

8879
.pdfПоддержка ассоциативного правила – это число транзакций, которые содер-
жат как условие, так и следствие. Например, для ассоциации A → B можно записать:
S= .
.
Достоверность ассоциативного правила A → B представляет собой меру точ-
ности правила и определяется как отношение количества транзакций, содержащих и условие, и следствие, к количеству транзакций, содержащих только условие:
C= .
.
Если поддержка и достоверность достаточно высоки, можно с большой веро-
ятностью утверждать, что любая будущая транзакция, которая включает условие,
будет также содержать и следствие.
Лифт – это отношение частоты появления условия в транзакциях, которые также содержат и следствие, к частоте появления следствия в целом. Значения лиф-
та большие, чем единица, показывают, что условие чаще появляется в транзакциях,
содержащих следствие, чем в остальных. Лифт является обобщенной мерой связи двух предметных наборов: при значениях лифта> 1 связь положительная, при 1 она отсутствует, а при значениях <1 – отрицательная.
Современные базы данных имеют очень большие размеры, достигающие гига-
и терабайтов, и тенденцию к дальнейшему увеличению. И поэтому, для нахождения ассоциативных правил требуются эффективные масштабируемые алгоритмы, позво-
ляющие решить задачу за приемлемое время.
Один из первых алгоритмов, эффективно решающих подобный класс задач, –
это алгоритм Aрriori. Кроме этого алгоритма в последнее время был разработан ряд других алгоритмов: DHP, Partition, DIC и другие.
Алгоритм Aрriori.
На первом шаге этого алгоритма этого в необходимо найти часто встречаю-
щиеся наборы элементов, а затем, на втором, извлечь из них правила. Количество элементов в наборе будем называть размером набора, а набор, состоящий из k эле-
ментов, – k-элементным набором.
41
Выявление часто встречающихся наборов элементов – операция, требующая много вычислительных ресурсов и, соответственно, времени. Примитивный подход к решению данной задачи – простой перебор всех возможных наборов элементов.
Это потребует O(2|I|) операций, где |I| – количество элементов. Apriori использует одно из свойств поддержки, гласящее: поддержка любого набора элементов не мо-
жет превышать минимальной поддержки любого из его подмножеств. Например,
поддержка 3-элементного набора {Хлеб, Масло, Молоко} будет всегда меньше или равна поддержке 2-элементных наборов {Хлеб, Масло}, {Хлеб, Молоко}, {Масло,
Молоко}. Дело в том, что любая транзакция, содержащая {Хлеб, Масло, Молоко},
также должна содержать {Хлеб, Масло}, {Хлеб, Молоко}, {Масло, Молоко}, при-
чем обратное не верно.
Это свойство носит название анти-монотонности и служит для снижения раз-
мерности пространства поиска. Не имей мы в наличии такого свойства, нахождение многоэлементных наборов было бы практически невыполнимой задачей в связи с экспоненциальным ростом вычислений.
Свойству анти-монотонности можно дать и другую формулировку: с ростом размера набора элементов поддержка уменьшается, либо остается такой же. Из всего вышесказанного следует, что любой k-элементный набор будет часто встречающим-
ся тогда и только тогда, когда все его (k-1)-элементные подмножества будут часто встречающимися.
После того как найдены все часто встречающиеся наборы элементов, можно приступить непосредственно к генерации правил.
Алгоритмы поиска ассоциативных правил предназначены для нахождения всех правил X Y, причем поддержка и достоверность этих правил должны быть вы-
ше некоторых наперед определенных порогов, называемых соответственно мини-
мальной поддержкой (minsupport) и минимальной достоверностью (minconfidence).
Все множество ассоциативных правил можно разделить на три вида:
42
Полезные правила – содержат действительную информацию, которая ра-
нее была неизвестна, но имеет логичное объяснение. Такие правила могут быть ис-
пользованы для принятия решений, приносящих выгоду.
