утверждать, что между выбранными признаками существует линейная зависимость, или, например, вы получили ложную корреляцию, которая обусловлена влиянием третьего признака. Постройте диаграмму рассеяния и опишите ее.
4.Проверьте гипотезу о том, что чем старше респонденты, тем более вероятно, что они будут затрудняться с ответами на вопросы анкеты. Для этого постройте коэффициент «99». Сначала пересчитайте: сколько подсказок «затрудняюсь ответить» выбрал респондент, отвечая на вопросы v5-v9 и v14_1 – v16_4. Затем постройте новую переменную К, которая будет равна «количество ответов 99, деленное на количество вопросов». Проверьте с помощью теста Колмогорова-Смирнова, распределены ли признаки (возраст и коэффициент) нормально, в зависимости от результатов выберите адекватный коэффициент корреляции. Опишите полученный результат.
Семинар 9. Одновыборочные тесты: параметрический и непараметрические аналоги (2 часа)
Процедура «Средние» – статистики описания распределений. Знакомство с возможностями процедуры. Обсуждение различий параметрических и непараметрических тестов. Социологические задачи, решаемые посредством одновыборочных тестов. Интерпретация и презентация результатов.
Задание
1.С помощью процедуры Means опишите распределения возраста в разных районах города (или в других интересующих Вас группах). В качестве зависимой переменной выберите признак «возраст» (dependent list) и в качестве независимого признака – критерий деления на группы, например, район (independent list). В списке Options отметьте статистики, с помощью которых можно описать распределения возраста по районам. В каком из районов города самый возрастной состав жителей, какой самый молодой? С помощью опции Excel постройте график, в кото-
12
ром по оси У расположены районы, а по оси Х – среднее значение возраста в районе.
2.Проверьте: в каких районах города средний возраст статистически значимо не отличается от среднего возраста по городу (43 года). Воспользуйтесь командой Split file для того, чтобы провести одновыборочный тест для каждого из районов. Проверьте гипотезу для двух вариантов доверительной вероятности – 95% и 99%. Прокомментируйте полученный результат с использованием знаний о доверительном интервале.
3.По данным Всероссийского социологического центра в России 20,1% считают, что в следующем году их семья будет жить лучше, 16,8% – будет жить хуже и 52,4% – полагают, что ничего не изменится (затруднилось с ответом 10,7%). Проанализируйте, как соотносятся всероссийские данные с распределением ответов на аналогичный вопрос жителей нашего города (v8). Используйте одновыборочный тест Хи-квадрат.
Семинар 10. Двухвыборочный t-тест (2 часа)
Обсуждение возможностей и ограничений теста. Знакомство с процедурой, реализованной в SPSS, в процессе выполнения задания. Анализ различий в группах с учетом сравнения дисперсий в группах. Интерпретация результатов тестирования.
Задание
1.Существуют ли возрастные отличия в группе «удовлетворенных работой городских служб» и в группе «неудовлетворенных»? Воспользуйтесь возможностями t-теста для 2-х несвязанных выборок. В окно test var. перенесите признак «возраст», а в окно grouping var. – степень удовлетворенности. В качестве интересующих групп отметьте крайние значения признака «степень удовлетворенности работой городских служб».
2.Для построения данного признака воспользуйтесь процедурами Count
и recode/ compute (исходные переменные: V14_1-V14_5). Проверьте гипотезу для двух вариантов доверительной вероятности – 95% и 99%. Прокомментируйте полученный результат.
3.Постройте наглядную диаграмму (средний возраст в группах «удовлетворенных» и «неудовлетворенных»).
Для тех, кто желает повысить свое мастерство, предлагаю выполнить (с содержательным комментарием) те же задания, только применительно к признаку «сумма, необходимая для обеспечения ребенка».
Семинар 11. Однофакторный дисперсионный анализ (2 часа)
Процедура ANOVA в SPSS. Возможности и ограничения ОДА. Подготовка переменных для анализа. Интерпретация результатов, в том числе обсуждение проблемы равенства дисперсий в группах. Попарные множественные сравнения. Ситуации использования непараметрических аналогов ОДА: тест
13
Краскела-Уоллиса. Презентация результатов в виде содержательных (исследовательских) выводов.
