

№1 История развития СУБД
Развитие СУБД началось в 60-е годы прошлого века, когда разрабатывался проект полета корабля Apollo на Луну. Была разработана система GUKM (Generalized Update Access Method), использующая иерархическую структуру. Затем была предложена система IDS (Integrated Data Store), основанная на сетевой структуре. В 1970 году Кодд предложил реляционную модель данных, ставшую основой реляционных БД. Первые коммерческие продукты появились в конце 60-х – начале 80-х годов, тогда же был разработан структурированный язык запросов SQL. В 80-х годах были созданы различные реляционные СУБД – DB2, Oracle и др. В настоящее время сущ. несколько десятков различных реляционных СУБД. Для ПК – это Access, FoxPro, Paradox, InterBase, FireBird, Oracle и др. В 1976 году Чен предложил модель "сущность-связь" (Entity Relationship model – ER модель), которая в наст. время стала самой распространенной технологией проектирования БД. Появились 2 новые сис-мы: объектно-ориентированная СУБД или ООСУБД и объектно-реляционная СУБД или ОРСУБД. Однако действительная структура этих моделей не совсем ясна. Эти СУБД относятся к СУБД 3-его поколения и еще до конца не разработаны.
Обзор современных СУБД
Они кратко характеризуются следующими принципами построения: 1)значительная часть совр. СУБД может работать на компьютерах различной архитектуры под управлением разных ОС; 2)подавляющее большинство совр. СУБД использует реляционную модель данных; 3) совр. СУБД для описания данных и манипуляции ими используют принятые стандарты в области языков; 4) многие сущ. СУБД явл-ся сетевыми СУБД, которые предназначены для поддержки многопользовательского режима работы с БД; 5) сущ-ие СУБД имеют развитые средства администрирования БД и средства защиты хранимой в них инф-ии.
В наст. время число СУБД превышает несколько десятков.
№2 Ограничения присущие традиционным файловым системам при работе с данными
Файловые системы – набор программ, кот. выполняют для пользователей некоторые операции, например создание отчетов. Каждая программа определяет свои собственные данные и управляет ими.
ФС были первой попыткой компьютеризировать известные всем ручные картотеки. Данные хранятся в отдельных файлах. ФС были разработаны в ответ на потребность в получении более эффективных способов доступа к данным. Однако, вместо организации централизованного хранилища всех данных предприятия, был использован децентрализованный подход, при котором сотрудники каждого отдела работают со своими собственными данными и хранят их в своем отделе.
Ограничения, присущие ФС:
разделение и изоляция данных - данные изолированы в отдельных файлах, и доступ к ним весьма затруднен.
дублирование данных – децентрализованная работа с данными в каждом отделе независимо от других отделов, что приводит к затрате дополнительных ресурсов и к нарушению целостности данных.
зависимость от данных – способ хранения записей в файлах жестко зафиксирован в коде программы приложения, изменить существующую структуру данных достаточно сложно.
несовместимость файлов – формат определяется кодом приложения.
фиксированные запросы – нельзя создавать произвольные запросы, так как их форматы фиксированы кодом приложения – надо увеличивать количество приложений и файлов для реализации новых запросов.
Существование фактов приводит к наличию связей между отдельными объектами предметной области.
Связи являются такой же частью данных предприятия как основные сущности. Поэтому связи должны быть представлены в базе данных наравне с основными сущностями предметной области.
№3 Основные понятия характеризующие БД и СУБД
Появление БД стало самым важным достижением в области ПО. БД лежат в основе информационных систем, и это изменило характер работы многих организаций. Осн. идеи современных ИС базируются на концепции баз данных. Под информацией понимаются любые сведения о каком-либо событии, процессе, объекте. К и. может относиться все, что может интересовать пользователя любого уровня.
Данные — это инф-ия, представленная в определенном виде, позволяющем автоматизировать ее сбор, хранение и дальнейшую обработку человеком или информационным средством. Для компьютерных технологий данные — это информация в дискретном виде, удобном для хранения и обработки на ЭВМ, а также для передачи по каналам связи.
БД –некоторый набор устойчивых (перманентных) данных, отражающий состояние объектов и их отношений в рассматриваемой предметной области и используемый прикладными системами какого-либо предприятия.
БД – совок-сть взаимосвязанных данных (и описаний этих данных), предназначенный для удовлетворения информационных потребностей орг-ии.
Администратор базы данных (АБД) — человек, который принимает участие в разработке БД, контролирует правильность ее функционирования.
Система управления базами данных (СУБД) – это программное обеспечение, которое управляет доступом к базе данных.
СУБД – совок-сть языковых и программных средств, с помощью кот. пользователи могут определять, создавать и поддерживать базу данных, а также осуществлять к ней контролируемый доступ.
Информационная система — это организационная совок-сть технических и обеспечивающих ср-в, технологических процессов и кадров, реализующих фу-ии сбора, обработки, хранения, поиска, выдачи и передачи информации.
№4 Характеристика уровней представления баз данных
Основная цель СУБД - предложить пользователю абстрактное представление данных, скрыв от него конкретные особенности хранения и управления ими. Т.к. БД является общим ресурсом, то каждому пользователю может потребоваться свое, отличное от других, представление об информации, хранимой в БД.