Тривиальные правила – содержат действительную и легко объяснимую информацию, которая уже известна. Такие правила, хотя и объяснимы, но не могут принести какой-либо пользы, т.к. отражают или известные законы в исследуемой области, или результаты прошлой деятельности. При анализе рыночных корзин в правилах с самой высокой поддержкой и достоверностью окажутся товары-лидеры продаж. Практическая ценность таких правил крайне низка.
Непонятные правила – содержат информацию, которая не может быть объяснена. Такие правила могут быть получены или на основе аномальных значе-
ний, или глубоко скрытых знаний. Напрямую такие правила нельзя использовать для принятия решений, т.к. их необъяснимость может привести к непредсказуемым результатам. Для лучшего понимания требуется дополнительный анализ.
Варьируя верхним и нижним пределами поддержки и достоверности, можно избавиться от очевидных и неинтересных закономерностей. Как следствие, правила,
генерируемые алгоритмом, принимают приближенный к реальности вид. Понятия
«верхний» и «нижний» предел очень сильно зависят от предметной области, поэто-
му не существует четкого алгоритма их выбора. Но есть ряд общих рекомендаций.
Большая величина параметра максимальная поддержка означает, что алгоритм будет находить хорошо известные правила, или они будут настолько очевидными, что в них нет никакого смысла. Поэтому ставить порог максималь-
ная поддержка очень высоким (более 20%) не рекомендуется.
Большинство интересных правил находится именно при низком значе-
нии порога поддержки, хотя слишком низкое значение поддержки ведет к гене-
рации статистически необоснованных правил. Поэтому правила, которые кажут-
ся интересными, но имеют низкую поддержку, дополнительно анализируйте,
рассчитывая для них лифт, левередж и улучшение.
43
Ограничивайте мощность часто встречающихся множеств – правила с большим числом предметов в условии трудно интерпретируются и воспринима-
ются.
Уменьшение порога достоверности приводит к увеличению количества правил. Значение минимальной достоверности не должно быть слишком малень-
ким, так как ценность правила с достоверностью 5% чаще всего настолько мала,
что это и правилом считать нельзя.
Правило с очень большой достоверностью (>85-90%) практической цен-
ности в контексте решаемой задачи не имеет, т.к. товары, входящие в следствие,
покупатель, скорее всего, уже купил.
При большом количестве найденных правил и широком ассортименте услуг и товаров анализировать полученные правила достаточно сложно. Для удобства ана-
лиза таких наборов правил в АП Deductor есть визуализаторы "Дерево правил" и "Что-если".
2.3.5. Раздел 5. Data Mining. Искусственные нейронные сети.
В наши дни возрастает необходимость в системах, которые способны не толь-
ко выполнять однажды запрограммированную последовательность действий над за-
ранее определенными данными, но и способны сами анализировать вновь поступа-
ющую информацию, находить в ней закономерности, производить прогнозирование и т.д. В этой области приложений самым лучшим образом зарекомендовали себя так называемые нейронные сети – самообучающиеся системы, имитирующие деятель-
ность человеческого мозга.
Математическая модель нейрона была впервые предложена Маккалоком и Питтсом еще в 1943 г. Нейрон – это несложный автомат, преобразующий входные сигналы, суммируя их с некоторыми весами, в выходной сигнал (рис. 18). Сигналы силы x1, x2, ..., xn, поступая на синапсы (входы), преобразуются линейным образом,
т.е. к телу нейрона поступают сигналы силы w1*x1, w2*x2, ..., wn*xn (здесь wi – веса соответствующих синапсов).
44

Рис. 18. Математическая модель нейрона
Для удобства к нейрону добавляют еще один вход (и еще один вес w0), считая,
что на этот вход всегда подается сигнал силы 1. В теле нейрона происходит суммирование сигналов:
n
S wi xi
i 0
Затем применяют к сумме некоторую фиксированную функцию f и получают на выходе сигнал силы Y = f(S). При этом в качестве активационной функции часто используются пороговая (ступенчатая) функция f, сигмоида, гиперболический тангенс и другие (рис. 19).
Рис. 19. Активационные функции искусственных нейронов, используемые при моделировании ИНС.
