

8879
.pdfговая точка приносит наибольшую суму продаж? Постройте кросс-диаграмму сумм продаж: общие продажи, продажи по торговым точкам, продажи по то-
варным группам.
2.То же, что в п.1, но за последние три месяца от имеющихся данных.
3.То же, что в п.1, но за последние три недели от имеющихся данных.
4.Найти сумму максимальной и средней стоимости покупки за последний месяц от имеющихся данных.
5.Сформировать многомерный отчет и график загруженности торговых точек по времени суток и торговым точкам. На какие часы приходятся пики продаж?
6.То же, что в п.5, но за последние три месяца от имеющихся данных.
7.Сформировать многомерный отчет и график загруженности торговых точек по дням недели.
8.То же, что в п.7, но за последний месяц от имеющихся данных.
9.Сформировать многомерный отчет и график загруженности торговых точек по дням месяца.
10.То же, что в п.9, но за последние три месяца от имеющихся данных.
11.20 самых продаваемых товаров.
12.То же, что в п.11, но за последние три недели от имеющихся данных.
13.10 самых продаваемых товаров по воскресеньям.
14.5 самых популярных товаров в каждой товарной группе.
15.То же, что в п.14, но за последнюю неделю от имеющихся данных.
16.Товары, дающие 50% объема продаж.
17.То же, что в п.16, но за последние три месяца от имеющихся данных.
18.То же, что в п.16, но за последнюю неделю.
19.10 самых продаваемых товаров с 18 до 21 часа.
20.10 товаров, пользующихся наименьшим спросом осенью.
21.Товары, дающие 50% объема продаж в летние месяцы.
101
Раздел 3.
Задание 1. Классификация на основе Дерева решений
Разделить все районы Нижегородского региона на различные классы по уровню дохода бюджета при помощи инструментов Квантование и Дерево решений
(данные взять из файла показатели.txt или из созданного ранее ХД Регион).
Для этого:
а) Нужно найти средние значения показателей по каждому району за весь исследуемый период;
б) Значения поля «доход бюджета» при помощи обработчика «Квантование» нужно разбить на три диапазона «низкий доход», «средний доход», «высокий доход».
в) С помощью обработчика «Дерево решений» получить правила, применяя которые можно определить к какому их трех возможных уровней дохода будет относиться произвольный район.
г) Оценить качество построенной классификационной модели по таблице сопряженности и соответствующей ей диаграмме.
Задание 2. Классификация на основе Дерева решений
1) Построить классифицирующее Дерево решений (рис. 4.36) для отнесения водных объектов на основе рассчитанного ранее в практической работе 3 показателя ИЗВ (индекс загрязнения воды) к определенному классу вод, используя критерии,
описанные в таблице.
Таблица. Классы качества вод в зависимости от значения ИЗВ
Значение ИЗВ |
Воды |
|
до 0,2 |
Очень чистые |
|
0,2 |
– 1,0 |
Чистые |
|
|
|
1,0 |
– 2,0 |
Умеренно загрязненные |
2,0 |
– 4,0 |
Загрязненные |
4,0 |
– 6,0 |
Грязные |
6,0 |
– 10,0 |
Очень грязные |
2) Результаты классификации отобразить на диаграмме «Процентное соотно-
шение качества вод региона» (рис. 63). Ответить на вопрос: какой процент водных объектов Нижегородской области относится к классу Загрязненных вод.
102

Рис. 63. Дерево решений
Рис. 64. Диаграмма «Процентное соотношение качества вод региона»
Задание 3. Построение модели отклика получателей рассылки на актив-
ных и неактивных при помощи алгоритма построения дерева решений.
Торговая компания, осуществляющая продажу товаров, располагает информа-
цией о своих клиентах и их покупках. Компания провела рекламную рассылку 13 504 клиентам и получила отклик в 14,5 % случаев. Необходимо построить модели отклика и проанализировать результаты, чтобы предложить способы минимизации издержек на новые почтовые рассылки.
