

3.1 Prior analysis of possible paralleling variants
For this NDO exist three levels of parallelization (Figure 3.2) is: subgraphs, branches and equations.

Figure 3.2 – Levels of parallelization
Analysis of virtual parallel algorithms is the indexes (for system avtokomutatsiyi InfiniBand):
- Loading processes;
- The ratio between the calculated volumes of transactions and data exchange operations;
- Virtual speed and efficiency of resource use;
Loading of processes
Calculations made using the formula:

For sub graphs:
![]() =17%,
where
=17%,
where
![]() -
6 branches
of
antitree
on
1 equation,
-
6 branches
of
antitree
on
1 equation,
![]() -
5 branches
of tree on 1 equation.
-
5 branches
of tree on 1 equation.
For branches:
![]() where
-
number
of bars
of
processor for calculating the two maximal
equations,
-
number of bars
of
processor for calculating the two minimal
equations.
where
-
number
of bars
of
processor for calculating the two maximal
equations,
-
number of bars
of
processor for calculating the two minimal
equations.
The ratio between the volumes calculated operations and data exchange operations
Calculations made by the formulas:

where Q – rate performance whole parallel computer architecture
F - network throughput
M – dimension of data bits
![]()
For sub graphs:

For branches:
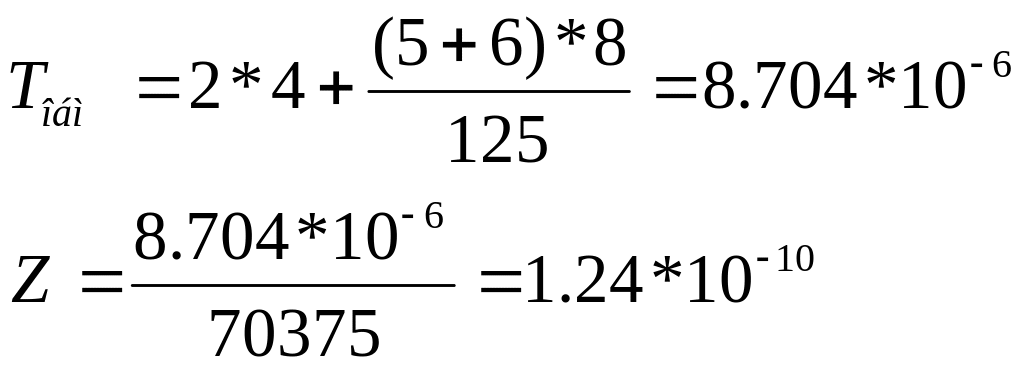
Virtual speed and efficiency of resource use
Calculations made by the formulas:
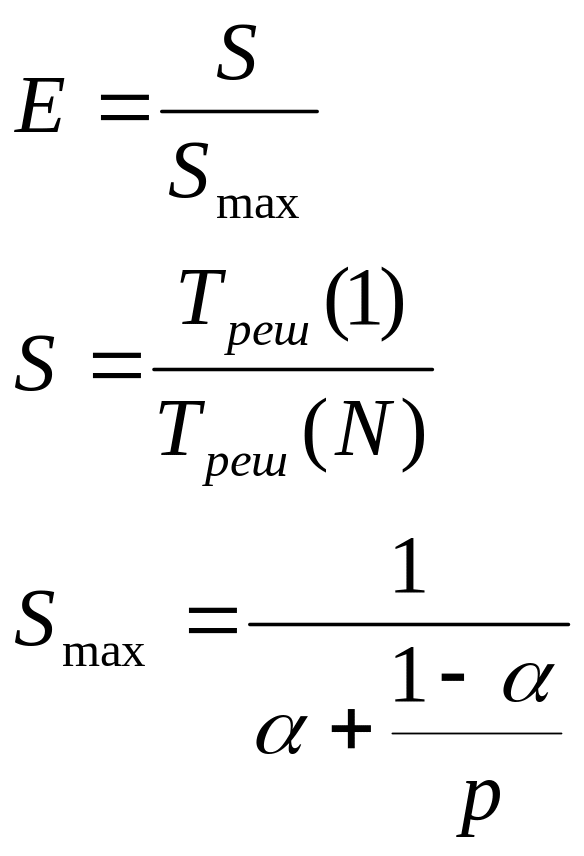
where
![]() -
part
of
parallel algorithm that is executed sequentially
-
part
of
parallel algorithm that is executed sequentially
p
– amount
of processors for parallel algorithm execution
![]()
where
![]() - time
of sharing
- time
of sharing
- time of calculation of whole system of equations
![]()
For sub graphs:
![]()
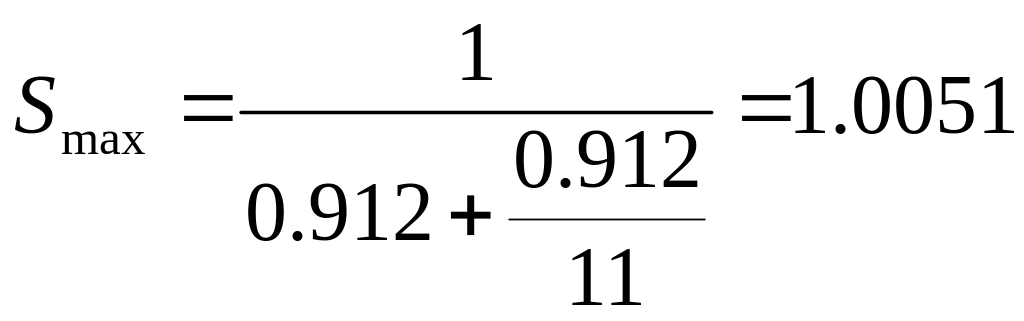
![]()
For branches
![]()

