

2)Основные алгоритмические конструкции
Под
алгоритмом понимают постоянное и точное
предписание (указание) исполнителю
совершить определенную последовательность
действий, направленных на достижение
указанной цели или решение поставленной
задачи.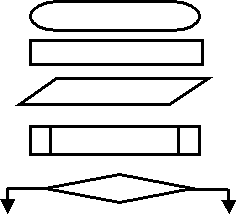
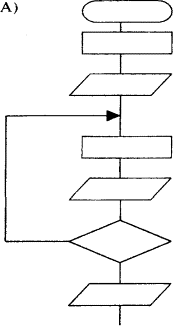
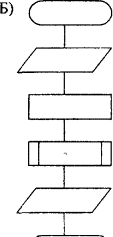
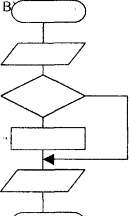
Это к большому рисуеку : А) повторение (цикл)
Начало – конец Б) следование
Процесс В) ветвление
Ввод-вывод
Типовой
процесс
Решение (условие)
Алгоритми́ческий язык — формальный язык, используемый для записи, реализации и изучения алгоритмов. Всякий язык программирования является алгоритмическим языком, но не всякий алгоритмический язык пригоден для использования в качестве языка программирования [1]. В узком смысле слова алгоритмическим языком также называют семейство языков программирования Алгол
3)Программи́рование — в обычном понимании, это процесс создания компьютерных программ. Программированием также называют настройку электронных устройств и программно-аппаратных комплексов (например, программирование цифровых АТС, программирование бытовых приборов конечным пользователем, запись информации в ПЗУ). Разработку логической схемы для ПЛИС тоже называют программированием. В общем понимании, программирование - это процесс описания функционирования устройства, который может быть выражен либо в структуре самого устройства, либо в виде набора инструкций. Программирование сочетает в себе элементы науки (логика, математика, информатика, кибернетика), инженерной дисциплины, и искусства (авторской творческой деятельности).
В узком смысле (так называемое кодирование) под программированием понимается написание инструкций на конкретном языке программирования, часто по уже имеющемуся алгоритму (плану, методу решения задачи). Соответственно, люди, которые этим занимаются, называются программистами (на жаргоне - кодерами), а те, кто разрабатывает алгоритмы - алгоритмистами, специалистами предметной области, математиками.
В более широком смысле под программированием понимают весь спектр активностей, связанных с созданием и поддержанием в рабочем состоянии программ (программного обеспечения ЭВМ). Более точный и современный термин - программная инженерия, или инженерия ПО. Сюда входят анализ и постановка задачи, проектирование программы, построение алгоритмов, разработка структур данных, написание текстов программ, отладка и тестирование программ (испытания программ), документирование, настройка (конфигурирование), доработка и сопровождение.
Языки программирования
Большая часть работы программистов связана с написанием исходного кода, тестированием и отладкой программ на одном из языков программирования. Исходные тексты и исполняемые файлы программ являются объектами авторского права и являются интеллектуальной собственностью их авторов и правообладателей.
Различные языки программирования поддерживают различные стили программирования (т. н. парадигмы программирования). Отчасти искусство программирования состоит в том, чтобы выбрать один из языков, наиболее полно подходящий для решения имеющейся задачи. Разные языки требуют от программиста различного уровня внимания к деталям при реализации алгоритма, результатом чего часто бывает компромисс между простотой и производительностью (или между временем программиста и временем пользователя).
Единственный язык, напрямую выполняемый ЭВМ — это машинный язык (также называемый машинным кодом). Изначально все программы писались в машинном коде, но сейчас этого практически уже не делается. Вместо этого программисты пишут текст исходный код на том или ином языке программирования, затем (используя компилятор, интерпретатор или ассемблер) транслируют его, в один или несколько этапов в машинный код, готовый к исполнению на целевом процессоре, или в промежуточное представление, которое может быть исполнено специальной программой - виртуальной машиной, или интерпретатором. Если требуется полный низкоуровневый контроль над системой на уровне машинных команд и отдельных ячеек памяти, программы пишут на языке ассемблера, мнемонические инструкции которого преобразуются один к одному в соответствующие инструкции машинного языка целевого процессора ЭВМ.
В некоторых языках вместо машинного кода генерируется интерпретируемый двоичный код «виртуальной машины», также называемый байт-кодом (byte-code). Такой подход применяется в Forth, некоторых реализациях Lisp, Java, Perl, Python, .NET Framework.
4) Система программирования – это комплекс средств, предназначенный для создания и эксплуатации программ на конкретном языке программирования на ЭВМ определенного типа.
Основная идея структурного программирования состоит в том, что структура программы должна отражать структуру решаемой задачи, чтобы алгоритм программы был ясно виден из исходного текста. Следовательно, надо разбить программу на последовательность модулей, каждый из которых выполняет одно или несколько действий. Требование к модулю – чтобы его выполнение начиналось с первой команды и заканчивалось последней. Модульность – это основная характеристика структурного программирования. А для этого надо иметь средства для создания программы не только с помощью трех простых операторов, но и с помощью средств более точно отражающих конкретную структуру алгоритма.