Задание
1.С помощью однофакторного дисперсионного анализа (процедура ANOVA) ответьте на вопрос: можно ли утверждать, что жители города, различающие в своих оценках работы городских служб (ранее полученная переменная), различаются и по возрасту? Воспользуйтесь тестами попарных множественных сравнений для выделения схожих и различающихся по возрасту групп с разными оценками работы городских служб.
2.В рамках одного из исследовательских проектов было выдвинуто следующее предположение: для людей разного возраста характерна различная степень готовности рисковать, а именно, представители старших возрастных групп в большей степени предпочли бы положить деньги в банк с низкими процентами, но с высокой надежностью, молодые – наоборот. Проверьте дисперсионным анализом КраскелаУоллиса (для нескольких возрастных групп).
Семинар 12. Двухвыборочные непараметрические тесты (2 часа)
Процедура «Непараметрические тесты» в SPSS. Подготовка группирующего и исследуемого признаков к анализу. Изучение различий в 2-х группах с помощью непараметрического теста.
Задание
1. Постройте ОЧР признака V28 (рисковая установка, склонность к рисковому поведению). Опишите оценки горожан.
2.Подготовьте признак V28 к дальнейшему анализу в качестве исследуемого признака в непараметрическом двухвыборочном тесте (решите вопрос с пропущенными значениями, затрудняюсь ответить и т.д.). ВАЖНО! Не забудьте про порядок подсказок!!! «Математический смысл совпадает с социологическим».
3.Отметьте в отчете (коротко) изменения, которые претерпела данная переменная.
4.Проанализируйте различия (если они есть) склонности к рисковому поведению среди мужчин и женщин (воспользуйтесь непараметрическим тестом Манна-Уитни).
5.Опишите, используя ОЧР и команду «расщепить файл», рисковые установки горожан с разным уровнем обобщенного доверия (V11). По результатам выберите 2-е группы с разными доверительными установками, для которых Вы более подробно проанализируете склонность к риску. Различается ли отношение к финансовому риску в выбранных Вами группах? Используйте тест Манна-Уитни, не забудьте в окне группи-
14
рующей переменной указать номера именно тех групп, которые Вы отобрали для анализа.
6. На основе переменной V9 создайте переменную V9_1 с тремя вариантами ответов: низкая оценка уровня жизни, средняя и высокая. ВАЖНО! Опишите, как строили переменную (что с чем объединяли). Сравните рисковые установки в группах с низкими и высокими оценками уровня жизни.
7.Объедините свои промежуточные выводы по каждому из пунктов в единый социологический тест, описывающий рисковые установки горожан, их различия (или отсутствие таковых) среди мужчин и женщин, группах с разным уровнем обобщенного доверия и оценками уровня жизни.
Семинар 13. Простая линейная регрессия (2 часа)
Подготовка данных к построению модели. Обсуждение ограничений и возможностей модели, которые были представлены на лекции. Возможности программы SPSS. Интерпретация и презентация результатов моделирования.
Задание
1.Построить модель простой линейной регрессии, где зависимый признак – доля людей, негативно оценивающих свое будущее, а независимый – доля людей старше 45 лет. Целью данного статистического анализа является проверка следующей исследовательской гипотезы: влияет ли возраст на оценку своего будущего.
2.Первый шаг – произвести агрегирование исходного файла (разбивающий признак – район проживания, агрегируемые переменные – возраст
иоценка будущего). В новом файле возраст необходимо представить как доля людей старше 45 лет (45 – средний возраст по городу), а оценку будущего – как долю людей, негативно оценивающих свое будущее.
3.Второй шаг – рассчитать коэффициент корреляции между зависимыми
инезависимыми признаками.
4.Третий шаг – построить модель линейной регрессии, дополнительно задать выдачу: Statistics/Durbin-Watson, confidence interval; Plots/ Histogram; Save/ unstandardized predicted value, confidence interval for individual.
