

8879
.pdfЕще одной операцией, которая может понадобиться при консолидации дан-
ных, является их обогащение.
Обогащение – процесс дополнения данных некоторой информацией, позволя-
ющей повысить эффективность решения аналитических задач.
Обогащение позволяет более эффективно использовать консолидированные данные. Его необходимо применять в тех случаях, когда данные содержат недоста-
точно информации для удовлетворительного решения определенной задачи анализа.
Обогащение данных позволяет повысить их информационную насыщенность и, как следствие, значимость для решения аналитической задачи.
Место консолидации в общем процессе анализа данных может быть представ-
лено в виде структурной схемы (рис. 1.).
Рис. 1. Процесс консолидации данных
Оценка качества данных, очистка и предобработка
Оценка качества данных является необходимым этапом в процессе подготовки их к загрузке в хранилище данных и дальнейшего их анализа. Она позволяет свое-
временно выявить в данных проблемы, которые не позволят их корректно анализи-
ровать, снизят значимость и достоверность результатов анализа, следствием чего может стать выработка неверных управленческих решений. Контроль качества дан-
11
ных должен проводиться на всех этапах аналитического процесса – от извлечения данных из источников до их обработки в аналитической системе, поскольку для каждого этапа характерно наличие своих проблем с качеством данных.
Проблемы с качеством встречаются в отдельных наборах данных – таких, как файлы и базы данных, например, как результат ошибок при вводе, утери информации и других загрязнений данных. Когда интеграции подлежит множество источников данных, например в хранилищах, интегрированных системах баз данных или глобальных информационных Интернет-системах, необходимость в очистке данных существенно возрастает. Это происходит оттого, что источники часто содержат разрозненные данные в различном представлении.
Термин «качество данных» появился задолго до IT-технологий. Изначально под качеством данных понималось количество ошибок при вводе и форматировании данных. В контексте современных аналитических технологий качество данных –
совокупность их свойств и характеристик, определяющих степень пригодности к анализу.
Сравнительная характеристика уровней качества данных приводится в табл. 1.
Таблица 1.
Уровни качества данных
Уровень |
Факторы |
|
|
Проявления |
|||
Технический |
Нарушения в структуре данных |
Мешают |
|
||||
|
Некорректное |
|
наименование |
интегрированию |
|
||
|
таблиц и полей |
|
|
|
данных, их загрузке в |
||
|
Некорректные |
|
форматы |
и |
ХД и в аналитические |
||
|
кодировки данных |
|
|
системы |
|
||
|
Нарушение |
полноты |
и |
|
|
|
|
|
целостности данных |
|
|
|
|
||
|
Противоречия |
и |
дубликаты |
на |
|
|
|
|
уровне таблиц и файлов БД |
|
|
|
|
||
Аналитический |
Пропуски |
|
|
|
Снижают |
|
|
|
Аномальные |
и |
фиктивные |
достоверность |
данных |
||
|
значения, опечатки |
|
и искажают результаты |
||||
|
Шумы |
|
|
|
их |
анализа, |
не |
|
Противоречия |
и |
дубликаты |
на |
позволяют |
|
|
|
уровне записей |
|
|
|
использовать некоторые |
||
|
|
|
|
|
аналитические методы |
||
|
|
|
12 |
|
|
|
|

Концептуальный |
Собранные |
и |
Отсутствие |
или |
|
консолидированные |
|
недостаток данных для |
|
|
данные в недостаточной мере |
|
анализа |
|
|
отражают исследуемые процессы |
|
|
|
С целью повышения качества данных используется комплекс методов и алго-
ритмов, получивших название очистка данных (cleaning, refinement).
Предобработку данных можно рассматривать как комбинацию методов очистки и специальных методов оптимизации данных для решения конкретной аналитической задачи и приведения их в соответствие с требованиями,
определяемыми спецификой задачи и способами ее решения.
Соотношение между очисткой и предобработкой дается на схеме (рис.2).