Данные находятся в файлах responses1.txt (обучающее множество) и responses2.txt (тестовое множество). Они представлены таблицами со следующими полями:
Таблица 1 – Поля наборов данных «Отклики»
N |
Поле |
Описание |
Тип |
1 |
Код клиента |
Уникальный идентификатор |
целый |
2 |
Пол |
Пол клиента |
строковый |
103
3 |
Сколько лет клиенту |
Число лет с момента первой покупки. Если |
целый |
|
|
менее года, то в поле стоит 0 |
|
4 |
Кол-во позиций товаров |
Сколько уникальных товаров приобретал клиент |
целый |
5 |
Доход с клиента, тыс. ед. |
Суммарная стоимость всех заказов клиента |
вещест. |
6 |
Число покупок в тек. году |
Сколько раз клиент делал заказ в текущем году |
целый |
7 |
Обращений в службу |
Сколько раз клиент обращался в службу поддержки |
целый |
|
поддержки |
|
|
8 |
Задержки платежей |
Задержки клиента фиксируются, когда длительное |
целый |
|
|
время после заказа оплата не поступает |
|
9 |
Дисконтная карта |
Является ли клиент участником дисконтных про- |
целый |
|
|
грамм, дающих право на скидки |
|
10 |
Возраст |
Возраст клиента |
целый |
11 |
Отклик |
Отклик клиента на последнюю рассылку. |
целый |
|
|
Значение «1» означает, что клиент совершил покуп- |
|
|
|
ку после прямой адресной рассылки. |
|
12 |
Дата отклика |
Информационное поле (пустое, если отклика не было) |
дата |
1. Построить и изучить Матрицу корреляции для оценки влияния входных перемен-
ных на выходную.
2.Для получения правил классификации запустить обработчик Дерево решений.
3.Изучите визуализаторы «Дерево решения», «Правила», «Значимость атрибутов», «Матрица классификации».
4.Изменяя порог отсечения построить новые модели, выбрать модель, лучшую с точки зрения точности и интерпретации. Выписать наиболее значимые правила. 5.Построить дерево решений на сбалансированном обучающем множестве и по-
смотреть те же визуализаторы и сделать вывод о качестве моделей.
6. Построить интерактивное дерево решений на сбалансированной выборке, приняв во внимание пожелания экспертов:
Первым атрибутом должен быть «Сколько лет клиент».
Вторым атрибутом – «Доход с клиента». Всех клиентов нужно разбить на 3
категории: малоприбыльные (до 20 тыс. ед.), дающие умеренный (от 20 тыс.
до 50 тыс. ед.) и высокий доход (свыше 50 тыс.ед.).
7. Изучить визуализаторы для интерактивного дерева. Выписать наиболее значи-
мые и интересные правила.
8. Прогнать через лучшую модель тестовое множество и сделать выводы о каче-
стве классификации.
9. Проведенное исследование оформить в виде отчета.
104
Раздел 4.
Задание 1.
Дана небольшая база:
Т01 |
Сливы, салат, помидоры |
Т02 |
Сельдерей, конфеты, |
Т03 |
Конфеты |
Т04 |
Яблоки, морковь, помидоры, картофель, конфеты |
Т05 |
Яблоки, апельсины, салат, конфеты, помидоры |
Т06 |
Персики, апельсины, сельдерей, помидоры |
Т07 |
Фасоль, салат, помидоры |
Т08 |
Апельсины, салат, морковь, помидоры, конфеты |
Т09 |
Яблоки, бананы, сливы, морковь, помидоры, лук, кон- |
|
феты |
Т010 |
Яблоки, картофель |
1)Приняв пороговое значение поддержки, равное 35%, найдите популярные трех-предметные наборы.
2)Для данных таблицы 1 нужно рассчитать показатели: Поддержка (S), Досто-
верность (С), Лифт (L), Леверидж (Рычаг) (T), Улучшение (I) для наборов: а)
салат -> помидоры; б) конфеты -> помидоры.
Задание 2.
Для транзакций (см. таблицу) найти ассоциативные правила, используя метод apriori (Порог=4). Выявить значимые правила (Поддержка ≥ 20%, достоверность ≥
80%)
1 |
a, b, c, d, e |
2 |
a, b, c |
3 |
a, c, d, e |
4 |
b, c, d, e |
5 |
b, c |
6 |
b, d, e |
7 |
c, d, e |
Задание 3.
