

1.5 Информационные меры
В теории передачи и преобразования информации установлены информационные меры количества и качества информации — семантические, структурные, статистические.
Семантический подход позволят выделить полезность или ценность информационного сообщения. В структурном аспекте рассматривают строение массивов информации и их измерение простым подсчетом информационных элементов или комбинаторным методом.
Структурный подход используют для оценки возможностей информационных систем вне зависимости от условий их применения. При использовании структурных мер информации учитывают только дискретное строение сообщения, количество содержащихся в нем информационных элементов, связей между ними. При структурном подходе различают геометрическую, комбинаторную и аддитивную меры информации.
Геометрическая мера определяет параметры геометрической модели информационного сообщения (длина, площадь, объем) в дискретных единицах. Эту меру применяют как для оценки информационной емкости всей модели, так и для оценки количества информации в одном сообщении.
В комбинаторной мере количество информации I определяют количеством комбинаций элементов (символов), которые совпадают с числом:
• сочетаний из q элементов по п:
![]()
например, для множества цифр 1, 2, 3, 4 можно составить шесть сочетаний по две цифры: 12, 13, 14, 23, 24, 34;
перестановок I = q!,
например, для множества букв а, в, с можно получить шесть перестановок: авс, асе, вас, вса, сав, сва;
размещений с повторениями из q элементов по п:
Например, для q = 0, 1 и n = 3 имеем: 000, 001, 010, 011, 100, 101, 110, 111.
Широкое распространение получила аддитивная мера.
Пусть N—число равновероятных сообщений, п — их длина, q — число букв алфавита, используемого для передачи информации. Количество возможных сообщений длины п равняется числу размещений с повторениями
N = qn. (1.11)
Эту меру наделяют свойством аддитивности, чтобы она была пропорциональна длине сообщения и позволяла складывать количество информации ряда источников. Для этого Хартли предложил логарифмическую функцию как меру количества информации (I):
I = log N = n log q. (1.12)
Количество информации, которое приходится на один элемент сообщения, называется энтропией (H).
H = I/n = log q. (1.13)
Основание логарифма зависит от выбора единицы количества информации. Если для алфавита используют двоичные цифры 0 и 1, то за основание логарифма принимают q = 2, в результате чего
I = n log2 2 = п.
При длине п = 1 получают I = 1 и это количество информации называют битом.
Передача сообщения длиной п = 1 эквивалентна выбору одного из двух возможных равновероятных сообщений — одно из них равно единице, другое — нулю. Двоичное сообщение длины п содержит п битов информации. Если основание логарифма равно 10, то количество информации измеряется в десятичных единицах — дитах, причем 1 дит = 3,32 бита.
Например, текст составлен из 32 букв алфавита и передается последовательно по телетайпу в двоичном коде. При этом количество информации I = log2N = log232 = 5 битов.
Далее используются логарифмы с основанием два.
В общем случае сообщения появляются с разной вероятностью. Статистическая мера использует вероятностный подход к оценке количества информации. Согласно Шеннону каждое сообщение характеризуется вероятностью появления, и чем она меньше, тем больше в сообщении информации. Вероятность конкретных типов сообщений устанавливают на основе статистического анализа.
Пусть сообщения образуются последовательной передачей букв некоторого алфавита:
х1, ..., хi ..., хq
с вероятностью появления каждой буквы: р(х1) = р1, ..., p(xi) =рi ..., р(хq) = рq,
при этом выполняется условие: р1 + ... + рi + ... + рq = 1.
Множество с известным распределением элементов называют ансамблем. Согласно Шеннону количество информации, которое содержится в сообщении хi, рассчитывают по формуле:
![]()
Для абсолютно достоверных сообщений рi = 1, тогда количество информации I(xi) = 0; при уменьшении значения pi количество информации увеличивается.