4. Стратегии решения задач (Этапы решения задач на ПК)
В процессе подготовки задачи (программной системы (ПС)) на ПК можно выделить такие этапы:
1. Постановка задачи
На этом этапе формулируется цель решения задачи, анализируются требования и подробно описывается содержание задачи, выявляются условия, при которых решается задача, а также определяются входные параметры, которые называются исходными данными. Например, для задачи 1, рассмотренной в предыдущей теме, целью является вычисление периметра треугольника, а исходными данными являются координаты его вершин, при этом условием является то, что вершины треугольника лежат на плоскости.
2. Формальное построение модели задачи
На этом этапе составляется формальная модель решения задачи, например, модель базы данных, адекватная оригиналу, модель объектов и потоков информации. Для задачи 1 мы определили, что периметр треугольника вычислим, если будем знать длины его сторон, а длины сторон определяются по координатам вершин треугольника.
3. Построение математической модели решения задачи
Этот этап иначе называют формализацией задачи, на котором описательная модель записывается с помощью какого-либо формального языка, например, математического. Для задачи 1, рассмотренной в предыдущей теме, для вычисления периметра используем формулу Р=AB+BC+AC, а для вычисления длины одной стороны такую - .
4. Построение алгоритма
Процесс обработки данных разбивается на отдельные самостоятельные блоки и определяется последовательность выполнения этих блоков. Для задачи 1 мы вынесли в самостоятельный блок (в подпрограмму-функцию) вычисление расстояния между двумя точками, вызов которой будет осуществляться из основной программы.
5. Составление программы
На этом этапе алгоритм записывается на каком - либо конкретном языке программирования.
6. Отладка программы
Когда программа составлена, говорят, что готова альфа-версия. Начинается отладка программы. Отладка программы - это процесс поиска и устранения синтаксических и логических ошибок в программе. Метод выявления ошибок называется тестированием.
Если программная система сложная, и ее разрабатывает компания-исполнитель по заданию заказчика, то программа, так называемая ее альфа-версия, сначала тестируется людьми компании-исполнителя (тестологами).
По истечении определенного времени тестирования, когда количество ошибок резко уменьшается, начинается интенсивное использование системы у заказчика с целью выявления и устранения максимального количества ошибок перед выходом системы на рынок. Этот процесс называется бета-тестированием.
В том случае, если ошибки не найдены, говорят, что при тестировании системы получен положительный результат.
Если заказчик удовлетворен качеством программного продукта, то наступает период его внедрения в эксплуатацию. После того, как заказчик подписывает акт приемки, проект разработки программной системы считается завершенным. Как правило, сотрудничество исполнителя по обслуживанию системы с заказчиком продолжается, которое называется сопровождением системы.
Жизненным циклом разработанного программного продукта является весь период от анализа требований до внедрения и сопровождения, т. е. весь период разработки и эксплуатации программного средства.
Главным качеством любого программного продукта является его надежность.
Постановка задачи, формальное построение модели задачи и построение математической модели решения задачи, построение алгоритма – это этапы системного анализа задачи (если задача сложная, то рассматривают такие этапы конструирования ИС -разработка архитектуры ИС, разработка структур программ и разработка схемы информационных обменов ИС), а далее идет этап кодирования алгоритма.
5)Предметом изучения данного раздела являются электронные таблицы (ЭТ). Появление электронных таблиц исторически совпадает с началом распространения персональных компьютеров. Первая программа для работы с электронными таблицами — табличный процессор, была создана в 1979 году, предназначалась для компьютеров типа Apple II и называлась VisiCalc. В 1982 году появляется знаменитый табличный процессор Lotus 1-2-3, предназначенный для IBM PC. Lotus объединял в себе вычислительные возможности электронных таблиц, деловую графику и функции реляционной СУБД. Популярность табличных процессоров росла очень быстро. Появлялись новые программные продукты этого класса: Multiplan, QuattroPro, SuperCalc и другие. Одним из самых популярных табличных процессоров сегодня является MS Excel, входящий в состав пакета MicrosoftOffice.
Что же такое электронная таблица? Это средство информационных технологий, позволяющее решать целый комплекс задач:
1) прежде всего, выполнение вычислений. Издавна многие расчеты выполняются в табличной форме,
особенно в области делопроизводства: многочисленные, расчетные ведомости,, табуляграммы, сметы расходов и т. п. Кроме того, решение численными методами целого ряда математических задач удобно выполнять в табличной форме. Электронные таблицы представляют собой удобный инструмент для автоматизации таких вычислений. Решения многих вычислительных задач на ЭВМ, которые раньше можно было осуществить только путем программирования, стало возможно реализовать на электронных таблицах;
2) математическое моделирование. Использование математических формул в ЭТ позволяет представить
взаимосвязь между различными параметрами некоторой реальной системы. Основное свойство ЭТ —
мгновенный пересчет формул при изменении значений входящих в них операндов. Благодаря этому
свойству, таблица представляет собой удобный инструмент для организации численного эксперимента: подбор параметров, прогноз поведения моделируемой системы, анализ зависимостей, планирование. Дополнительные удобства для моделирования дает возможность графического представления данных;
3) использование электронной таблицы в качестве базы данных. Конечно, по сравнению с СУБД электронные таблицы имеют меньшие возможности в этой области. Однако некоторые операции манипулирования данными, свойственные реляционным СУБД, в них реализованы. Это поиск информации по заданным условиям и сортировка информации.
