

2.2.1.1.2 Пример для первой психоаккустической модели.
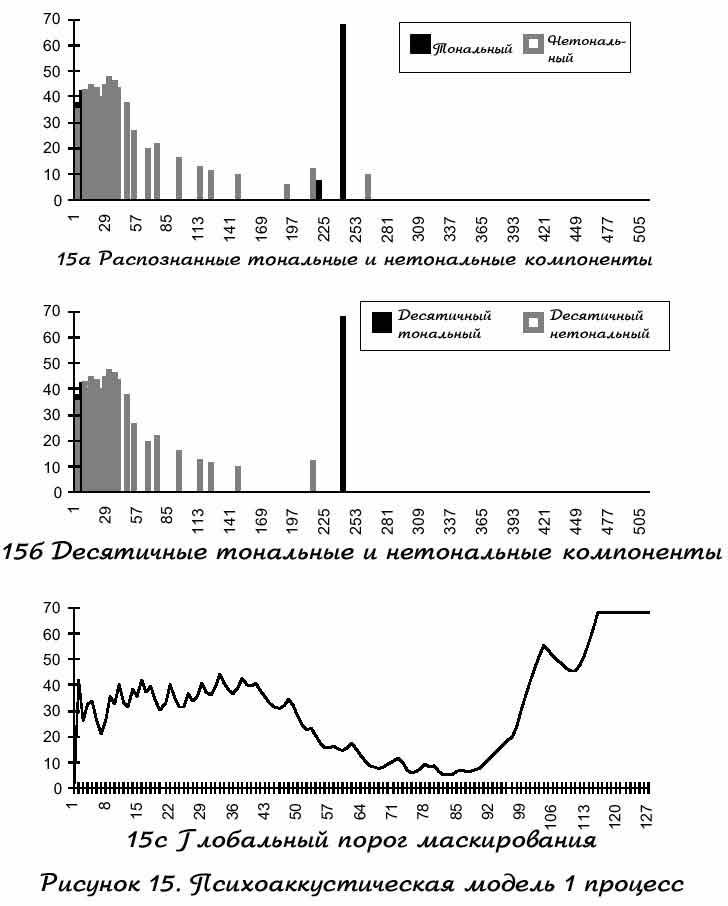
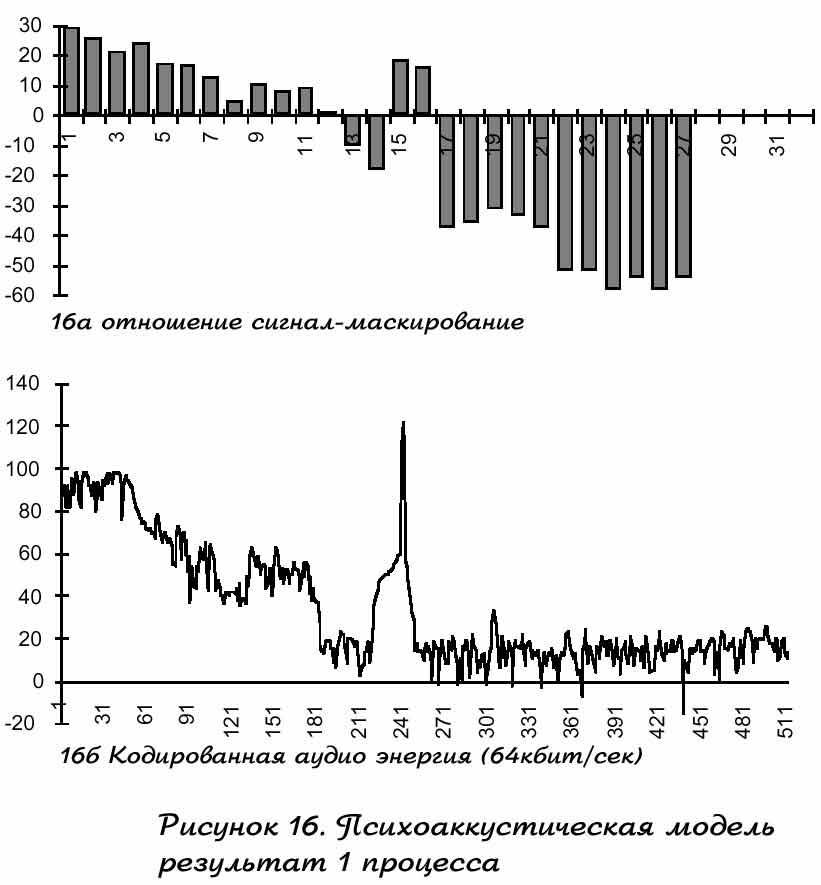
Этот пример использует однообразный аудио сигнал, упомянутый выше. Рисунок 15а показывает, как первая психоаккустическая модель определяет локальные спектральные пики, как тональные и нетональные компоненты. Рисунок 15б показывает остальные тональные и нетональные компоненты, после цифрового преобразования. Этот процесс одновременно убирает компоненты, которые могут быть ниже порога тишины и убирает слабые тональные компоненты внутри округленной части критической ширины полосы (примерно 0.5 ) от сильных тональных компонент. Первая психоавккустическая модель использует отрезает тональные и нетональные компоненты для определения глобального порога маскирования подчастей группы частот. Эта группа подчастей соответствует необходимой группе. Рисунок 15с показывает глобальный сосчитанный порог маскирования, для примера аудио