В ИНС нейроны объединяются в слои, при этом выходы нейронов предыдущего слоя являются входами нейронов следующего слоя. Нейроны сети
45
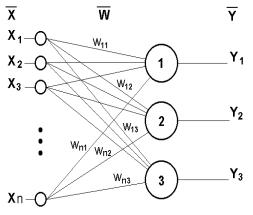
взаимодействуют друг с другом в зависимости от разновидности связей. Связи бывают полными (каждый с каждым), частичными (противоположность полной связи), с петлями обратных связей, без таковых. В каждом слое нейроны выполняют параллельную обработку данных. Простейшую искусственную нейронную сеть можно представить в виде одного «слоя» нейронов, соединенных между собой (рис.
20).
Рис.20. Простейшая нейронная сеть из трех нейронов.
В 1960 г. на основе таких нейронов Розенблатт построил первый в мире авто-
мат для распознавания изображений букв, который был назван “перцептрон”
(perception – восприятие). Этот автомат имел очень простую однослойную структу-
ру и мог решать только относительно простые (линейные) задачи. С тех пор были изучены и более сложные системы из нейронов, использующие в качестве переда-
точных любые непрерывные функции.
Нейронные сети не программируются в привычном смысле этого слова, они обучаются. Возможность обучения – одно из главных преимуществ нейронных сетей перед традиционными алгоритмами. Технически обучение заключается в нахождении коэффициентов связей между нейронами.
Наиболее распространенный алгоритм обучения нейронных сетей – алгоритм обратного распространения ошибки. В нейронных сетях с обратным распространением ошибки связи между собой имеют только соседние слои, при этом каждый нейрон предыдущего слоя связан со всеми нейронами последующего слоя. Первый слой нейронов называется входным. Последний слой нейронов
46
называется выходным и содержит столько нейронов, сколько классов образов распознается. Принцип обучения такой нейронной сети базируется на вычислении отклонений значений выходных данных от эталонных и обратном "прогоне" этих отклонений с целью минимизации ошибки.
Для получения необходимых значений весов сеть необходимо «тренировать» на примерах с известными значениями входных параметров и правильных ответов на них. Подбираются такие веса, которые обеспечивают наибольшую близость отве-
тов нейронной сети к правильным.
Тренировка нейросети происходит путем многократного прогона через нее ча-
сти набора данных (обучающего множества), выделенных для обучения. Обучающее множество представляет собой структурированный набор данных, применяемый для обучения аналитических моделей нейронных сетей. Каждая запись обучающего множества представляет собой обучающий пример, содержащий заданное входное воздействие и соответствующий ему правильный выходной (целевой) результат.
Фактически, обучающее множество представляет собой функцию, заданную таб-
лично парами входных и выходных векторов [(X1Y1),(X2Y2),...,(XkYk)]. После обуче-
ния модель должна реализовывать эту функцию. Для решения задачи классифика-
ции, обучающая выборка должна содержать объекты, для которых априорно изве-
стен класс.
Обучающее множество должно удовлетворять нескольким требованиям:
Отражать правила и закономерности исследуемого процесса, которые должна обнаружить модель и по которым должно строиться отображение вход-
выход;
быть репрезентативной, т.е. содержать достаточное количество уникальных примеров, как можно более полно отражающих закономерности исследуемого процесса;
не содержать дубликатов и противоречий, пропусков и аномальных значений. Наличие данных факторов снижает качество обучения модели.
47
Тестовое множество формируется путем случайной выборки из исходного множества данных. При разделении исходной выборки на обучающее и тестовое множества, главное – обеспечить репрезентативность обучающего множества, а все оставшиеся примеры можно использовать в качестве тестовых. Однако если объем исходной выборки недостаточен для формирования обучающего и тестового мно-
жеств, то использую специальные методы, такие как перекрестная проверка, пере-
крестная проверка без одного примера, бустрэп-выборка и т.д. Тестовые примеры –
это примеры, использующиеся не для обучения модели, а для проверки его резуль-
татов. Примеры тестового множества так же, как и обучающего, предъявляются мо-
дели в процессе обучения, но не используются для подстройки ее параметров. Цель применения тестового множества – проверить, как обученная модель будет работать с новыми данными, т.е. приобрела ли она способность к обобщению.