1)Для данных таблицы рассчитать показатели: Поддержка (S), Достоверность (С),
Лифт (L), Леверидж (Рычаг) (T), Улучшение (I) для всех наборов. Количество набо-
ров можно рассчитать по формуле:
105
2)Перечислить правила, у которых поддержка ≥ 20%, достоверность ≥ 80%
3)Найти ассоциативные правила, используя метод a-priori (Порог=4). Выявить значи-
мые правила (Поддержка ≥ 20%, достоверность ≥ 80%)
4)Построить FP - дерево
Т01 |
Капуста, перец, кукуруза |
Т02 |
Спаржа, кабачки, кукуруза |
Т03 |
Конфеты |
Т04 |
Кукуруза, помидоры, фасоль, кабачки |
Т05 |
Перец, кукуруза, помидоры, фасоль |
Т06 |
Кабачки, спаржа, фасоль, помидоры |
Т07 |
Помидоры, кукуруза |
Т08 |
Капуста, помидоры, перец |
Т09 |
Кабачки, спаржа, фасоль |
Т010 |
Фасоль, кукуруза |
Т011 |
Перец, капуста, фасоль, кабачки |
Т012 |
Спаржа, фасоль, кабачки |
Т013 |
Кабачки, кукуруза, спаржа, фасоль |
Т014 |
Кукуруза, перец, помидоры, фасоль, капуста |
Задание 4.
1.Загрузить данные transactions.txt
2.Настройки параметров построения ассоциативных правил:
Поддержка: 1%< S<20%
Достоверность: 40%< S<90%
Записать:
Количество популярных наборов =
Количество популярных наборов, удовлетворяющих поддержке >6% =
Количество правил =
Товары – лидеры продаж, (имеющие поддержку в нашей задаче)>10%:
Указание: используйте фильтр в визуализаторе «Популярные наборы».
Тривиальные правила (включающие лидеры продаж):
Тривиальные правила (экспертное мнение):
Полезные правила:
106
Непонятные правила:
3.Изменить настройки параметров построения ассоциативных правил Поддержка: 1%< S<100%
Допустимая достоверность: 40%< S<90%
Записать:
Количество популярных наборов =
Количество правил =
Тривиальные правила (включающие лидеры продаж):
Тривиальные правила (экспертное мнение):
Полезные правила:
Непонятные правила:
Для Полезных правил найти и проанализировать показатели значимости: S, C, L, T, I
4.Изменить настройки параметров построения ассоциативных правил Поддержка: 1%< S<25%
Допустимая достоверность: 40%< S<90%
Записать:
Количество популярных наборов =
Количество правил =
Тривиальные правила (включающие лидеры продаж):
Тривиальные правила (экспертное мнение):
Полезные правила:
Непонятные правила:
Для Полезных правил найти и проанализировать показатели значимости: S, C, L, T, I
5.Изменить настройки параметров построения ассоциативных правил Поддержка: 1%< S<25%
Допустимая достоверность: 25%< S<40%
Записать:
107
Количество популярных наборов =
Количество правил =
Тривиальные правила (включающие лидеры продаж):
Тривиальные правила (экспертное мнение):
Полезные правила:
Непонятные правила:
Для Полезных правил найти и проанализировать показатели значимости: S, C, L, T, I
6.Изменить настройки параметров построения ассоциативных правил Поддержка: 1%< S<25%
Допустимая достоверность: 1%< S<30%
Записать:
Количество популярных наборов =
Количество правил =
Тривиальные правила (включающие лидеры продаж):
Тривиальные правила (экспертное мнение):
Полезные правила:
Непонятные правила:
Для Полезных правил найти и проанализировать показатели значимости: S, C, L, T, I
7.Сделать вывод, оформить отчет:
Какие полезные правила выявлены:
Какое максимальное значение лифта было зафиксировано? Какое прави-
ло имеет максимальный лифт?
Заказчика, в частности, интересует, какие товары покупают к поздрави-
тельной открытке. Сколько таких товаров? Какая из ассоциаций здесь представляет наибольший интерес (имеет максимальный лифт)
как полезные правила применять на практике.
108

Задание 5. Ответить на вопросы теста.
