

Физическая реализация массивов
Мы рассмотрели как реализованы массивы в некоторых языках программирования. Если абстрагироваться от деталей, то становится видно, что массивы действительно практически одинаково выглядят в любом языке. Что же можно сделать с массивами? Создать, уничтожить, получить доступ к конкретному элементу, получить размерность, получить нижнее и верхнее значения конкретного индекса, изменить размер массива.
Не во всех языках возможно выполнение всех этих операций, не все операции кажутся очевидными. Например, создание и уничтожение массива. В языке Fortran эти операции нельзя выполнить явно. Но массивы тем не менее создаются и уничтожаются, автоматически, при входе в процедуру и при выходе из нее. (Собственно в Fortran IV массивы, как впрочем и локальные переменные процедур и функций, зачастую размещаются на этапе трансляции программы в статических областях памяти. При этом о создании и уничтожении массивов речи идти, естественно, не может. Однако, если компилятор размещает локальные переменные в стеке, то он просто обязан создавать и уничтожать массивы во время выполнения программы.)
Все элементы массива имеют один и тот же тип. Это очень важное замечание. Именно поэтому массивы относятся к однородным типам данных, в отличии от записей, объединений, деревьев, файлов и прочих типов данных, элементы которых могут быть различных типов.
Основой работы с массивами является доступ к отдельным элементам. Физически, массивы располагаются в оперативной памяти. Значит для доступа к элементу массива достаточно получить адрес этого элемента в памяти. Оперативная память представляет собой набор последовательно пронумерованых байт. По существу это одномерный массив байт. Элементы массива в языках высоко уровня могут занимать более одного байта. Кроме того массивы могут быть многомерными. Таким образом, для доступа к конкретному элементу массива в языке высоко уровня, необходимо решить задачу отображения этого массива на одномерный массив байт. Поверьте, это звучит страшнее, чем есть на самом деле.

Сначала определимся с понятиями. В оперативной памяти компьютера, кроме массивов, находятся и другие данные, а так же код программы и код операционной системы. Иначе говоря, массив занимает только часть памяти. Адрес памяти, с которого начинается массив, называется базовым адресом массива. Мы будем обозначать это base. Размер элемента массива будем обозначать как size. На рисунке изображен массив, элементы которго занимают по два байта. Нижняя граница индекса будет обозначаться low(), например нижняя граница индекса i будет выглядеть так, low(i). Соответственно верхняя граница будет обозначаться как high(). Сам массив будем обозначать как array.
Начнем разбираться с одномерных массивов с нижней границей индекса равной 0. Очевидно, что array[0] будет располагаться по адресу base. Следующий элемент, array[1], будет иметь адрес base+size. И так далее, array[2] расположиться по адресу base+size+size=base+2*size. В общем виде это можно записать так:
array[i]=base+i*size
Если допустить, что нижняя граница индекса не 0, то формула немного усложнится, оставаясь тем не менее простой и очевидной:
array[i]=base+(i-low(i))*size
Для неверящих формулам выполним проверку. Пусть у нас есть массив, нижняя граница индекса которого -5, а верхняя 5. Итак:
array[-5]=base+(-5+5)*size=base array[-4]=base+(-4+5)*size=base+size
Видно, что формулы дают правильные результаты.
Теперь попробуем разобраться с двумерными массивами. При этом мы сразу наталкиваемся на вопрос "какой индекс изменяется первым?". Порядок изменения индексов не важен с точки зрения языка высокого уровня, но важен с точки зрения вычисления адреса элемента. Те из Вас, кто изучал в институте язык Fortran, наверняка помнят задачи, в которых требовалось вывести на печать содержимое массива. Хитрость заключалась в том, что первый индекс соответствовал номеру строки, а второй номеру столбца. В языке Fortran при указании имени массива в операторе ввода-вывода, напрмер в операторе PRINT, первым изменяется первый индекс. В результате массив (его еще называли матрицей) печатается повернутым на 90 градусов. Решение было простое, использовать неявные циклы. Другие решения не принимались. Несмотря на явно учебный характер тех задач они показывали одну важную, и не всегда очевидную, проблему. Проблему переносимости данных через внешние носители. Если Ваша программа, на Вашем любимом языке программирования, выводит многомерный массив да диск, а другая программа, возможно даже на машине с другой архитектурой, читает этот массив, то Вы должны или явно указывать последовательность вывода каждого элемента массива, или быть уверены, что правила изменения индексов многомерного массива одинаковы в обоих случаях. Кстати, проблема последовательности передачи элементов информации очень важна при работе в сетях.