сигнала. Первая психоаккустическая модель выбирает минимальный глобальный порог маскирования внутри каждой подчасти для вычисления алгоритма отношения сигнал-маскирования. Рисунок 16а показывает результат отношения сигнал-маскирования и рисунок 16б частотный график обработанного аудио сигнала методом отнощения сигнал-маскирования.
2.3 Возможности кодирования слоя.
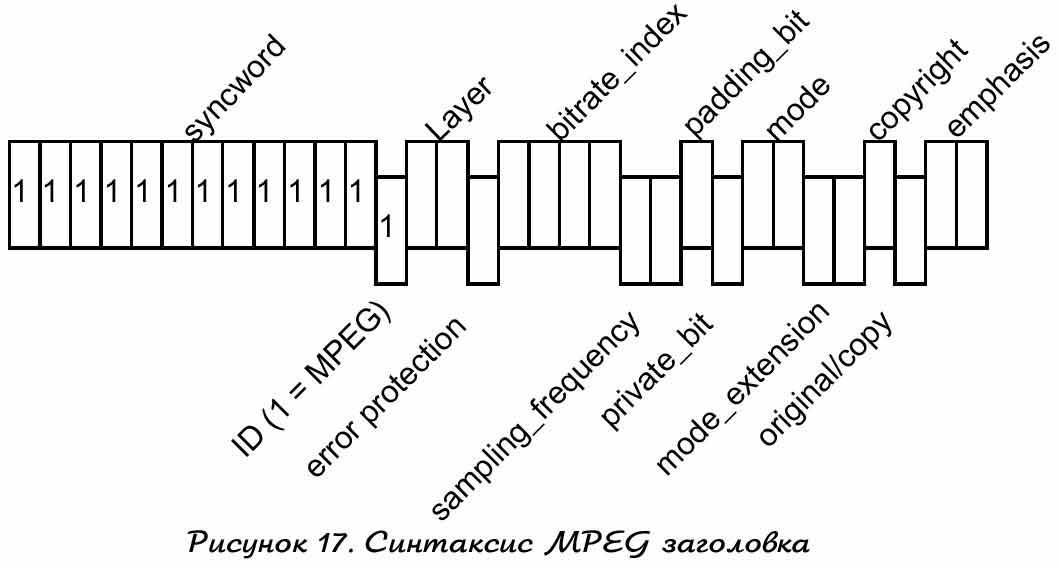
MPEG/audio стандарт имеет 3 отдельных слоя компрессии. Слой первый формируется основным алгоритмом, в то время, как слой два и три – определенные расширения, использующие некоторые элементы первого слоя. Каждый последующий слой улучшает качество компрессии, но более дорогостоим по сложности. Каждый MPEG/audio поток данных содержит периодически разделенные фрагменты заголовков для идентификации потока данных. Рисунок 17 дает графическое представление синтаксиса заголовка.
Второе битовое поле в MPEG заголовке определяет используемый слой.
2.3.1 Слой первый.