1.[……...............................] – это некоторое множество событий, происходящих совместно
2.Задача ассоциации впервые возникла
□в торговле при анализе рыночной корзины
□при анализе веб-логов
□при исследовании действия побочных эффектов лекарств
3.Предметный набор {карандаш, ручка, блокнот} является
□ 1-предметным □ 2-предметным □ 3-предметным □ k-предметным
4.Отметьте верные суждения: □ лифт ассоциативного правила показывает, какой процент транзакций поддерживает данное правило
□достоверность позволяет оценить полезность правила
□правило со значением показателя улучшения большим 1 говорит о том, что правило полезнее случайного угадывания
□лифт ассоциативного правила A>B равен лифту правила B>A
□S(не A)=1–S(A), где S – поддержка набора A
5.Из общего количества 1000 покупок в магазине было приобретено 300 мобильных телефонов, а 100 человек, из купивших телефон, приобрели и чехол к нему. Поддержка правила Телефон >
Чехол равна
6.Часто встречающееся множество или популярный предметный набор это:
□ предметный наборы с поддержкой, больше либо равной заданного порога; □ предметный набор с поддержкой, меньше либо равной заданного порога; □ предметный набор с достоверно-
|
стью, больше либо равной заданного порога; □ предметный набор с достоверностью, меньше ли- |
|
|
бо равной заданного порога. |
|
7. |
Для расчета левережда используется достоверность: □ да |
□ нет |
8.Один из первых популярных алгоритмов генерации ассоциативных правил это:
□ back propagatin |
□ a posteriori |
□ SOM |
□ a priori □ FPG |
□ a posteriori |
9.В ассоциативном правиле A B вероятность того, что из наличия в транзакции товара A следует наличие в ней товара B показывает значение
|
□ достоверности; |
□ левереджа; |
□ улучшения; □ лифта; □ поддержки |
||||
10. |
|
|
|
|
|
|
|
|
Следствие В |
Условие А |
|
Поддержка А В |
ДостоверностьА В |
Поддержка В |
|
|
|
карандаши |
|
4% |
|
29% |
17% |
|
конфеты |
зубная паста |
|
3% |
|
20% |
17% |
|
|
открытка |
|
1% |
|
45% |
17% |
|
Какова ожидаемая вероятность того, что клиент купит конфеты: |
|
|||||
11.Дана небольшая база:
Приняв пороговое значение поддержки, равное 30%, найдите все популярные наборы (начиная с двух-предметных) и выберите правильный вариант из списка:
□АВ,AF,AD,CD,CG,CF,ABD,DFG
□AB,AC,AD,BD,CD,CF,ABC,ABD
□AB,AC,AD,CD,CG,DF,CDG,ABC
□AB,AC,AD,CD,CG,DF,DG,ACD
□AB,AC,AD,CD,CG,DF,DG,ACD, CDG
□Свое решение:
109

Раздел 5.
Задание 1.
Построить нейронную сеть, позволяющую аппроксимировать заданную много-
мерную нелинейную функцию:
Подготовить обучающую выборку средствами приложения Microsoft Excel и
оформить ее в виде текстового файла с разделителями.
Рекомендации: Чтобы создать набор случайных чисел, нужно использовать функцию Excel СЛЧИС(). Затем случайные числа следует перевести в нужный диа-
пазон и рассчитать значение заданной функции в соседнем столбце.
Провести обучение нескольких нейронных сетей (с различной архитектурой) с
помощью Deductor по алгоритму обратного распространения;
Проверить качество каждой обученной сети с помощью диаграммы рассеяния.
Выбрать наилучшую модель и оценить точность аппроксимации.
Общее задание: f x1 x2 (использовать готовый файл multi.txt)
Индивидуальные задания:
1. |
f |
x1 x2 |
x |
4 |
x |
5 |
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|||||||||||
|
|
|
|
|
x3 |
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
2. |
f |
x1 |
20Sin(x2 ) 5x3 |
|
x4 |
||||||||||||||
e x5 |
|||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
x |
x |
2 |
|
|
|
|
|
|
|
|
|
|
|
||
3. |
f |
|
1 |
|
2 |
Sin(x |
4 |
x |
5 |
) |
|
|
|||||||
|
|
|
|
|
|
||||||||||||||
x3 |
|
|
|
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
4.f x1 x2 x3 x4 x52
5. |
f 0,5Cos(x |
x |
|
)2 |
|
|
|
1 |
|
|
x |
|
2 |
|
|
|
|
|
5 |
||||||
|
|
|
|
|
||||||||
|
1 |
|
|
|
x |
|
x |
|
2 |
|
||
|
|
|
|
|
|
3 |
4 |
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
6.f 5x1 Cos(x2 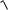
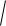 x3 ) Sin(x4 x25 )
x3 ) Sin(x4 x25 )
7.f 3Cos(x1 x2 ) 2Sin(x3 ) ln x4 10x52
110