При первоначальном знакомстве с электронными таблицами удобно оттолкнуться от известных ученикам представлений о реляционных базах данных. Объяснение нужно строить на конкретном примере. В учебнике использован пример таблицы учета продажи молочных продуктов в магазине. Рассматривая такую таблицу как базу данных, ее поля можно разделить на два типа: независимые, т. е. содержащие некоторую исходную информацию и вычисляемые по определенным формулам. К независимым полям относятся цена единицы товара, количество поставленного товара, количество проданного товара. К вычисляемым полям относятся остаток, равный разности между поставленным и проданным товаром, выручка от продажи, равная произведению количества проданного товара на цену. Основным свойством электронной таблицы является возможность мгновенного пересчета вычисляемых полей при изменении значений операндов, входящих в формулы.
Возможность размещения в ячейках таблицы формул — это первая базовая идея электронных таблиц. Вторая базовая идея — это принцип относительной адресации. Но об этом немного позже.
На уроках ученикам предстоит освоить конкретный табличный процессор. Как и в предыдущих темах курса, рассматривающих информационные технологии, рекомендуется придерживаться методической схемы виртуального исполнителя, элементами которой является изучение среды, режимов работы, системы команд, данных.
6) Электронные таблицы (или табличные процессоры) — это прикладные программы, предназначенные для проведения табличных расчетов.
В электронных таблицах вся обрабатываемая информация располагается в ячейках прямоугольной таблицы. Отличие электронной таблицы от простой заключается в том, что в ней есть «поля» (столбцы таблицы), значения которых вычисляются через значения других «полей», где располагаются исходные данные. Происходит это автоматически при изменении исходных данных. Поля таблицы, в которых располагаются исходные данные, принято называть независимыми полями. Поля, где записываются результаты вычислений, называют зависимыми или вычисляемыми полями. Каждая ячейка электронной таблицы имеет свой адрес, который образуется от имени столбца и номера строки, где она расположена. Строки имеют числовую нумерацию, а столбцы обозначаются буквами латинского алфавита.
Электронные таблицы имеют большие размеры. Например, наиболее часто применяемая в IBM-совместимых компьютерах электронная таблица Excel имеет 256 столбцов и 16 384 строк. Ясно, что таблица такого размера не может вся поместиться на экране. Поэтому экран — это только окно, через которое можно увидеть только часть таблицы. Но это окно перемещается, и с его помощью можно заглянуть в любое место таблицы.
Рассмотрим, как могла бы выглядеть таблица для подсчета расходов школьников, собравшихся поехать на экскурсию в другой город.
Всего на экскурсию едут 6 школьников, в музей собирается пойти 4 из них, а в цирк — 5. Билеты на поезд стоят 60 р., но можно поехать и на автобусе, заплатив по 48 р. Тогда появляется возможность либо увеличить затраты на обед, либо купить билеты в цирк подороже, но на лучшие места. Существует и масса других вариантов распределения бюджета, отведенного на экскурсию, и все они легко могут быть просчитаны с помощью электронной таблицы.
Электронная таблица имеет несколько режимов работы: формирование таблицы (ввод данных в ячейки), редактирование (изменение значений данных), вычисление по формулам, сохранение информации в памяти, построение графиков и диаграмм, статистическая обработка данных, упорядочение по признаку.
Формулы, по которым вычисляются значения зависимых полей, включают в себя числа, адреса ячеек таблицы, знаки операций. Например, формула, по которой вычисляется значение зависимого поля в третьей строке, имеет вид: ВЗ*СЗ — число в ячейке ВЗ умножить на число в ячейке СЗ, результат поместить в ячейку D3.
При работе с электронными таблицами пользователь может использовать и так называемые встроенные формулы (в Excel их имеется около 400), т. е. заранее подготовленные для определенных расчетов и внесенные в память компьютера
Большинство табличных процессоров позволяют осуществлять упорядочение (сортировку) таблицы по какому-либо признаку, например по убыванию. При этом в нашей таблице на первом месте (во второй строке) останется расход на покупку билетов (максимальное значение — 360 р.), затем (в третьей строке) окажется расход на посещение цирка (100 р.), затем расходы на обед (60 р.) и наконец в последней строке — расходы на посещение музея (минимальное значение — 8р.).
В электронных таблицах предусмотрен также графический режим работы, который дает возможность графического представления (в виде графиков, диаграмм) числовой информации, содержащейся в таблице.
Электронные таблицы просты в обращении, быстро осваиваются непрофессиональными пользователями компьютера и во много раз упрощают и ускоряют работу бухгалтеров, экономистов, ученых, конструкторов и людей целого ряда других профессий, чья деятельность связана с расчетами
7-10)Excel - это не просто одна отдельная программа. Неправильно, когда говорят, что Excel - это программа! Это комплекс программ! Он входит в состав пакета задач MicrosoftOffice и предназначен для решения любой математической, экономической, физической и т.п. задачи, при условии, что исходная информация и результаты могут быть представлены в виде таблицы.