Рис. 2. Связь между очисткой и предобработкой Типичный набор инструментов предобработки и подготовки данных к анализу,
поставляемый с большинством аналитических платформ, содержит следующие средства:
1.Очистка от шумов и сглаживание рядов данных.
Очень часто ряды данных содержат быстрые случайные изменения значений,
которые можно рассматривать как шум. Шум мешает выполнять анализ данных,
13
делает неустойчивой работу аналитических алгоритмов, не позволяет обнаруживать
вданных скрытые закономерности, структуры, тенденции.
2.Восстановление пропущенных значений необходимо, потому что пустые значения вызывают неопределенность при работе многих аналитических алгоритмов. Даже одно пропущенное значение может вызвать сбой в процессе анализа данных, который может привести к непредсказуемым результатам. Если же пропущенных данных много, то это может привести к недостаточному объему информации в анализируемой выборке.
3.Редактирование аномальных значений.
Аномальные значения также требуют большого внимания при подготовке данных к анализу. В большинстве случаев они являются просто ошибками ввода.
Если же аномальные значения – это действительные события, вызванные исключительными обстоятельствами, то они все равно не отражают реальную ситуацию в исследуемом процессе, а только искажают истинную его картину. С
другой стороны, исследование аномального поведения данных позволит прогнозировать условия, вызывающие аномальные события и их последствия,
исследовать реакцию информационно-аналитических систем на аномальные изменения условий.
4.Обработка дубликатов и противоречий.
Дубликаты и противоречия также весьма распространенные явления в данных.
Дубликатами являются просто одинаковые данные (записи). Они могут дублировать информацию об одном и том же событии, а могут содержать идентичную информацию о двух различных, но похожих событиях. В первом случае дубликаты должны быть просто удалены, а во втором случае требуют более тонкой обработки.
Противоречия возникают там, где нарушается логика причинно-следственной связи.
Например, два одинаковых события являются следствием различных исходных условий, или одинаковые условия породили различные события. Противоречия существенно мешают анализу данных, особенно при использовании их для
14
построения систем, основанных на обучении (нейронных сетей, деревьев решений и т.д.).
5.Снижение размерности входных данных.
В основе работы большинства аналитических моделей лежит принцип обобщения, т.е. чтобы получить на выходе модели даже единственное значение,
нужно подать на её вход некоторый набор значений, на основе соотношений между которыми и будет определено выходное. При разработке аналитической модели изначально стараются привлечь максимум собранной информации об исследуемом объекте. Это влечет к тому, что набор входных переменных разрастается, что приводит к усложнению аналитической модели, делает ее уязвимой к некачественным данным, увеличивает время, требуемое на аналитическую обработку. Для снижения размерности производится поиск входных признаков
(атрибутов, показателей), которые обладают высокой степенью статистической взаимозависимости. Такие данные могут быть исключены из рассмотрения без существенного ущерба для результатов анализа.
6.Устранение незначащих факторов.
Не все имеющиеся в распоряжении аналитика данные являются одинаково важными с точки зрения целей анализа. Экономический показатель, включаемый в рассмотрение при анализе, должен вносить достаточный вклад в решение задачи,
участвовать в объяснении причинно-следственной связи между исходными данными и результатом, т.е. между входными и выходными факторами должна быть высокая степень взаимной зависимости. Если между каким-либо входным фактором и выходным результатом такая связь мала или вообще отсутствует, то использование этого входного фактора бессмысленно или даже вредно, поскольку может увести решение в ложном направлении. Чаще всего критерием для определения значимости входных факторов является некоторый показатель значимости, который согласовывается со степенью зависимости (корреляции) искомого решения от данного фактора. Если показатель значимости входного фактора меньше некоторого
15
порога, то этот фактор может быть определен как слабо влияющий на решение и исключен из рассмотрения без существенного ухудшения качества анализа.