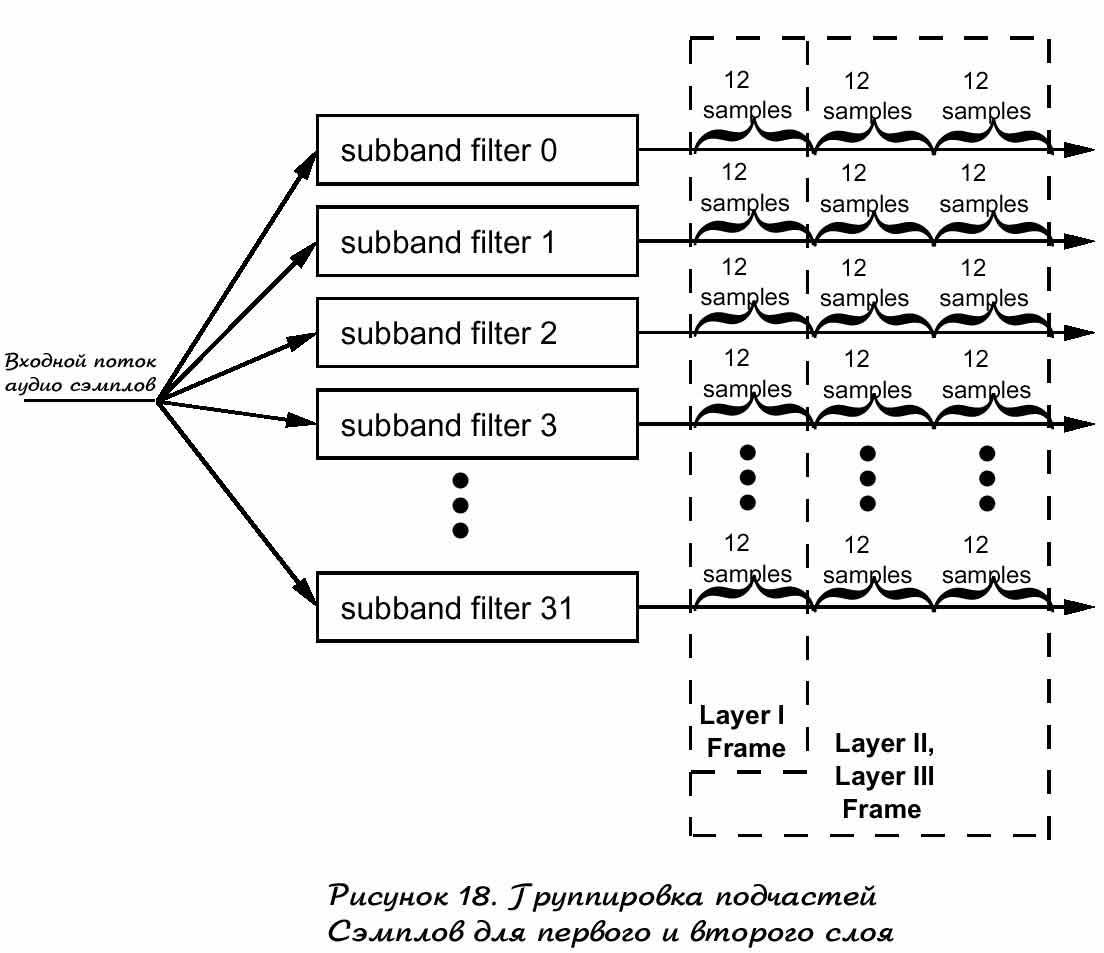
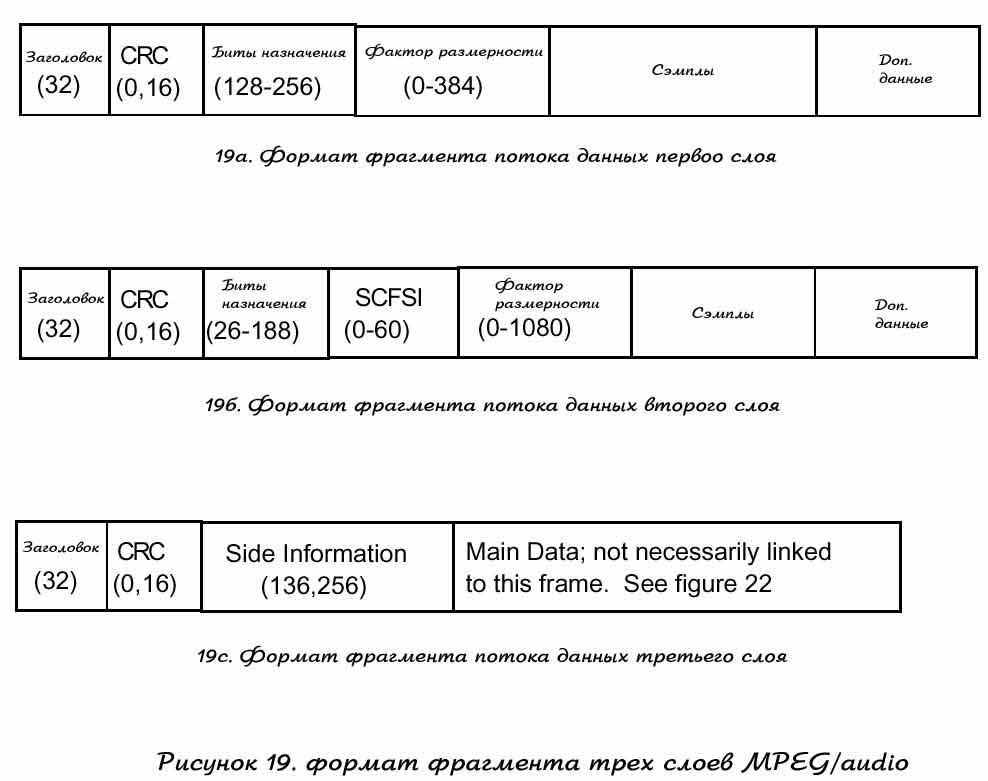
Алгоритм кодирования аудио, первого слоя во фрагментах 50 384 сэмпла. Это возможно, одновременным группированием 12 сжмплов каждый из который по 32 подчасти, как показано на рисунке 18. Кроме того код аудио данных, каждый его фрагмент содержит заголовок, включающий проверку на CRC error(слово) и возможные вспомогательные данные. Рисунок 19а показывает приведенные в порядок эти данные в поток данных первого слоя. Число внутри круглых скобок – возможное число бит, которые можно использовать для кодирования каждого поля. Каждая группа из 12 сэмплов получает назначенный бит и если выделенный бит не равен нулю, это фактор размера. Назначенный бит указывает декодеру число битов использованных для представления каждого сэмпла. Для слоя 1 он может быть назначен от 0 до 15 бит для подчасти. Фактор размерности – множитель этого бита для каждого сэмпла, для получения полного диапазона дискретизации. Каждый фактор размера представляется 6 битами. Декодер умножает раскодированные дискретные части на факто размерности для восстановления значений дискретный подчастей. Меняющийся диапазон выбора ыактора размерности одинаков и примерно и небного больше 120Дб. Комбинация назначенных бит и фактора размерности дают возможность для представления сэмплов с нечетким размером диапазона - около 120Дб. Стерео кодирование немного немного отличается представлением левого и правого каналов аудио сэмплирования и будет показано позже.
2.3.2 Слой 2.