На практике встречающиеся нам задачи имеет конечное число исходных элементов, например:
- это может быть одно данное. Это тоже таблица, состоящая из одного элемента;
- либо несколько данных, которые можно расположить в одной строке. Это опять же таблица, которую называют линейной;
- либо прямоугольная таблица или матрица данных, как принято ее называть.
Отсюда следует, что программный комплекс Excel имеет универсальное применение для решения огромного множества задач практически из любой области знаний. Единственное требование - это, чтобы исходная информация и результаты могли быть представлены в виде таблицы.
Цель моих уроков - дать возможность учащимся школы, в частности, я имею в виду прежде всего учеников 10-11 классов, где систематически изучается предмет ИНФОРМАТИКА, обстоятельно познакомиться с программным комплексом Excel. Как на уроках, так и во внеурочное время, в домашних условиях, используя Интернет и мои электронные уроки. Конечно, уроки могут быть использованы всеми учителями и учениками независимо от их места проживания, от их имущесьтвенного ценза и прочих различий, которые увидят в моих уроках рациональное зерно и, заинтересовавшись, начнут вместе со всеми постигать тонкости программного комплекса EXCEL и особенности успешной работы с ним.
11-12)Справочно-правовые системы (информационно-правовые системы) — особый класс компьютерных баз данных, содержащих тексты указов, постановлений и решений различных государственных органов. Кроме нормативных документов, они также содержат консультации специалистов по праву, бухгалтерскому и налоговому учету, судебные решения, типовые формы деловых документов и др.
В настоящее время в нашей стране вокруг правовой информации сложилась целая индустрия. Одним из направлений деятельности в этой сфере стало создание компьютерных справочных правовых систем (СПС). Необходимо отметить, что тексты нормативных документов, включенные в информационные базы СПС, не являются объектом авторских прав и поэтому не могут быть предметом продажи. Приобретая правовую систему, потребитель платит за инструмент хранения, поиска и анализа необходимой ему информации, а также за сервис и услуги по обработке и передаче новых документов.
Начало эпохи автоматизации правовой информации можно отнести к выходу в 1975 г. Постановления ЦК КПСС и Совмина СССР № 558. Там указывалось на необходимость введения государственной регистрации нормативных актов и предусматривалось создание Научно-информационного центра при ВНИИ советского законодательства при Министерстве юстиции СССР. В то время доступ к такой информации носил строго ограниченный характер. Однако с приходом в эту сферу коммерческих структур в конце 80-х - начале 90-х годов правовая информация стала доступна более широкому кругу заинтересованных лиц.
13-18)Ба́зада́нных — представленная в объективной форме совокупность самостоятельных материалов (статей, расчетов, нормативных актов, судебных решений и иных подобных материалов), систематизированных таким образом, чтобы эти материалы могли быть найдены и обработаны с помощью электронной вычислительной машины (ЭВМ) (Гражданский кодекс РФ, ст. 1260).
Другие определения из авторитетных монографий и стандартов:
База данных — организованная в соответствии с определёнными правилами и поддерживаемая в памяти компьютера совокупность данных, характеризующая актуальное состояние некоторой предметной области и используемая для удовлетворения информационных потребностей пользователей[1].
База данных — совокупность данных, хранимых в соответствии со схемой данных, манипулирование которыми выполняют в соответствии с правилами средств моделирования
Иерархические базы данных могут быть представлены как дерево, состоящее из объектов различных уровней. Верхний уровень занимает один объект, второй — объекты второго уровня и т. д.
Между объектами существуют связи, каждый объект может включать в себя несколько объектов более низкого уровня. Такие объекты находятся в отношении предка (объект более близкий к корню) к потомку (объект более низкого уровня), при этом возможна ситуация, когда объект-предок не имеет потомков или имеет их несколько, тогда как у объекта-потомка обязательно только один предок. Объекты, имеющие общего предка, называются близнецами.
Реляционная база данных — база данных, основанная на реляционной модели данных. Слово «реляционный» происходит от англ. relation (отношение[1]). Для работы с реляционными БД применяют реляционные СУБД.
Использование реляционных баз данных было предложено доктором Коддом из компании IBM в 1970 году.
Целью нормализации реляционной базы данных является устранение недостатков структуры базы данных, приводящих к вредной избыточности в данных, которая в свою очередь потенциально приводит к различным аномалиям и нарушениям целостности данных.
Теоретики реляционных баз данных в процессе развития теории выявили и описали типичные примеры избыточности и способы их устранения.
К основным понятиям сетевой модели базы данных относятся: уровень, элемент (узел), связь.
Узел — это совокупность атрибутов данных, описывающих некоторый объект. На схеме иерархического дерева узлы представляются вершинами графа. В сетевой структуре каждый элемент может быть связан с любым другим элементом.
Сетевые базы данных подобны иерархическим, за исключением того, что в них имеются указатели в обоих направлениях, которые соединяют родственную информацию.
Несмотря на то, что эта модель решает некоторые проблемы, связанные с иерархической моделью, выполнение простых запросов остается достаточно сложным процессом.
Также, поскольку логика процедуры выборки данных зависит от физической организации этих данных, то эта модель не является полностью независимой от приложения. Другими словами, если необходимо изменить структуру данных, то нужно изменить и приложение.