![]()
The final calculation of S and E research conducted after the execution time of parallel programs.
3.2 Development of parallel program
Parallel program developed at the level of equations. MIMD-equation algorithm shown on figure 3.3
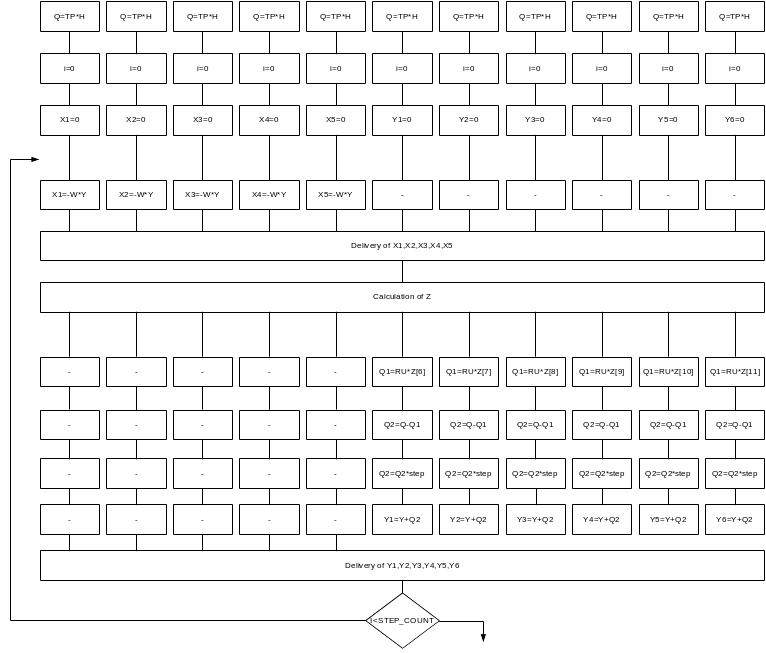
Figure 3.3 MIMD-algorithm for solving equations
For the developing an application we need following MPI functions:
Initialization of MPI-enveronment
Int mpi_Init(int *argc, char ***argv)
The programs in C each process arguments passed to the init function main, obtained from the command line (int * argc, char ** argv).
End function of MPI programs MPI_Finalize.
int MPI_Finalize(void)
Function close all MPI-processes and eliminate all areas of communication.
Function determine the number of processes in connection MPI_Comm_size.
int MPI_Comm_size (MPI_Comm comm, int * size)
IN comm - communicator;
OUT size - the number of communication processes in the communicator comm.
The function returns the number of processes of communication communicator comm.
To create groups and explicitly linked them communicators only possible value of COMM is MPI_COMM_WORLD and MPI_COMM_SELF, which are automatically created to initialize MPI. Subroutine is local.
Feature identification process MPI_Comm_rank.
int MPI_Comm_rank (MPI_Comm comm, int * rank)
IN comm - communicator;
OUT rank - number process vyzvav function.
The function returns the process number that caused this. Rooms processes lie in the range 0 .. size-1 (size value can be defined by the previous function). Is a local function.
Synchronization function MPI_Barrier blocking its work process, which has caused, until all other processes as a group do not cause this. Completion of this function is only possible once all processes.