5.Четвертый шаг – провести качество модели на основе анализа результатов однофакторного дисперсионного анализа и t-статистик для коэффициентов регрессионного управления.
6.Пятый шаг – если качество модели удовлетворительное, оценить объяснительную силу модели и проинтерпретировать полученные коэффициенты регрессионного управления.
7.Шестой шаг – осуществить дополнительную проверку качества модели: проверить распределение стандартизированных остатков (соответ-
15
ствует ли оно нормальному), построить график, отразить на нем линию регрессии и доверительные интервалы для предсказанных значений с наложением диаграммы расселения объектов (районов) в поле модельных признаков. Построение графика: Plots/scatter/overlay/Y-X pail (попарно с независимым признаком «доля людей старше 45 лет» заносите в окно эмпирические значения переменной «доля негативно оценивающих будущее», модельные значения данного признака, значения границ доверительных интервалов). Внимание! Независимый признак должен располагаться на оси Х, соответственно, обратите внимание на то, чтобы в окне для построения графика это отражалось (признаки в паре можно поменять местами с помощью swap pair).
8.Седьмой шаг – обобщенный вывод – что дало моделирование для решения исследовательской задачи (содержательный вывод).
Семинар 14. Процедура факторного анализа: метод главных компонент (2 часа)
Возможности SPSS для сворачивания признакового пространства с помощью метода главных компонент. Подготовка переменных для участия в построении модели. Факторные нагрузки. Условные критерии качества модели. Интерпретация главных факторов. Представление данных, в том числе визуализация «нового» признакового пространства.
Задание
1.Постройте шкалу «оценка надежности окружающих» на основе исходных признаков, отражающих мнения горожан о степени надежности окружающих (v36_1 – v36_2). Подготовьте признаки: проверьте порядок следования значений, исключите несодержательные коды. Для решения задачи воспользуйтесь процедурой факторного анализа, методом главных компонент. Прокомментируйте полученный результат.
Часть 2. Стимульный материал для организации семинарских занятий и самостоятельной работы студентов
2.1. Пошаговая исследовательская модель анализа данных
Пошаговая исследовательская модель анализа данных представлена на основе схемы, предложенной Ю. Толстовой в работе «Логика математического анализа социологических данных (М.: Наука, 1999. – С. 34).
Методологические основания математико-статистических моделей имеют решающее значение для анализа социологических данных. Всегда стоит помнить, что статистические модели являются инструментом для проверки теоретических гипотез исследования. Соответственно, анализ и интерпретация данных – промежуточное звено исследовательского процесса. В представленной схеме отражена идея необходимости взаимосвязи различных этапов исследовательской работы. В рамках данного курса особое значение имеет переход от формальной модели к апостериорной содержательной модели.
16
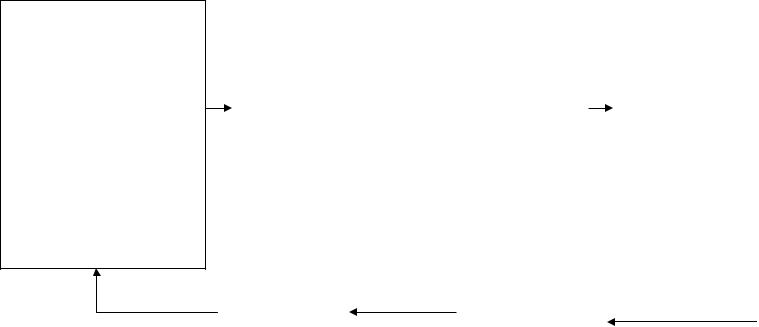
Априорная содержательная модель (объект + предмет)
Уровень благосостояния семьи