Объектно-ориентированная база данных (ООБД) — база данных, в которой данные оформлены в виде моделей объектов, включающих прикладные программы, которые управляются внешними событиями. Результатом совмещения возможностей (особенностей) баз данных и возможностей объектно-ориентированных языков программирования являются Объектно-ориентированные системы управления базами данных (ООСУБД). ООСУБД позволяет работать с объектами баз данных также, как с объектами в программировании в ООЯП. ООСУБД расширяет языки программирования, прозрачно вводя долговременные данные, управление параллелизмом, восстановление данных, ассоциированные запросы и другие возможности.
Некоторые объектно-ориентированные базы данных разработаны для плотного взаимодействия с такими объектно-ориентированными языками программирования как Python, Java, C#, VisualBasic .NET, C++, Objective-C и Smalltalk; другие имеют свои собственные языки программирования. ООСУБД используют точно такую же модель, что и объектно-ориентированные языки программирования.
В качестве основных этапов обобщенной технологии работы с СУБД, которая схематично представлена на рис. 15.27, можно выделить следующие:
• создание структуры таблиц базы данных;
• ввод и редактирование данных в таблицах;
• обработка данных, содержащихся в таблицах;
• вывод информации из базы данных.
Рассмотрим выделенные этапы более подробно.
Создание структуры таблиц базы данных
При формировании новой таблицы базы данных работа с СУБД начинается с создания структуры таблицы. Этот процесс включает определение перечня полей, из которых состоит каждая запись таблицы, а также типов и размеров полей.
Практически все используемые СУБД хранят данные следующих типов: текстовый (символьный), числовой, календарный, логический, примечание. Некоторые СУБД формируют поля специального типа, содержащие уникальные номера записей и используемые для определения ключа.
СУБД, предназначенные для работы в Windows, могут формировать поля типа объекта OLE, которые используются для хранения рисунков, графиков, таблиц.
Если обрабатываемая база данных включает несколько взаимосвязанных таблиц, то необходимо определение ключевого поля в каждой таблице, а также полей, с помощью которых будет организована связь между таблицами.
Создание структуры таблицы не связано с заполнением таблиц данными, поэтому эти две операции можно разнести во времени.
Рис. 15.27. Схема обобщенной технологии работы в СУБД
Ввод и редактирование данных
Заполнение таблиц данными возможно как непосредственным вводом данных, так и в результатевыполнения программ и запросов.
Практически все СУБД позволяют вводить и корректировать данные в таблицах двумя способами:
• с помощью предоставляемой по умолчанию стандартной формы в виде таблицы;
• с помощью экранных форм, специально созданных для этого пользователем.
СУБД, работающие с Windows, позволяют вводить в созданные экранные формы рисунки, узоры, кнопки. Возможно построение форм, наиболее удобных для работы пользователя, включающих записи различных связанных таблиц базы данных. Пример экрана с формой ввода представлен на рис. 15.28.
Обработка данных, содержащихся в таблицах
Обрабатывать информацию, содержащуюся в таблицах базы данных, можно путем использования запросов или в процессе выполнения специально разработанной программы.
Конечный пользователь получает при работе с СУБД такое удобное средство обработки информации, как запросы. Запрос представляет собой инструкцию на отбор записей.
Большинство СУБД разрешают использовать запросы следующих типов:
• запрос-выборка, предназначенный для отбора данных, хранящихся в таблицах, и неизменяющий эти данные;
• запрос-изменение, предназначенный для изменения или перемещения данных; к этому типу запросов относятся: запрос на добавление записей, запрос на удаление записей, запрос на создание таблицы, запрос на обновление;
• запрос с параметром, позволяющий определить одно или несколько условий отбора во время выполнения запроса.
Самым распространенным типом запроса является запрос на выборку.
Результатом выполнения запроса является таблица с временным набором данных (динамический набор). Записи динамического набора могут включать поля из одной или нескольких таблиц базы данных. На основе запроса можно построить отчет или форму.
при разработке БД можно выделить следующие этапы работы.
I этап. Постановка задачи.
На этом этапе формируется задание по созданию БД. В нем подробно описывается состав базы, назначение и цели ее создания, а также перечисляется, какие виды работ предполагается осуществлять в этой базе данных (отбор, дополнение, изменение данных, печать или вывод отчета и т. д).
II этап. Анализ объекта.
На этом этапе рассматривается, из каких объектов может состоять БД, каковы свойства этих объектов. После разбиения БД на отдельные объекты необходимо рассмотреть свойства каждого из этих объектов, или, другими словами, установить, какими параметрами описывается каждый объект. Все эти сведения можно располагать в виде отдельных записей и таблиц. Далее необходимо рассмотреть тип данных каждой отдельной единицы записи. Сведения о типах данных также следует занести в составляемую таблицу.
III этап. Синтез модели.
На этом этапе по проведенному выше анализу необходимо выбрать определенную модель БД. Далее рассматриваются достоинства и недостатки каждой модели и сопоставляются с требованиями и задачами создаваемой БД. После такого анализа выбирают ту модель, которая сможет максимально обеспечить реализацию поставленной задачи. После выбора модели необходимо нарисовать ее схему с указанием связей между таблицами или узлами.