Алгоритм второго слоя – прямое расширение первого слоя. Он кодирует аудио данные более большими группами и размывает границы возможных назначенных битов для значений средних и высоких подчастей. Так же как с битами назначения, так и со значением фактора размерности и дискретными частями, в более компактном коде. Второй слой дает более качественное аудио, за счет сохранения битов в своеобразных пространствах, содержащих больше возможных кодовых битов для представления значений дескретных подчастей.
Кодирование вторым слоем создает до 1152 сэмплов для каждого аудио канала. Тогда как первый слой кодирует данные одной группой по 12 сэмплов для каждой подчасти, второй слой кодирует данные 3 группами по 12 сэмплов для каждой подчасти.
Рисунок 18 – показывает группировку, насколько это возможно. Снова процедура стерео избыточного кодирования, это биты назначения и до трех факторов размерности для каждых трех из 12 сэмплов. Кодировщик изпользует различные факторы размерности для каждой группы 12 сэмплов, только если необходимо избежать слышимых искажений. Кодировщик разделяет значения факторов размерности среди двух или всех трех групп в двух других случаях. В первом – когда значение фактора размерности достаточно закрыты. Во втором – когда кодировщик предвидит временный шум-маскинг, эти шумы в аудио системах будут неслышны, за счет использования одного фактора размерности, вместо двух или трех. Выбор информационного поля фактора размерности в потоке данных второго слоя оповещает декодер как респределить значения фактора размерности. Рисунок 19 показывает соглашение различных полей данных в потоке первого слоя.
Другое расширение – для случая когда кодировщик второго слоя назначает 3,5, или 9 уровней для дискретизрования подчастей. При этих обстоятельствах кодировщик второго слоя определяет 3 последовательных дискретных значения как один, получается более компактное кодовое слово.