В целом последние две задачи похожи, т.к. в них из анализа исключаются данные, которые в контексте решаемой задачи являются избыточными и только создают дополнительные вычислительные затраты, усложняют используемую аналитическую модель. Принципиальной разницей является только то, что в первом случае в качестве критерия для исключения факторов используется степень взаимной зависимости (корреляции) между входными факторами. Следовательно,
чем выше эта степень, тем больше оснований для исключения факторов. Во втором случае используется степень связи между входными факторами и результатом. Это значит, чем ниже эта степень, тем больше оснований для исключения фактора.
Методы и инструменты аудита данных в Deductor
Для проведения первичной оценки качества массива данных, представленного аналитику, необходима определенная последовательность действий, которую назы-
вают аудитом данных. Эту процедуру желательно проводить самой первой, она за-
канчивается отчетом и выводами о качестве данных.
Рассмотрим рекомендуемую схему аудита (рис.3).
16
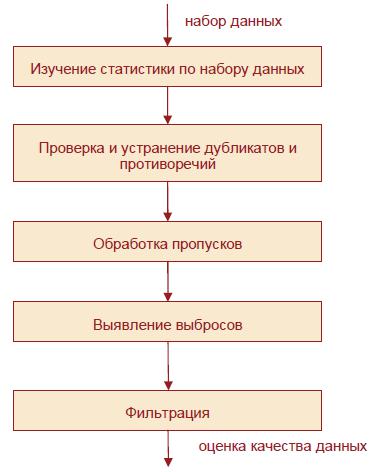
Рис. 3. Последовательность аудита данных Первичная оценка качества данных подразумевает, в первую очередь, выявле-
ние и обработку объективных ошибок и отклонений – дубликаты, противоречия,
пропуски, аномалии (для упорядоченных наборов еще присутствует процедура сглаживания). Аудит данных, как правило, не предполагает полную очистку данных и устранение всех проблем, он ориентирован больше на их идентификацию.
В таблице 2 сведены инструменты для решения задач аудита данных в
Deductor Studio.
|
|
|
Таблица 2 |
|
|
Методы и инструменты аудита данных в Deductor |
|||
№ |
Задача |
Метод |
Обработчик/ |
|
Визуализатор |
||||
|
|
|
||
1 |
|
Стандартные статистические |
Визуализатор Стати- |
|
|
Изучение ста- |
стика, статистические |
||
|
показатели: минимум, максимум, |
|||
|
тистики |
функции в обработчике |
||
|
среднее и т.п. |
|||
|
|
Калькулятор. |
||
|
|
|
||
|
|
17 |
|
|
2 |
Проверка и |
|
Обработчик и визуали- |
|
|
||
|
устранение |
|
|
|
|
затор Дубликаты и |
|
|
дубликатов и |
||
|
|
противоречия |
|
|
противоречий |
|
|
|
|
|
|
|
|
|
|
3 |
|
Для неупорядоченных данных: под- |
|
|
|
становка константы; подстановка |
|
|
|
среднего; подстановка наиболее ве- |
Обработчики Парци- |
|
Обработка |
роятного значения. |
|
|
альная обработка, |
||
|
пропусков |
Для упорядоченных данных: под- |
|
|
Калькулятор |
||
|
|
становка константы; подстановка |
|
|
|
|
|
|
|
среднего; интерполяция (путем |
|
|
|
сглаживания ряда). |
|
4 |
Выявление вы- |
Статистический метод на основе от- |
Обработчики |
|
клонения среднего от среднеквадра- |
Парциальная обработ- |
|
|
бросов |
||
|
тического отклонения. |
ка, Калькулятор |
|
|
|
2.3.2. Раздел 2. Оперативная аналитическая обработка данных OLAP.
OLAP (OnLine Analytical Processing, оперативная аналитическая обработка дан-
ных) является на сегодня одним из самых популярных методов анализа данных. Его основное назначение – поддержка аналитической деятельности, а также произволь-
ных (нерегламентированных) запросов лиц, принимающих решения. На основе
OLAP строятся многочисленные системы поддержки принятия решений и подготов-
ки отчетов.