IV этап. Выбор способов представления информации и программного инструментария.
После создания модели необходимо, в зависимости от выбранного программного продукта, определить форму представления информации.
В большинстве СУБД данные можно хранить в двух видах:
с использованием форм;
без использования форм.
Форма – это созданный пользователем графический интерфейс для ввода данных в базу.
V этап. Синтез компьютерной модели объекта.
В процессе создания компьютерной модели можно выделить некоторые стадии, типичные для любой СУБД.
Стадия 1. Запуск СУБД, создание нового файла базы данных или открытие созданной ранее базы.
Стадия 2. Создание исходной таблицы или таблиц.
Создавая исходную таблицу, необходимо указать имя и тип каждого поля. Имена полей не должны повторяться внутри одной таблицы. В процессе работы с БД можно дополнять таблицу новыми полями. Созданную таблицу необходимо сохранить, дав ей имя, уникальное в пределах создаваемой базы.
При проектировании таблиц, рекомендуется руководствоваться следующими основными принципами:
1. Информация в таблице не должна дублироваться. Не должно быть повторений и между таблицами. Когда определенная информация хранится только в одной таблице, то и изменять ее придется только в одном месте. Это делает работу более эффективной, а также исключает возможность несовпадения информации в разных таблицах. Например, в одной таблице должны содержаться адреса и телефоны клиентов.
2. Каждая таблица должна содержать информацию только на одну тему. Сведения на каждую тему обрабатываются намного легче, если они содержатся в независимых друг от друга таблицах. Например, адреса и заказы клиентов лучше хранить в разных таблицах, с тем, чтобы при удалении заказа информация о клиенте осталась в базе данных.
3. Каждая таблица должна содержать необходимые поля. Каждое поле в таблице должно содержать отдельные сведения по теме таблицы. Например, в таблице с данными о клиенте могут содержаться поля с названием компании, адресом, городом, страной и номером телефона. При разработке полей для каждой таблицы необходимо помнить, что каждое поле должно быть связано с темой таблицы. Не рекомендуется включать в таблицу данные, которые являются результатом выражения. В таблице должна присутствовать вся необходимая информация. Информацию следует разбивать на наименьшие логические единицы (Например, поля "Имя" и "Фамилия", а не общее поле "Имя").
4. База данных должна иметь первичный ключ. Это необходимо для того, чтобы СУБД могла связать данные из разных таблиц, например, данные о клиенте и его заказы.
Стадия 3. Создание экранных форм.
Первоначально необходимо указать таблицу, на базе которой будет создаваться форма. Ее можно создавать при помощи мастера форм, указав, какой вид она должна иметь, или самостоятельно. При создании формы можно указывать не все поля, которые содержит таблица, а только некоторые из них. Имя формы может совпадать с именем таблицы, на базе которой она создана. На основе одной таблицы можно создать несколько форм, которые могут отличаться видом или количеством используемых из данной таблицы полей. После создания форму необходимо сохранить. Созданную форму можно редактировать, изменяя местоположение, размеры и формат полей.
Стадия 4. Заполнение БД.
Процесс заполнения БД может проводиться в двух видах: в виде таблицы и в виде формы. Числовые и текстовые поля можно заполнять в виде таблицы, а поля типа МЕМО и OLE – в виде формы.
VI этап. Работа с созданной базой данных.
Работа с БД включает в себя следующие действия:
поиск необходимых сведений;
сортировка данных;
отбор данных;
вывод на печать;
изменение и дополнение данных.
В 19-21)середине 60-х годов корпорация IBM совместно с фирмой NAA (NorthAmericanAviation, в настоящее время - RockwellInternational) разработали первую СУБД - иерархическую систему IMS (InformationManagementSystem). Несмотря на то, что IMS является самой первой из всех коммерческих СУБД, она до сих пор остается основной иерархической СУБД, используемой на большинстве крупных мейнфреймов.
Другим заметным достижением середины 60-х годов было появление системы IDS (IntegratedDataStore) фирмы GeneralElectric. Развитие этой системы привело к созданию нового типа систем управления базами данных - сетевых СУБД, что оказало существенное влияние на информационные системы того поколения. Сетевая СУБД создавалась для представления более сложных взаимосвязей между данными, чем те, которые можно было моделировать с помощью иерархических структур, и послужили основой для разработки первых стандартов БД. Для создания таких стандартов в 1965 году на конференции CODASYL (ConferenceonDataSystemsLanguages) была сформирована рабочая группа ListProcessingTaskForce, переименованная в 1967 году в группу DataBaseTaskGroup (DBTG). В компетенцию группы DBTG входило определение спецификаций среды, которая допускала бы разработку баз данных и управление данными. Полный вариант отчета этой группы был опубликован в в 1971 году и содержал следующие утверждения:
Сетевая схема - это логическая организация всей базы данных в целом (с точки зрения АДБ), которая включает определение имени базы данных, типа каждой записи и компонентов записей каждого типа.
Подсхема - это часть базы данных, видимая конкретными пользователями или приложениями.
Язык управления данными - инструмент для определения характеристик и структуры данных, а также для управления ими.