Архитектура большинства современных СУБД строится на базе так называемой архитектуры ANSI – SPARC (American National Standard Institute Standards Planning and Requirements Committee). Хотя модель ANSI/SPARC не стала стандартом, тем не менее, она представляет собой основу для понимания некоторых функциональных особенностей СУБД.
Наиболее важным моментом этой модели является определение трех уровней абстракции, то есть трех различных уровней описания элементов данных. В модели определены три уровня – внешний, концептуальный и внутренний.
Причины, по которым желательно выполнять такое разделение:
Каждый пользователь должен иметь возможность обращаться к одним и тем же данным, используя свое собственное представление о них.
Пользователи не должны иметь дело с подробностями физического хранения данных в базе.
АБД должен иметь возможность изменять структуру хранения данных в базе, не оказывая влияния на пользовательское представление.
№5 Внешний уровень представления БД
Внешний уровень – представление БД с точки зрения пользователей. Этот уровень описывает ту часть БД, которая относится к каждому пользователю. С точки зрения пользователя определение данных представляется в контексте предметной области.

Каждый пользователь имеет дело с представлением «реального мира», выраженным в наиболее удобной для него форме.
Осн. Понятия:
Сущность – объект «реального мира», Работник, Отдел, Договор.
Атрибуты – свойства или качества каждой сущности (например, Имя, Адрес, Зарплата для сущности Работник).
Связи – взаимоотношения между сущностями (например, Работник работает в Отделе).
Внешнее представление пользователя содержит только те сущности, атрибуты и связи «реального мира», которые интересны этому пользователю. Другие сущности, атрибуты и связи, которые ему не интересны, также могут быть представлены в базе данных, но они важны для другого пользователя. (Адрес – для отдела кадров, а бухгалтерия может им не пользоваться).
№6 Концептуальный уровень представления БД
Концептуальный уровень – обобщающее представление БД. Он описывает то, какие данные хранятся в БД, а также связи, существующие между ними. Этот уровень обобщает представления всех пользователей – фактически, это полное представление требований к данным со стороны организации, в которой работают пользователи. Это представление не зависит от способа хранения этих данных.
На концептуальном уровне представлены следующие компоненты:
все сущности, их атрибуты и связи;
накладываемые на данные ограничения;
семантическая информация о данных;
информация о безопасности и целостности данных.
Описание сущности должно содержать сведения о типах данных атрибутов (целочисленный, действительный, символьный) и их длине (количество значащих цифр или максимальное количество символов), не должно включать сведений об объеме занятого пространства в байтах.
№7 Внутренний уровень представления БД
Внутренний уровень – физическое представление БД в компьютере. Этот уровень описывает, как информация хранится в БД. Этот уровень содержит описание структур данных и организации отдельных файлов, используемых для хранения данных в запоминающих устройствах. На физическом уровне определяются методы взаимодействия СУБД с операционной системой компьютера.
№8 Схемы и подсхемы БД
Общее описание БД называется схемой базы данных. Существует три различных типа схем базы данных, которые соответствуют трем уровням абстракции.
Внешнее представление 1
SNo |
FName |
LName |
Age |
Salary |
Номер сотрудника |
Имя |
Фамилия |
Возраст |
Зарплата |
Внешнее представление 2
StNo |
Lname |
BNo |
Личный № сотрудника |
Фамилия |
Номер отдела |
Концептуальный уровень
StaffNo |
FName |
LName |
DOB Дата рождения |
Salary |
BranchNo |
Внутренний уровень
Struct STAFF
Staff No integer (идентификатор)
Branch No integer
FName char (15)
LName char (15)
DOB date
Salary double–precision
На самом верхнем уровне имеется несколько внешних схем или подсхем, которые соответствуют разным представлениям данных. На концептуальном уровне описание базы данных называют концептуальной схемой, а на самом нижнем уровне абстракции – внутренней схемой.
Важно различать описание базы данных и саму базу данных. Описанием базы данных является схема БД, которая создается при проектировании и меняется достаточно редко. Данные, содержащиеся в БД, могут меняться часто (например, при добавлении сведений о новом сотруднике).
Схема создается с помощью некоторого языка определения данных конкретной СУБД.
№9,10,11,12,13,14 Модели данных
Модель данных – интегрированный набор понятий для описания данных, связей между ними и ограничений, накладываемых на данные в некоторой орг-ии.
МД можно рассматривать как сочетание 3 компонентов:
структурной части – набора правил, по которым может быть построена база данных; управляющей части, определяющей типы допустимых операций с данными (операции обновления и извлечения данных, а также операции изменения структуры базы данных); набора ограничений поддержки целостности данных, гарантирующих корректность используемых данных.
Цель построения МД - понятное представление данных, которое можно будет легко применить при проектировании БД.
Для трехуровневой архитектуры существуют 3 связанные МД (объектные модели):
Внешняя МД (моделью предметной области) - отображает представления каждого типа пользователей организации. Внешние МД используются при работе с CASE-средствами (при разработке функциональной модели, модели потоков данных) для создания внешних объектов, процессов, потоков, накопителей и описания структур данных.