Пусть в ансамбле все буквы алфавита х1, ..., хi ... , хq — равновероятны, то есть p1 = р2 = ... = рq = 1/q, и статистически независимы. Тогда количество информации в сообщении длиной n букв с учетом выражения (1.4)
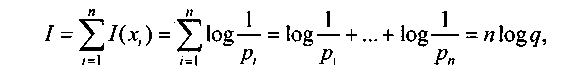 (1.14)
(1.14)
что совпадает с мерой Хартли в соответствии с выражениями (1.11) и (1.12).
Согласно Шеннону информация — это снятие неопределенности, что понимают следующим образом. До опыта событие (например, появление буквы хi) характеризуют малой начальной вероятностью рн, которой соответствует большая неопределенность. После опыта неопределенность уменьшается, поскольку конечная вероятность рк > рн. Уменьшение неопределенности рассчитывают как разность между начальным IH и конечным IК значениями количества информации.
Например, для рH = 0,1 и рK = 1 получим:
∆I = IH
– IK
= log
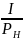 - log
- log
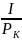 = log 10 – log 1 = 3.32
= log 10 – log 1 = 3.32
Пусть сложное сообщение характеризуется алфавитом из букв х1, х2, ..., хq, их вероятностями р1, р2, .... рq и частотой появления каждой буквы m1, m2, ..., mq. Все сообщения статистически независимы, при этом m1, + m2 + ... + mq = m.
Общее количество информации для всех q типов сообщений с учетом выражения (1.14)
![]()
Среднее значение количества информации на одно сообщение (энтропия) согласно формуле Шеннона
![]()
где при большом значении m отношение mi/m характеризует вероятность рi каждой буквы. Выражение log1/pi, рассматривают как частную энтропию, которая характеризует информативность буквы xi, а энтропию Н— как среднее значение частных энтропии. При малых значениях pi частная энтропия велика, а с приближением pi, к единице она приближается к нулю (рис. 1.5, а).
Функция η = (Pi) = pi log1/p, отражает вклад буквы хi в энтропию Н. Как видим, при pi = 1 эта функция равна нулю, затем возрастает до своего максимума и при уменьшении рi приближается к нулю. Функция η(pi) при значении pi = 0,37 имеет максимум 0,531.
Интерес представляют сообщения с использованием двухбуквенного алфавита х1 и х2 (например, цифры 0 и 1).
Поскольку при q = 2 вероятность букв алфавита p1 +p2 = 1, то можно положить, что p1 = р и р2 = 1 -р. Тогда энтропию определяют соотношением:
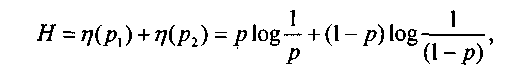 (1.15)
(1.15)
график которой показан на рис.1.5, б. Он образуется суммированием двух графиков, определяющих энтропию каждой из двух букв. Из графиков видно, что при p = 0 или р = 1 энтропия равна нулю и неопределенность полностью снимается. Это означает, что с вероятностью, равной единице, можно знать, каким будет следующее сообщение.
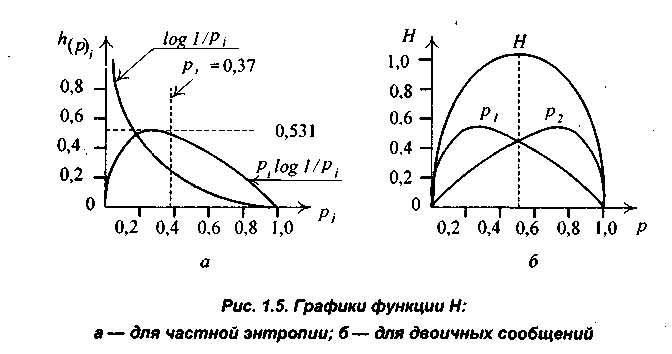
Энтропия двухбуквенных сообщений достигает максимального значения, равного 1 биту, при р = 0,5, и ее график симметричен относительно этого значения. Это тот случай, когда наиболее трудно предугадать, какое сообщение будет следующим, — то есть ситуация наиболее неопределенная.