Влияние (содержательная закономерность) – исследовательская гипотеза
Различие социальноэкономической ситуации в районах
|
|
Концептуальная модель |
|
|
Формальная модель |
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
Интерпретация |
Операционализация |
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
Результаты измерения |
|
|
|
субъективная оценка |
оценка по 5-ти |
|
||||||
|
|
благосостояния |
балльной шкале |
|
|
|
(массив данных) |
|||
|
|
семьи |
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
причинно- |
статистическая |
|
|
числа + интерпретация |
||||
|
|
следственная связь |
|
связь |
|
|
|
|
|
|
|
|
район проживания |
конкретный район |
|
|
|
|
|
||
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
Реальная |
|
|
Апостериорная |
|
|
|
|||
|
|
жизнь |
|
|
содержательная |
|
|
|
||
|
|
|
|
|
|
|
||||
|
|
|
|
|
модель |
|
|
|
||
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
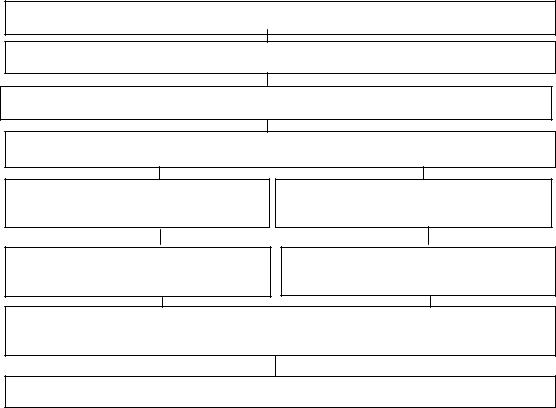
2.2. Общая схема проверки статистической гипотезы
(Источник: Малхотра Н. Маркетинговые исследования. М.: Вильямс, 2003. С.563)
На схеме представлены альтернативные способы проверки статистических гипотез. В пакете SPSS реализован первый способ (эмпирический уровень значимости соотносится с заданным критическим уровнем). Однако, воспользовавшись математико-статистическими таблицами, можно реализовать и второй способ проверки.
Сформулировать нулевую и альтернативную гипотезы
Выбрать подходящий статистический метод проверки
Выбрать критический уровень значимости (доверительную вероятность)
Вычислить значение выборочной статистики критерия
Определить эмпирический уровень значимости
Сравнить с критическим уровнем значимости
Определить критическое значение выборочной статистики критерия
Сравнить с эмпирическим значением статистики
Определить, попадает ли значение в область принятия или отклонения нулевой гипотезы
Отклонить или принять нулевую (альтернативную) гипотезу
18
2.3. Одномерные частотные распределения (ОЧР)
(Процедура FREQUENCIES)
Построение одномерных частотных распределений является первым шагом анализа количественных данных. В табл. 1 представлены возможные варианты «линеек»: количество объектов в группах, процент от опрошенных, валидный процент (процент от тех, кто дал содержательный ответ на вопрос), накопленный процент. В табл. 2 приведены различные статистики выборочного распределения интервального признака, которые могут быть получены с помощью процедуры Frequencies.
Таблица 1. Распределение респондентов по возрастным группам
Возрастные |
Количество |
% от |
% от ответивших |
Накопленный |
|
опрошенных |
процент |
||||
группы |
(frequency) |
(valid percent) |
|||
|
|
(percent) |
|
(cumulative percent) |
|
18 – 24 |
193 |
16,4 |
16,4 |
16,4 |
|
25 – 34 |
198 |
16,9 |
16,9 |
33,3 |
|
35 – 44 |
169 |
14,4 |
14,4 |
47,7 |
|
45 – 54 |
239 |
20,3 |
20,3 |
68,0 |
|
55 – 64 |
178 |
15,1 |
15,1 |
83,1 |
|
65+ |
198 |
16,9 |
16,9 |
100,0 |
|
Всего |
1175 |
100,0 |
100,0 |
- |
Таблица 2. Оценки параметров распределения признака «возраст»
N (количество) |
Valid (валидное количество) |
1175 |
|
Missing (системные ошибки) |