Концептуальная МД, - отображает логическое (или обобщенное) представление о данных, не зависимое от типа выбранной СУБД. Конц. МД создается с помощью CASE-средства (ER – модель), содержит сущности, связи, атрибуты.
Внутренняя МД, которая отображает концептуальную схему для конкретной СУБД. Разрабатывается с помощью CASE-средства (лог. модель, для конкретной СУБД – реляционная модель СУБД). Содержит домены, типы атрибутов.
Кроме объектных моделей существуют МД на основе записей. В зависимости от способа записи данных БД состоит из нескольких (множества) записей фиксированного формата, которые могут иметь разные типы. Каждый тип записи определяет фиксированное количество полей, каждое из которых имеет фиксированную длину. Существует три основных типа записей, определяющие три типа моделей:
реляционная модель данных (relational data model);
сетевая модель данных (network data model);
иерархическая модель данных (hierarchical data model).
Сущность «Работник»
StaffNo |
FName |
LName |
DOB |
Salary |
BranchNo |
2152 |
Иван |
Егоров |
20.02.1935 |
3500 |
02 |
2876 |
Петр |
Сивохин |
2.12.1981 |
2500 |
11 |
Сущность «Отдел»
BranchNo |
Name |
№ комнаты |
02 |
Отдел сбыта |
21 |
11 |
Плановый отдел |
18 |
Рис.4: Описание данных в реляционной модели
В реляционной МД единственное требование состоит в том, чтобы БД с точки зрения пользователя выглядела как набор таблиц. Это требование относится только к внешнему и концептуальному уровням архитектуры ANSI/SPARC.
Рис.5. Сетевая модель данных
В сетевой модели данные представлены в виде коллекций записей, а связи – в виде наборов (см. рис.5). Сетевую модель можно представить как граф с записями в виде узлов (вершин) графа, и наборов данных в виде его ребер.
Иерархическая модель данных является подтипом сетевой модели. В ней данные представлены как коллекции записей, а связи – как наборы (см. рис.6). Однако узел может иметь только одного родителя.
№15 Функции СУБД
СУБД должна реализовывать: 1) Хранение, извлечение и обновление данных, 2) предоставлять пользователям возможность сохранять, извлекать и обновлять данные в базе данных. 3) Каталог, доступный конечным пользователям. 4) должна иметь доступный конечным пользователям каталог, в котором хранится описание элементов данных, а также сами данные. (системный каталог – каталог метаданны: C:\DATA\IB\ sqledu01) 5) Поддержка транзакций. 6) должна иметь механизм, который гарантирует выполнение либо всех операций обновления данной транзакции, либо ни одной из них.
Если во время выполнения транзакции произойдет сбой, например из-за выхода из строя компьютера, БД попадает в противоречивое состояние, поскольку некоторые изменения уже будут внесены, а остальные – еще нет. Поэтому все частичные изменения должны быть отменены для возвращения БД в прежнее, непротиворечивое состояние. 7) Сервисы управления параллельностью. СУБД должна иметь механизм, кот. гарантирует корректное обновление БД при параллельном выполнении операций обновления многими пользователями. 8)Сервисы восстановления - на случай какого-либо ее повреждения или разрушения. 9) СУБД должна иметь механизм, гарантирующий возможность доступа к базе данных только санкционированных пользователей. 10) Поддержка обмена данными по сети. Удаленные пользователи должны иметь возможность доступа к централизованной БД по сети. Такой режим наз-ся распределенной обработкой. 11) Служба поддержки целостности данных. Целостность БД означает корректность и непротиворечивость хранимых данных. Может рассматриваться как еще один тип защиты базы данных. Целостность выражается в виде ограничений или правил сохранения непротиворечивости данных (бизнес – правил), которые не должны нарушаться. 12) Дополнительные сервисы.
Службы поддержки независимости от данных. СУБД должна обладать инструментами поддержки независимости программ от фактической структуры БД.
Вспомогательные службы:
Утилиты импортирования и экспортирования (плоские файлы).
Средства мониторинга, предназначенные для отслеживания характеристик функционирования и использования БД. Программы статистического анализа, позволяющие оценить производительность или степень использования БД. Инструменты реорганизации индексов. Индекс- механизм доступа, ускоряющий выборку данных из таблицы БД – подобен указателю в конце книги.
№16 Компоненты СУБД
СУБД – вид ПО, используемый для предоставления пользователям различных сервисов. Компонентную структуру СУБД практически невозможно обобщить, так как она очень сильно различается в разных системах.

Рис. 7. Структура СУБД
СУБД состоит из нескольких программных модулей, каждый из которых предназначен для выполнения специфических операций. Контроллер БД взаимодействует с запущенными пользователями прикладными программами и запросами.