В общем случае энтропия обладает следующими свойствами.
Энтропия — величина вещественная, непрерывная, ограниченная и неотрицательная.
Энтропия равна нулю, если сообщение заранее известно. В этом случае некоторое сообщение задано с вероятностью рi = 1, а вероятность остальных равна нулю.
Энтропия максимальна, если все сообщения равновероятны: р1 =р2 = ... = рq = 1/q...
В этом случае на основании выражения (1.15) получим:
![]()
что совпадает с выражением (1.3). В этом случае оценки количества информации по Хартли и Шеннону совпадают.
При неравных вероятностях количество информации по Шеннону меньше меры Хартли.
При объединении энтропии двух независимых источников сообщений их энтропии складываются.
В компьютере наименьшей возможной единицей объемной (геометрической) меры информации является бит. Объем (или емкость) информации вычисляется по количеству двоичных символов 0 и 1, записанных в памяти компьютера. При этом возможно только целое число битов в отличие от вероятностного подхода, где может быть и нецелое число.
Для удобства использования введены также единицы количества информации, превышающие бит. Так, двоичное слово из восьми символов содержит 1 байт информации, 1024 байт составляют килобайт (Кбайт), 1024 Кбайт — мегабайт (Мбайт) и 1024 Мбайт — гигабайт (Гбайт); при этом 1024 = 210
Между объемным и вероятностным количествами информации соотношение неоднозначное. Если сообщение допускает измерение количества информации и объемно и вероятностно, то они не обязательно совпадают. При этом вероятностное количество не может быть больше объемного. В дальнейшем тексте количество информации понимается в объемном значении.
Замечание
Международная система единиц измерения величин СИ (SI) устанавливает специальные приставки для получения кратных и дольных единиц измерения во всех областях науки и техники. Эти приставки имеют полные наименования и сокращенные обозначения и позволяют умножать значение основной единицы на определенную степень числа 10. Для удобства мы будем называть эти приставки десятичными. Приведем наиболее важные десятичные приставки.
Название приставки Сокращение приставки Значение приставки
кило к 103 = 1000
мега М 106 = 1 000 000
гига Г 109 = 1 000 000 000
тера Т 1012 = 1 000 000 000 000
пета П 1015 = 1 000 000 000 000 000
Ни в одной области науки и техники эти приставки не могут иметь другие значения. И компьютерные технологии тоже не могут отменить правила системы СИ.
Проблема с приставками возникла из-за того, что в ряде областей информатики удобнее применять приставки не с десятичным значением, а с двоичным. Например, при измерении объема оперативной памяти компьютера. Производители микросхем оперативной памяти обычно указывают емкость схемы в Мбитах. Маркировка вида 64Мх8 означает, что емкость составляет 512 Мбит (64 • 8 = 512). Буква М означает здесь вовсе не миллион, а два в двадцатой степени, т. е. степень двух, наиболее близкую к шестой степени десяти. Эта величина больше, чем миллион, и составляет 1 048 576. Соответственно, емкость в битах надо вычислять следующим образом:
512 ∙ 1 048 576 = 536 870 912 (бит).
Емкость устройства или одного модуля оперативной памяти обычно выражают в более крупных единицах: Мбайтах или Гбайтах. И здесь символы МиГ тоже надо использовать с двоичным значением. Причина использования двоичных приставок заключается в том, что адрес байта в электронных запоминающих устройствах задается в форме целого двоичного числа. Поэтому количество байтов в микросхемах и модулях памяти удобно делать таким, чтобы значение этого количества было степенью двух.
Проблемы с двоичными приставками начались позже. Первая причина — это быстрый рост размеров памяти компьютера. Возникла потребность в более крупных приставках. Появились двоичные приставки «М», «Г», «Т», и эти обозначения были выбраны неудачно — они полностью совпали с десятичными приставками СИ. Но была еще вторая причина, более серьезная. Кто-то решил для удобства называть двоичные кратные приставки так же, как это принято для десятичных. Таким образом, «Кбайты» стали «килобайтами», «Мбайты» — «мегабайтами» и т. д. Эта «вредная» привычка очень быстро распространилась среди пользователей.