Группа DBTG также предложила стандартизировать три различных языка:
Язык определения данных DDL для схемы, который позволит АБД описать ее.
Язык определения данных (также DDL) для подсхемы, который позволит определять в приложениях те части базы данных, доступ к которым будет необходим.
Язык манипулирования данными DML, предназначенный для управления данными
Система управления базами данных (СУБД) ≈ это комплекс языковых и про╜граммныхсредств, предназначенныйдлясоздания, веденияисовместногоиспользо╜ванияБДмногимипользователями.
В основу функционирования современных СУБД положена трехуровневая архитектура представления информации: внешний, концептуальный и внутренний уровни. Каждому из трех уровней соответствует определенный тип схемы базы данных, под которой понимk 838i87ci 2;ется общее описание базы данных с помощью некоторого языка определения данных (DLL) для конкретной СУБД. Поскольку это язык относительно низкого уровня, то для представления схемы базы данных в виде, понятном различным категориям пользователей, требуется ее описание на более высоком уровне, называемое моделью данных. Модель данных √ это интегрированный набор понятий для описания данных, связей между ними и ограничений, накладываемых на данные.
Внешний уровень определяется локальными представлениями пользователей-абонентов информационной системы о предметной области и о своих информационных потребностях. На основе анализа этих представлений определяется несколько информационно-логических (инфологических) схем (или подсхем), которые соответствуют различным представлениям конечных пользователей о предметной области. Инфологическая модель представляет собой формализованное описание объектов предметной области и отношений между этими объектами.
Концептуальный (промежуточный) уровень представления информации √ концептуальная схема базы данных (иначе логическая структура данных). Концептуальная схема (модель) является обобщенным описанием логической структуры всей базы данных и═описываетвсеэлементыданныхисвязимеждунимисуказаниемнеобходимыхограниченийподдержкицелостностиданных. Длякаждойбазыданныхимеетсятолькооднаконцептуальная схема.
Внутренний уровень √ это физическое представление базы данных в компьютере. Ему соответствует внутренняя схема, которая является полным описанием внутренней модели данных. Она содержит определения хранимых записей, методы представления, описания полей данных, сведения об индексах и выбранных схемах хеширования. Для каждой базы данных существует только одна внутренняя схема.
Основным назначением трехуровневой архитектуры является обеспечение независимости от данных. Логическая независимость от данных означает полную защищенность внешних схем от изменений, вносимых в концептуальную схему. Физическая независимость от данных означает защищенность концептуальной схемы от изменений, вносимых во внутреннюю схему.
Функции СУБД
1. Хранение, извлечение и обновление данных. СУБД должна предоставлять пользователям возможность сохранять, извлекать и обновлять данные в базе данных. Это самая фундаментальная функция СУБД. Причем, способ реализации этой функции должен быть скрыт от конечного пользователя.
2. Каталог, доступный конечным пользователям. СУБД должна иметь доступный конечным пользователям каталог, в котором хранится описание элементов данных. Ключевой особенностью архитектуры ANSI/SPARC является наличие интегрированного системного каталога с данными о схемах, пользователях, приложениях и т. д. Предполагается, что каталог доступен как пользователям, так и функциям СУБД. Системный каталог или словарь данных является хранилищем информации, описывающей данные в базе данных (метаданные). В зависимости от типа используемой СУБД количество информации и способ ее примk 838i87ci 7;нения могут варьироваться. Обычно в системном каталоге хранятся следующие сведения:
- имена, типы и размеры элементов данных;
- имk 838i87ci 7;на связей;
- накладываемые на данные ограничения поддержки целостности;
- имk 838i87ci 7;на санкционированных пользователей;
- внешняя, концептуальная и внутренняя схемы и отображения между ними;
- статистические данные (частота транзакций, счетчик обращения к объектам базы данных).
Системный каталог позволяет достичь определенных преимуществ:
- информация о данных может быть централизованно собрана и сохранена, что позволит контролировать доступ к этим данным, как и к любому другому ресурсу;
- можно определить смысл данных, что поможет другим пользователям понять их назначение;
- упрощается сообщение, так как сохраняются точные определения смысла данных. В системном каталоге также могут быть указаны один или несколько пользователей, которые являются владельцами данных или обладают правом доступа к ним;
- благодаря централизованному хранению избыточность и противоречивость описания отдельных элементов данных могут быть легко обнаружены;
- внесенные в базу данных изменения могут быть запротоколированы;
- последствия любых изменений могут быть определены еще до их внесения, поскольку в системном каталоге зафиксированы все существующие элементы данных, установленные между ними связи, а также все их пользователи;
- меры обеспечения безопасности могут быть дополнительно усилены;
- появляются новые возможности организации поддержки целостности данных;
- может выполняться аудит сохраняемой информации.
3. Поддержка транзакций. СУБД должна иметь механизм, который гарантирует выполнение либо всех операций обновления данной транзакции, либо ни одной из них. Транзакция представляет собой набор действий, выполняемых отдельным пользователем или прикладной программой с целью доступа или изменения содержимого базы данных (напримk 838i87ci 7;р, удаление сведений о сотруднике из база данных и передача ответственности за всю курируемую им работу другому сотруднику). Если во время выполнения транзакции произойдет сбой, напримk 838i87ci 7;р, из-за выхода из строя компьютера, база данных попадет в противоречивое состояние, поскольку некоторые изменения уже будут внесены, а остальные √ нет. В этом случае все частичные изменения должны быть отменены для возвращения базы данных в исходное непротиворечивое состояние.