Контроллер файлов манипулирует предназначенными для хранения файлами и отвечает за распределение доступного дискового пространства. Он создает и поддерживает список структур и индексов, определенных во внутренней схеме. Он передает запросы соответствующим методам доступа, которые считывают данные в системные буферы, или записывает их оттуда на диск. Препроцессор языка DML преобразует имеющиеся в прикладных программах DML – операторы в вызовы стандартных функций. Для генерации соответствующего кода препроцессор языка DML должен взаимодействовать с процессором запросов. Компилятор языка DDL преобразует DDL-команды в набор действий по созданию таблиц, содержащих метаданные. Затем эти таблицы сохраняются в системном каталоге. Контроллер словаря управляет доступом к системному каталогу и обеспечивает работу с ним. Системный каталог доступен большинству компонентов СУБД.
№17 Понятие целостности данных
Ограничения целостности данных - ограничения, которые вводятся с целью предотвратить помещение в базу противоречивых данных. Типы ограничений целостности данных: 1)обязательные данные; 2)ограничения для атрибутов; 3) целостность сущностей; 4) ссылочная целостность; 5) требования данного предприятия.
Обязательные данные – некоторые атрибуты всегда должны содержать одно из допустимых значений. Эти атрибуты не могут иметь пустого значения.
Ограничения для атрибутов – каждый атрибут должен иметь набор допустимых значений. Набор доп. значений атрибута носит название домен. Например, атрибут «Пол» имеет домен, состоящий из двух допустимых значений «М» и «Ж».
Целостность сущностей – ПК любой сущности не может содержать пустого значения. Сущность «отдел» должна содержать уникальное значение атрибута первичного ключа – «No отдела». ПК – это атрибут, который выбран для уникальной идентификации записей БД (в отношении).
Ссылочная целостность – внешний ключ связывает каждую строку зависимого отношения с той строкой первичного отношения, которая содержит это же значение соответствующего первичного ключа. Понятие ссылочной целостности означает, что если внешний ключ содержит некоторое значение, то оно обязательно должно присутствовать в первичном ключе одной из строк родительского отношения. Каждый работник работает в одном из отделов предприятия. Требования данного предприятия – ограничения предприятия называются бизнес-правилами. Один работник не может участвовать в выполнении >3 проектов.
№18 Архитектура многопользовательских СУБД
Существует 3 типовых архитектурных решения при реализации многопользовательских СУБД: 1) обычная телеобработка; 2)файловый сервер; 3) технология клиент/сервер.
Телеобработка (рис.8) предполагает наличие одного компьютера с единственным процессором, который соединен с несколькими терминалами.
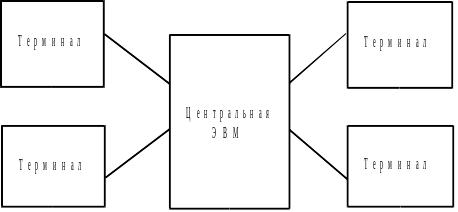
Рис. 8. Обычная телеобработка
Вся обработка данных выполняется в рамках единственного компьютера. Присоединенные к нему пользовательские терминалы являются простыми «не интеллектуальными» устройствами, не способными функционировать самостоятельно. Центральный комп выполняет действия прикладных программ и СУБД, а также значительную работу по обслуживанию терминалов (например, форматирование данных, выводимых на экраны терминалов, управление обменом данными со всеми терминалами). В результате на центральный процессор ложится чрезвычайно большая нагрузка, с которой могут справляться большие мейнфреймы.
№19 Технология клиент/сервер
Д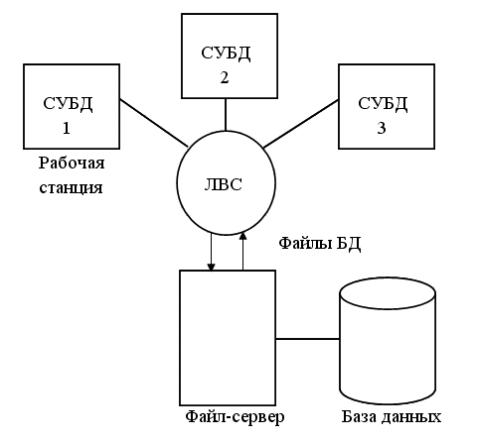 ецентрализация
и замена мейнфреймов ПК привела к
появлению 2 типов архитектуры СУБД –
файлового сервера и техн-ии клиент/сервер.
ФС (рис.9) используется в ЛВС и служит
для распределенной обработки данных.
ФС содержит файлы для работы приложений
и самой СУБД. СУБД на каждой РС посылает
запросы ФС по всем необходимым ей данным,
кот. хранятся на диске файл – сервера.
СУБД рабочей станции должна запросить
у ФС все файлы, соотв-щие таблицам БД,
содерж-им необходимые данные. А затем
СУБД извлечет из этих файлов нужные ей
записи из соотв-щих таблиц БД. Недостатки:
1) большой объем сетевого трафика; 2)на
каждой РС должна работать полная копия
СУБД; 3) управление параллельностью,
восстановлением и целостностью
усложняется, поскольку доступ к одним
и тем же файлам могут осущ-ть сразу
несколько экземпляров СУБД.
ецентрализация
и замена мейнфреймов ПК привела к
появлению 2 типов архитектуры СУБД –
файлового сервера и техн-ии клиент/сервер.
ФС (рис.9) используется в ЛВС и служит
для распределенной обработки данных.
