

6.1. Стандартный дп-распознаватель
Стандартная
система распознавания речи на основе
ДП-процедуры и ЛПК имеет параметры.
Входной речевой сигнал
![]() ,
записанный по стандартному телефонному
каналу, ограничивается с помощью
широкополосного фильтра в полосе 100 –
3200 Гц и оцифровывается с частотой
квантования 6,67 кГц. Первый шаг –
предобработка с помощью подчеркивания
высоких частот. Далее речевой сигнал
сегментируется в 45 мсек блоки (по 300
отсчетов), разделенных на 15 мсек части
(по 100 отсчетов). Восьмиполюсный ЛПК
анализ (автокорреляционный метод)
работает на длине слова (после выделения
конца слова детектором конца слова).
Каждый полученный ЛПК-вектор далее
используется или непосредственно, или
обрабатывается процедурой ВК с помощью
кодовой книги размерности M*.
Полученная последовательность
ЛПК-векторов, называемая тестовым
образом, сравнивается с каждым образом
эталонного множества с помощью ДП
выравнивающего алгоритма, который
последовательно вычисляет расстояние,
связанное с текущим эталонным образом.
Расстояния, вычисленные для всех
эталонных образов, обрабатываются
решающим правилом, которое классифицирует
входное слово, или, возможно, упорядочивает
по расстоянию
лучших кандидатов.
,
записанный по стандартному телефонному
каналу, ограничивается с помощью
широкополосного фильтра в полосе 100 –
3200 Гц и оцифровывается с частотой
квантования 6,67 кГц. Первый шаг –
предобработка с помощью подчеркивания
высоких частот. Далее речевой сигнал
сегментируется в 45 мсек блоки (по 300
отсчетов), разделенных на 15 мсек части
(по 100 отсчетов). Восьмиполюсный ЛПК
анализ (автокорреляционный метод)
работает на длине слова (после выделения
конца слова детектором конца слова).
Каждый полученный ЛПК-вектор далее
используется или непосредственно, или
обрабатывается процедурой ВК с помощью
кодовой книги размерности M*.
Полученная последовательность
ЛПК-векторов, называемая тестовым
образом, сравнивается с каждым образом
эталонного множества с помощью ДП
выравнивающего алгоритма, который
последовательно вычисляет расстояние,
связанное с текущим эталонным образом.
Расстояния, вычисленные для всех
эталонных образов, обрабатываются
решающим правилом, которое классифицирует
входное слово, или, возможно, упорядочивает
по расстоянию
лучших кандидатов.
Эталонные образы слов распознавателя создаются с помощью обучающей процедуры. Для распознавателя, настраивающегося на диктора, обычно создается один эталон на слово словаря. Для независимого от диктора распознавателя множество из Q эталонных образов создается для каждого слова словаря с помощью процедуры кластеризации. Обычно около 12 произнесений на слово, выбранных на основе гомогенной популяции дикторов носителей языка, достаточно.
Если используется ВК кодовая книга на M* входов, как описано в разделе 5.1, можно хранить таблицу из M*x M* расстояний между всеми парами входов кодовой книги. В этом случае вычисление расстояний между любой парой входов кодовой книги становится простым нахождением пересечения. Таким образом, если мы обрабатываем с помощью ВК ЛПК-вектор тестовой последовательности и все эталонные образы, тогда вычисление расстояний с помощью ДП-процедуры становится тривиальным.
Новая методика уменьшения дисперсии ВК была предложена Сакое. В этом случае тестовый вектор не квантуется. Вместо этого вычисляется таблица расстояний между всеми тестовыми векторами и всеми входами кодовой книги, и далее используется для вычисления расстояний ДП-процедуры. В этом случае уменьшается дисперсия, потребный объем памяти (по сравнению с традиционным ВК), и главное, не требуется вычислений для определения локальных расстояний (это тоже табличный метод).
6.2. Стандартный смм-распознаватель
Блок-схема стандартного СММ-распознавателя включает предобработку, сегментацию, ЛПК-анализ и векторное квантование, аналогичное описанному выше для ДП-распознавателя. Тестовая последовательность уменьшается до наблюдаемой последовательности {O}, состоящей из кодов векторов кодовой книги, которые наилучшим образом соответствуют ЛПК-векторам последовательности. Алгоритм Витерби определяет, для каждого индивидуального слова СММ, вероятность того, что наблюдаемая последовательность была сгенерирована данным словом СММ. Решающее правило или выбирает слово, чья модель имеет наибольшую вероятность, как распознанное слово, или выдает перечень кандидатов слов, упорядоченный по их вычисленной вероятности.
Вероятность
для каждой модели слова вычисляется по
следующему алгоритму. Каждое слово СММ
является моделью из N
состояний, которая характеризуется
матрицей переходных вероятностей A,
и порождающей матрицей B.
На рис. 14. представлена модель слова при
N=5
с M*
дискретными выходными символами на
каждое состояние. Здесь мы предполагаем,
что модели слов являются слева-на-право
моделями; то есть, что элементы переходной
матрицы
![]() удовлетворяют отношению:
удовлетворяют отношению:
![]() (7.27)
(7.27)
и, далее, мы ограничиваем ранг переходов случаем, когда:
![]() . (7.28)
. (7.28)
Таким образом, мы имеем переходы между состояниями не более чем через два. Эксперименты показывают, что это приемлемые ограничения.
Основываясь
на рассуждениях раздела 5.2, мы имеем
процедуру для вычисления вероятности
наблюдаемой последовательности
![]() ,
где L
означает метки входов кодовой книги,
порожденной моделью
,
где L
означает метки входов кодовой книги,
порожденной моделью
![]() ,
следующего вида:
,
следующего вида:
Инициализация:
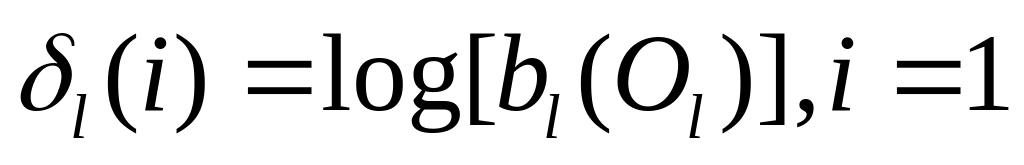
![]()
2.
Рекурсия: для
![]()
![]()
![]()
3.
Завершение: ![]() .
.
Этот
алгоритм является вариантом хорошо
известного ДП-метода, и может быть
показано, что он имеет свойство вычисления
последовательности
![]() ,
которая максимизирует вероятность
,
которая максимизирует вероятность
![]() .
Можно видеть, что если входы в матрицы
A
и B
хранятся в логарифмическом формате и
потому вычисление расстояния по Витерби
не требует умножений и вычисления
логарифма. Поэтом скорость вычисления
расстояния по Витерби очень высока.
.
Можно видеть, что если входы в матрицы
A
и B
хранятся в логарифмическом формате и
потому вычисление расстояния по Витерби
не требует умножений и вычисления
логарифма. Поэтом скорость вычисления
расстояния по Витерби очень высока.
Матрицы A и B для каждого СММ-слова вычисляются на основе обучающей выборки, содержащей множество наблюдаемых последовательностей для слова. Начиная с начальной оценки модели вычисляется вероятность P наблюдения данной обучающей последовательности O данной модели M. Используя алгоритм переоценки Баума-Вэлша модель итеративно переоценивается для увеличения P. Итерация останавливается, когда P перестает увеличиваться существенно, или когда выполняются какие-либо другие критерии (например, когда превышается заданное число итераций).