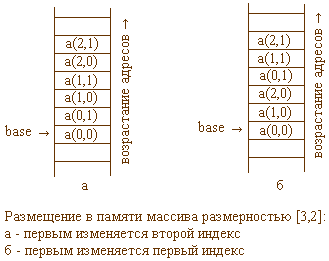
Однако вернемся к массивам. На рисунке показана разница в размещении элементов массива [3,2] в зависимости от того, какой индекс изменяется первым. Вычисление адреса элемента в обоих случаях выполняется одинаково. Для наглядности рассуждений примем, что первым изменяется второй индекс, то есть сначала в памяти размещаются элемены первой строки, затем второй, и так далее. Будем рассматривать массив array[i,j]. Адрес каждого элемента в строке будет вычисляться по тем же формулам, что и для одномерного массива. Для вычисления адреса начала каждой строки нам потребуется знать, сколько памяти занимает одна строка. Очевидно, что каждая строка является одномерным массивом (это кстати объясняет, почему многомерные массивы часто рассматриваются как массивы массивов) и занимает
(high(j)-low(j)+1)*size
байт оперативной памяти. Первая строка двумерного массива начинается с адреса base, вторая с адреса base+(high(j)-low(j)+1)*size. Значит формулу для вычисления адреса элемента двумерного массива можно получить из формулы для одномерного массива. Нужно только заменить base на приведенное выше выражение, с учетом номера строки
array[i,j]=base+(i-low(i))*(high(j)-low(j)+1)*size+(j-low(j))*size
Желающие могут упростить выражение вынеся size за скобки. Проверим формулу для массива [2,3]. При этом индекс i будет изменяться от 0 до 1, а j от 0 до 2, т.е. low(i)=0, high(i)=1, low(j)=0, high(j)=2. Пусть каждый элемент занимает по два байта, т.е. size=2.
a[0,0]=base+(0-0)*(2-0+1)*2+(0-0)*2=base a[0,1]=base+(0-0)*(2-0+1)*2+(1-0)*2=base+2 a[0,2]=base+(0-0)*(2-0+1)*2+(2-0)*2=base+4 a[1,0]=base+(1-0)*(2-0+1)*2+(0-0)*2=base+6 a[1,1]=base+(1-0)*(2-0+1)*2+(1-0)*2=base+8 a[1,2]=base+(1-0)*(2-0+1)*2+(2-0)*2=base+10
Как видно, результаты получились правильными. Для случая, когда первым изменяется первый индекс, формула сохраняется, поменяются лишь переменные i и j
array[i,j]=base+(j-low(j))*(high(i)-low(i)+1)*size+(i-low(i))*size
Массивы размерностью 3 ничего нового не привносят. Формула остается прежней, только base заменяется на выражение, учитывающее количество двумерных массивов и их размер. Напомню, что трехмерный массив можно рассматривать как одномерный массив двумерных массивов. Аналогично и четырехмерный массив можно рассматривать как одномерный массив трехмерных массивов. И так далее. Формулы приводить не буду. Попробуйте написать их сами.
Описаные формулы позволяют выполнить основную операцию - доступ к отдельным элементам массива. Операция создания массива сводится к определению требуемого объема памяти и собственно выделению памяти. Операция уничтожения массива просто освобождает ранее выделенную память. Операция изменения размера массива допускается достаточно редко. Если размер массива уменьшается, то просто освобождается часть занимаемой им памяти. Если размер массива увеличивается, что бывает гораздо чаще, то выделяется новый блок памяти соотвествующего размера, после чего содержимое массива копируется во вновь выделую память, а старый блок памяти освобождается. Так что изменение размера массива операция достаточно дорогостоящая и медленая.
Информационные функции, такие как получение размерностей, доступны в достаточно малом количестве языков. Для их реализации требуется ведение специальных информационных структур, в которых хранятся: количество индексов, верхняя и нижняя граница каждого индекса. Разумеется, можно хранить и дополнительную информацию, такую как размер массива в байтах. Эти же структуры данных используются и для контроля выхода индексов за границы массива.
На контроле индексов остановлюсь подробнее. Эта возможность есть далеко не во всех языках и компиляторах. Иногда контроль можно включить или выключить, для всей программы или ее части. Контроль индексов может сильно замедлить Вашу программу. Действительно, для статических массивов эта операция требует дополнительно по два сравнения на каждый индекс. Для динамических массивов, кроме того, требуется обращение к массиву с границами индексов. Так что может иметь смысл использовать контроль индексов только на этапе отладки программы. Можно так же запретить контроль индексов для критичной по времени части программы, например для внутренних циклов.