ФС содержит файлы для работы приложений
и самой СУБД. СУБД на каждой РС посылает
запросы ФС по всем необходимым ей данным,
кот. хранятся на диске файл – сервера.
СУБД рабочей станции должна запросить
у ФС все файлы, соотв-щие таблицам БД,
содерж-им необходимые данные. А затем
СУБД извлечет из этих файлов нужные ей
записи из соотв-щих таблиц БД. Недостатки:
1) большой объем сетевого трафика; 2)на
каждой РС должна работать полная копия
СУБД; 3) управление параллельностью,
восстановлением и целостностью
усложняется, поскольку доступ к одним
и тем же файлам могут осущ-ть сразу
несколько экземпляров СУБД.
Т ехнология
клиент/сервер
(рис.10) была разработана с целью устранения
недостатков. Клиент/сервер - способ
взаимод. программных компонентов, при
котором они образуют единую систему.
Существует некий клиентский процесс,
требующий определенных ресурсов, а
также серверный процесс, который эти
ресурсы предоставляет. При этом
необязательно, чтобы оба процесса
находились на одном и том же компе.
Сервер размещается на одном узле лок.
сети, а клиенты – на других
ехнология
клиент/сервер
(рис.10) была разработана с целью устранения
недостатков. Клиент/сервер - способ
взаимод. программных компонентов, при
котором они образуют единую систему.
Существует некий клиентский процесс,
требующий определенных ресурсов, а
также серверный процесс, который эти
ресурсы предоставляет. При этом
необязательно, чтобы оба процесса
находились на одном и том же компе.
Сервер размещается на одном узле лок.
сети, а клиенты – на других
Пользовательское приложение БД представляет собой клиентский проц., вып-щийся на РС. Клиент принимает от пользователя запрос, проверяет его и генерирует запрос к БД на языке SQL. Затем он передает этот запрос серверу и ожидает поступления ответа. Сервер принимает и обрабатывает запросы к БД, а затем передает полученные рез-ты обратно клиенту. Такая обработка включает проверку полномочий клиента, обеспечение требований целостности, поддержку системного каталога, а также выполнение запроса и при необходимости обновление данных. Также поддерж-ся упр-ие параллельностью и восстановлением.
Клиент, получив ответ от сервера, отображает полученные данные пользователю. Преимущества:
более эффективный доступ к существующим БД;
повышается общая производительность системы.
стоимость аппаратного обеспечения снижается;
сокращаются коммуникационные расходы (сокращается объем пересылаемых по сети данных);
повышается уровень непротиворечивости данных (все ограничения определяются и проверяются только в одном месте – на сервере, каждому приложению не надо выполнять собственную проверку).
Разработано дальнейшее расширение двухуровневой архитектуры клиент/сервер, при котором функциональная часть прежнего толстого (интеллектуального) клиента разделяется на две части. В трехуровневой архитектуре клиент/сервер тонкий (неинтеллектуальный) клиент на РС управляет только пользовательским интерфейсом, тогда как средний уровень обработки данных управляет всей остальной логикой приложения. Третьим уровнем явл-ся сервер БД. Такая трехуровневая архитектура оказалась более подходящей для некоторых сред – например, для сетей Internet и Intranet, где в качестве клиента может использоваться обычный Web-браузер.
№20 Язык определения данных
Язык определения данных – DDL, - описательный язык, кот. позволяет АБД или пользователю описать и поименовать сущности, необходимые для работы некоторого приложения, а также связи, имеющиеся между различными сущностями.
Схема БД состоит из набора определений, выраженных на специальных языке определения данных – DDL. Язык DDL исп-ся как для определения новой схемы, так и для модификации существующей. Этот язык нельзя использовать для управления данными. Рез-том компиляции DDL-операторов является набор таблиц, хранимых в особых файлах, в которых хранятся данные, описывающие объекты БД – метаданные. Такой особый файл называется системным каталогом (иногда каталогом данных). Метаданные включают определения записей элементов данных, а также другие объекты, необходимые пользователям или для работы СУБД. Перед доступом к реальным данным, СУБД обычно обращается к системному каталогу.
№21 Язык управления данными
Язык управления данными – DML, это язык, содержащий набор операторов для поддержки основных операций манипулирования данными, содержащимися в базе.
К операциям управления данными относятся:
1) вставка в БД новых сведений; 2) модификация сведений, хранимых в БД; 3) извлечение сведений, содержащихся в БД; 4) удаление сведений из БД.
Одна из осн. ф-ий СУБД - поддержкаязыка манипулирования данными (ЯМД), с помощью кот. пользователь может создавать выражения для выполнения перечисленных выше операций с данными. Языки DML отличаются базовыми конструкциями извлечения данных.