Ошибка модели, полученная на обучающем множестве, называется ошибкой обучения. Ошибка модели, полученная на тестовом множестве, называется ошибкой обобщения. Если ошибки на тестовом и обучающем множествах достаточно малы,
то это с достаточной долей уверенности позволяет утверждать, что модель приобре-
ла способность к обобщению и может использоваться для работы с новыми данны-
ми. Если малая ошибка достигнута только на обучающем множестве, а на тестовом она велика, то это позволяет предположить низкую способность к обобщению. Кро-
ме этого, ошибка на тестовом множестве позволяет не допустить переобучения мо-
дели. Если ошибка на обучающем множестве монотонно падает, то на тестовом множестве, после некоторого числа итераций, она может начать возрастать, что го-
ворит о переобучении модели. Поэтому, чтобы избежать переобучения, целесооб-
разно остановить процесс обучения, как только ошибка на тестовом множестве начинает возрастать.
Преимуществами нейросетевого метода по сравнению с классическим стати-
стическим анализом являются:
отсутствие ограничений по характеру входной информации;
48
способность обучаться на множестве примеров в тех случаях, когда неиз-
вестны закономерности развития ситуации;
способность успешно решать задачи, опираясь на неполную, искаженную,
зашумленную и внутренне противоречивую входную информацию;
возможность находить сложные нелинейные зависимости между входны-
ми данными и выходными;
способность адаптироваться к изменениям среды;
возможность сделать систему самообучаемой, что особенно важно для решения трудноформализуемых задач прогнозирования.
Вобщем случае сеть может решать как задачи классификации, так и задачи предсказания.
Алгоритм построения классификатора на основе нейронных сетей
1.Работа с данными
Составить базу данных из примеров, характерных для данной задачи.
Разбить всю совокупность данных на два множества: обучающее и тесто-
вое (возможно разбиение на 3 множества: обучающее, тестовое и под-
тверждающее).
Число примеров в обучающем множестве должно быть больше числа при-
меров в тестовом множестве и больше в 1,5-2 раза числа настраиваемых весов.
2.Предварительная обработка
Выбрать систему признаков, характерных для данной задачи, и преобра-
зовать данные соответствующим образом для подачи на вход сети (нор-
мировка, стандартизация и т.д.)
Выбрать систему кодирования выходных значений (классическое кодиро-
вание, 2 на 2 кодирование и т.д.)
3.Конструирование, обучение и оценка качества сети
Выбрать топологию сети: количество слоев, число нейронов в слоях.
49

При выборе архитектуры ИНС обычно опробуется несколько конфигураций с различным количеством элементов. Рекомендуется руководствоваться следующими правилами:
а) количество скрытых слоев в большинстве случаев не должно быть больше двух;
б) число связей (весов) должно быть в 2 раза меньше объема обучаю-
щей выборки;
в) количество нейронов в скрытых слоях можно приблизительно рас-
считать по формуле с
 n m , где n - число входных нейронов, m-число выходов сети, с – константа (по умолчанию с=4).
n m , где n - число входных нейронов, m-число выходов сети, с – константа (по умолчанию с=4).
Выбрать функцию активации нейронов (например "сигмоида").
Выбрать алгоритм обучения сети. Обычно используется алгоритм обуче-
ния Back Propagation (обратного распространения) с подтверждающим множеством.
Оценить качество работы сети на основе подтверждающего множества или по другому критерию, оптимизировать архитектуру (уменьшение ве-
сов, прореживание пространства признаков).
Остановиться на варианте сети, который обеспечивает наилучшую спо-
собность к обобщению, и оценить качество работы по тестовому множе-
ству
4.Использование и диагностика
Выяснить степень влияния различных факторов на принимаемое решение
(эвристический подход).
Убедиться, что сеть дает требуемую точность классификации (число не-
правильно распознанных примеров мало).
При необходимости вернуться на этап 2, изменив способ представления образцов или изменив базу данных.
Практически использовать сеть для решения задачи.
50