

8879
.pdfРис. 6. Технология OLAP
Алгоритм работы следующий:
1.Получение данных в виде плоской таблицы или результата выполнения SQL
запроса.
2.Кэширование данных и преобразование их к многомерному кубу.
3.Отображение построенного куба при помощи кросс-таблицы или диаграммы и т.п. В общем случае, к одному кубу может быть подключено произвольное ко-
личество отображений.
Отображения, используемые в OLAP системах, чаще всего бывают двух видов
–кросс-таблицы и кросс-диаграммы. Кросс-таблица является основным и наиболее распространенным способом отображения куба. Она отличается от обычной плос-
кой таблицы наличием нескольких уровней вложенности (например, она допускает разбиение строк на подстроки, а столбцов – на подстолбцы). Кросс-диаграмма пред-
ставляет собой диаграмму заданного типа (гистограмму, линейную диаграмму и т.д.), построенную на основе кросс-таблицы. Основное отличие кросс-диаграммы от обычной диаграммы в том, что она однозначно соответствует текущему состоянию куба и при любых его изменениях (транспонирование, фильтрация по измерениям и т.д.) также синхронно изменяется.
OLAP-куб можно использовать не только как метод визуализации, но и как средство оперативного формирования отчетов и представления информации в нуж-
ном разрезе (так называемая аналитическая отчетность).
OLAP-куб позволяет анализировать данные сразу по нескольким измерениям,
т.е. выполнять многомерный анализ. Пользователь, анализирующий информацию,
может «резать» куб по разным направлениям, получать сводные (например, по го-
21
дам) или, наоборот, детальные (по неделям) сведения и осуществлять прочие мани-
пуляции, которые необходимы ему в процессе анализа. В анализе может использо-
ваться любое число измерений, каждое из которых будет представлено новой осью.
Конечно, для OLAP-куба с размерностью больше трех геометрическая интерпрета-
ция не имеет смысла (тем более что речь идет не о реальном, а об информационном пространстве).
Следует отметить, что задача расчета и визуализации куба с большим числом измерений, во-первых, может потребовать слишком больших вычислительных ре-
сурсов, а во-вторых, ее содержательная интерпретация весьма затруднительна. Как правило, человек не способен анализировать больше 5-7 измерений одновременно.
Поэтому сложные задачи, требующие анализа данных большой размерности, следу-
ет по возможности сводить к нескольким более простым.
Визуализация и отчеты в Deductor Studio
На верхнем уровне принятия решений значение имеет не точность цифр, а
закономерности, поэтому визуализация результатов анализа в виде OLAP–отчетов,
графиков, карт и диаграмм – наиболее оптимальный вариант отображения статистической информации, который позволяет на уровне простых обобщений получить агрегированные данные на текущий момент и спланировать динамику на ближайшее время.
В АП Deductor предусмотрены следующие способы визуализации данных:
OLAP-кубы, диаграммы, графики, гистограммы, статистика, правила, матрицы классификации, диаграммы рассеяния, ретропрогноз, карты Кохонена, профили кла-
стеров.
Визуализаторы общего назначения рассматривались в разделе «Базовые навы-
ки работы Deductor Studio Academic». Визуализаторы для иллюстрации построения и оценки качества аналитических моделей будут использоваться в разделе «Модели
Data Mining». Рассмотрим OLAP-кубы – визуализаторы, которые чаще всего ис-
пользуются в отчетах.
22