Типы языков DML: процедурный и непроцедурный. Основное отличие между ними - процедурные языки указывают то, как можно получить результат оператора языка DML, непроцед. описывают то, какой результат будет получен. Как правило, в процедурных языках записи БД рассматриваются по отдельности, а непроцед. языки оперируют наборами данных
№22 Процед. и непроцедурные языки управления данными
Процедурные языки DML – языки, кот. позволяют сообщить сис-ме о том, какие данные необходимы, и точно указать, как их можно извлечь. С помощью процедурного языка программист указывает на то, какие данные ему необходимы, и как их можно получить. Программист должен определить все операции доступа к данным (осуществляемые посредством вызова соответствующих процедур), которые должны быть выполнены для получения требуемой информации. Обычно такой процедурный язык позволяет извлечь запись, обработать ее, и, в зависимости от полученных результатов, извлечь другую запись, которая должна быть подвергнута аналогичной обработке, и т.д. Подобный процесс извлечения данных продолжается до тех пор, пока не будут извлечены все запрашиваемые данные. Языки DML сетевых и иерархических СУБД обычно являются процедурными.
Непроцедурные языки DML –языки, кот. позволяют указать лишь то, какие данные требуются, но не то, как их следует извлекать. Н. я. позволяют определить весь набор требуемых данных с помощью одного оператора извлечения или обновления. С помощью этих языков пользователь указывает, какие данные ему нужны без определения способа их получения. СУБД транслирует выражение на языке DML в процедуру (или набор процедур), которая обеспечивает манипулирование затребованным набором записей.
Этот подход освобождает пользователя от необходимости знать детали внутренней реализации структур данных и особенности алгоритмов, используемых для извлечения и возможного преобразования данных. В рез-те работа пользователя получает определенную степень независимости от данных. Н. я. называют декларативными языками.
Реляционные СУБД обычно включают поддержку н. я. DML – чаще всего это язык структурированных запросов SQL или язык запросов по образцу QBE (Query-by-Example).
Н. я. обычно проще понимать и использовать, чем пр. я. DML, т.к. пользователь выполняет < работы, а СУБД – большая.
№23 Терминология реляционных БД
Реляционная модель впервые была предложена Э.Ф.Коддом в 1970 году. РМ является основой современной технологии БД.
Реляционные системы базируются на теории, которая называется реляционной моделью данных. Основным понятием этой теории является понятие отношения.
Отношение – это математ-ое понятие, физич.представлением которого явл-ся определенного вида таблица (рис.11).

Рис.11. Отношения "Отдел" и "Служащий"
В таблице содержатся некоторые факты, относящиеся к объектам Отдел и Служащий. Отношение – это множество фактов, касающееся объектов, которые можно обсуждать. Таблица – физич. представление отношения, т.е. множества фактов, относящихся к обсуждаемым объектам. Реляционная модель состоит из трех основных частей – структуры, целостности данных и манипулирования ими. Каждая часть имеет свою терминологию.
Отношение – плоская таблица, состоящая из столбцов и строк.
Атрибут – поименованный столбец отношения.
Домен – набор допустимых значений для одного или нескольких атрибутов.
Кортеж – строка отношения.
Степень – количество атрибутов, содержащихся в отношении.
Кардинальность – количество кортежей, которое содержит отношение.
Первичный ключ – атрибут или множество атрибутов, которые выбраны для уникальной идентификации кортежей отношения.
Реляционная БД – набор отношений (нормализованных).
Каждый кортеж отношения представляет собой определенное высказывание об объекте.
№24 Реляционные языки и реляционная алгебра
Для управления отношениями в реляционных СУБД можно использовать процедурные и непроцедурные языки. Коддом были предложены формальные языки – реляционная алгебра и реляционное исчисление. Реляц. алгебра - процедурный язык, который может быть использован, чтобы сообщить СУБД как следует построить требуемое отношение на базе одного или нескольких существующих в базе данных отношений.
Реляц. исчисление - непроцедурный язык, кот. можно использовать для определения того, каким будет некоторое отношение, созданное на основе одного или нескольких других отношений базы данных. РА и РИ эквивалентны друг другу. Для каждого выражения алгебры существует эквивалентное выражение в реляционном исчислении (и наоборот).
Кодд определил 8 операторов РА, использующих отношения в качестве операндов и возвращающих отношения в качестве результата. Они составляют две группы по четыре оператора:
Специальные реляционные операции
Выборка. Результат - отношение, содержащее все кортежи из заданного отношения, удовлетв-щие определенным условиям.
Проекция. Результат - отношение, содержащее кортежи заданного отношения, состоящие из определенных атрибутов (остальные атрибуты исключены).
Соединение. Результат - отношение, содерж. все возможные кортежи, кот. представляют собой комбинацию атрибутов двух кортежей, принадлежащих двум заданным отнош-ям, при условии, что в этих двух комбинируемых кортежах присутствуют одинаковые значения в одном или нескольких общих для исходных отношений атрибутах (общие значения в результирующем кортеже появл-ся один раз, а не дважды)
Деление. Результат - отношение, содержащее все кортежи из первого унарного отн-ия, кот. содержатся также в др. отн-ии.
Традиционные операции над множествами
Объединение Результат – отн-ие, содержащее все кортежи, которые принадлежат либо одному из двух заданных отношений, либо им обоим.
Произведение Результат – отн-ие, содержащее все возможные кортежи, которые явл-ся сочетанием двух кортежей, принадлежащих соответственно двум заданным отношениям.
Пересечение Результат – отн-ие, содержащее все кортежи, которые принадлежат одновременно двум заданным отношениям.