0 |
Mean (среднее) |
|
44,75 |
Median (медиана) |
|
46,00 |
Mode (мода) |
|
50 |
Std. Error of Mean (стандартная ошибка среднего) |
0,497 |
|
Std. Deviation (стандартное отклонение) |
17,046 |
|
Variance (дисперсия) |
|
290,557 |
Skewness (статистика скошенности) |
0,081 |
|
Std. Error of Skewness (стандартная ошибка |
0,071 |
|
скошенности) |
|
|
|
|
|
Kurtosis (статистика пикообразности) |
-1,153 |
|
Std. Error of Kurtosis (стандартная ошибка |
0,143 |
|
пикообразности) |
|
|
|
|
|
Range (размах) |
|
64 |
Percentiles (процен- |
33,3 |
35,00 |
тили, 3 равные |
66,7 |
54,00 |
группы) |
|
|
|
|
|
19
2.4. Таблицы сопряженности и меры связи
(Процедура CROSSTABS)
Таблицы сопряженности являются инструментом исследования взаимосвязи двух переменных (номинальных или ранговых с небольшим количеством альтернатив). Табл. 1 содержит частотное распределение признака «оценка городской ситуации» в трех возрастных группах. В табл. 2 представлены полезные для анализа характеристики взаимосвязи отдельных альтернатив признаков
– Z-статистики, а также ожидаемое (в условиях нулевой гипотезы об отсутствии связи между признаками) количество объектов в клетке таблицы, участвующее в построение статистики. Меры связи для номинальных (ранговых) признаков приведены в табл. 3 и табл. 4.
Таблица 1. Оценка современной ситуации в городе
( % от числа ответивших в каждой возрас- |
Возрастные группы |
Всего |
||
тной группе) |
18 – 34 |
35 – 54 |
старше55 |
(N=1175) |
Варианты оценки городской ситуации |
(N=391) |
(N=408) |
(N=376) |
|
все идет хорошо |
16,6 |
5,1 |
1,1 |
7,7 |
все не так плохо, жить можно |
55,8 |
41,2 |
22,3 |
40,0 |
жить трудно, но можно терпеть |
21,2 |
41,2 |
53,7 |
38,6 |
все очень плохо, терпеть уже невозможно |
5,6 |
11,0 |
19,9 |
12,1 |
другое |
0,3 |
- |
1,1 |
0,4 |
затрудняюсь ответить |
0,5 |
1,5 |
1,9 |
1,3 |
Всего |
100,0 |
100,0 |
100,0 |
100,0 |
Таблица 2. Оценка современной ситуации в городе (ожидаемые частоты, Z- статистики)
Варианты оценки |
|
Возрастная группа |
Все- |
|||
городской ситуа- |
Характеристики |
18–34 |
35–54 |
старше55 |
го |
|
ции |
|
(N=388) |
(N=402) |
(N=365) |
|
|
все идет хорошо |
Count (кол-во) |
65 |
21 |
4 |
90 |
|
Expected Count (ожидаемое кол-во) |
30,2 |
31,3 |
28,4 |
90,0 |
||
|
Adjusted Residual |
8,1 |
-2,4 |
-5,8 |
- |
|
|
(стандартизованный остаток, Z- |
|||||
|
статистика) |
|
|
|
|
|
все не так плохо, |
Count |
218 |
168 |
84 |
470 |
|
жить можно |
Expected Count |
157,9 |
163,6 |
148,5 |
470,0 |
|
|
Adjusted Residual |
7,6 |
0,6 |
-8,3 |
- |
|
жить трудно, но |
Count |
83 |
168 |
202 |
453 |
|
Expected Count |
152,2 |
157,7 |
143,2 |
453,0 |
||
можно терпеть |
||||||
Adjusted Residual |
-8,8 |
1,3 |
7,6 |
- |
||
|
||||||
все очень плохо, |
Count |
22 |
45 |
75 |
142 |
|
терпеть уже не- |
Expected Count |
47,7 |
49,4 |
44,9 |
142,0 |
|
возможно |
Adjusted Residual |
-4,9 |
-0,8 |
5,8 |
- |
|
В целом по вы- |
Count |
388 |
402 |
365 |
1155 |
|
борке* |
Expected Count |
388,0 |
402,0 |
365,0 |
1155 |
|
* В таблице приводятся данные для тех, кто дал содержательные ответы на вопрос об оценке современной ситуации в городе.
20