

Синтез речевого сообщения по правилам.
При формировании речевых сообщений по правилам словарь практически неограничен. В основе такого способа построения сообщений лежит формантный способ синтеза речи. На вход устройства, состоящего из лингвистического процессора и синтезатора, поступает текст (в виде орфографической записи) произвольного содержания, а на его выходе формируется сигнал, соответствующий звучащей речи. Многочисленные разновидности этого способа основаны на расчленении речевого сигнала на отдельные фонетические составляющие-фонемы, аллофоны, дифтонги. В базе данных синтезатора хранится информация не только об этих элементах речи, но и правила их модификации в зависимости от конкретного речевого сообщения.
При синтезе речи по правилам используется электронная модель голосового тракта человека (синтезатор) и лингвистический процессор. Их настройка выполняется для каждого отдельного элемента фонетического алфавита, а не для постоянного интервала времени.
Слайд 5. Синтез сообщения по правилам
Конструирование речевых сообщений при синтезе речи по правилам выполняется за два этапа.
1. Символьное представление текста преобразуется в фонетическое описание сообщения (эти действия выполняет лингвистический процессор).
2. Последовательность элементов фонетического алфавита преобразуется в последовательность управляющих слов для управления синтезатором.
Вначале получают фонетическое описание произносимого слова или фразы, т. е. последовательность элементов фонетического алфавита, включая паузы, с указанием длительности каждого из них. Для этого служит лингвистический процессор ЛП, показанный на слайде (6).
Слайд 6. Получение фонетического описания произносимого слова или фразы.
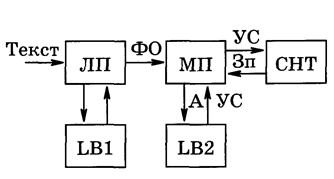
ЛП – лингвистический процессор;
LB1 – библиотека правил;
ФО – фонетическое описание;
МП – микропроцессор;
LB2 – библиотека кодов элементов фонетического описания;
А – адрес;
УС – управляющее слово;
Зп – запрос;
СНТ – синтезатор.
Последовательность слов и словосочетаний текста подается на его вход в виде символьного представления. Этот процессор на основе набора хранимых в библиотеке LB1 правил вырабатывает их фонетическое описание ФО. Эти правила определяются фонетическими особенностями языка. Правила, находящиеся в библиотеке, достаточно сложны и неоднозначны, они содержат большое число исключений, поэтому библиотека довольно большая, а лингвистический процессор создается на базе мощных микропроцессоров. Иногда человек-оператор создает словарь заранее с помощью ПК, т. е. он составляет фонетическое описание всех слов и словосочетаний будущей системы речевого вывода. Эти описания передаются в память синтезатора, т. е. словарь системы становится ограниченным.
Созданное лингвистическим процессором фонетическое описание передается в библиотеку LB2. Эта библиотека, состоящая из кодов элементов фонетического описания, используется для формирования управляющих слов УС, направляемых на синтезатор. Микропроцессор МП системы речевого вывода по адресу А получает из библиотеки управляющее слово, включающее, помимо набора параметров настройки синтезатора, параметр длительности звучания фонетического элемента, флаг цепи управляющих слов и ряд других признаков. Адресом управляющего слова служит соответствующий элемент фонетического алфавита. Для организации непрерывного звучания каждое следующее УС передается в синтезатор по его запросу Зп, если закончен интервал звучания, или следующего УС, если в предыдущем был установлен признак цепочки УС, означающий незавершенность воспроизведения фонетического элемента.