Разность Рез-т – отн-ие, содерж. все кортежи, кот. принадл. первому из 2х заданных отн-ний и не принадл. второму.
Можно записывать вложенные реляционные выражения, в кот. операнды сами представлены реляционными выражениями.
Основная цель алгебры – обеспечить запись реляц. выражений. Выражения можно преобразовывать в соотв-вии с правилами преобразования. РА в явном виде представляет набор операций, которые можно использовать, чтобы сообщить сис-ме, как в БД из опред-ых отн-ий построить нек. отн-ие.
№ 25 Нормализация отношений
При проектировании БД основная цель - выбор подходящей логической стр-ры для заданного массива данных, который требуется поместить в БД. Решается, какие необходимы отношения и какой выбор атрибутов они должны включать. Такой процесс наз-ся концептуальным проектированием БД (относится к внешнему уровню представления данных). Для определения подходящего набора отн-ий используется метод, называемый нормализацией. Н-ия – метод создания набора отн-ия с заданными св-вами на основе требований к данным.
Н. часто выполняется в виде последовательности тестов, выполняемых над некоторым отн-ем и необходимых для проверки его соответствия требованиям заданной нормальной формы. Осн. цель н. - минимизация избыточности данных и сокращений объема памяти, необходимого для физического хранения БД. При наличии избыточности возникает ряд проблем, осложняющих процесс функционирования СУБД.
Пример. Таблица 6 Отношение Служащий (Staff)

Т![]() аблица
7 Отношение Отделение. Альтернативное
представление данных с помощью одного
отношения (табл.8): Таблица 8 Отношение
Служащий – Отделение (Staff - Branch)
аблица
7 Отношение Отделение. Альтернативное
представление данных с помощью одного
отношения (табл.8): Таблица 8 Отношение
Служащий – Отделение (Staff - Branch)

Избыточные данные: сведения об отделении повторяются в кортежах, относящихся к каждому сотруднику. Проблемы, возникающие при наличии избыточности в отношениях, называются аномалиями обновления и подразделяются на аномалии вставки, удаления и модификации. Нормализация служит для получения правильно спроектированных отн-ий.
№ 26 Свойства отношений
Точное определение термина отношение: Пусть задано множество доменов Тi (I = 1, 2,..n), все из которых необязательно должны быть различными. Тогда r будет отношением, определенным на этих доменах, если оно состоит из двух частей – заголовка и тела, где а) заголовок – это множество из n атрибутов вида Ai : Ti; здесь Ai – имена атрибутов, а Ti – соответствующие им имена типов. б) тело – это множество из m кортежей t; здесь t, в свою очередь, является множеством компонентов вида Ai : Vi, в которых Vi – значение типа Ti, то есть значение атрибута Ai в кортеже t (I = 1, 2,..n).
В терминах таблицы, заголовок – это строка, состоящая из названий столбцов и соответствующих имен типов, а тело – это множество строк данных. Св-ва отн-ий: 1) в них нет одинаковых кортежей; 2) кортежи отношения не имеют упорядоченности в направлении сверху вниз; 3) атрибуты в кортежах не упорядочены слева направо; 4)каждый кортеж содержит ровно одно значение для каждого атрибута.
Св-во 1: следует из того факта, что тело отн-ия – это мат. множество (кортежей), а в математике множества по определению не содержат одинаковых эл-ов. Таблица, в общем случае, может содержать одинаковые строки (при отсутствии правил, запрещающих это). Св-во 2: следует из того, что тело отн-ия – это мат. множество, а простые множества в математике не упорядочены. В таблице строки упорядочены сверху вниз. Св-во 3: следует из того факта, что заголовок отн-ия также определен, как множество (атрибутов). Атрибут всегда определяется по имени, а не по расположению. В таблице столбцы могут быть упорядочены. Св-о 4: следует из определения кортежа: кортеж является множеством из n компонентов. Отн-е, удовлетворяющее этому св-у, наз-ся нормализованным или представленным в 1НФ.
Дополнительные св-ва: 1)Отн-ие имеет имя, кот. отличается от имен всех других отн-ий. 2) Каждый атрибут имеет уникальное имя. 3)Значения атрибута берутся из одного и того же домена. 4) Все кортежи одного отношения должны иметь одно и то же количество атрибутов.
№27 Аномалии обновлений при наличии избыт. в отн-ях
Избыточные данные: сведения об отделении повторяются в кортежах, относящихся к каждому сотруднику. Проблемы, возникающие при наличии избыточности в отношениях, называются аномалиями обновления и подразделяются на аномалии вставки, удаления и модификации.
Аномалии вставки. Существуют два основных типа аномалий вставки. При вставке сведений о новых сотрудниках необходимо указывать и сведения об отделении, в которых эти сотрудники работают, которые должны соответствовать сведениям об этом же отделении в других строках отношения «Служащий-отделение». Первые отношения не могут пострадать от такого потенциального несоответствия, так как требуется вводить только номер отделения. Сведения об отделении, кроме того, заносятся однократно.