Эта технология позволяет осуществлять многомерный анализ данных. Она мо-
жет применяться не только для подготовки отчетности, но и для первичной провер-
ки гипотез об изучаемой предметной области. Такие гипотезы неизбежно возникают в процессе анализа; для выработки качественных решений они должны быть прове-
рены на основе имеющейся информации.
Средства OLAP-системы должны обеспечить работу с данными в многомерном представлении данных – естественном на уровне ненормализованной ER-модели с полной поддержкой иерархий независимо от того, какие типы баз данных исполь-
зуются в качестве источников.
18
ВOLAP-системах предварительно подготовленная информация преобразуется
вформу многомерного куба; такими данными гораздо легче манипулировать, ис-
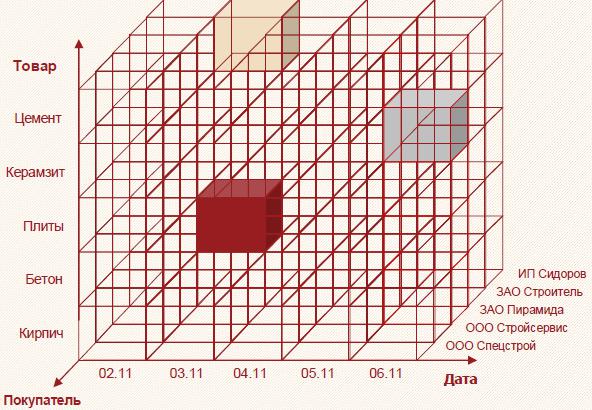
пользуя необходимые для анализа срезы (рис. 3.4).
Многомерный куб можно рассматривать как систему координат, осями которой являются измерения, например, Дата, Товар, Покупатель. По осям будут отклады-
ваться значения измерений – даты, наименования товаров, названия фирм-
покупателей, ФИО физических лиц и т. д.
Втакой системе каждому набору значений измерений (например, дата – товар
–покупатель) будет соответствовать ячейка, в которой можно разместить числовые показатели (то есть факты), связанные с данным набором. Таким образом, между объектами бизнес-процесса и их числовыми характеристиками будет установлена однозначная связь.
Принцип организации многомерного куба поясняется на рис. 4.
Рис. 4. Принцип организации многомерного куба
19
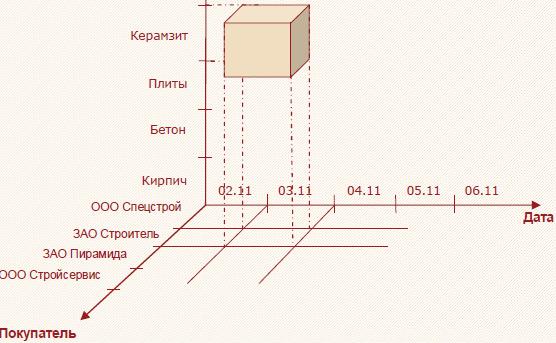
Рис. 5. Измерения и факты в многомерном кубе.
Многомерный взгляд на измерения Дата, Товар и Покупатель представлен на рис. 5. Фактами в данном случае являются Цена, Количество, Сумма. Выделенный сегмент содержит информацию о том, сколько плит, на какую сумму и по какой цене приобрела фирма ЗАО «Строитель» 3 ноября.
Визуализация OLAP-куба производится с помощью специального вида таб-
лиц, которые строятся на основе срезов OLAP-куба, содержащих необходимую пользователю информацию. Срезы, в свою очередь, являются результатом выполне-
ния соответствующего запроса к базе данных. Как правило, в процессе построения срезов пользователь с помощью мыши и клавиатуры манипулирует заголовками из-
мерений, добиваясь наиболее информативного представления данных в кубе. В за-
висимости от положения заголовков измерений в таблице автоматически формиру-
ется запрос к базе или хранилищу данных. Запрос извлекает данные из базы или хранилища, после чего OLAP-ядро системы визуализирует их.
Общую схему работы настольной OLAP системы можно представить следу-
ющим образом:
20