Аналитическая отчетность (отчеты) – это одно из средств визуализации и кон-
солидации результатов анализа данных для конечного пользователя (для лиц, при-
нимающих решения). Аналитическая отчетность обеспечивает быстрый доступ к ре-
зультатам анализа, не требуя от пользователя навыков анализа данных и работы в АП Deductor. При работе с отчетами пользователь не видит сценарий анализа дан-
ных, ему доступны только конечные результаты (выдержки) из работы аналитика.
Для построения аналитической отчетности в АП Deductor предназначена вкладка Отчеты, cпособ открытия: «Вид – Отчеты» или кнопка  , после нажатия на которую, в рабочей части экрана появится панель Отчеты.
, после нажатия на которую, в рабочей части экрана появится панель Отчеты.
Отчеты строятся в виде древовидного иерархического списка (рис. 7), каждым узлом которого является отдельный отчет или папка, содержащая несколько отче-
тов. Каждый узел дерева отчетности связан со своим узлом в дереве сценария. Для каждого отчета настраивается свой способ отображения (таблица, гистограмма,
кросс таблица, кросс диаграмма и т.п.). Это удобно, так как несколько отчетов могут быть связаны с одним узлом дерева сценария.
Рис. 7. Панель отчетов сценария «Мониторинг водных ресурсов» Чтобы добавить новый отчет, нужно щелкнуть по кнопке Добавить узел или
выбрать соответствующую команду из контекстного меню. В результате откроется окно Выбор узла, в котором следует выделить узел дерева сценария, где содержится нужная выборка данных, и щелкнуть по кнопке Выбрать. Следует отметить, что операция добавления нового отчета доступна, только если выделена папка или кор-
23
невой пункт Отчеты списка отчетов. Если выделить узел, содержащий отдельный отчет, команда создания нового отчета будет недоступна.
Чтобы добавить новую папку, нужно щелкнуть по кнопке Добавить папку 
или выбрать соответствующую команду в контекстном меню. В результате в списке отчетов появится новая папка с открытым полем имени, куда следует ввести имя папки. После ввода имени для его сохранения щелкнуть по любому узлу списка.
Чтобы поместить отчет в папку, нужно перед вызовом команды Добавить узел вы-
делить эту папку.
На рис. 7. представлены отчеты сценария «Мониторинг водных ресурсов», ко-
торые содержат в себе историю работы с данными и их анализа. Для перехода на ту или иную ветку сценария необходимо щелкнуть правой кнопкой мыши по интере-
сующему отчету и выбрать опцию Найти узел в сценарии, после чего откроется тот или иной узел.
Используя имеющиеся в Deductor OLAP-технологии, отчеты можно предста-
вить в виде OLAP-кубов и кросс-диаграмм. Примером является отчет «Динамика за-
грязнения объекта» (рис. 8.). Он представляет собой сводную таблицу по измерени-
ям «Дата» и «Створ» и кросс-диаграмму, которая показывает динамику загрязнения водного объекта (в данном случае реки Беленькая) для фонового и для контрольного створа конкретным загрязнителем (в данном случае ХПК) на протяжении всего пе-
риода проведения мониторинга.
Данный отчет является универсальным, так как здесь имеется возможность выбора любого другого водного объекта и загрязнителя для быстрого составления отчетности.
24
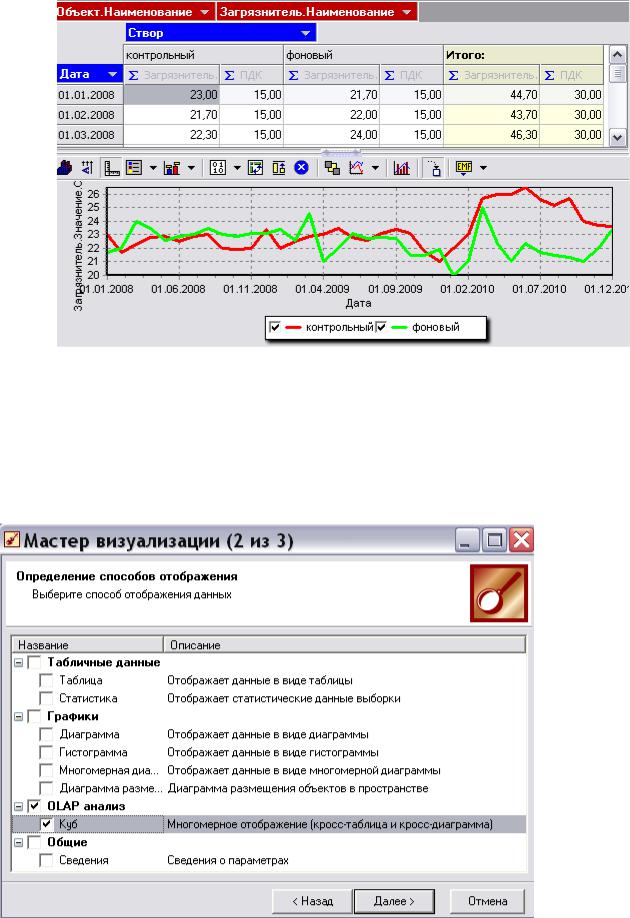
Рис. 8. Отчет «Динамика загрязнения объекта»
Рассмотрим порядок настройки OLAP-куба для отчета «Динамика загрязнения объекта» (рис. 8).
Чтобы построить OLAP-куб, пользователь должен активировать мастер визуа-
лизации  и выбрать способ отображения данных в виде куба (рис. 9).
и выбрать способ отображения данных в виде куба (рис. 9).
25

Рис. 9. Выбор способа отображения данных в виде куба На 3 и 4 шаге «Мастера настройки отображения» нужно указать системе, ка-
кие измерения и факты включать в куб (рис. 10, 11).
Рис. 10. Настройка назначений полей куба
Рис. 11. Настройка размещений полей куба На последнем шаге нужно выбрать, какие факты нужно отображать в кубе на
пересечении измерений и варианты агрегации их значений (рис. 12).
26

Рис. 12. Настройка отображения фактов
Для отображения фактов предусмотрено 8 способов объединения (агрегирова-
ния):
Сумма – вычисляется сумма объединяемых фактов;
Минимум – среди всех объединяемых фактов в таблице отображается только минимальный;
Максимум - среди всех объединяемых фактов в таблице отображается только максимальный;
Среднее – вычисляется среднее значение объединяемых фактов;
Количество – в кубе будет отображаться количество объединенных фактов;
Стандартное отклонение;
Сумма квадратов;
Количество пропусков;
Кроме того, всегда присутствует факт Количество, который рассчитывает число записей, соответствующих совокупности измерений.
В результате для нашего примера получится многомерный отчет, представ-
ленный на рис. 3.6. Измерения в кубе изображаются специальными полями. Си-
27