Для вставки сведений о новом отделении, которое еще не имеет собственных сотрудников, потребуется присвоить значение NULL всем атрибутам, включая номер сотрудника StaffNo. Однако, этот атрибут является ключом и попытка ввода NULL нарушит целостность сущностей. Первые отношения позволяют избегать возникновения этой проблемы.
Аномалии удаления При удалении из отношения строки с информации о последнем сотрудники некоторого отделения, сведения об этом отделении будут полностью удалены из БД.
Первые два отношения позволяют избежать возникновения этой проблемы.
Аномалии обновления При попытке изменения значения одного из атрибутов для некоторого отделения в отношении необходимо обновить соответствующие значения в строках для всех сотрудников этого отделения. Если такой модификации будут подвергнуты не все требуемые строки, то база данных будет содержать противоречивые сведения.
2 8. Функциональные зависимости и 1нф.
Ф. завис-сть описывает связь между атрибутами и явл-ся одним из основных понятий нормализации.
Если в отношении R, содержащем атрибуты А и В, атрибут В функционально зависит от атрибута А (что обозначается А → В), то каждое значение атрибута А связано только с одним значением атрибута В. (При этом каждый из атрибутов А и В может состоять из одного или нескольких атрибутов) (рис.22).

Рис. 22. Функциональные зависимости
Детерминантом ФЗ наз-ся атрибут или группа атрибутов, расположенная на диаграмме ФЗ слева от символа строки.
В отношении Staff
– может быть несколько сотрудников с
одинаковыми должностями. Связь между
атрибутами StaffNo
и Position
относится к типу 1:1, поскольку для каждого
номера сотрудника имеется только одна
должность. А связь между атрибутами
Position
и StaffNo
имеет тип 1:N,
так как существует несколько номеров
сотрудников, занимающих одну и ту же
должность.
отношении Staff
– может быть несколько сотрудников с
одинаковыми должностями. Связь между
атрибутами StaffNo
и Position
относится к типу 1:1, поскольку для каждого
номера сотрудника имеется только одна
должность. А связь между атрибутами
Position
и StaffNo
имеет тип 1:N,
так как существует несколько номеров
сотрудников, занимающих одну и ту же
должность.
StaffNo – детерминант ФЗ StaffNo → Position. Для выявления ключей отношения Staff - Branch необходимо найти атрибут (или группу атрибутов), кот. уникальным образом идентифицирует каждую строку этого отн-ия. Это атрибут StaffNo. В отношении Branch потенциальными ключами являются TelNo и Branch-No. В отношении Staff – атрибут StaffNo. Нормализация - это формальный метод анализа отн-ия на основе их ПК (или потенциальных ключей) и существующих ФЗ. Он включает ряд правил, которые могут исп-ся для проверки отдельных отн-ий т.о., чтобы вся БД могла быть нормализована до желаемой степени нормализации. При работе с реляционной моделью данных важно понимать, что только удовлетворение требований 1НФ (каждый кортеж содержит ровно одно значение для каждого атрибута) обязательно для создания отношений приемлемого качества. Все остальные формы могут использоваться по желанию проектировщиков. Однако, для того чтобы избежать аномалий обновления нормализацию рекомендуется выполнять как минимум до 3НФ.
1НФ - отношение, в котором на пересечении каждой строки и каждого столбца содержится только одно значение (отсутствуют повторяющиеся группы данных).
Повторяющейся группой называется группа, состоящая из атрибута таблицы, в кот. возможно наличие неск-их значений для единств. значения ключ. атрибута
Существует два подхода исключения повторяющихся групп – выравнивание и декомпозиция (табл.10,11).
Таблица 10 Выравнивание Таблица 11 Декомпозиция
![]()

При использовании выравнивания дальнейшая нормализация все равно приводит к необходимости декомпозиции исходного отношения.
29. Полная функциональная зависимость и 2нф
2НФ основана на понятии полной функц. зависимости.
В некотором отношении атрибут В называется полностью функц-но зависимым от атрибута А, если атрибут В функц-но зависит от полного значения атрибута А и не зависит ни от какого подмножества полного значения атрибута А.
![]()
Эта зависимость не является полной, т. к. существует зависимость StaffNo → BranchNo
Отношение, которое находится в 1НФ и каждый атрибут которого, не входящий в состав ПК, характеризуется полной функ. завис-стью от этого ПК. Если в отношении между атрибутами сущ-ет частичная зависимость, то функционально – зависимые атрибуты удаляются из него и помещаются в новое отношение вместе с копией их детерминанта.
Таблица 12 Отношение FIRST Таблица 13 Отн-ие SECOND


Таблица 14 Отношение SP
В отношении FIRST (табл. 12) первичный ключ SNo, PNo. Однако, только атрибут QTY (количество) полностью зависит от этого составного ключа. Атрибуты STATUS, CITY частично зависят от указанного ключа, т.к. сущ-ют завис-сти SNo Status и SNo City
Поэтому отношение First декомпозировано на два отношения Second и SP (табл. 13,14).
В отношении Second помещены атрибуты STATUS и CITY, имеющие частичную зависимость от ключа SNo, PNo вместе с их детерминантом SNo.
Если в отн-ии нет составного ПК и оно находится в 1НФ, то оно автоматически также находится и в 2НФ.