Но это еще не всё. На ситуацию с приставками очень негативно влияет еще одна вещь. В информационных технологиях есть, по меньшей мере, две области, в которых правила системы СИ выполняются совершенно точно. Это производство жестких магнитных дисков и системы передачи данных (телекоммуникации).
При измерении емкости жестких дисков мегабайты и гигабайты являются десятичными единицами. Емкость диска на 200 гигабайт означает, что на этом диске можно записать примерно двести миллиардов байт. Двести обычных «десятичных миллиардов», а не тридцатых степеней двух. Причина, по которой производители жестких дисков предпочитают правила СИ, не только техническая, но и коммерческая. Количество десятичных гигабайтов всегда будет больше, чем двоичных. В системах передачи данных основной единицей количества информации является бит. При этом двоичные множители не имеют никаких объективных преимуществ перед десятичными. Поэтому в этой области правила системы СИ тоже не отменяются. При передаче данных по каналу связи один «килобит» (кб) должен означать одну тысячу бит, а один «мегабит» (Мб) — один миллион бит.
Таким образом, в информационных технологиях образовалась большая путаница с приставками. При вычислении мегабитов в системах передачи данных надо умножать количество битов на миллион, а при вычислении мегабитов в оперативной памяти — на два в двадцатой степени. Двести гигабайт на жестком диске — это двести миллиардов байт, а два ГБ в оперативной памяти — это уже больше, чем два миллиарда. Представить себе что-нибудь подобное в других областях науки и техники совершенно невозможно. Разве может один километр содержать тысячу метров при измерении длины реки, но 1024 метра при измерении высоты горы?
Международная электротехническая комиссия (МЭК) сделала попытку покончить с этим «ужасным» положением. В ноябре 2000 г. были приняты поправки к международному стандарту МЭК 60027-2 («Телекоммуникация и электроника»). Суть их состоит в следующем. Приставки системы СИ для образования кратных единиц разрешается использовать только с десятичным значением. То есть в одном килобите может быть только тысяча бит, а в одном мегабайте — только миллион байт. Для приставок с двоичным значением МЭК предлагает использовать следующее решение проблемы. Названия всех двоичных приставок меняются. От приставки СИ берутся только две первые буквы. К ним добавляется слог «би» (bi) — от английского «binary» («двоичный»). В результате образуется название новой приставки с двоичным значением.
Для наиболее распространенных двоичных приставок это должно выглядеть следующим образом:
Название приставки Сокращение приставки Значение приставки
киби Ки 210=1024
меби Ми 220= 1048 576
гиби Ги 230= 1 073 741 824
теби Ти 240 = 1 099 511 627 776
пеби Пи 250 = 1 125 899 906 842 624
Теперь основы для противоречий больше нет. Двоичные приставки получили свои собственные названия и обозначения. Один кибибайт данных (КиБ) содержит 1024 байт. Два гибибайта оперативной памяти (2ГиБ) — это 2 147 483 648 байт. Но все-таки говорить об успешном решении проблемы еще рано. У новых правил МЭК есть один, но очень большой недостаток: никто не спешит их выполнять. Мешают многолетняя привычка и традиции языка. Уж очень неудобно и непривычно для многих пользователей звучат эти «кибибиты» и «мебибайты».
На своих учебных занятиях, где двоичное значение приставки не ясно из контекста задачи, обычно дается специальный комментарий или добавляем прилагательное «двоичный». При этом часть условия может звучать примерно так: «объем данных составляет тридцать два двоичных килобайта». С одной стороны, студенты сразу понимают, какую приставку использовать при вычислении. С другой стороны, здесь нет слишком грубого нарушения правил системы СИ.