4. Сервисы управления параллельностью. СУБД должны иметь механизм, который гарантирует корректное обновление базы данных при параллельном выполнении операций обновления многими пользователями. Одна из основных целей создания и использования СУБД заключается в том, чтобы множество пользователей могло осуществлять доступ к совместно обрабатываемым данным. Параллельный доступ сравнительно просто организовать, если все пользователи выполняют только чтение данных. Конфликтные ситуации с нежелательными последствиями легко могут возникнуть, когда два и более пользователей пытаются обновить данные. СУБД должна гарантировать, что при одновременном доступе к базе данных многих пользователей таких конфликтов не произойдет.
5. Сервисы восстановления. СУБД должна предоставлять средства восстановления базы данных на случай какого-либо ее повреждения или разрушения. Сбой может произойти в результате выхода из строя системы или запоминающего устройства, возможны ошибки аппаратного и программного обеспечения, которые могут привести к останову СУБД. К тому же пользователь может потребовать отмены операции. Во всех подобных случаях СУБД должна предоставить механизм восстановления базы данных и возврата к ее непротиворечивому состоянию. Сервисы восстановления тесно связаны с управлением транзакциями.
6. Сервисы контроля доступа к данным. СУБД должна иметь механизм, гарантирующий возможность только санкционированного доступа к базе данных. Иногда требуется скрыть некоторые хранимые в базе данных сведения от других пользователей. Напримk 838i87ci 7;р, менеджерам отделений компании можно было бы предоставить всю информацию, связанную с зарплатой сотрудников, но желательно скрыть ее от других пользователей. Кроме того, базу данных следует защитить от любого несанкционированного доступа. Термин безопасность относится к защите базе данных от преднамеренного или случайного несанкционированного доступа.
7. Поддержка обмена данными. СУБД должна обладать способностью к интеграции с коммуникационным программным обеспечением. Большинство пользователей осуществляют доступ к базе данных с помощью терминалов. Иногда эти терминалы подсоединены непосредственно к компьютеру с СУБД. В других случаях терминалы могут находиться на значительном удалении и обмениваться данными с компьютером, на котором располагается СУБД, через сеть. В любом случае СУБД получает запросы в виде сообщений обмена данными (communicationsmessages) и аналогичным образом отвечает на них. Такая передача данных управляется менеджером обмена данными. Хотя этот менеджер не является частью собственно СУБД, тем не менее, чтобы быть коммерчески жизнеспособной, любая СУБД должна обладать способностью интеграции с разнообразными существующими менеджерами обмена данными. Даже СУБД для персональных компьютеров должны поддерживать работу в локальной сети, чтобы вместо нескольких баз данных для каждого пользователя можно было установить одну централизованную базу данных и использовать ее как общий ресурс для всех пользователей. При этом предполагается, что не база данных должна быть распределена в сети, а удаленные пользователи должны иметь возможность доступа к централизованной базе данных. Такая топология называется распределенной обработкой.
8. Службы поддержки целостности данных. СУБД должна обладать инструментами контроля за тем, чтобы данные и их изменения соответствовали заданным правилам. Целостность базы данных означает корректность и непротиворечивость хранимых данных. Она может рассматриваться как еще один тип защиты базы данных, но в более широком смысле целостность связана с качеством самих данных. Целостность обычно выражается в виде ограничений или правил сохранения непротиворечивости данных (напримk 838i87ci 7;р, сотрудник не имеет права работать больше, чем на полторы ставки в данной организации).
9. Службы поддержки независимости от данных. СУБД должна обладать инструментами поддержки независимости программ от фактической структуры базы данных. Обычно она достигается за счет реализации механизма поддержки представлений или подсхем. Физическая независимость от данных достигается достаточно просто, что нельзя сказать о логической независимости от данных. Как правило, система легко адаптируется к добавлению нового объекта, атрибута или связи, но не к их удалению. В некоторых системах вообще запрещается вносить любые изменения в уже существующие компоненты логической схемы.
10. Вспомогательные службы. СУБД должна предоставлять некоторый набор различных вспомогательных служб. Вспомогательные утилиты обычно предназначены для оказания помощи АБД в эффективном администрировании базы данных. Приведем примk 838i87ci 7;ры таких утилит:
- утилиты импортирования, предназначенные для загрузки данных из плоских файлов или других СУБД, а также утилиты экспортирования, которые служат для выгрузки базы данных в плоские файлы или другие СУБД;
- средства мониторинга, предназначенные для отслеживания характеристик функционирования и использования базы данных;
- программы статистического анализа, позволяющие оценить производительность или степень использования базы данных;
- инструменты реорганизации индексов, предназначенные для перестройки индексов и обработки случаев их переполнения;
- инструменты сборки мусора и перераспределения памяти для физического устранения удаленных записей с запоминающих устройств, объединения освобожденного пространства и перераспределения памяти в случае необходимости.