ние поля показывают измерения, участвующие в построении таблицы. Зелеными полями отображаются скрытые измерения, не участвующие в построении таблицы.
Имеется возможность перестраивать таблицу с помощью мыши «на лету». Сделать это можно, если перетаскивать поля с заголовками измерений.
Изменять расположение измерений можно, используя операцию транспониро-
вания таблицы. В результате транспонирования данные, ранее отображавшиеся в строках, отображаются в столбцах, а данные в столбцах преобразуются в строки.
Транспонирование во многих случаях позволяет оперативно сделать таблицу более удобной для восприятия.
Куб можно сортировать как по измерениям, так и по фактам. В первом случае на помощь приходит кнопка  Сортировать значения измерений (по умолчанию значения измерений следуют в алфавитном порядке), во втором – щелчок мышью по заголовку факта, как это показано ниже.
Сортировать значения измерений (по умолчанию значения измерений следуют в алфавитном порядке), во втором – щелчок мышью по заголовку факта, как это показано ниже.
Еще одной полезной возможностью является фильтрация. Чтобы осуществить фильтрацию по значениям измерений, нужно нажать кнопку  в заголовке измере-
в заголовке измере-
ния. Раскроется список всех уникальных значений данного измерения, в котором при помощи флажков можно включить/отключить нужные (рис. 13). Если включены не все значения, заголовок измерения в кубе поменяет цвет с синего на красный.
Рис. 13. Фильтрация по значениям измерения
28
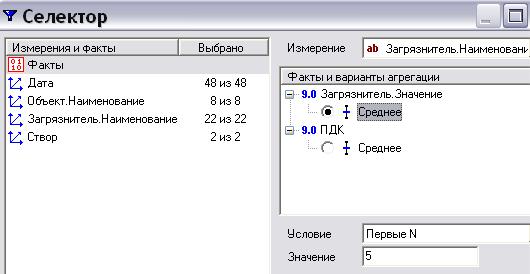
Чтобы осуществить фильтрацию по значениям фактов необходимо во всплы-
вающем меню или на панели инструментов нажать кнопку  , после чего будет от-
, после чего будет от-
крыто окно селектора (рис. 14).
Рис. 14. Окно селектора Слева отображаются все измерения куба и поле Факты, означающее филь-
трацию по фактам. Справа находятся элементы:
Измерение. Фильтрация подразумевает, что в таблице останется лишь часть значений некоторого измерения. Это поле как раз и задает измерение, значе-
ния которого будут отфильтрованы;
Факты и варианты агрегации. В кубе может содержаться один и более фак-
тов. Фильтрация будет происходить по значениям выбранного здесь факта.
Для факта выбирается функция агрегации, в соответствии с которой отбира-
ются записи.
Условие – условие отбора записей по значениям выбранного факта.
Условие может принимать различные значения, перечислим некоторые из них.
Первые N. Значения измерения сортируются в порядке убывания факта и вы-
бираются первые N значений измерений. Таким образом, можно, например,
выделить 5 загрязнителей, больше всех превышающих ПДК или 10 наиболее продаваемых товаров, или первые 5 наиболее удачных дней.
29
Последние N. Значения измерения сортируются в порядке убывания факта и выбираются последние N значений измерений. Например, 10 наименее попу-
лярных товаров.
Доля от общего. Значения измерения сортируются в порядке убывания факта.
В этой последовательности выбирается столько первых значений измерения,
сколько в сумме дадут заданную долю от общей суммы. Например, можно отобрать клиентов, приносящих 80% прибыли, или товары, дающие 50 % объ-
ема продаж.
Диапазон, Больше, Меньше – отбираются записи, для которых значение соот-
ветствующего факта лежит в заданном диапазоне, больше или меньше указан-
ного значения.
2.3.3. Раздел 3. Data Mining: классификация и регрессия. Машинное обуче-
ние. Деревья решений.
Информационный подход к анализу данных получил распространение в таких методиках извлечения знаний, как KDD (Knowledge Discovery in Databases, извлече-
ние знаний из баз данных) и Data Mining (интеллектуальный анализ данных). Сего-
дня на базе этих методик создается большинство прикладных аналитических реше-
ний в бизнесе и многих других областях. KDD включает в себя этапы подготовки данных, выбора информативных признаков, очистки, построения моделей, посто-
бработки и интерпретации полученных результатов. Ядром или шагом процесса
KDD являются методы Data Mining, позволяющие обнаруживать закономерности и знания.
Knowledge Discovery in Databases – процесс получения из данных знаний в ви-
де зависимостей, правил, моделей, обычно состоящий из таких этапов, как выборка данных, их очистка и трансформация, моделирование и интерпретация полученных результатов.
Data Mining (DM) – обнаружение в «сырых» данных ранее неизвестных, не-
тривиальных, практически полезных и доступных интерпретации знаний, необхо-
30